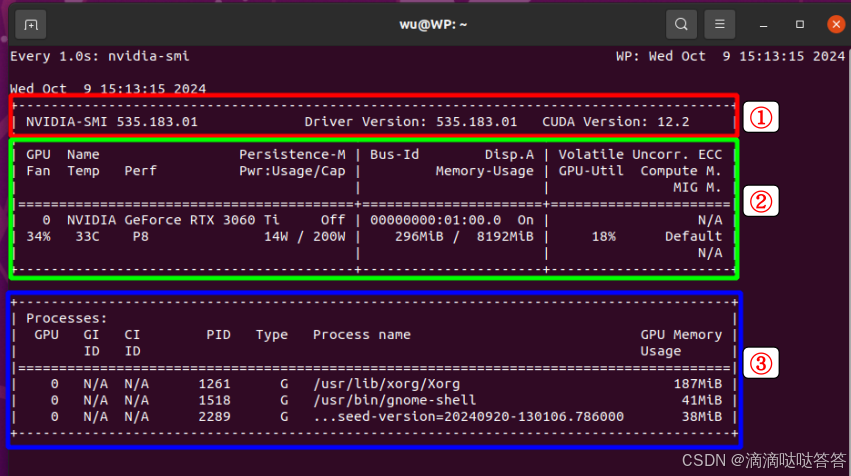
首先标注一部分图片,进行训练,生成模型,标注文件为xml方便后面统一做处理。
1、标注数据(文件为xml, 转为txt用于训练,保留xml标签文件)
2、模型训练(训练配置、训练代码、)
3、使用训练好的模型进行预标注 (生成标注文件 xml)
4、检测标注文件工具:
单类别拆分、
合并所有类别xml、
合并指定几个类别、
固定矩形位置增加类别与固定位置绘制矩形检测是否重合删除类别(增删类别)、
固定矩形位置生成xml、
1、标注数据
注意:标注使用voc
这样标注文件是xml文件。
生成文件结构:放入当前目录下运行
import os# 创建文件夹结构
# 创建单层目录,如果目录存在则报错
path = "./VOCdevkit"
os.mkdir(path)
# 创建多级目录,如果目录存在则报错
p1 = os.path.join(path, "VOC2007")
os.makedirs(p1)
p2 = os.path.join(p1, "Annotations")
os.makedirs(p2)
p3 = os.path.join(p1, "YOLOLabels")
os.makedirs(p3)
xml转txt标注文件:
将xml文件放入:\VOCdevkit\VOC2007\Annotations 文件夹中
将图片放入:\VOCdevkit\VOC2007\JPEGImages 文件夹中
可指定训练与测试的百分比
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfileclasses = ['clascc1', 'class2'] # 注意与自己的类对应,对应,对应,不然转好的txt文件是空的
# classes=["ball"]TRAIN_RATIO = 80 # 按自己的要求划分,这里代表是train:test=8:2# 创建文件夹结构
# 创建单层目录,如果目录存在则报错
path = "./VOCdevkit"
os.mkdir(path)
# 创建多级目录,如果目录存在则报错
p1 = os.path.join(path, "VOC2007")
os.makedirs(p1)
p2 = os.path.join(p1, "Annotations")
os.makedirs(p2)
p3 = os.path.join(p1, "YOLOLabels")
os.makedirs(p3)def clear_hidden_files(path):dir_list = os.listdir(path)for i in dir_list:abspath = os.path.join(os.path.abspath(path), i)if os.path.isfile(abspath):if i.startswith("._"):os.remove(abspath)else:clear_hidden_files(abspath)def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id, encoding='utf-8')out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w', encoding='utf-8')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):# difficult = obj.find('difficult').textcls = obj.find('name').text# if cls not in classes or int(difficult) == 1:# continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')in_file.close()out_file.close()wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):path = os.path.join(image_dir, list_imgs[i])if os.path.isfile(path):image_path = image_dir + list_imgs[i]voc_path = list_imgs[i](nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))annotation_name = nameWithoutExtention + '.xml'annotation_path = os.path.join(annotation_dir, annotation_name)label_name = nameWithoutExtention + '.txt'label_path = os.path.join(yolo_labels_dir, label_name)prob = random.randint(1, 100)print("Probability: %d" % prob)if (prob < TRAIN_RATIO): # train datasetif os.path.exists(annotation_path):train_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_train_dir + voc_path)copyfile(label_path, yolov5_labels_train_dir + label_name)else: # test datasetif os.path.exists(annotation_path):test_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_test_dir + voc_path)copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()2、模型训练
将下面文件结构复制到训练的路径(服务器)
yol;ov8 数据集文件结构:当前文件结构可以直接用于训练

训练配置:
配置图片的路径
train: /data/libowen/yolov8_1/ultralytics/data/VOCdevkit/images/train
val: /data/libowen/yolov8_1/ultralytics/data/VOCdevkit/images/val
# number of classes
nc: 2
# class names
names: ['class1', 'class2']
训练代码:
from ultralytics import YOLO# Load a model
# model = YOLO("yolov8n.yaml") # build a new model from YAML
# 目标检测 n s m l x
model = YOLO("yolov8m.pt") # load a pretrained model (recommended for training)
