- host和device:
- host:即CPU,CPU所关联的内存就叫host memory
- device:即GPU,GPU内的内存就叫device memory
- 运行CUDA程序主要有三步:1)host-to-device transfer:将数据从host memory拷到device memory;2)加载GPU程序并执行,将数据缓存到on-chip上读取更快;3)device-to-host transfer:将device memory中的结果拷到host memory
- 【逻辑上】CUDA kernel:就是在GPU上执行的函数
- start with a
__global__declaration specifier - a kernel is executed as a grid of blocks of threads
- start with a
- 【物理上】一个CUDA block在一个SM(streaming multiprocessor)上执行;一个SM可以运行多个并发的CUDA block;一个kernel在一个deivce上执行,一个device上可以同时运行多个kernels。如下图是逻辑和硬件资源的映射关系:

- 其中,SM的基本执单元是包含32个线程的线程数,所以block大小一般设置为32的倍数
- 每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管一个warp中的线程同时从同一程序地址执行,但可能具有不同的行为。比如遇到了分支结构,一些线程可能进入这个分支,但另外一些可能并不用执行,只能进入死等(等待warp内其他未执行完的线程执行完毕),因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。
- CUDA中的index问题
- 几个built-in变量:
gridDim,blockDim用于指示自己的维度;blockIdx,threadIdx用于指示自己在上一层中是第几个。如下图的例子中:gridDim.x=3(表示grid的x维度有3个blocks),gridDim.y=2(grid的y维度有2个blocks)blockDim.x=4(表示block的x维度有4个threads),blockDim.y=3(表示block的y维度有3个threads)blockIdx.x=0, blockIdx.y=1表示的是 block(0, 1)threadIdx.x=2, threadIdx.y=1表示的是 thread(2, 1)

- thread indexing: 为每个thread分配一个唯一的id
- 1D grid of 1D blocks:
threadId = blockIdx.x * blockDim.x + threadIdx.x

- 1D grid of 2D blocks:
threadId = blockIdx.x * blockDim.x * blockDim * y + threadIdx.y * blockDim.x + threadIdx.x;

- 2D grid of 1D blocks:
threadId = blockIdx.y * gridDim.x * blockDim.x + blockIdx.x * blockDim.x + threadIdx.xblockId = blockIdx.y * gridDim.x + blockIdx.xthreadId = blockId * blockDim.x + threadIdx.x

- 2D grid of 2D blocks:
threadId = blockIdx.y * gridDim.x * blockDim.x * blockDim.y + blockIdx.x * blockDim.x * blockDim.y + theadIdx.y * blockDim.x + threadIdx.x

- 总结:二维下,[小Id]就是[小Idx.y]*[大Dim.x]+[小Idx.x],即若位于第n行,前面就有n*上一级列数个,然后再加上是第几列(因为索引值从零开始,所以直接加即可)
- 1D grid of 1D blocks:
- 几个built-in变量:
- GPU存储


上图中:
L1/SMEM:指L1 cache/Shared memory,是每个SM独有的。Shared memory可以由用户写代码进行数据的读写控制,L1则不行;
Read only:只读缓存;
L2 Cache:所有SM都可以访问
Global Memory:全局内存,是所有线程都能访问的内存,也是和CPU内存进行数据传递的地方。通常说的显存就是global memory

每个SM都拥有自己的shared memory,而这些SM们都位于同一块芯片上(on the same chip),这块芯片通过PCB电路连接内存芯片(DRAM)
SP(cuda core、流处理器,一个thread占用一个SP)对shared memory的访问属于片上访问,可以立刻获得数据
SP对内存芯片(DRAM)的访问需要通过请求内存控制器等一系列操作,然后才能得到数据。
下图是一个速度问题:其中s、t、u是本地内存(local memory)中的变量,a、b、c是shared memory中的变量,所以t=s最快

__syncthreads():- 确保这行代码之前,同一个block内的所有线程都完成了各自的工作(如将数据从全局内存加载到了共享内存中)。只同步一个线程块中的线程,其他线程块不受影响
cuda编程模型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/448747.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

python基于大数据的电影市场预测分析
一、摘要
智慧是改变生活和生产的一种来源,那么智慧的体现更大程度上是对于软件技术的改变。当今社会,好的思路,好的创新方式往往是改变人们生活的一种来源。最常见最直接的形式就是各种软件的创始思路,京东因为非典的流行才能够…

