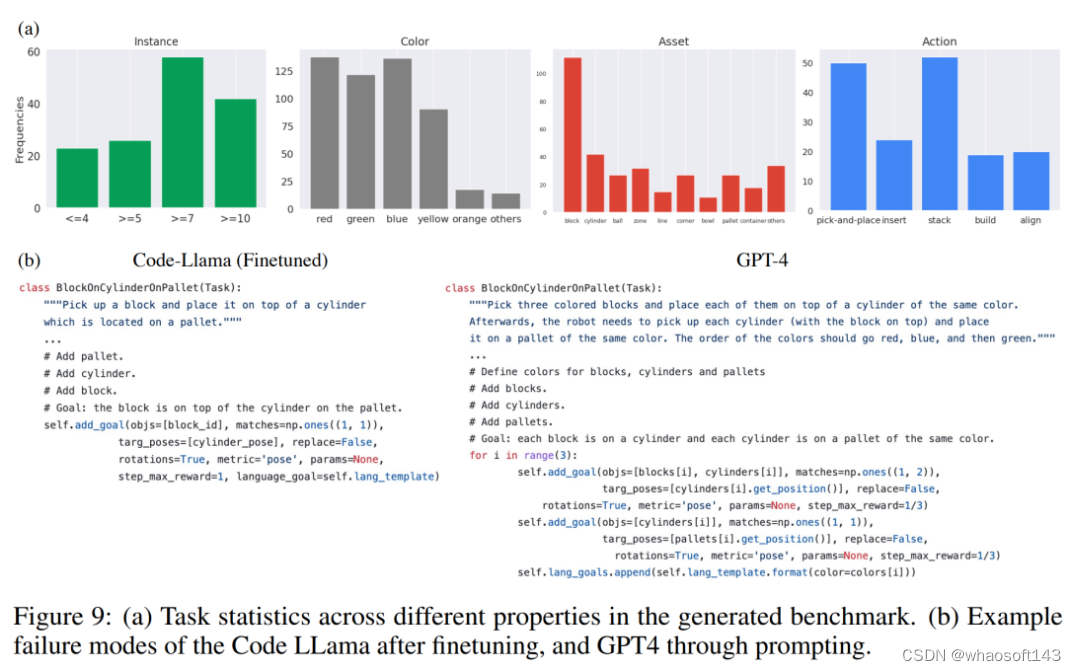
我自己的原文哦~ https://blog.51cto.com/whaosoft/12286799
# Attention as an RNN
Bengio等人新作:注意力可被视为RNN,新模型媲美Transformer,但超级省内 , 既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?
序列建模的进展具有极大的影响力,因为它们在广泛的应用中发挥着重要作用,包括强化学习(例如,机器人和自动驾驶)、时间序列分类(例如,金融欺诈检测和医学诊断)等。
在过去的几年里,Transformer 的出现标志着序列建模中的一个重大突破,这主要得益于 Transformer 提供了一种能够利用 GPU 并行处理的高性能架构。
然而,Transformer 在推理时计算开销很大,主要在于内存和计算需求呈二次扩展,从而限制了其在低资源环境中的应用(例如,移动和嵌入式设备)。尽管可以采用 KV 缓存等技术提高推理效率,但 Transformer 对于低资源领域来说仍然非常昂贵,原因在于:(1)随 token 数量线性增加的内存,以及(2)缓存所有先前的 token 到模型中。在具有长上下文(即大量 token)的环境中,这一问题对 Transformer 推理的影响更大。
为了解决这个问题,加拿大皇家银行 AI 研究所 Borealis AI、蒙特利尔大学的研究者在论文《Attention as an RNN 》中给出了解决方案。值得一提的是,我们发现图灵奖得主 Yoshua Bengio 出现在作者一栏里。
- 论文地址:https://arxiv.org/pdf/2405.13956
- 论文标题:Attention as an RNN
具体而言,研究者首先检查了 Transformer 中的注意力机制,这是导致 Transformer 计算复杂度呈二次增长的组件。该研究表明注意力机制可以被视为一种特殊的循环神经网络(RNN),具有高效计算的多对一(many-to-one)RNN 输出的能力。利用注意力的 RNN 公式,该研究展示了流行的基于注意力的模型(例如 Transformer 和 Perceiver)可以被视为 RNN 变体。
然而,与 LSTM、GRU 等传统 RNN 不同,Transformer 和 Perceiver 等流行的注意力模型虽然可以被视为 RNN 变体。但遗憾的是,它们无法高效地使用新 token 进行更新。
为了解决这个问题,该研究引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出,从而实现高效的更新。
在此新注意力公式的基础上,该研究提出了 Aaren([A] ttention [a] s a [re] current neural [n] etwork),这是一种计算效率很高的模块,不仅可以像 Transformer 一样并行训练,还可以像 RNN 一样高效更新。
实验结果表明,Aaren 在 38 个数据集上的表现与 Transformer 相当,这些数据集涵盖了四种常见的序列数据设置:强化学习、事件预测、时间序列分类和时间序列预测任务,同时在时间和内存方面更加高效。
方法介绍
为了解决上述问题,作者提出了一种基于注意力的高效模块,它能够利用 GPU 并行性,同时又能高效更新。
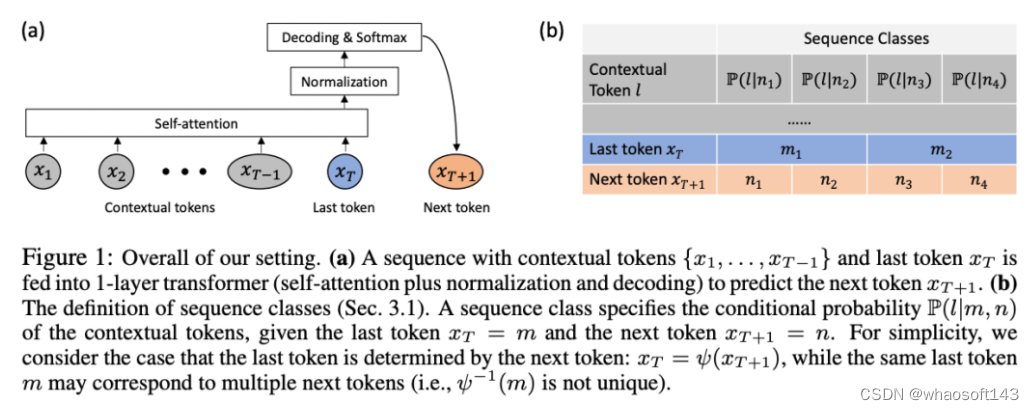
首先,作者在第 3.1 节中表明,注意力可被视为一种 RNN,具有高效计算多对一 RNN(图 1a)输出的特殊能力。利用注意力的 RNN 形式,作者进一步说明,基于注意力的流行模型,如 Transformer(图 1b)和 Perceiver(图 1c),可以被视为 RNN。然而,与传统的 RNN 不同的是,这些模型无法根据新 token 有效地更新自身,从而限制了它们在数据以流的形式到达的序列问题中的潜力。
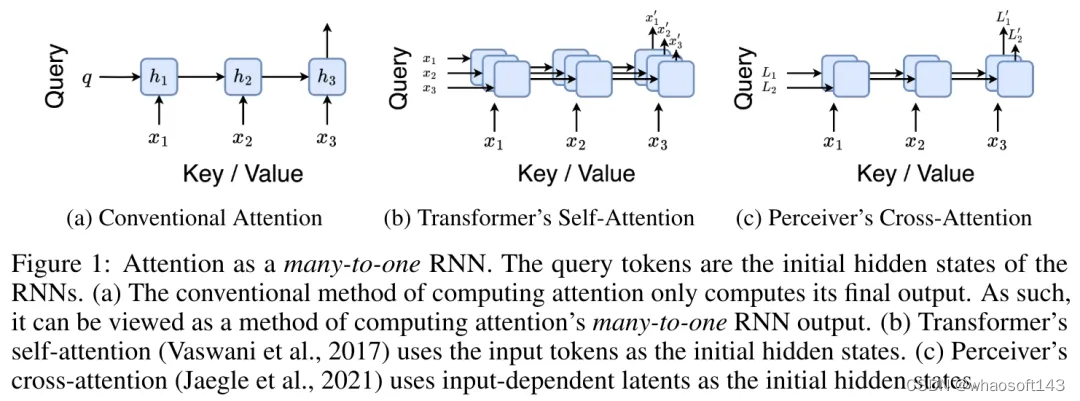
为了解决这个问题,作者在第 3.2 节中介绍了一种基于并行前缀扫描算法的多对多 RNN 计算注意力的高效方法。在此基础上,作者在第 3.3 节中介绍了 Aaren—— 一个计算效率高的模块,它不仅可以并行训练(就像 Transformer),还可以在推理时用新 token 高效更新,推理只需要恒定的内存(就像传统 RNN)。