# 图像分类
# model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# model = YOLO("dataset.yaml").load("yolov8n.pt") # build from YAML and transfer weights# Train the model
results = model.train(data="dataset.yaml", epochs=40, imgsz=640) # 40次 输入图像缩放大小640
# results = model.train(data="D:/yolo_/mu_biao_gen_zong/data", epochs=40, imgsz=640)
3、预标注–生成标注文件 xml
参数:读取图片的路径、保存xml的路径、需要标注的类别、需要标注的文件后缀、模型的路径+名称、图像的分辨率信息、
import cv2
from ultralytics import YOLO
import numpy as np
import time
import os
import xml.etree.ElementTree as ET
from xml.dom import minidomdef save_xml_add(root, lei_bie_name, xmin, ymin, xmax, ymax):object_elem1 = ET.SubElement(root, "object")ET.SubElement(object_elem1, "name").text = lei_bie_namebndbox1 = ET.SubElement(object_elem1, "bndbox")ET.SubElement(bndbox1, "xmin").text = str(xmin)ET.SubElement(bndbox1, "ymin").text = str(ymin)ET.SubElement(bndbox1, "xmax").text = str(xmax)ET.SubElement(bndbox1, "ymax").text = str(ymax)def create_xml_annotation(image_path, coord1, xml_save_path, size_3):root = ET.Element("annotation")folder = os.path.dirname(image_path)ET.SubElement(root, "folder").text = folderfilename = os.path.basename(image_path)ET.SubElement(root, "filename").text = filenamesize = ET.SubElement(root, "size")ET.SubElement(size, "width").text = size_3[0]ET.SubElement(size, "height").text = size_3[1]ET.SubElement(size, "depth").text = size_3[2]for i in coord1:save_xml_add(root, str(i[0]), str(i[1]), str(i[2]), str(i[3]), str(i[4]))with open(xml_save_path, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)print("已保存:", xml_save_path)class Yolov8Detector():def __init__(self, mode_name):# 加载目标检测模型# self.model = YOLO(mode_name)self.model = YOLO(mode_name)self.model_cls_name = self.model.namesdef run(self, frame, image_size):# 判断图像类型是否正确if (isinstance(frame, np.ndarray)):boxes_list = []# 目标检测results = self.model.predict(frame, imgsz=image_size)# results = self.model(frame)result = results[0]# print(result, "这是")boxes = result.boxes.cpu() # Boxes对象用于边界框输出for cls_, box in zip(boxes.cls, boxes):cls_1 = int(np.array(cls_))x1 = int(np.array(box.xyxy)[0][0])y1 = int(np.array(box.xyxy)[0][1])x2 = int(np.array(box.xyxy)[0][2])y2 = int(np.array(box.xyxy)[0][3])boxes_list.append((self.model_cls_name[cls_1], x1, y1, x2, y2))# 返回格式# [(类别1, x1, y1, x2, y2), (类别2, x1, y1, x2, y2)]return boxes_listdef model_cls_name(self):# 获取模型内类别名return self.model_cls_name# 加载检测模型
v8D = Yolov8Detector("zhayaoku_20240828.pt")# 图片路径
img_path = "./img_lab_1000/img_1000/"
# 保存xml的路径
xml_save_path = "./img_lab_1000/img_xml/"# 图片分辨率信息
size_list = ["1920", "1080", "3"]# 需要标注的类别 # head_no_hat head_with_hat
class_name_list_xml_save = ['helmet']for img_name in os.listdir(img_path):if img_name.endswith(".jpg"):image_path = os.path.join(img_path, img_name)frame = cv2.imread(image_path)coord1 = v8D.run(frame, 640) coord2 = []for i_ in coord1:for name_i in class_name_list_xml_save:if i_[0] == name_i:coord2.append((i_[0], i_[1], i_[2], i_[3], i_[4]))# xml文件名xml_save_path_name = os.path.join(xml_save_path, os.path.splitext(img_name)[0] + ".xml")# 保存xmlcreate_xml_annotation(image_path, coord2, xml_save_path_name, size_list)
检测标注文件工具:
单类别拆分
参数:全部类别名、xml读取路径、xml保存路径、
import xml.etree.ElementTree as ET
