本节重点介绍 :
- 什么是高基数
- 采集端高基数的原因
- 获取采集端的高基数metrics
- tsdb-status页面介绍
- 统计原理讲解:是基于内存中的倒排索引 算最大堆取 top10
- 通过接口获取metrics name top10
什么是高基数
- 通俗的说就是返回的series或者查询到的series数量过多
- 查询表现出来返回时间较长,对应调用服务端资源较多的查询
- 数量多少算多 10w~100w
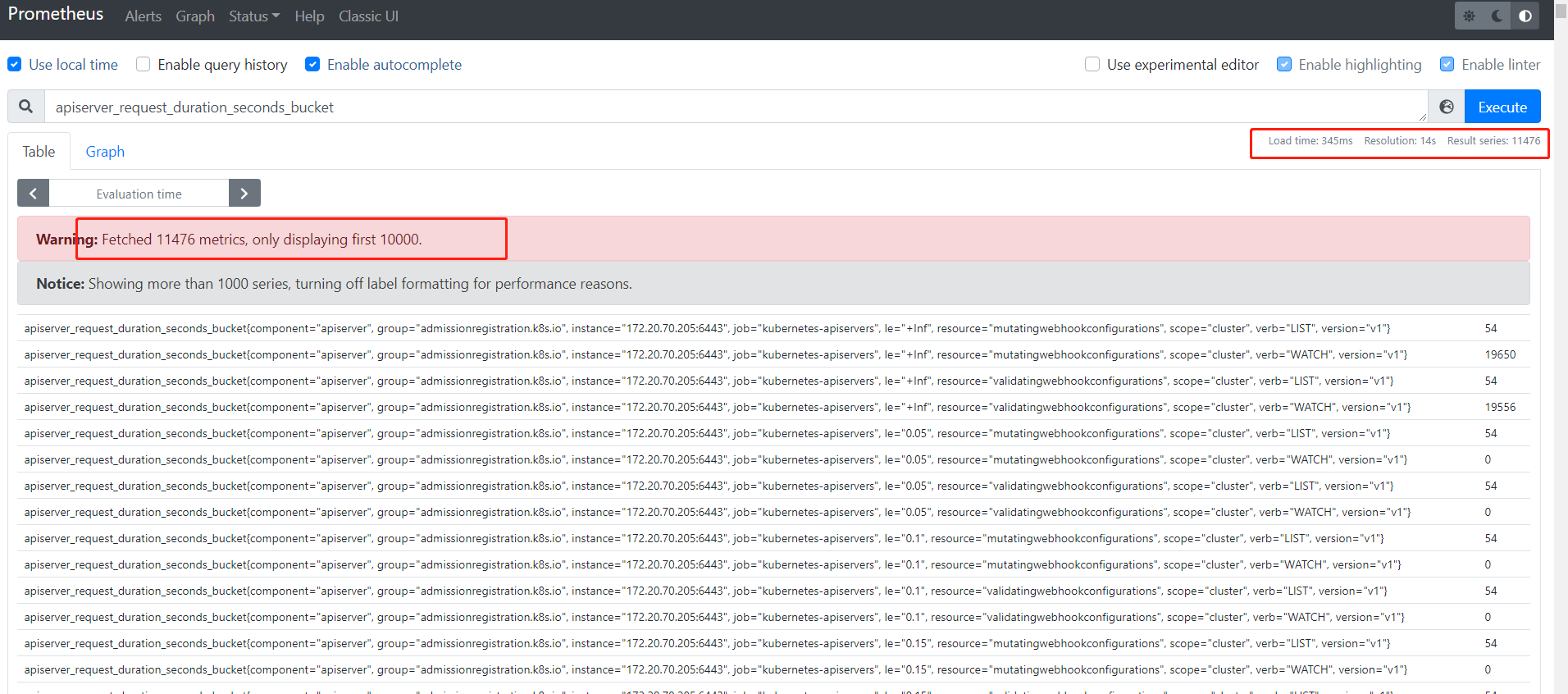
采集端高基数的现象
- apiserver_request_duration_seconds_bucket
采集端高基数的原因
举例histogram 标签过多
- 我们定义了一个名为 test_histogram_01 的histogram型metrics
- bucket总数为20个,也就是le这个标签的选项有20个
- 还定义了三个标签 “path”, “resource”, “scope”
- 假设这三个标签每个都有100选项
- 那么这个metric_name中不同标签的选项为
100*100*100*20=2kw - 也就是可以达到惊人的2千万的级别
- 当时实际中不大可能所有的标签都达到100个数量,但是个别的标签达到100是没问题的
TestHistogram01 = prometheus.NewHistogramVec(prometheus.HistogramOpts{Name: "test_histogram_01",Help: "RPC latency distributions.",Buckets: prometheus.LinearBuckets(0.1, 0.2, 20),}, []string{"path", "resource", "scope"})
)
获取采集端的高基数metrics
tsdb页面解析
- Top 10 label names with value count: 标签中value最多的10个
- Top 10 series count by metric names: metric_name匹配的series最多的10个
- Top 10 label names with high memory usage: 标签消耗内存最多的10个
- Top 10 series count by label value pairs: 标签对数量最多的10个
统计原理解析
- 是基于内存中的倒排索引 算最大堆取 top10
- 代码位置 D:\go_path\src\github.com\prometheus\prometheus\web\api\v1\api.go
func (api *API) serveTSDBStatus(*http.Request) apiFuncResult {s, err := api.db.Stats("__name__")if err != nil {return apiFuncResult{nil, &apiError{errorInternal, err}, nil, nil}}metrics, err := api.gatherer.Gather()if err != nil {return apiFuncResult{nil, &apiError{errorInternal, fmt.Errorf("error gathering runtime status: %s", err)}, nil, nil}}chunkCount := int64(math.NaN())for _, mF := range metrics {if *mF.Name == "prometheus_tsdb_head_chunks" {m := *mF.Metric[0]if m.Gauge != nil {chunkCount = int64(m.Gauge.GetValue())break}}}return apiFuncResult{tsdbStatus{HeadStats: HeadStats{NumSeries: s.NumSeries,ChunkCount: chunkCount,MinTime: s.MinTime,MaxTime: s.MaxTime,NumLabelPairs: s.IndexPostingStats.NumLabelPairs,},SeriesCountByMetricName: convertStats(s.IndexPostingStats.CardinalityMetricsStats),LabelValueCountByLabelName: convertStats(s.IndexPostingStats.CardinalityLabelStats),MemoryInBytesByLabelName: convertStats(s.IndexPostingStats.LabelValueStats),SeriesCountByLabelValuePair: convertStats(s.IndexPostingStats.LabelValuePairsStats),}, nil, nil, nil}
}
api接口
import requestsdef label_names(host, ):uri = 'http://{}/api/v1/status/tsdb'.format(host)res = requests.get(uri)data = res.json().get("data")if not data:returnseriesCountByMetricName = data.get("seriesCountByMetricName")for i in seriesCountByMetricName:print(i)if __name__ == '__main__':label_names("172.20.70.215:8091")
- seriesCountByMetricName结果
{'name': 'apiserver_request_duration_seconds_bucket', 'value': 11476}
{'name': 'etcd_request_duration_seconds_bucket', 'value': 9430}
{'name': 'rest_client_request_duration_seconds_bucket', 'value': 2266}
{'name': 'apiserver_response_sizes_bucket', 'value': 1440}
{'name': 'workqueue_work_duration_seconds_bucket', 'value': 737}
{'name': 'workqueue_queue_duration_seconds_bucket', 'value': 737}
{'name': 'grpc_server_handled_total', 'value': 697}
{'name': 'apiserver_request_total', 'value': 472}
{'name': 'apiserver_request_duration_seconds_count', 'value': 302}
{'name': 'apiserver_request_duration_seconds_sum', 'value': 302}
本节重点总结 :
- 什么是高基数
- 采集端高基数的原因
- 获取采集端的高基数metrics
- tsdb-status页面介绍
- 统计原理讲解:是基于内存中的倒排索引 算最大堆取 top10
- 通过接口获取metrics name top10