亚马逊某个分类商品的页面
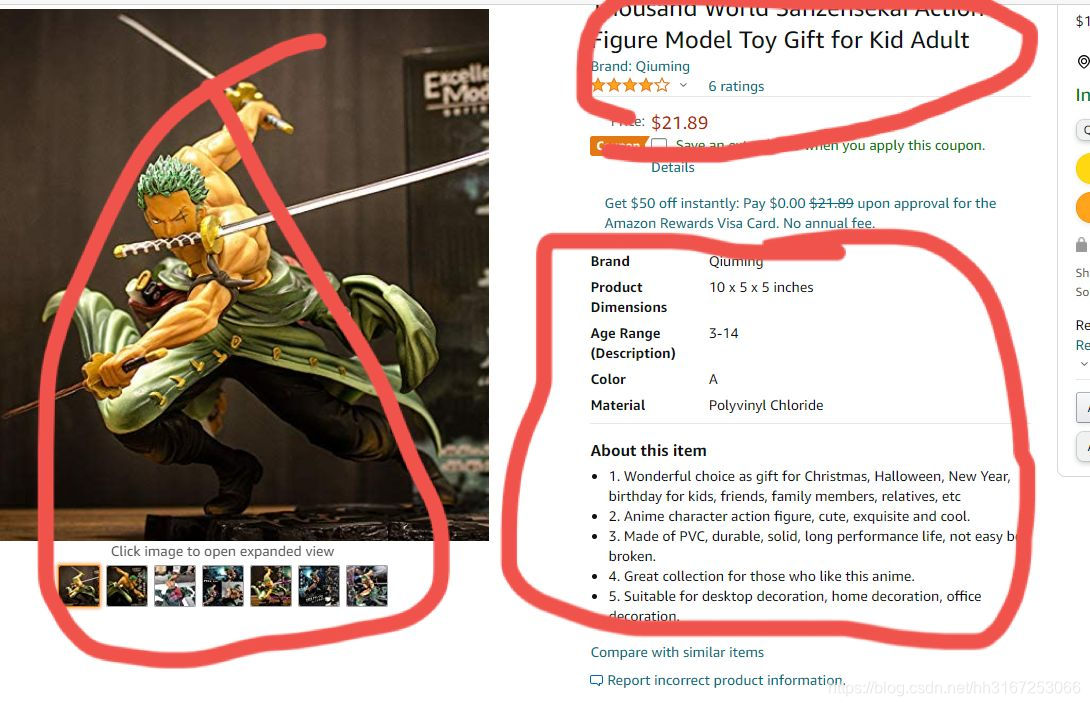
- 一开始肯定就是只试试这一个页面,看看能不能请求到
- 刚开始不知道反爬做的好不好,就简单的加个User-Agent,果然不行,爬到的网页是让输入验证码的网页。
- 然后就是用session, 再加上cookie,咦!竟然成功爬到了。
- 再就是分析页面链接了,进行分页,发现只改个url就好了

i 为for循环的数字
“https://www.amazon.com/s?k=anime+figure+one+piece&page=“ + i
- 改完开始分页爬取。咦!竟然还能爬到,发现原来是点击下一页的时候cookie一点都不变。于是就拿到了所有商品的url.
代码
import requests
import json
from lxml import etreedef load_cookies():cookie_json = {}try:with open('export.json', 'r') as cookies_file:cookie_json = json.load(cookies_file)except:print("Json load failed")finally:return cookie_jsondef main():page_list = []for i in range(1, 8):agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"headers = {"HOST": "www.amazon.com/s?k=anime+figure+one+piece","Referer": "https://www.amazon.com/s?k=anime+figure+one+piece","User-Agent": agent}session = requests.session()session.headers = headersrequests.utils.add_dict_to_cookiejar(session.cookies, load_cookies())url = "https://www.amazon.com/s?k=anime+figure+one+piece&page=%d" % iresponse = session.get(url)print(response.text[:300])# with open("test.html", "wb") as f:# f.write(response.text.encode('utf-8'))page_text = response.texttree = etree.HTML(page_text)a_list = tree.xpath('//a[@class="a-link-normal a-text-normal"]/@href')# print(a_list)#for j in a_list:page_url = "https://www.amazon.com" + jpage_list.append(page_url)print("Done")print(page_list)for k in page_list:with open("page02.txt", "a+") as f:f.write(k + "\r")if __name__ == '__main__':main()
另外coookie封装到了一个cookie.py文件里,以下cookie有删改
import jsondef save_cookies(cookies):cookies_file = 'export.json'with open(cookies_file, 'w') as f:json.dump(cookies, f)def main():cookies = {"ad-privacy": "0","ad-id": "A5d94GSIhp6aw774YK1k","i18n-prefs": "USD","ubid-main": "138-2864646","session-id-time": "20887201l","sst-main": "Sst1|PQHBhLoYbd9ZEWfvYwULGppMCd6ESJYxmWAC3tFvsK_7-FgrCJtViwGLNnJcPk6NS08WtWl7f_Ng7tElRchY70dGzOfHe6LfeLVA2EvS_KTJUFbqiKQUt4xJcjOsog_081jnWYQRp5lAFHerRS0K30zO4KWlaGuxYf-GlWHrIlX0DCB0hiuS4F69FaHInbcKlPZphULojbSs4y3YC_Z2098BiZK5mzna84daFvmQk7GS1uIEV9BJ-7zXSaIE1i0RnRBqEDqCw","sess-at-main": "7B9/7TbljVmxe9FQP8pj4/TirM4hXdoh0io=","at-main": "Atza|IwEBICsAvrvpljvBn6U0aVHZtVAdHNTj8I9XMXpj0_akGclan8n4it62oe4MadfnSheGBfJeVJwRmrV41ZbllH48hNM32FGo4DJGoeXE01gDei-_2PGNH3jKU79B8rzg8MaHRootDMSwFmj4vNmPtnvl6qrbfZoPSmey12IuWq9ijSx3MuCbpJ2wt4Sp7ixf7jWHW6VfaZ849AJkOBDonSHp9o","sp-cdn": "L5Z:CN","session-id": "141-56579-5761416","x-main": "2XkJe2ehs13TDTsRlELJt12FINPkJSfDKLuc5XjGgy2akeyGa45?wYKN4wcIC","session-token": "HfpLyDT70a2q+Ktd9sYUopKOKUeQndXMlbDcwP8sQNGA/ZeUA9ZNGNXOPRvXV8E6pUjeI7j/RR9iDCr5S7W0sRLmHT27PAvbN3TXsyaLvvPhsn4e3hUvhgdJn/xK/BfioKniukounAKZnYZLNcGf44ZiX8sRfdIjOiOx9GvAvl+hnPfJmWi/l73tqO6/G+PPf8uc0vq7Xubsgw2SuSXzqwq0gHEtE6HcbA6AeyyE59DCuH+CdV3p2mVSxUcvmF+ToO6vewLuMl1Omfc+tQ==","lc-main": "en_US",# "csm-hit": "tb:s-YM0DR0KTNG964PT0RMS0|1627973759639&t:1627973760082&adb:adblk_no"# "csm-hit": "tb:s-K3VN7V41Z5H7N250A9NE|1627974200332&t:1627974200622&adb:adblk_no""csm-hit": "tb:6CJBWDDJGRZPB09G+b-K3VN7V41Z5H7N250A9NE|1627974443&t:1627974446683&adb:adblk_no"}save_cookies(cookies)if __name__ == '__main__':main()
- 爬到了url就很晚了,本来想着原来那么简单,再对每个url加上cookie再一爬取页面,xpath一解析就完事了,先睡觉喽。
- 第二天上午继续做,发现事情果然没那么简单。对每个商品进行爬取时cookie也对应着变,每一次请求都会发现cookie中
csm-hit字段的值都会变。而且不知为何昨天晚上弄得那个代码也爬不到了。崩了。但是肯定还是有办法的。 - 没错,就是selenium。自动化操作,一个一个请求页面url,获取页面详细信息也挺香的,还不用输cookie啥的。
- 先把昨天的url重新获取。(用无头化发现获取不全url,于是就注释掉了)
from selenium import webdriver
from time import sleep
from lxml import etree
# # 实现无可视化界面
# from selenium.webdriver.chrome.options import Options
# # 实现规避检测
# from selenium.webdriver import ChromeOptions
# # 实现无可视化界面的操作
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# # 实现规避检测
# option = ChromeOptions()
# option.add_experimental_option('excludeSwitches', ['enable-automation'])# , chrome_options=chrome_options, options=optiondriver = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')sleep(2)
for i in range(1, 8):url = "https://www.amazon.com/s?k=anime+figure+one+piece&page=" + str(i)try:driver.get(url)page_list = []page_text = driver.page_sourcetree = etree.HTML(page_text)a_list = tree.xpath('//a[@class="a-link-normal a-text-normal"]/@href')for j in a_list:page_url = "https://www.amazon.com" + jpage_list.append(page_url)for k in page_list:with open("page02.txt", "a") as f:f.write(k + "\r")sleep(2)print(str(i) + " ok")except:print(str(i) + " eroor")continue- 因为要英文的商品标题和介绍,在爬取商品详情前要先把美国的邮编输上去,就会自动改成英文的。当然自动化来搞了,定位定位click,再输入就完事了。