import os
from xml.dom import minidom# 全部类别
list_class = ['helmet', 'human_backward', 'human_forward','closed_door', 'opened_door', 'covered_door','head_with_hat', 'head_no_hat']
# xml标签路径 (绝对路径)
path_lab = "E:/zyk_lab/炸药库ataset240820/ce/lab/"# 拆分保存xml的路径 (绝对路径)
save_xml_path = "E:/zyk_lab/炸药库ataset240820/ce/ce/"for xml_name in os.listdir(path_lab):# xml_name = 'Camera12_20231001_30.xml'# 1. 读取XML文档tree = ET.parse(path_lab + xml_name)root = tree.getroot()# 存储 字典dict_class = {}for i in list_class:dict_class[i] = []# 创建单个文件夹folder_name = save_xml_path + "/" + i + "/"if not os.path.exists(folder_name):os.mkdir(folder_name)# print(f"文件夹 '{folder_name}' 创建成功。")# else:# print(f"文件夹 '{folder_name}' 已存在。")# for i, j in dict_class.items():# print(i, j)size_find_0 = root.find("size")size_w = size_find_0.find("width")size_h = size_find_0.find("height")size_d = size_find_0.find("depth")## print(size_w.text)# print(size_h.text)# print(size_d.text)# 分离文件名 与 文件后缀name_lab, xml_ = os.path.splitext(xml_name)folder_jpg = root.find("folder")# print(folder_jpg.text)path_jpg = root.find("path")# print(path_jpg.text)filename_jpg = root.find("filename")# print(filename_jpg.text)# 2. 查找 object 全部objects = root.findall('object')for object_find_0 in objects:# print('Tag:', child.tag)# print('Text:', child.text)# print('Attributes:', child.attrib)class_name = object_find_0.find("name")class_bndbox = object_find_0.find("bndbox")class_bndbox_xmin = class_bndbox.find("xmin")class_bndbox_ymin = class_bndbox.find("ymin")class_bndbox_xmax = class_bndbox.find("xmax")class_bndbox_ymax = class_bndbox.find("ymax")# print(class_name.text)# print(class_bndbox_xmin.text)# print(class_bndbox_ymin.text)# print(class_bndbox_xmax.text)# print(class_bndbox_ymax.text)dict_class[class_name.text].append((class_name.text,class_bndbox_xmin.text,class_bndbox_ymin.text,class_bndbox_xmax.text,class_bndbox_ymax.text,))for ob_class, ob_list in dict_class.items():# 创建根元素root = ET.Element("annotation")folder_save = ET.SubElement(root, "folder")folder_save.text = folder_jpg.textfilename_jpg_save = ET.SubElement(root, "filename")filename_jpg_save.text = filename_jpg.textpath_save_xml = ET.SubElement(root, "path")path_save_xml.text = path_jpg.text# 创建子元素size_save = ET.SubElement(root, "size")# 创建二级子元素 只需输入参数不同即可size_w_save = ET.SubElement(size_save, "width")size_w_save.text = size_w.textsize_h_save = ET.SubElement(size_save, "height")size_h_save.text = size_h.textsize_d_save = ET.SubElement(size_save, "depth")size_d_save.text = size_d.textfor ob_list_i in ob_list:object_save = ET.SubElement(root, "object")name_save = ET.SubElement(object_save, "name")name_save.text = str(ob_list_i[0])bndbox_save = ET.SubElement(object_save, "bndbox")xmin_save = ET.SubElement(bndbox_save, "xmin")xmin_save.text = str(ob_list_i[1])ymin_save = ET.SubElement(bndbox_save, "ymin")ymin_save.text = str(ob_list_i[2])xmax_save = ET.SubElement(bndbox_save, "xmax")xmax_save.text = str(ob_list_i[3])ymax_save = ET.SubElement(bndbox_save, "ymax")ymax_save.text = str(ob_list_i[4])# 写入文件if len(dict_class[ob_class]) != 0:if ob_class in list_class:path_save_i = save_xml_path + "/" + ob_class + "/" + xml_nameprint(path_save_i)# tree.write(path_save_i, encoding="utf-8", xml_declaration=True)with open(path_save_i, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)合并所有类别xml