将注意力视为一个多对一 RNN

通过从 a_(k-1)、c_(k-1) 和 m_(k-1) 对 a_k、c_k 和 m_k 的循环计算进行封装,作者引入了一个 RNN 单元,它可以迭代计算注意力的输出(见图 2)。注意力的 RNN 单元以(a_(k-1), c_(k-1), m_(k-1), q)作为输入,并计算(a_k, c_k, m_k, q)。注意,查询向量 q 在 RNN 单元中被传递。注意力 RNN 的初始隐藏状态为 (a_0, c_0, m_0, q) = (0, 0, 0, q)。
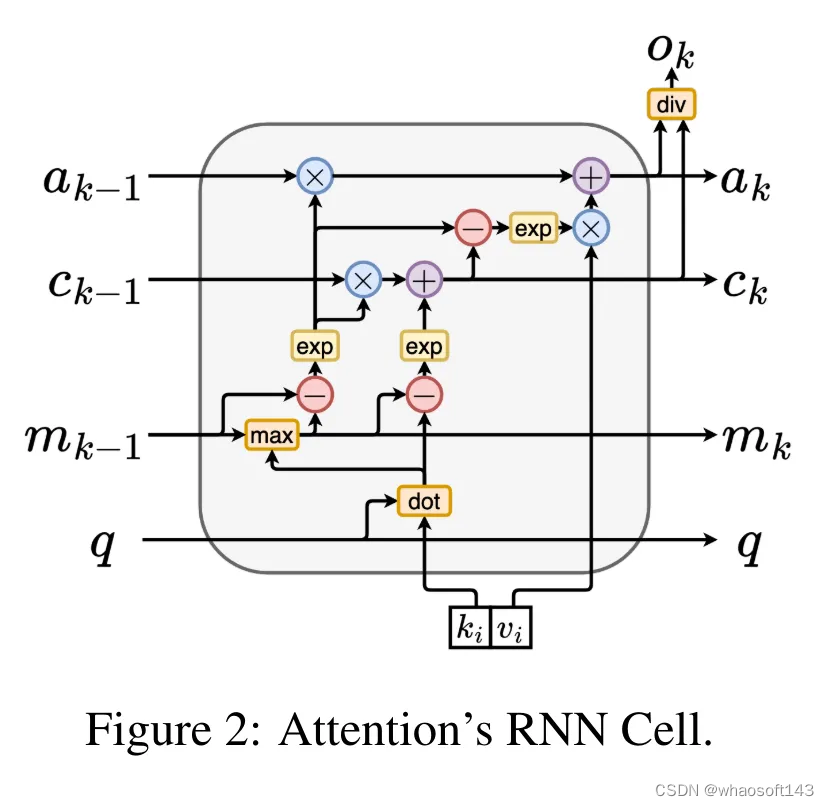
计算注意力的方法:通过将注意力视为一个 RNN,可以看到计算注意力的不同方法:在 O (1) 内存中逐个 token 循环计算(即顺序计算);或以传统方式计算(即并行计算),需要线性 O (N) 内存。由于注意力可以被看作是一个 RNN,因此计算注意力的传统方法也可以被看作是计算注意力多对一 RNN 输出的高效方法,即 RNN 的输出以多个上下文 token 为输入,但在 RNN 结束时只输出一个 token(见图 1a)。最后,也可以将注意力计算为一个逐块处理 token 的 RNN,而不是完全按顺序或完全并行计算,这需要 O (b) 内存,其中 b 是块的大小。
将现有的注意力模型视为 RNN。通过将注意力视为 RNN,现有的基于注意力的模型也可以被视为 RNN 的变体。例如,Transformer 的自注意力是 RNN(图 1b),上下文 token 是其初始隐藏状态。Perceiver 的交叉注意力是 RNN(图 1c),其初始隐藏状态是与上下文相关的潜变量。通过利用其注意力机制的 RNN 形式,这些现有模型可以高效地计算其输出存储。
然而,当将现有的基于注意力的模型(如 Transformers)视为 RNN 时,这些模型又缺乏传统 RNN(如 LSTM 和 GRU)中常见的重要属性。
值得注意的是,LSTM 和 GRU 能够仅在 O (1) 常量内存和计算中使用新 token 有效地更新自身,相比之下, Transformer 的 RNN 视图(见图 1b)会通过将一个新的 token 作为初始状态添加一个新的 RNN 来处理新 token。这个新的 RNN 处理所有先前的 token,需要 O (N) 的线性计算量。
在 Perceiver 中,由于其架构的原因,潜变量(图 1c 中的 L_i)是依赖于输入的,这意味着它们的值在接收新 token 时会发生变化。由于其 RNN 的初始隐藏状态(即潜变量)发生变化,Perceiver 因此需要从头开始重新计算其 RNN,需要 O (NL) 的线性计算量,其中 N 是 token 的数量,L 是潜变量的数量。
将注意力视为一个多对多 RNN


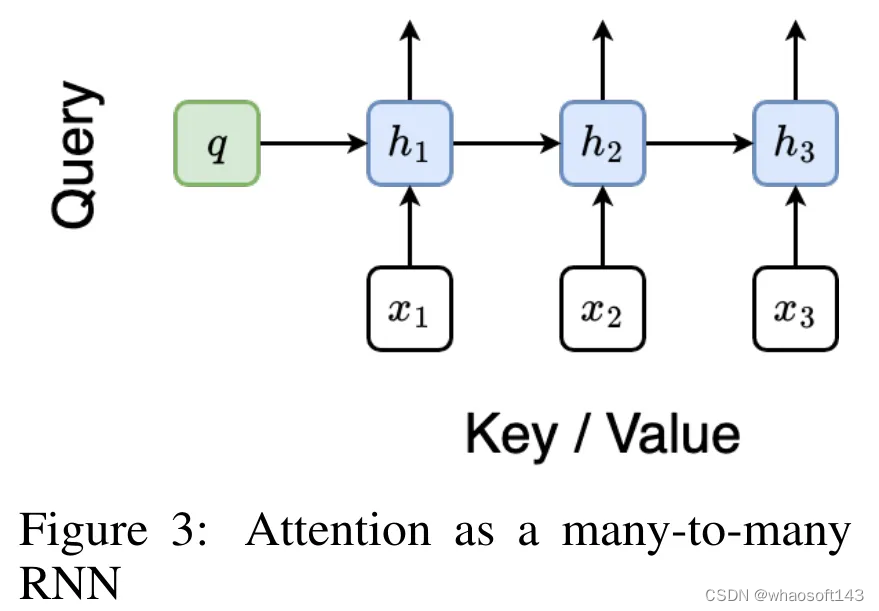
Aaren:[A] ttention [a] s a [re] current neural [n] etwork
Aaren 的接口与 Transformer 相同,即将 N 个输入映射到 N 个输出,而第 i 个输出是第 1 到第 i 个输入的聚合。此外,Aaren 还自然可堆叠,并且能够计算每个序列 token 的单独损失项。然而,与使用因果自注意力的 Transformers 不同,Aaren 使用上述计算注意力的方法作为多对多 RNN,使其更加高效。Aaren 形式如下:
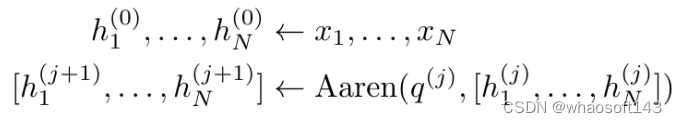
与 Transformer 不同,在 Transformer 中查询是输入到注意力的 token 之一,而在 Aaren 中,查询 token q 是在训练过程中通过反向传播学习得到的。
下图展示了一个堆叠 Aaren 模型的例子,该模型的输入上下文 token 为 x_1:3,输出为 y_1:3。值得注意的是,由于 Aaren 利用了 RNN 形式的注意力机制,堆叠 Aarens 也相当于堆叠 RNN。因此,Aarens 也能够高效地用新 token 进行更新,即 y_k 的迭代计算仅需要常量计算,因为它仅依赖于 h_k-1 和 x_k。

