时间:2020

这篇文章解决的问题
各模态间的语义信息在特征空间是 异构的,这可能会导致以下两个问题:①多模态之间的信息融合不够充分;②模型过于依赖各模态间的信息完整度 (可能有的事件只存在文本信息,而有的事件只存在图片 信息)。
作者如何解决这个问题的
作者提出了MFCD模型,该模型框架由三部分组成:纯文本模型Textual、纯图片模型Visual、深度特征级融合模型FFM
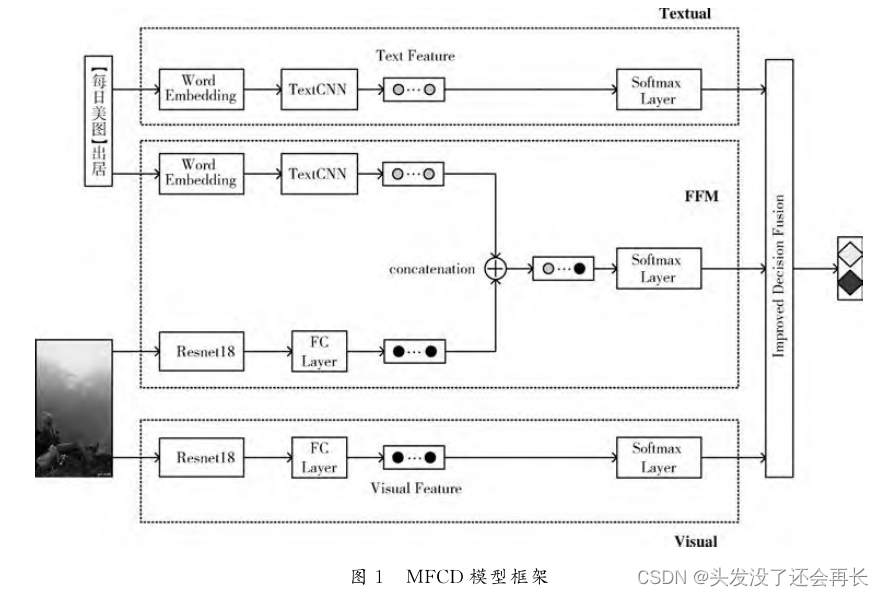
对于问题一的解决方式:
使用TextCNN编码文本内容,使用Resnet编码图片内容,然后将两者的语义映射进行特征级融合,得到深度特征级融合模型FFM。最后将三个模型的最终决策输入到决策级融合层得到最终的决策结果。这样就挖掘了各个模特的特征进行融合
对于问题二的解决方式:
作者加入了决策级融合,对于缺失某个模态的信息的文章,只采用已有的模特进行特征融合,而不使用填充发方式融合所有模态信息,这样模型就避免了因某个模态信息缺失而影响到最终模型的分类结果。
公式:
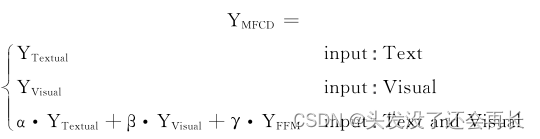
这个问题的解决有什么亮点,局限
亮点:作者加入了决策级融合,避免了某个模态不存在的时候,用填充法对最后的结果造成影响
局限:没有考虑各模态间的互补效果
未来方向:如何构建更加 高效合理的特征级融合方案,进一步剔除冗余信息,提高 各模态间的信息互补能力。