参数:全部类别、读取图片路径、单类别拆分的总路径、合并保存的路径、
import xml.etree.ElementTree as ET
import os
from xml.dom import minidomlist_class = ['helmet', 'human_backward', 'human_forward','closed_door', 'opened_door', 'covered_door','head_with_hat', 'head_no_hat']
# 图片路径
path_img = "E:/zyk_lab/炸药库ataset240820/ce/img/"
# 拆分的总路径
path_lab = "E:/zyk_lab/炸药库ataset240820/ce/ce/"
# 合并后保存的路径
path_lab_save = "E:/zyk_lab/炸药库ataset240820/ce/lab_ce/"for img_name in os.listdir(path_img):# img_name = "Camera12_20231001_31"img_name = os.path.splitext(img_name)[0]dict_class = {}for i in list_class:dict_class[i] = []dict_class["width"] = 0dict_class["height"] = 0dict_class["depth"] = 0dict_class["folder"] = "null"dict_class["path"] = "null"dict_class["filename"] = "null"for file_1 in os.listdir(path_lab):path_i = os.path.join(path_lab, file_1)for xml_name in os.listdir(path_i):if img_name == os.path.splitext(xml_name)[0]:# 1. 读取XML文档xml_path = os.path.join(path_i, xml_name)tree = ET.parse(xml_path)root = tree.getroot()size_find_0 = root.find("size")size_w = size_find_0.find("width").textsize_h = size_find_0.find("height").textsize_d = size_find_0.find("depth").textfolder_jpg = root.find("folder").text# print(folder_jpg.text)try:path_jpg = root.find("path").text# print(path_jpg.text)except BaseException:path_jpg = "path_jpg"filename_jpg = root.find("filename").text# print(filename_jpg.text)dict_class["width"] = size_wdict_class["height"] = size_hdict_class["depth"] = size_ddict_class["folder"] = folder_jpgdict_class["path"] = path_jpgdict_class["filename"] = filename_jpg# 2. 查找 object 全部try:objects = root.findall('object')for object_find_0 in objects:# print('Tag:', child.tag)# print('Text:', child.text)# print('Attributes:', child.attrib)class_name = object_find_0.find("name")class_bndbox = object_find_0.find("bndbox")class_bndbox_xmin = class_bndbox.find("xmin")class_bndbox_ymin = class_bndbox.find("ymin")class_bndbox_xmax = class_bndbox.find("xmax")class_bndbox_ymax = class_bndbox.find("ymax")# print(class_name.text)# print(class_bndbox_xmin.text)# print(class_bndbox_ymin.text)# print(class_bndbox_xmax.text)# print(class_bndbox_ymax.text)dict_class[class_name.text].append((class_name.text,class_bndbox_xmin.text,class_bndbox_ymin.text,class_bndbox_xmax.text,class_bndbox_ymax.text,))except BaseException:print("读取 object 失败")# 保存# 创建根元素root = ET.Element("annotation")folder_save = ET.SubElement(root, "folder")if dict_class["folder"] != "null":folder_save.text = dict_class["folder"]filename_jpg_save = ET.SubElement(root, "filename")if dict_class["filename"] != "null":filename_jpg_save.text = dict_class["filename"]path_save_xml = ET.SubElement(root, "path")if dict_class["path"] != "null":path_save_xml.text = dict_class["path"]# 创建子元素size_save = ET.SubElement(root, "size")# 创建二级子元素 只需输入参数不同即可size_w_save = ET.SubElement(size_save, "width")if dict_class["width"] != "null":size_w_save.text = dict_class["width"]size_h_save = ET.SubElement(size_save, "height")if dict_class["height"] != "null":size_h_save.text = dict_class["height"]size_d_save = ET.SubElement(size_save, "depth")if dict_class["depth"] != "null":size_d_save.text = dict_class["depth"]for ob_class, ob_list in dict_class.items():print(ob_class, ob_list)if ob_class in ["folder", "filename", "path", "size", "width", "height", "depth"]:continuefor ob_list_i in ob_list:# print(ob_list_i)object_save = ET.SubElement(root, "object")name_save = ET.SubElement(object_save, "name")name_save.text = str(ob_list_i[0])bndbox_save = ET.SubElement(object_save, "bndbox")xmin_save = ET.SubElement(bndbox_save, "xmin")xmin_save.text = str(ob_list_i[1])ymin_save = ET.SubElement(bndbox_save, "ymin")ymin_save.text = str(ob_list_i[2])xmax_save = ET.SubElement(bndbox_save, "xmax")xmax_save.text = str(ob_list_i[3])ymax_save = ET.SubElement(bndbox_save, "ymax")ymax_save.text = str(ob_list_i[4])# 写入文件# if len(dict_class[ob_class]) != 0:# if ob_class in list_class:path_save_i = path_lab_save + img_name + ".xml"print(path_save_i)# tree.write(path_save_i, encoding="utf-8", xml_declaration=True)with open(path_save_i, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)合并指定几个类别
注意:合并后检测完毕后,需要到原本拆分成单类别目录,将检测前的xml文件删除,把检查后的xml放入其中一个类别文件夹即可。
参数:全部类别、需要合并的类别、读取图像路径、拆分总目录、保存xml路径、
import xml.etree.ElementTree as ET
import os
from xml.dom import minidom# 全部类别
# list_class = ['class1', 'class2', 'class3']
list_class = ['class1', 'class2']# 图像路径
path_lab = "E:/zyk_lab/ataset240820/ce/img/"# 拆分后的总路径
xml_path_all = "E:/zyk_lab/ataset240820/ce/ce/"
# xml 保存的路径
xml_save_path = "E:/zyk_lab/ataset240820/ce/xml_ce/"for xml_name in os.listdir(path_lab):# xml_name = 'Camera12_20231001_30.xml'# 存储 字典dict_class = {}for i in list_class:dict_class[i] = []dict_class["width"] = 0dict_class["height"] = 0dict_class["depth"] = 0dict_class["folder"] = "null"dict_class["path"] = "null"dict_class["filename"] = "null"# 读取 拆分后的 单类别路径for list_class_i in list_class:class_path = os.path.join(xml_path_all, list_class_i)# 拆分.jpg后缀xml_name = os.path.splitext(xml_name)[0] + ".xml"path_xml_name = os.path.join(class_path, xml_name)# 检测文件是否存在if os.path.exists(path_xml_name):# 1. 读取XML文档tree = ET.parse(path_xml_name)root = tree.getroot()size_find_0 = root.find("size")size_w = size_find_0.find("width")size_h = size_find_0.find("height")size_d = size_find_0.find("depth")# print(size_w.text)# print(size_h.text)# print(size_d.text)folder_jpg = root.find("folder")# print(folder_jpg.text)try:path_jpg = root.find("path").text# print(path_jpg.text)except BaseException:path_jpg = "path_jpg"filename_jpg = root.find("filename")# print(filename_jpg.text)dict_class["width"] = size_w.textdict_class["height"] = size_h.textdict_class["depth"] = size_d.textdict_class["folder"] = folder_jpg.textdict_class["path"] = path_jpgdict_class["filename"] = filename_jpg.text# 2. 