基于 Transformer 的模型需要线性内存(使用 KV 缓存时)并且需要存储所有先前的 token ,包括中间 Transformer 层中的那些,但基于 Aaren 的模型只需要常量内存,并且不需要存储所有先前的 token ,这使得 Aarens 在计算效率上显著优于 Transformer。
实验
实验部分的目标是比较 Aaren 和 Transformer 在性能和所需资源(时间和内存)方面的表现。为了进行全面比较,作者在四个问题上进行了评估:强化学习、事件预测、时间序列预测和时间序列分类。
强化学习
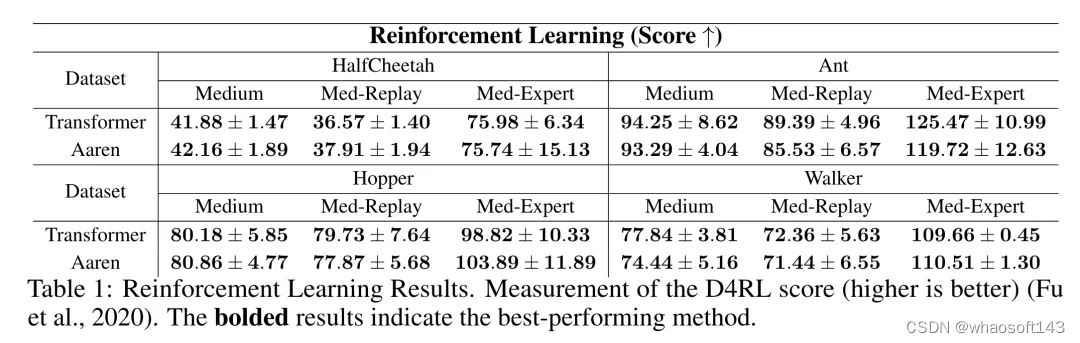
作者首先比较了 Aaren 和 Transformer 在强化学习方面的表现。强化学习在机器人、推荐引擎和交通控制等交互式环境中很受欢迎。
表 1 中的结果表明,在所有 12 个数据集和 4 种环境中,Aaren 与 Transformer 的性能都不相上下。不过,与 Transformer 不同的是,Aaren 也是一种 RNN,因此能够在持续计算中高效处理新的环境交互,从而更适合强化学习。
事件预测
接下来,作者比较了 Aaren 和 Transformer 在事件预测方面的表现。事件预测在许多现实环境中都很流行,例如金融(如交易)、医疗保健(如患者观察)和电子商务(如购买)。
表 2 中的结果显示,Aaren 在所有数据集上的表现都与 Transformer 相当。Aaren 能够高效处理新输入,这在事件预测环境中尤为有用,因为在这种环境中,事件会以不规则流的形式出现。

时间序列预测
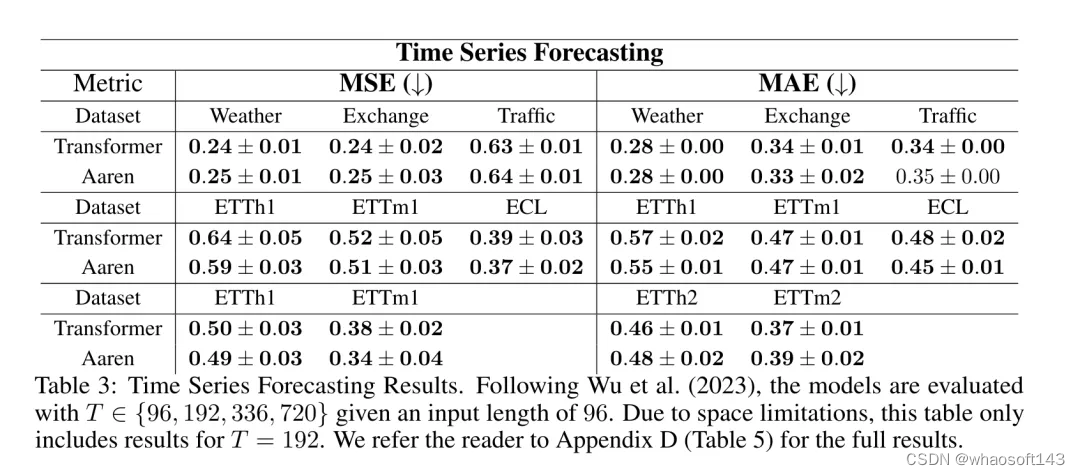
然后,作者比较了 Aaren 和 Transformer 在时间序列预测方面的表现。时间序列预测模型通常用在与气候(如天气)、能源(如供需)和经济(如股票价格)相关的领域。
表 3 中的结果显示,在所有数据集上,Aaren 与 Transformer 的性能相当。不过,与 Transformer 不同的是,Aaren 能高效处理时间序列数据,因此更适合与时间序列相关的领域。
时间序列分类
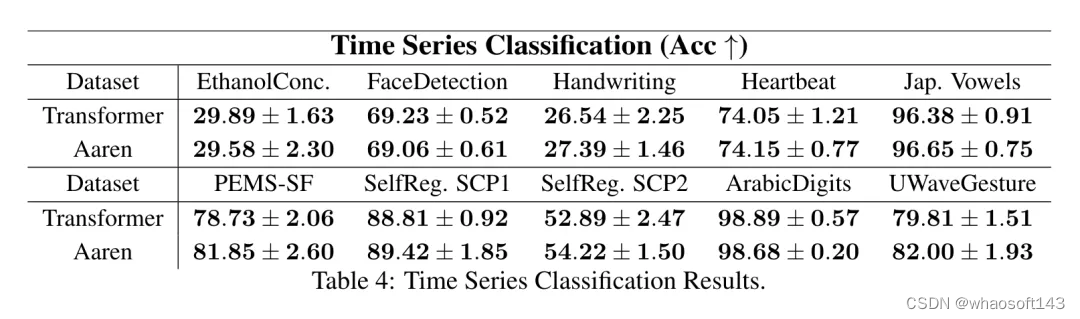
接下来,作者比较了 Aaren 和 Transformer 在时间序列分类方面的表现。时间序列分类在许多重要的应用中很常见,例如模式识别(如心电图)、异常检测(如银行欺诈)或故障预测(如电网波动)。
从表 4 中可以看出,在所有数据集上,Aaren 与 Transformer 的表现不相上下。
分析
最后,作者比较了 Aaren 和 Transformer 所需的资源。
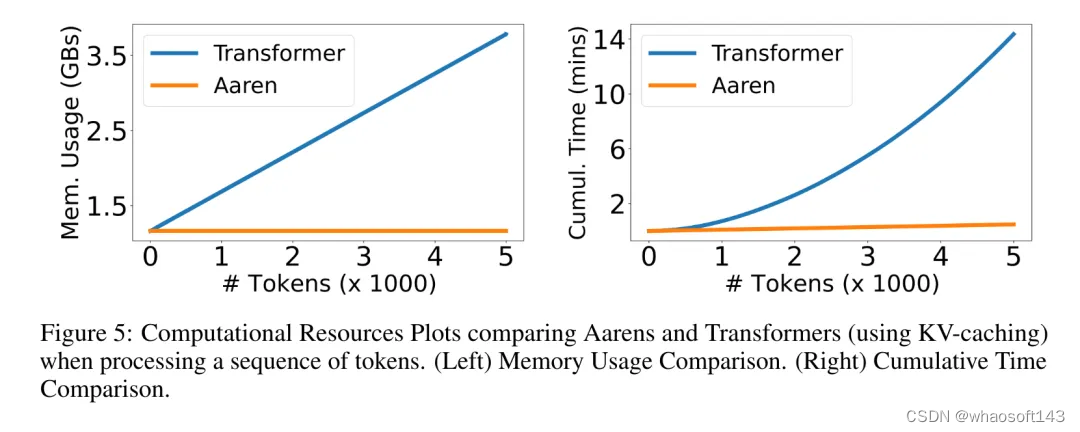
内存复杂性:在图 5(左)中,作者比较了 Aaren 和 Transformer(使用 KV 缓存)在推理时的内存使用情况。可以看到,伴随 KV 缓存技术的使用,Transformer 的内存使用量呈线性增长。相比之下,Aaren 只使用恒定的内存,无论 token 数量如何增长,因此它的效率要高得多。
时间复杂度:在图 5(右图)中,作者比较了 Aaren 和 Transformer(使用 KV 缓存)按顺序处理一串 token 所需的累计时间。对于 Transformer,累计计算量是 token 数的二次方,即 O (1 + 2 + ... + N) = O (N^2 )。相比之下,Aaren 的累计计算量是线性的。在图中,可以看到模型所需的累计时间也是类似的结果。具体来说,Transformer 所需的累计时间呈二次增长,而 Aaren 所需的累计时间呈线性增长。
参数数量:由于要学习初始隐藏状态 q,Aaren 模块需要的参数略多于 Transformer 模块。不过,由于 q 只是一个向量,因此差别不大。通过在同类模型中进行实证测量,作者发现 Transformer 使用了 3, 152, 384 个参数。相比之下,等效的 Aaren 使用了 3, 152, 896 个参数,参数增加量仅为 0.016%—— 对于内存和时间复杂性的显著差异来说,这只是微不足道的代价。
# GreenBitAI
只需单卡RTX 3090,低比特量化训练就能实现LLaMA-3 8B全参微调
本文由GreenBit.AI团队撰写,团队的核心成员来自德国哈索·普拉特纳计算机系统工程院开源技术小组。我们致力于推动开源社区的发展,倡导可持续的机器学习理念。我们的目标是通过提供更具成本效益的解决方案,使人工智能技术在环境和社会层面产生积极影响。