- 问题又来了,这图片咋获取呀,获取到的都是40*40的图片,根本看不清楚。不过是问题总能解决的。
- 分析html页面,高清的图片在这个高亮的li标签里,但是只有这一个高清的图片。

- 不过仔细搞下,发现当我鼠标在这图片上一经过

- 下面的li标签立刻就多了起来,在一个个打开,发现果然是高清的图片

- 于是就有办法了,我可以在每次获取页面的html详情前都先把这图片都点击一下,然后再获取页面html信息,再进行xpath解析,再对获取到的标题,介绍,价格进行写入文件的操作就行了,于是就OK了。
from selenium import webdriver
from time import sleep
from lxml import etree
import os
import requestsheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
driver = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')driver.get("https://www.amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_atf_aps_sr_pg1_1?ie=UTF8&adId=A08238052EFHH6KXIQA1O&url=%2FAnime-Cartoon-Figure-Character-Model-Toy%2Fdp%2FB094QMYVNV%2Fref%3Dsr_1_1_sspa%3Fdchild%3D1%26keywords%3Danime%2Bfigure%2Bone%2Bpiece%26qid%3D1627911157%26sr%3D8-1-spons%26psc%3D1&qualifier=1627911157&id=1439730895405084&widgetName=sp_atf")
button = driver.find_element_by_xpath('//a[@class="nav-a nav-a-2 a-popover-trigger a-declarative nav-progressive-attribute"]')
button.click()
sleep(2)input = driver.find_element_by_id('GLUXZipUpdateInput')
input.send_keys("75159")
sleep(1)
button_set = driver.find_element_by_id('GLUXZipUpdate')
button_set.click()
sleep(2)
# button_close = driver.find_element_by_id('GLUXConfirmClose-announce')
# sleep(2)page_list = []
with open("page02.txt", "r") as f:for i in range(0, 368):t = f.readline()page_list.append(t[0:-1])
i = 1for url in page_list:try:# ls = []sleep(2)driver.get(url)# page_text = driver.page_source# # print(page_text)# tree = etree.HTML(page_text)sleep(2)# imgfor p in range(4, 13):try:xpath_1 = format('//li[@class="a-spacing-small item imageThumbnail a-declarative"]/span/span[@id="a-autoid-%d"]' % p)min_img = driver.find_element_by_xpath(xpath_1)min_img.click()except:continuepage_text = driver.page_sourcetree = etree.HTML(page_text)max_img_list = tree.xpath('//ul[@class="a-unordered-list a-nostyle a-horizontal list maintain-height"]//div[@class="imgTagWrapper"]/img/@src')# print(max_img_list)# titletitle_list = tree.xpath('//span[@class="a-size-large product-title-word-break"]/text()')[0]# print(title_list[8:-7])title = title_list[8: -7]# priceprice_list = tree.xpath('//span[@class="a-size-medium a-color-price priceBlockBuyingPriceString"]/text()')# print(price_list[0])price = price_list[0]# itemitem_title = tree.xpath('//table[@class="a-normal a-spacing-micro"]/tbody/tr/td[@class="a-span3"]/span/text()')item_con = tree.xpath('//table[@class="a-normal a-spacing-micro"]/tbody/tr/td[@class="a-span9"]/span/text()')# print(item_title)# print(item_con)item_list = []for k in range(len(item_title)):item_list.append(item_title[k] + " -:- " + item_con[k])# print(item_list)# about# about_title = tree.xpath('//div[@class="a-section a-spacing-medium a-spacing-top-small"]/h1[@class="a-size-base-plus a-text-bold"]/text()')about_li = tree.xpath('//div[@class="a-section a-spacing-medium a-spacing-top-small"]/ul/li/span[@class="a-list-item"]/text()')# about_title_str = about_title[0][2:-2]# print(about_li[2:])# 文件夹路径path = "./data4/" + str(i)if not os.path.exists(path):os.mkdir(path)# print(path)# txt文件路径path_txt = path + "/" + str(i) + ".txt"with open(path_txt, "a") as f:f.write(title + "\r")f.write(price + "\r")for p in item_list:with open(path_txt, "a+") as f:# f.write("\r")f.write(p + "\r")for o in about_li:with open(path_txt, "a+", encoding="utf8") as f:f.write(o)for d in max_img_list:img_data = requests.get(url=d, headers=headers).contentimg_path = path + "/" + str(i) + d.split("/")[-1]with open(img_path, 'wb') as fp:fp.write(img_data)print(str(i) + " OK")i = i + 1except:sleep(2)i = i + 1print(str(i) + "error")continuesleep(10)
driver.quit()
注意:一定要先进行点击那几张图片,再获取html页面源码,否则解析不到那几张高清图片。
成果展示
每个商品都建了个文件夹
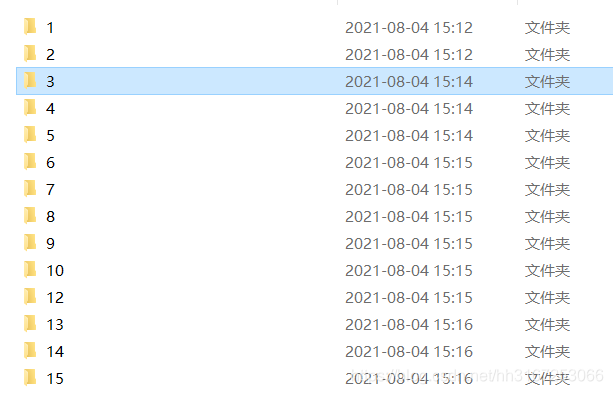
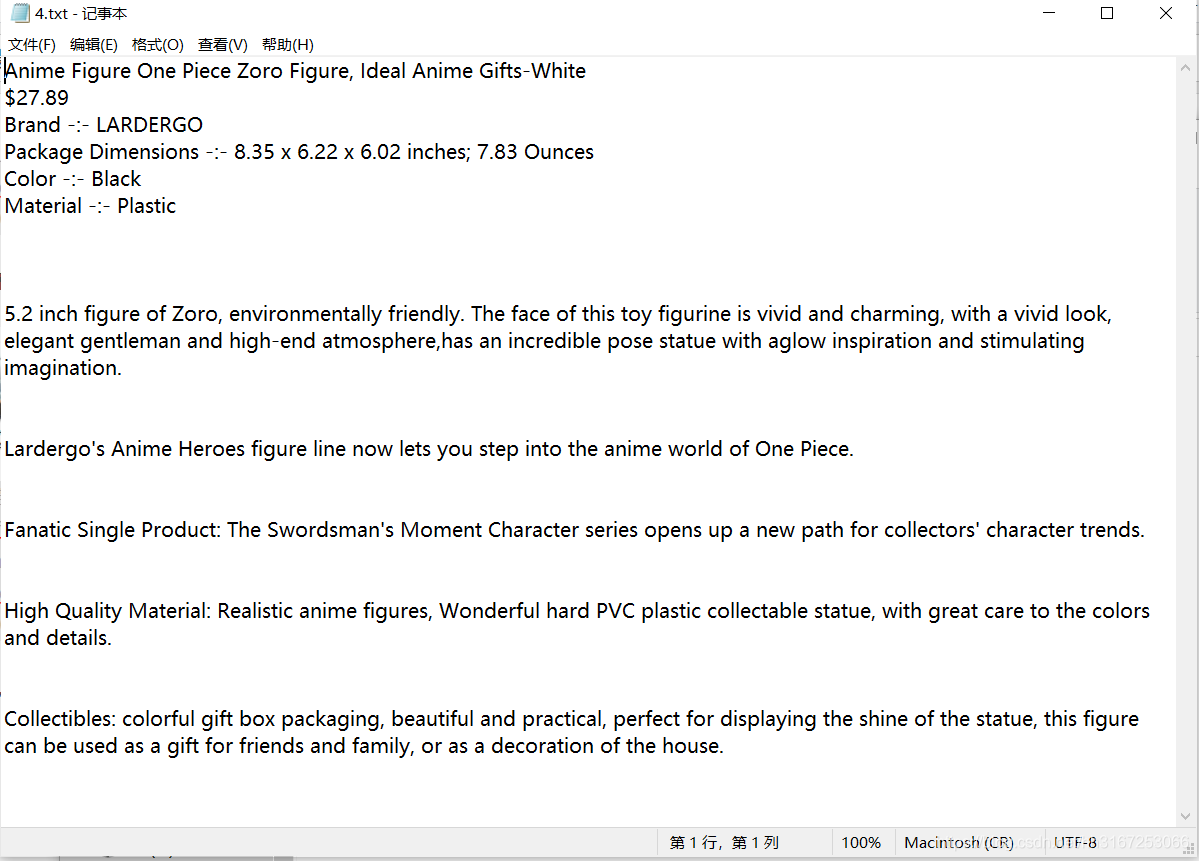
里面有个txt文件,和所有图片

txt文件里就是标题,价格,详细描述了
over! over!


![[R语言]手把手教你如何绘图(万字)](https://img-blog.csdnimg.cn/img_convert/c76c1058d2825fedeb2301666ca431e0.png)