查找 object 全部try:objects = root.findall('object')for object_find_0 in objects:# print('Tag:', child.tag)# print('Text:', child.text)# print('Attributes:', child.attrib)class_name = object_find_0.find("name")class_bndbox = object_find_0.find("bndbox")class_bndbox_xmin = class_bndbox.find("xmin")class_bndbox_ymin = class_bndbox.find("ymin")class_bndbox_xmax = class_bndbox.find("xmax")class_bndbox_ymax = class_bndbox.find("ymax")# print(class_name.text)# print(class_bndbox_xmin.text)# print(class_bndbox_ymin.text)# print(class_bndbox_xmax.text)# print(class_bndbox_ymax.text)if class_name.text in list_class:dict_class[class_name.text].append((class_name.text,class_bndbox_xmin.text,class_bndbox_ymin.text,class_bndbox_xmax.text,class_bndbox_ymax.text,))except BaseException:print("读取 object 失败")# for i, j in dict_class.items():# print(i, j)# 创建根元素root = ET.Element("annotation")folder_save = ET.SubElement(root, "folder")folder_save.text = dict_class["folder"]filename_jpg_save = ET.SubElement(root, "filename")filename_jpg_save.text = dict_class["filename"]path_save_xml = ET.SubElement(root, "path")path_save_xml.text = dict_class["filename"]# 创建子元素size_save = ET.SubElement(root, "size")# 创建二级子元素 只需输入参数不同即可size_w_save = ET.SubElement(size_save, "width")size_w_save.text = dict_class["width"]size_h_save = ET.SubElement(size_save, "height")size_h_save.text = dict_class["height"]size_d_save = ET.SubElement(size_save, "depth")size_d_save.text = dict_class["depth"]for class_i in list_class:for ob_list_i in dict_class[class_i]:object_save = ET.SubElement(root, "object")name_save = ET.SubElement(object_save, "name")name_save.text = str(ob_list_i[0])bndbox_save = ET.SubElement(object_save, "bndbox")xmin_save = ET.SubElement(bndbox_save, "xmin")xmin_save.text = str(ob_list_i[1])ymin_save = ET.SubElement(bndbox_save, "ymin")ymin_save.text = str(ob_list_i[2])xmax_save = ET.SubElement(bndbox_save, "xmax")xmax_save.text = str(ob_list_i[3])ymax_save = ET.SubElement(bndbox_save, "ymax")ymax_save.text = str(ob_list_i[4])# 写入文件path_save_i = os.path.join(xml_save_path, xml_name)print(path_save_i)# tree.write(path_save_i, encoding="utf-8", xml_declaration=True)with open(path_save_i, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)增删类别
注意:不会新建xml
在xml文件内,想在固定位置绘制一个矩形框作为标签。
在xml文件内,指定左上角与右下角坐标检查某类别的标注矩形是否有重合,有则删除。
import xml.etree.ElementTree as ET
import os
from xml.dom import minidom# 矩形重合检测def is_rectangles_overlap(x1, y1, x2, y2, x1_, y1_, x2_, y2_):stat = Falsenum_x2 = x2_ - x1_for i in range(num_x2):x1_i = x1_ + i# print(x1_i)if (x1 < x1_i < x2) and (y1 < y1_ < y2):# print("x上面线内的点有重合")stat = Truebreakif (x1 < x1_i < x2) and (y1 < y2_ < y2):# print("x下面线内的点有重合")stat = Truebreaknum_y1 = y2_ - y1_for j in range(num_y1):y1_i = y1_ + jif (x1 < x1_ < x2) and (y1 < y1_i < y2):# print("y左边线内有重合")stat = Truebreakif (x1 < x2_ < x2) and (y1 < y1_i < y2):# print("y右边线内有重合")stat = Truebreak# 矩形完全重合if x1 == x1_ and y1 == y1_ and x2 == x2_ and y2 == y2_:stat = Truereturn statdef save_xml_add(name, xmin, ymin, xmax, ymax):object_save = ET.SubElement(root, "object")name_save = ET.SubElement(object_save, "name")name_save.text = str(name)bndbox_save = ET.SubElement(object_save, "bndbox")xmin_save = ET.SubElement(bndbox_save, "xmin")xmin_save.text = str(xmin)ymin_save = ET.SubElement(bndbox_save, "ymin")ymin_save.text = str(ymin)xmax_save = ET.SubElement(bndbox_save, "xmax")xmax_save.text = str(xmax)ymax_save = ET.SubElement(bndbox_save, "ymax")ymax_save.text = str(ymax)# 添加标注的信息
# 根据分辨率的不同设置不同类别和坐标
dict_add = {}