自 2010 年起,AI 技术历经多个重大发展阶段,深度学习的崛起和 AlphaGo 的标志性胜利显著推动了技术前进。尤其是 2022 年底推出的 ChatGPT,彰显了大语言模型(LLM)的能力达到了前所未有的水平。自此,生成式 AI 大模型迅速进入高速发展期,并被誉为第四次工业革命的驱动力,尤其在推动智能化和自动化技术在产业升级中有巨大潜力。这些技术正在改变我们处理信息、进行决策和相互交流的方式,预示着将对经济和社会各层面带来深远的变革。因此,AI 为我们带来了重大机遇,然而在 AI 技术不断进步的同时,其产业落地也面临诸多挑战,尤其是高昂的成本问题。例如,在商业化过程中,大模型尤其因成本过高而成为企业的一大负担。持续的技术突破虽然令人鼓舞,但如果落地阶段的成本无法控制,便难以持续资助研发并赢得广泛信任。然而,开源大模型的兴起正逐步改变这一局面,它们不仅技术开放,还通过降低使用门槛促进了技术的平等化和快速发展。例如,普通的消费级 GPU 就能够支持 7B/8B 规模模型的全参数微调操作,可能比采用高成本闭源模型成本低几个数量级。在这种去中心化的 AI 范式下,开源模型的应用在保证质量的前提下,可以显著降低边际成本,加速技术的商业化进程。此外,观察显示,经过量化压缩的较大模型在性能上往往优于同等大小的预训练小模型,说明量化压缩后的模型仍然保持了优秀的能力,这为采用开源模型而非自行重复预训练提供了充分的理由。
在 AI 技术的迅猛发展中,云端大模型不断探索技术的极限,以实现更广泛的应用和更强大的计算能力。然而,市场对于能够快速落地和支撑高速成长的智能应用有着迫切需求,这使得边缘计算中的大模型 —— 特别是中小型模型如 7B 和 13B 的模型 —— 因其高性价比和良好的可调性而受到青睐。企业更倾向于自行微调这些模型,以确保应用的稳定运行和数据质量的持续控制。此外,通过回流机制,从应用中收集到的数据可以用于训练更高效的模型,这种数据的持续优化和用户反馈的精细化调整成为了企业核心竞争力的一部分。尽管云端模型在处理复杂任务时精度高,但它们面临的几个关键挑战不容忽视:
- 推理服务的基础设施成本:支持 AI 推理的高性能硬件,尤其是 GPU,不仅稀缺而且价格昂贵,集中式商业运营带来的边际成本递增问题成为 AI 业务从 1 到 10 必须翻越的障碍。
- 推理延迟:在生产环境中,模型必须快速响应并返回结果,任何延迟都会直接影响用户体验和应用性能,这要求基础设施必须有足够的处理能力以满足高效运行的需求。
- 隐私和数据保护:特别是在涉及敏感信息的商业应用场景中,使用第三方云服务处理敏感数据可能会引发隐私和安全问题,这限制了云模型的使用范围。
考虑到这些挑战,边缘计算提供了一个有吸引力的替代方案。在边缘设备上直接运行中小模型不仅能降低数据传输的延迟,提高响应速度,而且有助于在本地处理敏感数据,增强数据安全和隐私保护。结合自有数据的实时反馈和迭代更新,AI 应用将更高效和个性化。
在当前的开源模型和工具生态中,尽管存在众多创新和进步,仍面临一系列不足之处。首先,这些模型和工具往往并未针对本地部署场景进行优化,导致在本地运用时常常受限于算力和内存资源。例如,即便是相对较小的 7B 规模模型,也可能需要高达 60GB 的 GPU 显存 (需要价格昂贵的 H100/A100 GPU) 来进行全参数微调。此外,市场上可选的预训练小型模型数量和规模相对有限,大模型的开发团队往往更专注于追求模型规模的扩展而非优化较小的模型。另一方面,现有的量化技术虽然在模型推理部署中表现良好,但其主要用途是减少模型部署时的内存占用。量化后的模型权重在微调过程中无法进行优化,这限制了开发者在资源有限的情况下使用较大模型的能力。开发者往往希望在微调过程中也能通过量化技术节省内存,这一需求尚未得到有效解决。