【Java知识】java进阶-反射的原理以及实现
文章目录 反射的原理类对象继承图反射的使用注意事项 Java反射机制是Java语言的一个特性,它允许程序在运行时动态地加载、探查、使用编译期间完全未知的类。反射机制使得Java程序可以处理一些在编译时并不确定的类,增加了程序的灵活性。 反射的原理 类的…
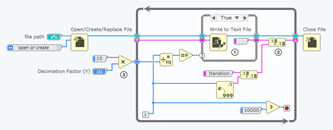
如何提高LabVIEW编程效率
提高LabVIEW编程效率对开发者来说非常重要,尤其是在处理复杂项目或紧迫的开发周期时。以下是一些可以显著提升LabVIEW编程效率的技巧,从代码结构、工具使用到团队协作的多个角度进行详细分析: 1. 模块化设计
模块化设计 是提高代码可维护性和…
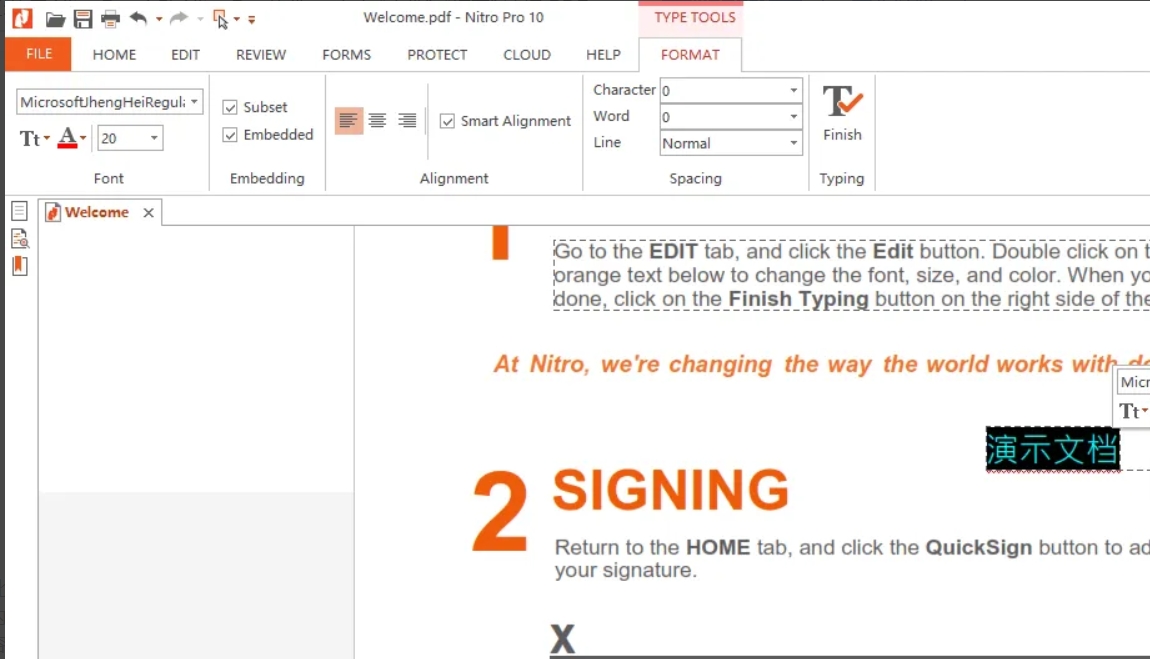
pdf怎么删除多余不想要的页面?删除pdf多余页面的多个方法
pdf怎么删除多余不想要的页面?在日常办公或学习中,我们经常会遇到需要处理PDF文件的情况。PDF文件因其格式稳定、不易被篡改的特点而广受青睐,但在编辑方面却相对不如Word等文档灵活。有时,在接收或创建的PDF文件中,可…

简单介绍$listeners
$listeners
它可以获取父组件传递过来的所有自定义函数,如下:
// 父组件
<template><div class"a"><Child abab"handleAbab" acac"handleAcac"/></div>
</template><script>
impor…

(38)MATLAB分析带噪信号的频谱
文章目录 前言一、MATLAB仿真代码二、仿真结果画图总结 前言
本文给出带噪信号的时域和频域分析,指出频域分析在处理带噪信号时的优势。
首先使用MATLAB生成一段信号,并在信号上叠加高斯白噪声得到带噪信号,然后对带噪信号对其进行FFT变换&…

C语言_字符串+内存函数的介绍
字符函数和字符串函数
本章重点 重点介绍处理字符和字符串的库函数的使用和注意事项 求字符串长度 strlen 长度不受限制的字符串函数 strcpy strcat strcmp 字符串查找 strstr strtok 错误信息报告 strerror 字符操作内存操作函数 memcpy memmove memset memcmp
1. 字…


