Redis数据类型
Redis 常用的数据类型有哪些?
Redis 中比较常见的数据类型有下面这些:
- 5 种基础数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- 3 种特殊数据类型:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
除了上面提到的之外,还有一些其他的比如 Bloom filter(布隆过滤器)、Bitfield(位域)。
String 的应用场景有哪些?
String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
String 的常见应用场景如下:
- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
- 分布式锁(利用
SETNX key value命令可以实现一个最简易的分布式锁);
购物车信息用 String 还是 Hash 存储更好呢?
- 用户 id 为 key
- 商品 id 为 field,商品数量为 value
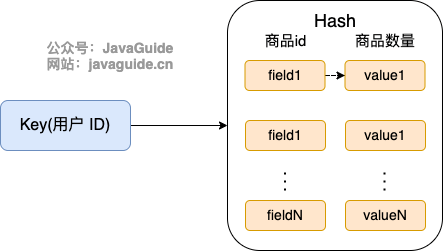
那用户购物车信息的维护具体应该怎么操作呢?
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/database/redis/redis-questions-01.html
- 用户添加商品就是往 Hash 里面增加新的 field 与 value;
- 查询购物车信息就是遍历对应的 Hash;
- 更改商品数量直接修改对应的 value 值(直接 set 或者做运算皆可);
- 删除商品就是删除 Hash 中对应的 field;
- 清空购物车直接删除对应的 key 即可。
String 还是 Hash 存储对象数据更好呢?
简单对比一下二者:
- 对象存储方式:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
- 内存消耗:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
- 复杂对象存储:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
- 性能:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
总结:
- 在绝大多数情况下,String 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
- 如果你需要频繁操作对象的部分字段或节省内存,Hash 可能是更好的选择
String 的底层实现是什么?
Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 \0 结尾的字符数组),而是自己编写了 SDS(Simple Dynamic String,简单动态字符串) 来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
Simple Dynamic String(SDS)是一个用于C语言的高级字符串库,由Antirez开发。SDS旨在提供一个简单、高效的动态字符串处理方式,以替代C标准库中的字符串处理函数。以下是对SDS的详细介绍:
一、SDS概述
SDS,即Simple Dynamic String,是一种动态字符串类型,其内存分配是动态的。与C语言中的普通字符串(char*)不同,SDS是二进制安全的,并不以'\0'来标识字符串结尾,而是使用一个len字段来标记字符串的长度。因此,SDS字符串是由“字符串长度”和“字符数组”组成的。
二、SDS存储结构
SDS字符串在Redis中的存储结构包括一个头部(sdshdr)和一个字节数组(buf)。头部中包含了字符串的长度(len)、已分配的空间(alloc)以及一个标志位(flags)等信息。为了适应不同长度的字符串,SDS头部设计了多种结构,分别适应长度在各自范围内的字符串。这些结构包括sdshdr5、sdshdr8、sdshdr16、sdshdr32和sdshdr64,其中末尾数字对应的是2的次幂,表示该结构能表示的最大字符串长度。
三、SDS优势
- 常数复杂度获取字符串长度:由于SDS在头部中直接存储了字符串的长度,因此可以在常数时间内获取字符串的长度,而C语言中的字符串则需要遍历整个字符串才能获取长度。
- 杜绝缓冲区溢出:SDS的空间分配策略完全杜绝了发生缓冲区溢出的可能性。当需要对SDS进行修改时,SDS API会先检查空间是否足够,如果不足够则会自动扩展空间至所需大小。
- 减少内存重分配次数:SDS实现了空间预分配和惰性空间释放两种优化策略。空间预分配用于优化SDS字符串增长操作,当SDS进行修改时,不仅会分配所需的空间,还会分配额外的未使用空间。惰性空间释放则用于优化SDS缩短操作,当需要缩短SDS保存的字符串时,程序并不立即回收缩短后多出来的字节,而是等待将来使用。
- 二进制安全:SDS的API都是二进制安全的,可以处理任意数据,包括图片、音频、视频等二进制数据。
- 兼容部分C字符串函数:Redis和C一样遵循C字符串以空字符结尾的惯例,因此SDS可以在有需要时重用<string.h>函数库中的部分函数。
Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?
这道面试题很多大厂比较喜欢问,难度还是有点大的。
- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 O(log n)。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
- B+树 vs 跳表:B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并
Set 的应用场景是什么?
Redis 中 Set 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。
Set 的常见应用场景如下:
- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是
HyperLogLog更适合一些)、文章点赞、动态点赞等等。 - 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。