我们的出发点在于解决上述痛点,并为开源社区贡献实质性的技术进步。基于 Neural Architecture Search (NAS) 以及相匹配的 Post-Training Quantization (PTQ) 量化方案,我们提供了超过 200 个从不同规模开源大模型序列压缩而来的低比特量化小模型,这些模型涵盖了从 110B 到 0.5B 的规模跨度,并优先保证精度和质量,再次刷新了低比特量化的 SOTA 精度。同时,我们的 NAS 算法深入考量了模型参数量化排布的硬件友好性,使得这些模型能轻易的在主流计算硬件 (如 Nvidia GPU 和 Apple silicon 芯片硬件平台) 进行适配,极大地方便了开发者的使用。此外,我们推出了 Bitorch Engine 开源框架以及专为低比特模型训练设计的 DiodeMix 优化器,开发者可以直接对低比特量化模型在量化空间进行全参数监督微调与继续训练,实现了训练与推理表征的对齐,大幅度压缩模型开发与部署的中间环节。更短的工程链条将大幅度提升工程效率,加快模型与产品迭代。通过结合低比特权重训练技术和低秩梯度技术,我们就能实现在单卡 RTX 3090 GPU 上对 LLaMA-3 8B 模型进行全参数微调(图 1)。上述解决方案简洁有效,不仅节省资源,而且有效地解决了量化模型精度损失的问题。我们将在下文对更多技术细节进行详细解读。
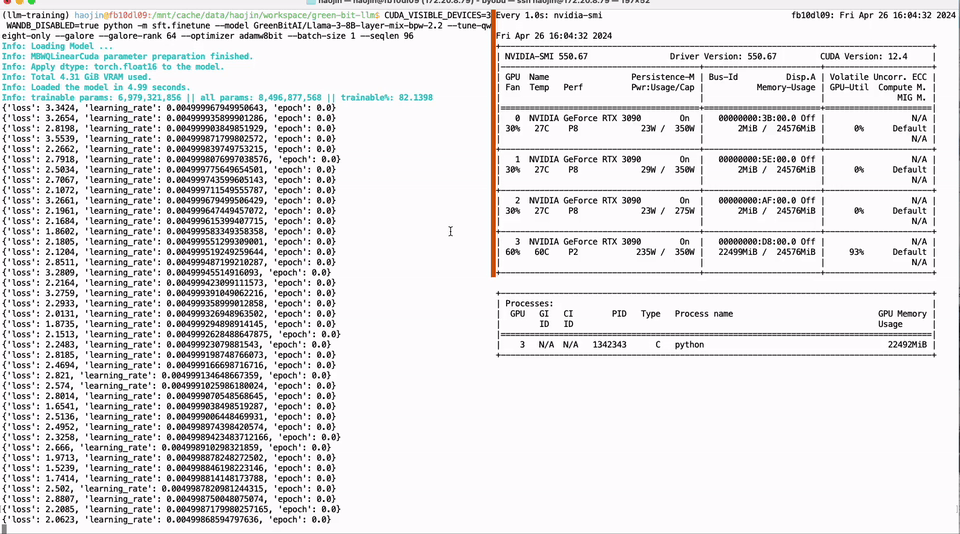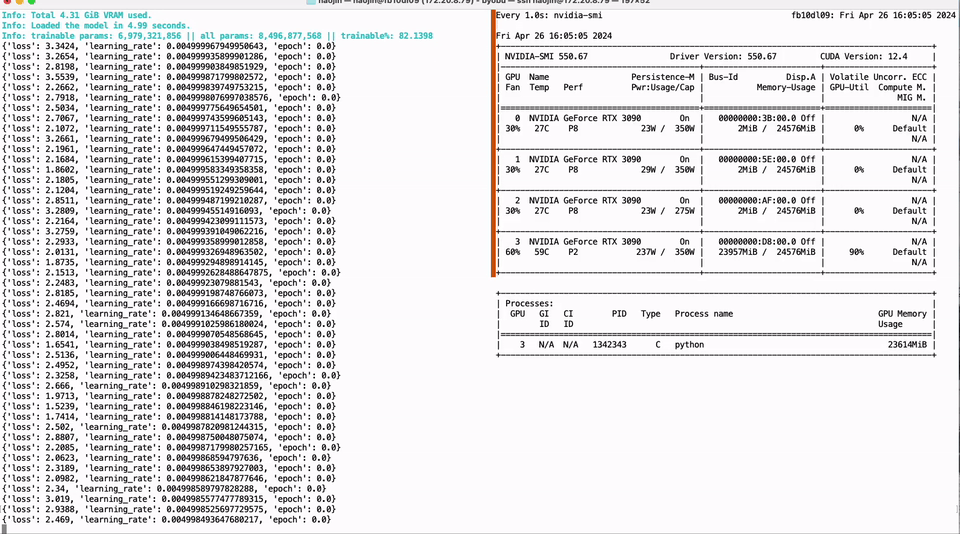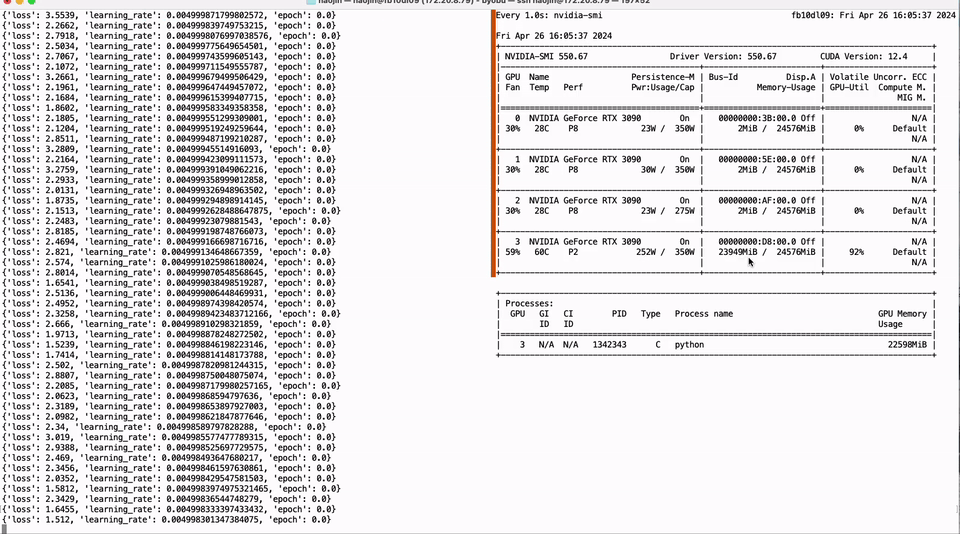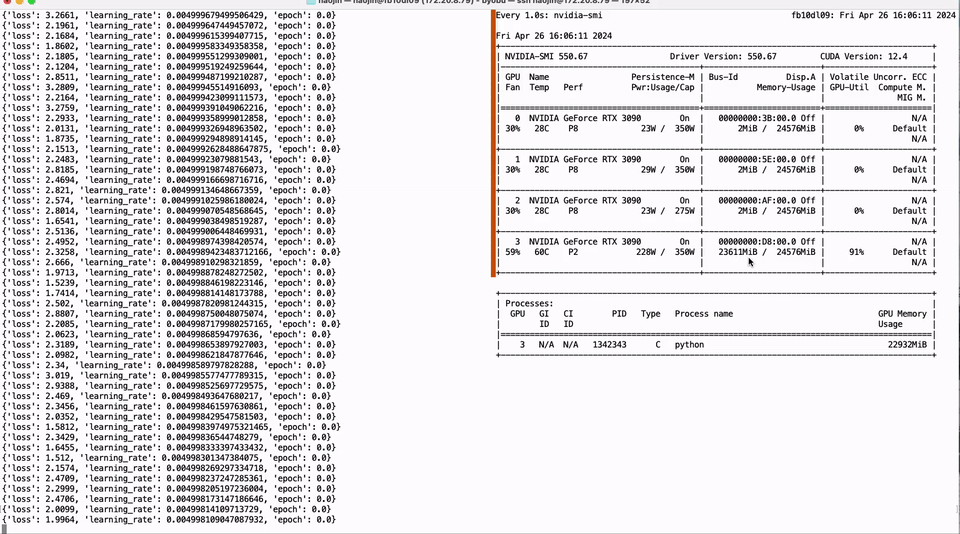
图 1. 单卡 3090 实现 LLaMA-3 8B 全参微调
模型量化
大模型时代的显著特征之一便是模型对计算资源需求的大幅度攀升。GPTQ 与 AWQ 等权重 PTQ 压缩方案以可扩展的方式验证了大语言模型在 4-bit 表征上的可靠性,在相比于 FP16 表征实现 4 倍的权重空间压缩的同时实现了较小的性能丢失,大幅度降低模型推理所需的硬件资源。与此同时,QLoRA 巧妙地将 4-bit LLM 表征与 LoRA 技术相结合,将低比特表征推广至监督微调阶段,并在微调结束后将 LoRA 模块与原始 FP16 模型融合,实现了低资源需求下的模型 Parameter-Efficient-Finetuning (PEFT)。这些前沿的高效工程探索为社区提供了便利的研究工具,大幅度降低了模型研究与产业应用的资源门槛,也进一步激发了学术与产业界对更低比特表征的想象空间。
相比于 INT4,更低比特的 Round-To-Nearest (RTN) 量化如 INT2 表征通常要求原始模型有着更平滑的连续参数空间才能保持较低的量化损失,例如,超大规模模型往往存在容量冗余并有着更优的量化容忍度。而通过 LLM.int8 () 等工作对当前基于 transformer 架构的大语言模型分析研究,我们已经观察到了模型推理中广泛存在着系统性激活涌现现象,少数通道对最终推理结果起着决定性作用。近期 layer-Importance 等多项工作则进一步观测到了不同深度的 transformer 模块对模型容量的参与度也表现出非均匀分布的特性。这些不同于小参数模型的分布特性引申出了大量 Model Pruning 相关研究的同时也为低比特压缩技术提供了研究启示。基于这些工作的启发,我们探索了一种搜索与校准结合的 Two-stage LLM 低比特量化方案。
(1) 首先,我们利用 NAS 相关方法对大语言模型参数空间的量化敏感性进行搜索与排序,利用经典的混合精度表征实现模型参数中的最优比特位分配。为降低模型量化后的大规模硬件部署难度,我们放弃了复杂的矢量量化与 INT3 表征等设计,采用经典 Group-wise MinMax Quantizer,同时仅选择 INT4 (group size 128) 与 INT2 (group size 64) 作为基础量化表征。相对简单的 Quantizer 设计一方面降低了计算加速内核的设计复杂度与跨平台部署难度,另一方面也对优化方案提出了更高的要求。为此,我们探索了 Layer-mix 与 Channel-mix 两种排布下的混合精度搜索空间。其中,Channel-mix 量化由于能更好适配 transformer 架构的系统性激活涌现现象,往往能达到更低的量化损失,而 Layer-mix 量化在具备更优的硬件友好度的同时仍然保持了极佳的模型容量。利用高效的混合精度 NAS 算法,我们能在数小时内基于低端 GPU 如 RTX 3090 上完成对 Qwen1.5 110B 大模型的量化排布统计,并基于统计特性在数十秒内完成任意低比特量级模型的最优架构搜索。我们观察到,仅仅基于搜索与重要性排序,已经可以快速构造极强的低比特模型。