MOE论文详解(3)-Switch Transformers
Switch Transformers也是google在2022年发表的一篇论文, 该论文简化了MoE的路由算法, 减少了计算量和通信量; 第一次支持bfloat16精度进行训练. 基于T5-Base和T5-Large设计的模型在相同的算力下训练速度提升了7x倍; 同时发布了1.6万亿(1.6 trillion)参数的MoE模型,相…
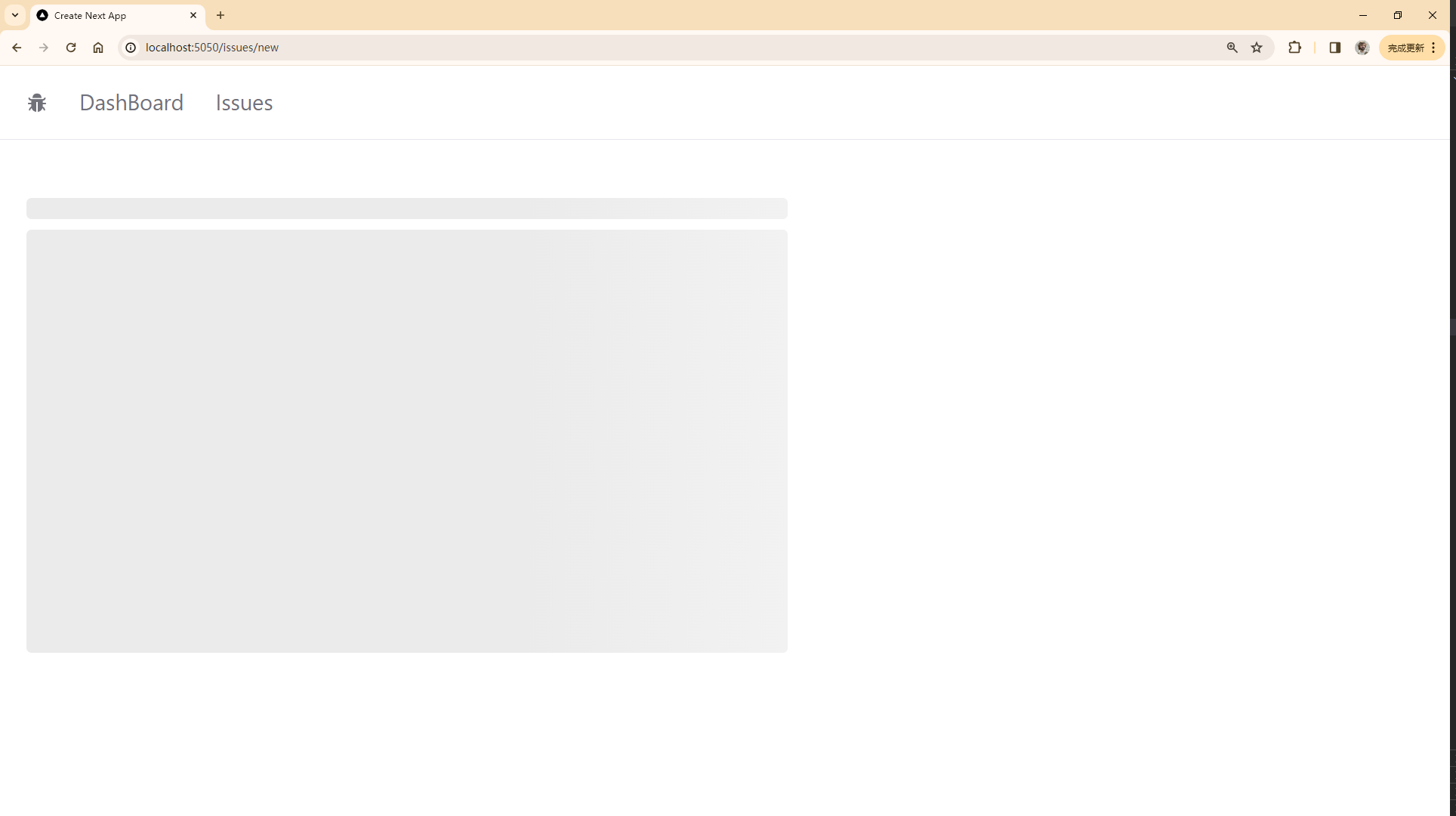
【Next.js 项目实战系列】03-查看 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】02-创建 Issue
查看 Issue
展示 Issue
本节代码链接
首先使用 prisma 获取所有…

【QT】常用控件(二)
个人主页~
常用控件(一)~ 常用控件 三、按钮类控件1、Push Buttonwidget.hwidget.cpp 2、Radio Button3、Check Box 四、显示类控件1、label 三、按钮类控件
1、Push Button
QPushButton继承自QAbstractButton,它是所有按钮的父类
我们从…