# 704 只是为了提醒自己在多大分辨率的图上绘制
# dict_add = {704: [("covered_door", 184, 33, 331, 330), ]
# }# 删除标注信息
# dict_del = [("closed_door", 184, 33, 331, 330)]
# dle 不管什么类别 只要重合就删除
dict_del = [("dle", 184, 33, 331, 330)]
# dict_del = []# 读取路径 拆分后单类别的路径
path_i = r"E:\zyk_lab\炸药库ataset240820\ce\ce\closed_door"# 保存路径 自己新建路径
path_lab_save = r"E:\zyk_lab\炸药库ataset240820\ce\xml_ce"# xml_name = "Camera12_20231001_30.xml"
for xml_name in os.listdir(path_i):# 存储字典 全部类别list_class = ['helmet', 'human_backward', 'human_forward','closed_door', 'opened_door', 'covered_door','head_with_hat', 'head_no_hat']dict_class = {}for i in list_class:dict_class[i] = []# 1. 读取XML文档xml_path = os.path.join(path_i, xml_name)print(xml_path)tree = ET.parse(xml_path)root = tree.getroot()size_find_0 = root.find("size")size_w = size_find_0.find("width").textsize_h = size_find_0.find("height").textsize_d = size_find_0.find("depth").textfolder_jpg = root.find("folder").text# print(folder_jpg.text)path_jpg = root.find("path").text# print(path_jpg.text)filename_jpg = root.find("filename").text# print(filename_jpg.text)dict_class["width"] = size_wdict_class["height"] = size_hdict_class["depth"] = size_ddict_class["folder"] = folder_jpgdict_class["path"] = path_jpgdict_class["filename"] = filename_jpg# 2. 查找 object 全部objects = root.findall('object')for object_find_0 in objects:# print('Tag:', child.tag)# print('Text:', child.text)# print('Attributes:', child.attrib)class_name = object_find_0.find("name")class_bndbox = object_find_0.find("bndbox")class_bndbox_xmin = class_bndbox.find("xmin")class_bndbox_ymin = class_bndbox.find("ymin")class_bndbox_xmax = class_bndbox.find("xmax")class_bndbox_ymax = class_bndbox.find("ymax")# print(class_name.text)# print(class_bndbox_xmin.text)# print(class_bndbox_ymin.text)# print(class_bndbox_xmax.text)# print(class_bndbox_ymax.text)con_1 = Falseif dict_del:for list_con in dict_del:x1_, y1_, x2_, y2_ = int(class_bndbox_xmin.text), int(class_bndbox_ymin.text), int(class_bndbox_xmax.text), int(class_bndbox_ymax.text)# print(f"{list_con[1]}, {list_con[2]}, {list_con[3]}, {list_con[4]},{x1_}, {y1_}, {x2_}, {y2_}")# 制定类别if class_name == list_con[0] or list_con[0] == "dle":# 框若有重合 则跳过if is_rectangles_overlap(list_con[1], list_con[2], list_con[3], list_con[4], x1_, y1_, x2_, y2_):print("有重合")print(f"{list_con[1]}, {list_con[2]}, {list_con[3]}, {list_con[4]},{x1_}, {y1_}, {x2_}, {y2_}")con_1 = Trueelse:print("无重合")print(f"{list_con[1]}, {list_con[2]}, {list_con[3]}, {list_con[4]},{x1_}, {y1_}, {x2_}, {y2_}")# print(con_1)if con_1:continuedict_class[class_name.text].append((class_name.text,class_bndbox_xmin.text,class_bndbox_ymin.text,class_bndbox_xmax.text,class_bndbox_ymax.text,))# 保存# 创建根元素root = ET.Element("annotation")folder_save = ET.SubElement(root, "folder")if dict_class["folder"] != "null":folder_save.text = dict_class["folder"]filename_jpg_save = ET.SubElement(root, "filename")if dict_class["filename"] != "null":filename_jpg_save.text = dict_class["filename"]path_save_xml = ET.SubElement(root, "path")if dict_class["path"] != "null":path_save_xml.text = dict_class["path"]# 创建子元素size_save = ET.SubElement(root, "size")# 创建二级子元素 只需输入参数不同即可size_w_save = ET.SubElement(size_save, "width")if dict_class["width"] != "null":size_w_save.text = dict_class["width"]size_h_save = ET.SubElement(size_save, "height")if dict_class["height"] != "null":size_h_save.text = dict_class["height"]size_d_save = ET.SubElement(size_save, "depth")if dict_class["depth"] != "null":size_d_save.text = dict_class["depth"]for ob_class, ob_list in dict_class.items():# print(ob_class, ob_list)if ob_class in ["folder", "filename", "path", "size", "width", "height", "depth"]:continuefor ob_list_i in ob_list:# print(ob_list_i)save_xml_add(ob_list_i[0], ob_list_i[1], ob_list_i[2], ob_list_i[3], ob_list_i[4])# 读取字典内容 添加新的标注if dict_add:for img_size, list_class_xyxy in dict_add.items():for class_xyxy_i in list_class_xyxy:save_xml_add(class_xyxy_i[0], class_xyxy_i[1], class_xyxy_i[2], class_xyxy_i[3], class_xyxy_i[4])# 写入文件# if len(dict_class[ob_class]) != 0:# if ob_class in list_class:path_save_i = os.path.join(path_lab_save, xml_name)# print(path_save_i)# tree.write(path_save_i, encoding="utf-8", xml_declaration=True)with open(path_save_i, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)固定矩形位置生成xml
参数:
import os
import xml.etree.ElementTree as ET
from xml.dom import minidomdef save_xml_add(root, lei_bie_name, xmin, ymin, xmax, ymax):object_elem1 = ET.SubElement(root, "object")ET.SubElement(object_elem1, "name").text = lei_bie_namebndbox1 = ET.SubElement(object_elem1, "bndbox")ET.SubElement(bndbox1, "xmin").text = str(xmin)ET.SubElement(bndbox1, "ymin").text = str(ymin)ET.SubElement(bndbox1, "xmax").text = str(xmax)ET.SubElement(bndbox1, "ymax").text = str(ymax)def create_xml_annotation(image_path, coord1, xml_save_path, size_3, lei_bie_name):root = ET.Element("annotation")folder = os.path.dirname(image_path)ET.SubElement(root, "folder").text = folderfilename = os.path.basename(image_path)ET.SubElement(root, "filename").text = filenamesize = ET.SubElement(root, "size")ET.SubElement(size, "width").text = size_3[0]ET.SubElement(size, "height").text = size_3[1]ET.SubElement(size, "depth").text = size_3[2]for i in coord1:save_xml_add(root, lei_bie_name, i[0], i[1], i[2], i[3])with open(xml_save_path, 'w', encoding='utf-8') as xml_file:# 将 XML 元素树转换为字节串,编码为 utf-8rough_string = ET.tostring(root, 'utf-8')# 使用 minidom 模块解析生成的字节串,得到一个可操作的 XML 对象reparsed = minidom.parseString(rough_string)# 将重新解析后的 XML 对象转换为格式打印(pretty-print)的字符串形式,# 其中 indent=" "表示使用两个空格作为缩进string_ = reparsed.toprettyxml(indent=" ")xml_file.write(string_)print("已保存:", xml_save_path)def xml_save(folder_path, xml_save_path, coord1, size_list, lei_bie_name):for filename in os.listdir(folder_path):if filename.endswith(".jpg"):image_path = os.path.join(folder_path, filename)xml_save_path_name = os.path.join(xml_save_path, os.path.splitext(filename)[0] + ".xml")create_xml_annotation(image_path, coord1, xml_save_path_name, size_list, lei_bie_name)# 图片路径
folder_path = r"E:\zyk_lab\ataset240820\ce\img"
# 保存xml的路径
xml_save_path = r"E:\zyk_lab\ataset240820\ce\xml_ce"
# 绘制坐标
coord1 = [(221, 47, 330, 325)]
# 绘制类别
lei_bie_name = "covered_door"
# 图片分辨率信息
size_list = ["704", "576", "3"]xml_save(folder_path, xml_save_path, coord1, size_list, lei_bie_name)