(2) 搜索得到模型的量化排布后,我们引入了一种基于离线知识蒸馏的可扩展 PTQ 校准算法,以应对超低比特量化 (如 2 到 3-bit) 带来的累积分布漂移问题,仅需使用不超过 512 个样本的多源校准数据集,即可在数小时内使用单张 A100 GPU 完成 0.5B-110B 大语言模型的 PTQ 校准。尽管额外的校准步骤引入了更长的压缩时间,从经典低比特以及量化感知训练(QAT)相关研究的经验中我们可以了解到,这是构建低量化损失模型的必要条件。而随着当前开源社区 100B + 大模型的持续涌现 (如 Command R plus、Qwen1.5 110B, LLama3 400B),如何构建高效且可扩展的量化压缩方案将是 LLM 社区系统工程研究的重要组成部分,也是我们持续关注的方向。我们经验性的证明,搜索与校准相结合的低比特量化方案在推进低量化损耗表征模型的同时,在开源社区模型架构适配、硬件预期管理等方面都有着显著优势。
性能分析
基于 Two-stage 量化压缩方案,我们提供了超过 200 个从不同规模开源大模型序列压缩而来的低比特量化小模型,涵盖了最新的 Llama3、Phi-3、Qwen1.5 以及 Mistral 等系列。我们利用 EleutherAI 的 lm-evaluation-harness 库等对低比特量化模型的真实性能与产业场景定位进行了探索。其中我们的 4-bit 量化校准方案基本实现了相对于 FP16 的 lossless 压缩。基于混合 INT4 与 INT2 表征实现的 sub-4 bit 量化校准方案在多项 zero-shot 评测结果表明,搜索与少量数据校准的经典 INT2 量化表征已经足够维持 LLM 在语言模型阅读理解 (BoolQ,RACE,ARC-E/C)、常识推理 (Winogr, Hellaswag, PIQA) 以及自然语言推理 (WIC, ANLI-R1, ANLI-R2, ANLI-R3) 方面的核心能力。
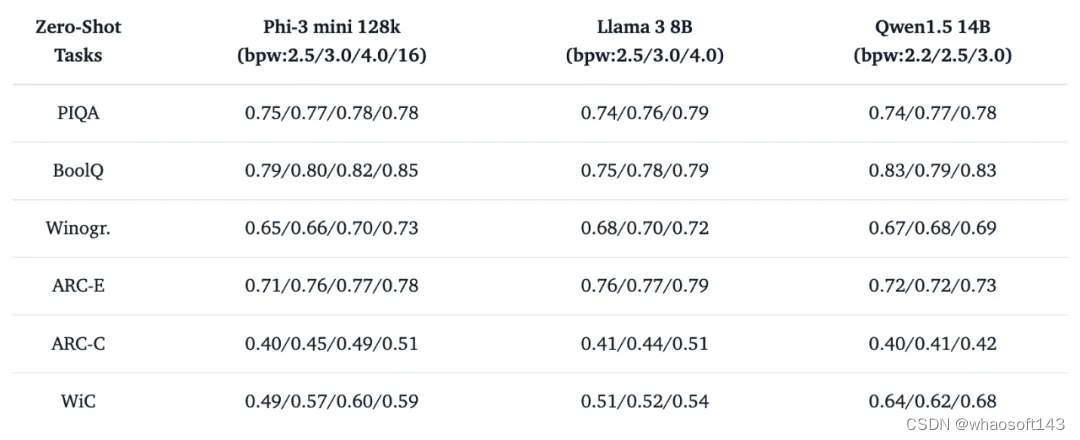
表 1. 低比特量化模型 zero-shot 评测示例
同时我们试图利用进一步的 few-shot 消融对比实验探索超低比特在产业应用中的定位,有趣的现象是,INT2 表征为主体的超低比特 (bpw: 2.2/2.5) 模型在 5-shot 帮助下即可实现推理能力的大幅度提升。这种对少量示例样本的利用能力表明,低比特压缩技术在构造容量有限但足够 “聪明” 的语言模型方面已经接近价值兑现期,配合检索增强 (RAG) 等技术适合构造更具备成本效益的模型服务。
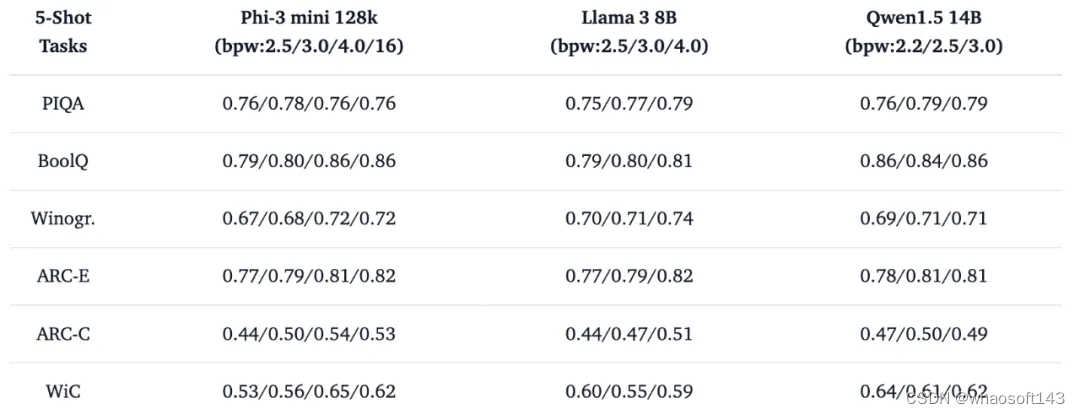
表 2. 低比特量化模型 5-shot 评测示例
考虑到当前少样本 PTQ 校准仅仅引入了有限的计算资源 (校准数据集 < 512),以我们开源的低比特模型作为初始化进行更充分的全参数量化训练将进一步提升低比特模型在实际任务中的表现,我们已经为这一需求的高效实现提供了定制化开源工具。
开源工具
我们推出了三款实用的工具来辅助这些模型的使用,并计划未来持续优化和扩展。
Bitorch Engine (BIE) 是一款前沿的神经网络计算库,其设计理念旨在为现代 AI 研究与开发找到灵活性与效率的最佳平衡。BIE 基于 PyTorch,为低位量化的神经网络操作定制了一整套优化的网络组件,这些组件不仅能保持深度学习模型的高精度和准确性,同时也大幅降低了计算资源的消耗。它是实现低比特量化 LLM 全参数微调的基础。此外,BIE 还提供了基于 CUTLASS 和 CUDA 的 kernel,支持 1-8 bit 量化感知训练。我们还开发了专为低比特组件设计的优化器 DiodeMix,有效解决了量化训练与推理表征的对齐问题。在开发过程中,我们发现 PyTorch 原生不支持低比特张量的梯度计算,为此我们对 PyTorch 进行了少量调整,提供了支持低比特梯度计算的修改版,以方便社区利用这一功能。目前我们为 BIE 提供了基于 Conda 和 Docker 的两种安装方式。而完全基于 Pip 的预编译安装版本也会在近期提供给社区,方便开发者可以更便捷的使用。
green-bit-llm 是为 GreenBitAI low-bit LLM 专门开发的工具包。该工具包支持云端和消费级 GPU 上的高性能推理,并与 Bitorch Engine 配合,完全兼容 transformers、PEFT 和 TRL 等主流训练 / 微调框架,支持直接使用量化 LLM 进行全参数微调和 PEFT。目前,它已经兼容了多个低比特模型序列,详见表 3。