线下陪玩导游系统软件源码,家政预约服务源码(h5+小程序+app)
游戏陪玩系统源码陪玩小程序源码搭建基于PHP+MySQL陪玩系统app源码陪玩系统定制开发服务、成品陪玩系统源码
系统基于Nginx或者Apache PHP7.3 数据库mysql5.6
前端为uniapp-vue2.0 后端为thinkphp6
有域名授权加密,其他开源可二开
演示源码下载 开…

Zookeeper快速入门:部署服务、基本概念与操作
文章目录 一、部署服务1.下载与安装2.查看并修改配置文件3.启动 二、基本概念与操作1.节点类型特性总结使用场景示例查看节点查看节点数据 2.文件系统层次结构3.watcher 一、部署服务
1.下载与安装
下载:
一定要下载编译后的文件,后缀为bin.tar.gz
w…

如何匿名浏览网站,保护在线隐私?
在现如今的网络世界,在线隐私已不复存在。你总是被跟踪,即使你使用隐身模式也无济于事。隐身模式会阻止浏览器保存你的浏览历史记录。但它并不能阻止你的互联网服务提供商 (ISP)、雇主、学校、图书馆或你访问的网站看到你在网上做什么。 更有不法分子在未…

CVE-2015-4852 Weblogic T3 反序列化分析
0x01 前言 看到很多师傅的面经里面都有提到 Weblogic 这一个漏洞,最近正好有一些闲暇时间,可以看一看。 因为环境上总是有一些小问题,所以会在本地和云服务器切换着调试0x02 环境搭建
• 太坑了,我的建议是用本地搭建的方法&…

【C语言】一维数组应用Fibonacci数列
Fibonacci数(斐波那契数列) 前两项为1,从第三项开始,每一项为前两项的和。可以知道连续三项的关系:f[i]f[i-1]f[i-2] 使用数组进行存储,十分方便。可以知道前n项的fibonacci数。
#include <stdio.h>…

ios局域网访问主机Xcode配置
前景:
公司业务是做智能家居,所有设备通过主机控制,目前有个产品需求是,在没有外网的情况下依然能够通过局域网控制主机的设备。
IOS开发需要做的:
除了业务代码之外,前提还要配置访问局域网功能。有以下…

诺贝尔经济学奖历史名单数据集(1969-2024年)
2024年诺贝尔经济学奖授予了达龙阿西莫格鲁(Daron Acemoglu)、西蒙约翰逊(Simon Johnson)和詹姆斯A罗宾逊(James A. Robinson),以表彰他们在理解制度如何影响经济发展方面的贡献。(“…

Linux 外设驱动 应用 3 串口
3 串口
3.1 串口原理
串行口是计算机一种常用的接口,具有连接线少,通讯简单,得到广泛的使用。常用的串口是 RS- 232-C接口(又称 EIA RS-232-C)它是在 1970 年由美国电子工业协会(EIA)联合贝尔系统、调制解调器厂家及计算机终端生产厂家共同…

Input-Source-Pro:自动切换输入法并提示状态
Input Source Pro 是一款 macOS 上的输入法辅助工具,它可以根据不同应用、不同网站来自动切换输入法,并可以在鼠标周围显示当前输入法状态。
macOS 不像 Windows 那样能保存输入法状态,因此这样的软件还是挺有用的。
介绍
官网&#x…
最新文章
- 深圳建立企业网站/网络推广网站排名
- 网站开发文档教学/品牌如何推广
- 有限公司 wordpress/英文网站建设
- wordpress密码加密方式/武汉百度搜索优化
- 亳州网站开发公司/辅导机构
- wordpress 离线编辑 mac/论坛seo教程
- 系统压力测试助手——stress-ng
- Ubuntu22.04 LTS 安装nvidia显卡驱动
- RGCL:A Review-aware Graph Contrastive Learning Framework for Recommendation
- 5、mysql的读写分离
- C++版循环安全队列DequeBuffer
- Java中的访问修饰符:分类、作用及应用场景
推荐文章
- LeetCode解法汇总1276. 不浪费原料的汉堡制作方案
- 干货!影视剪辑大神常用避免侵权的8个秘籍首次公开【覃小龙课堂】
- 一篇关于密码学的概念性文章
- #8松桑前端后花园周刊-谷歌推迟cookie弃用、JS Naked Day、Node22、pnpm9.0、Hexo、JSR、html-to-image
- #如何在PDF文件中添加图片和文本框?
- #渗透测试#SRC漏洞挖掘# 操作系统-windows系统bat病毒
- (javaweb)SpringBootWeb案例(毕业设计)案例--部门管理
- (八)k8s实战-身份认证与权限
- (超级详细版)Java基础:Java常用变量详解
- (第69天)可刷新 PDB
- (分享) 英语邮件要点
- (即插即用模块-Attention部分) 二十、(2021) GAA 门控轴向注意力