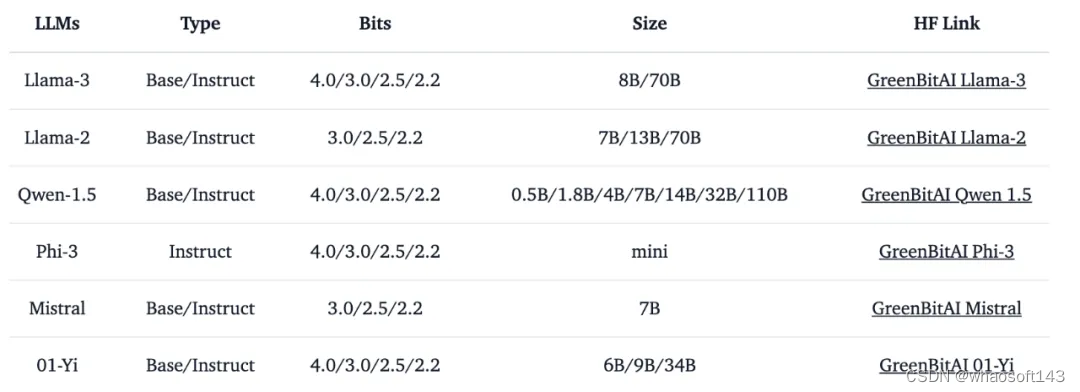
表 3. 已支持低比特模型序列信息
以目前最新的开源大模型 Llama-3 8b base 模型为例,我们选择它的 2.2/2.5/3.0 bit 作为全参数量化监督微调 (Q-SFT) 对象,使用 huggingface 库托管的 tatsu-lab/alpaca 数据集 (包含 52000 个指令微调样本) 进行 1 个 epoch 的最小指令微调对齐训练测试,模型完全在量化权重空间进行学习而不涉及常规的 LoRA 参数优化与融合等后处理步骤,训练结束后即可直接实现高性能的量化推理部署。在这一例子中,我们选择不更新包括 Embedding,、LayerNorm 以及 lm.head 在内的任何其他 FP16 参数,以验证量化空间学习的有效性。传统 LoRA 微调、Q-SFT 配合 Galore 优化器微调以及单纯使用 Q-SFT 微调对低比特 Llama 3 8B 模型能力的影响如表 4 中所示。
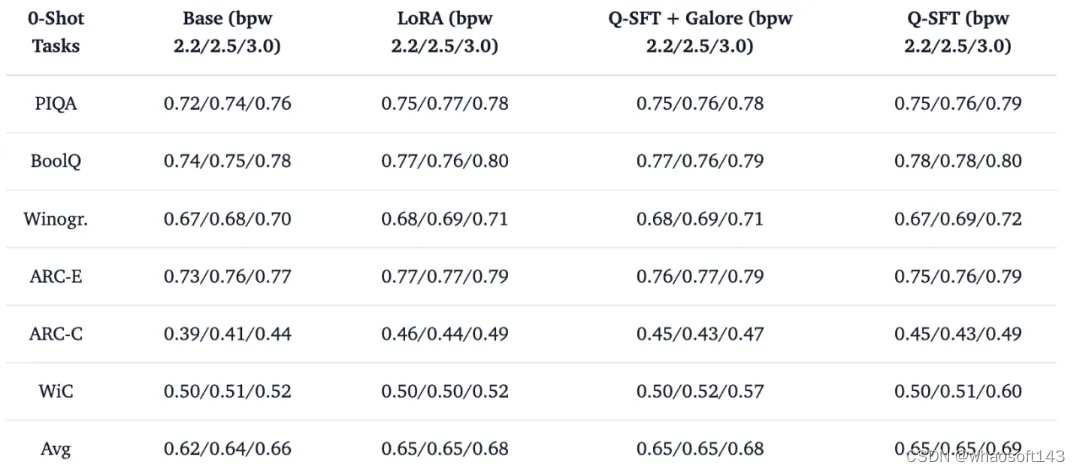
表 4. Q-SFT 对量化 LLM 的 zero-shot 能力影响
相比于传统的 LoRA 微调 + 后量化的工程组合,Q-SFT 直接在推理模型量化空间进行学习的方式大幅度简化了大模型从开发到部署之间的工程链条,同时实现了更好的模型微调效果,为更具成本效益的模型扩展提供了解决方案。此外,推理模型与训练模型的表征对齐也为更丝滑的端侧学习与应用提供了可能性,例如,在端侧进行非全参数 Q-SFT 将成为更可靠的端侧优化管线。
在我们的自研低比特模型以外,green-bit-llm 完全兼容 AutoGPTQ 系列 4-bit 量化压缩模型,这意味着 huggingface 现存的 2848 个 4-bit GPTQ 模型都可以基于 green-bit-llm 在量化参数空间进行低资源继续学习 / 微调。作为 LLM 部署生态最受欢迎的压缩格式之一,现有 AutoGPTQ 爱好者可以基于 green-bit-llm 在模型训练和推理之间进行无缝切换,不需要引入新的工程节点。
Q-SFT 和 Bitorch-Engine 能在低资源环境下稳定工作的关键是,我们探索了专用于低比特大模型的 DiodeMix 优化器,以缓解 FP16 梯度与量化空间的表征 Mismatch 影响,量化参数更新过程被巧妙的转换为基于组间累积梯度的相对大小排序问题。更符合量化参数空间的高效定制优化器将是我们未来持续探索的重要方向之一。
gbx-lm 工具将 GreenBitAI 的低比特模型适配至苹果的 MLX 框架,进而能在苹果芯片上高效的运行大模型。目前已支持模型的加载和生成等基础操作。此外,该工具还提供了一个示例,遵循我们提供的详尽指南,用户可以在苹果电脑上迅速建立一个本地聊天演示页面,如下图所示。
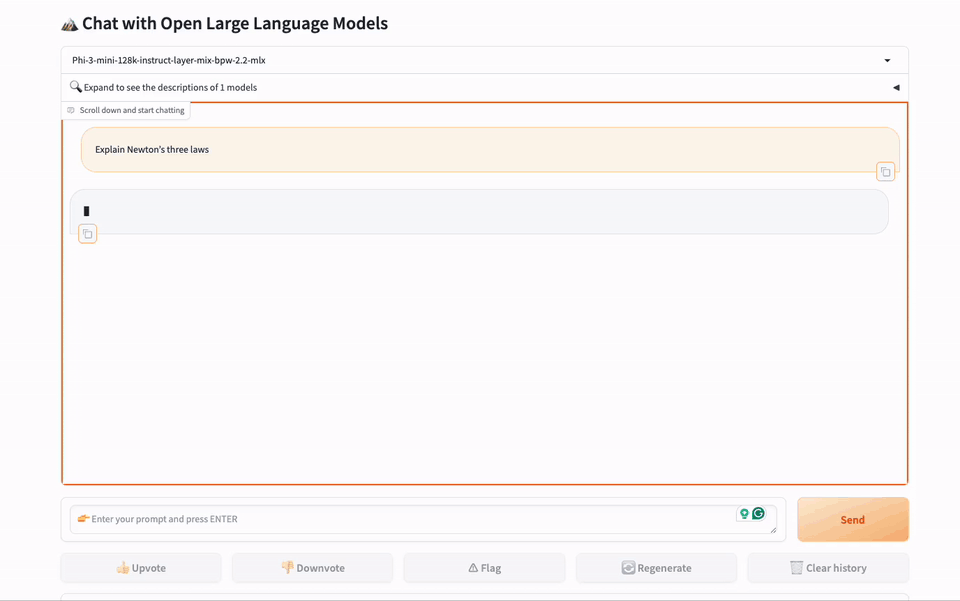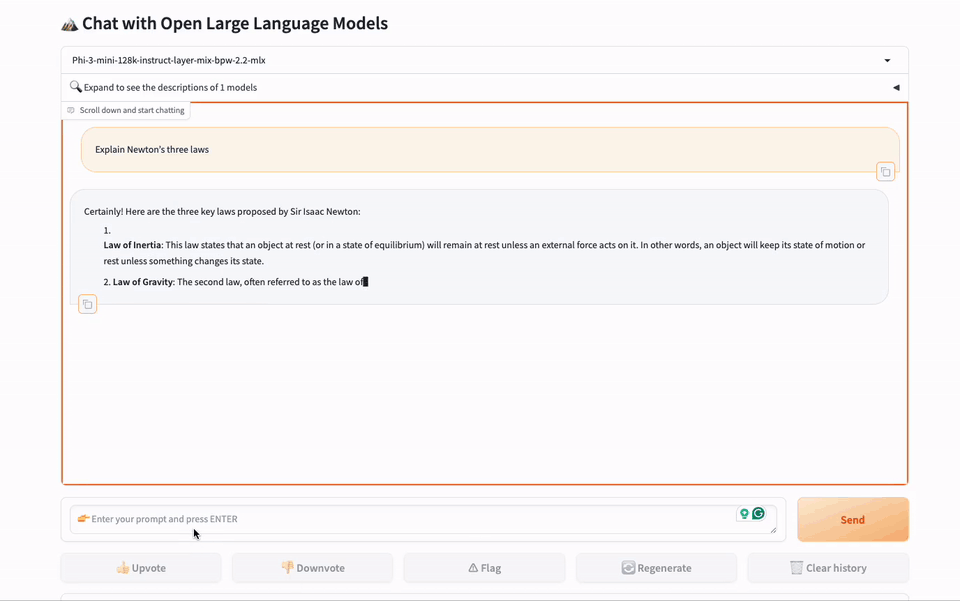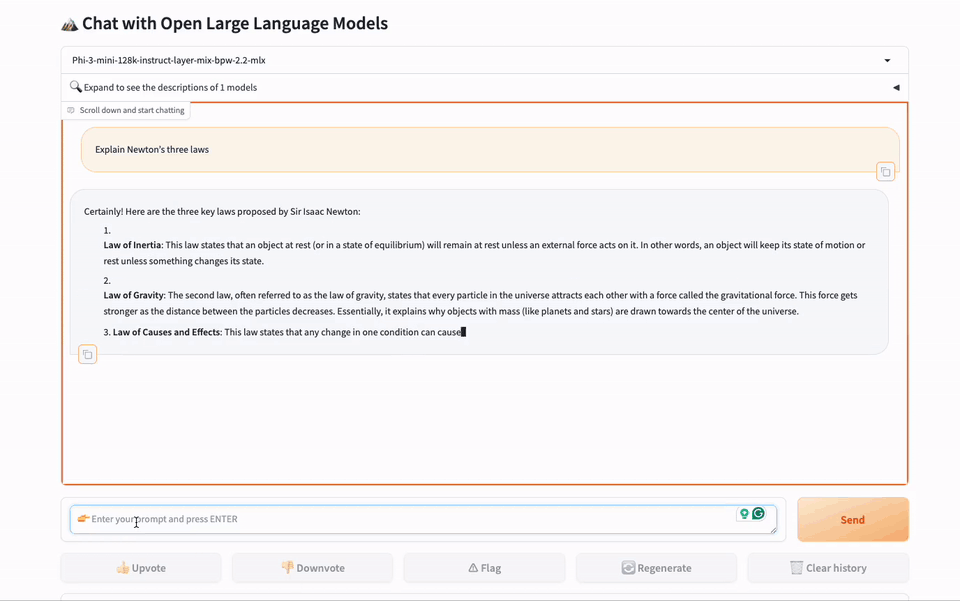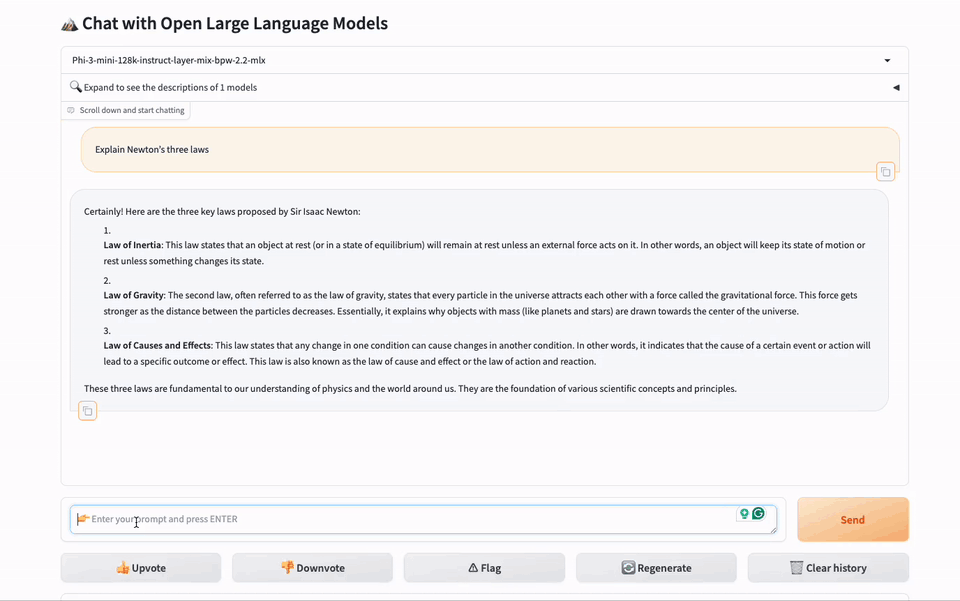
我们非常期待与更多开发者一同推动开源社区的发展。如果你也热衷于此,并希望与志同道合的伙伴们一起前行,请不要犹豫!我们真诚地欢迎你的加入。你可以通过社区平台或直接发送邮件至 team@greenbit.ai 与我们联系。
资源链接
- 模型库: https://huggingface.co/GreenBitAI
- BIE: https://github.com/GreenBitAI/bitorch-engine
- green-bit-llm: https://github.com/GreenBitAI/green-bit-llm
- gbx-lm: https://github.com/GreenBitAI/gbx-lm
#Highest fusion performance without harmful edge energy bursts in tokamak
可控核聚变新里程碑,AI首次实现双托卡马克3D场全自动优化,登Nature子刊
几十年来,核聚变释放能量的「精妙」过程一直吸引着科学家们的研究兴趣。
现在,在普林斯顿等离子体物理实验室(PPPL)中 ,科学家正借助人工智能,来解决人类面临的紧迫挑战:通过聚变等离子体产生清洁、可靠的能源。
与传统的计算机代码不同,机器学习不仅仅是指令列表,它可以分析数据、推断特征之间的关系、从新知识中学习并适应。
PPPL 研究人员相信,这种学习和适应能力可以通过多种方式改善他们对聚变反应的控制。这包括完善超热等离子体周围容器的设计、优化加热方法以及在越来越长的时间内保持反应的稳定控制。
近日,PPPL 的 AI 研究取得重大成果。PPPL 研究人员解释了他们如何使用机器学习来避免磁扰动破坏聚变等离子体的稳定性。

图示:上面显示的两个托卡马克(DIII-D 和 KSTAR)装置中部署了用于检测和消除等离子体不稳定性的机器学习代码。(来源:通用原子公司和韩国聚变能源研究所)
该论文的主要作者、PPPL 研究物理学家 SangKyeun Kim 表示:「研究结果令人印象深刻,因为我们能够使用相同的代码在两个不同的托卡马克装置上实现这些结果。」
相关研究以《Highest fusion performance without harmful edge energy bursts in tokamak》为题,发布在《Nature Communications》上。
论文链接:https://www.nature.com/articles/s41467-024-48415-w
抑制聚变中「边缘爆发」
为了使聚变能在全球能源市场上具有经济竞争力,它必须在维持聚变的同时,实现具有足够等离子体密度(n)、温度(T)和能量约束时间(τ)的高聚变三重积(nτT)。
换句话说,聚变等离子体需要足够的品质因数(G ∝ nτT)才能实现高聚变性能,并且随着等离子体约束质量 (H89:归一化能量约束时间) 的增加而增加。
为了使托卡马克设计成为聚变反应堆的可行选择,必须开发可靠的方法来定期抑制边缘爆发(edge burst)事件而不影响 G。
科学家已经通过各种方法来减轻边缘爆发事件。一种有效的方法是利用外部 3D 场线圈的共振磁扰动 (RMP),这已被证明是最有前途的边缘爆发抑制方法之一。
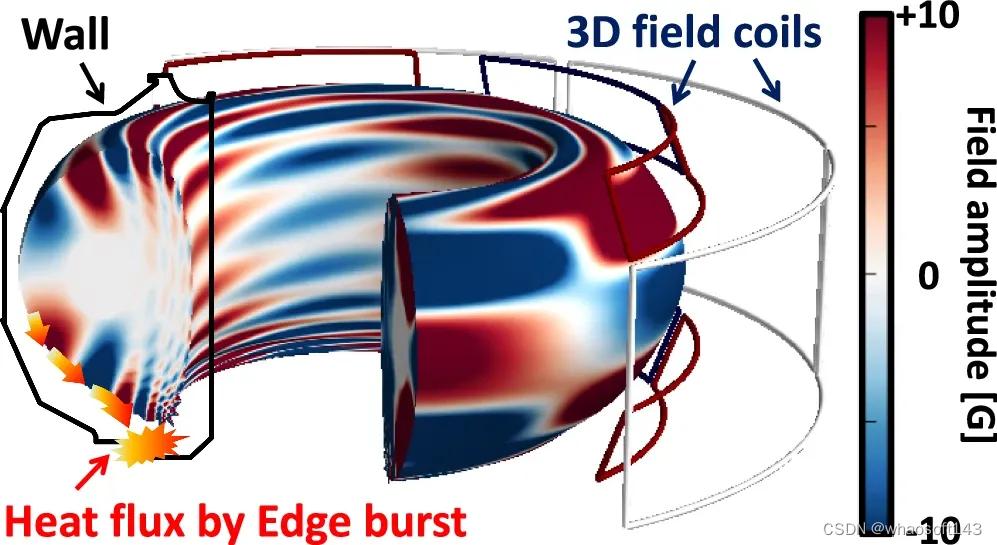
图示:托卡马克中的 3D 场线圈结构。(来源:论文)
然而,这种情况的代价高昂,导致 H89 和 G 与标准高约束等离子体体系相比显著恶化,从而削弱了经济前景。此外,3D 场还增加了灾难性核心不稳定的风险,称为中断,这甚至比边缘爆裂更严重。因此,无边缘爆发操作与高约束操作的安全可及性和兼容性亟待探索。
首次在两个托卡马克上实现
该研究首次在 KSTAR 和 DIII-D 两个托卡马克上进行了创新和集成的 3D 场优化,通过结合机器学习 (ML)、自适应和多机器功能,来自动访问和实现几乎几乎完全无边缘爆发状态,同时从最初的爆发抑制状态提高等离子体聚变性能,这是未来反应堆实现无边缘爆发运行的一个重要里程碑。
这是通过实时利用无边缘爆发起始和损耗之间的滞后来增强等离子体约束,同时扩展 ML 在捕获物理和优化核聚变技术方面的能力来实现的。
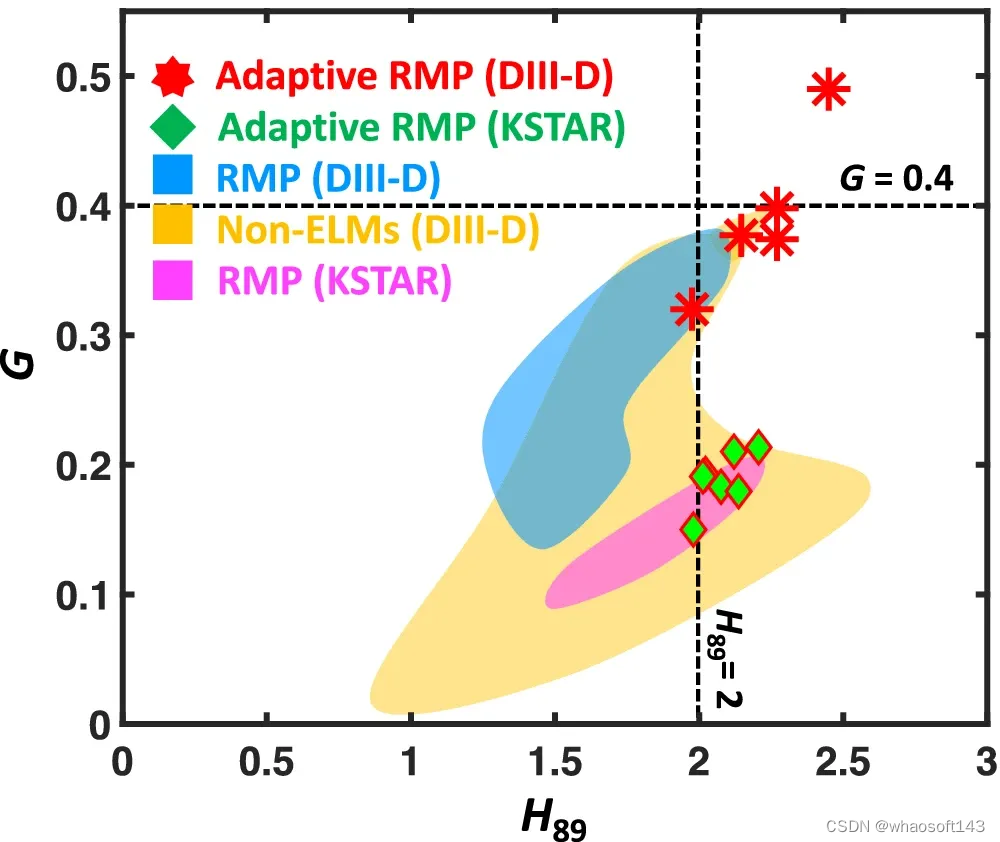
图示:DIII-D 和 KSTAR 托卡马克中 ELM-free 放电的性能比较。(来源:论文)
这种集成有助于:
- 高度增强等离子体约束,在两台机器的无边界局域模(Edge Localized Mode-free,ELM-free)场景中达到最高融合 G,G 增加高达 90%;
- 使用基于 ML 的 3D 场模拟器首次实现全自动 3D 场优化;
- 从等离子体操作一开始就同时建立爆发抑制,实现接近 ITER 相关水平的几乎完全的无边缘爆发操作。这一成就为国际热核聚变实验反应堆(ITER)等未来设备迈出了至关重要的一步,在这些设备中,依赖经验 RMP 优化不再是可行或可接受的方法。
「等离子体中存在不稳定性,可能会导致聚变装置严重损坏。我们不能在商业聚变容器中使用这些物质。我们的工作推动了该领域的发展,并表明人工智能可以在管理聚变反应方面发挥重要作用,避免不稳定,同时允许等离子体产生尽可能多的聚变能。」通讯作者、PPPL 机械和航空航天工程系副教授 Egemen Kolemen 说道。
基于 ML 的全自动 3D 场优化
在本实验中,使用一系列放电来寻找安全 ELM 抑制的优化 3D 波形。
在此背景下,研究引入了 ML 技术来开发自动化 3D 线圈优化的新颖路径,并首次演示了该概念。
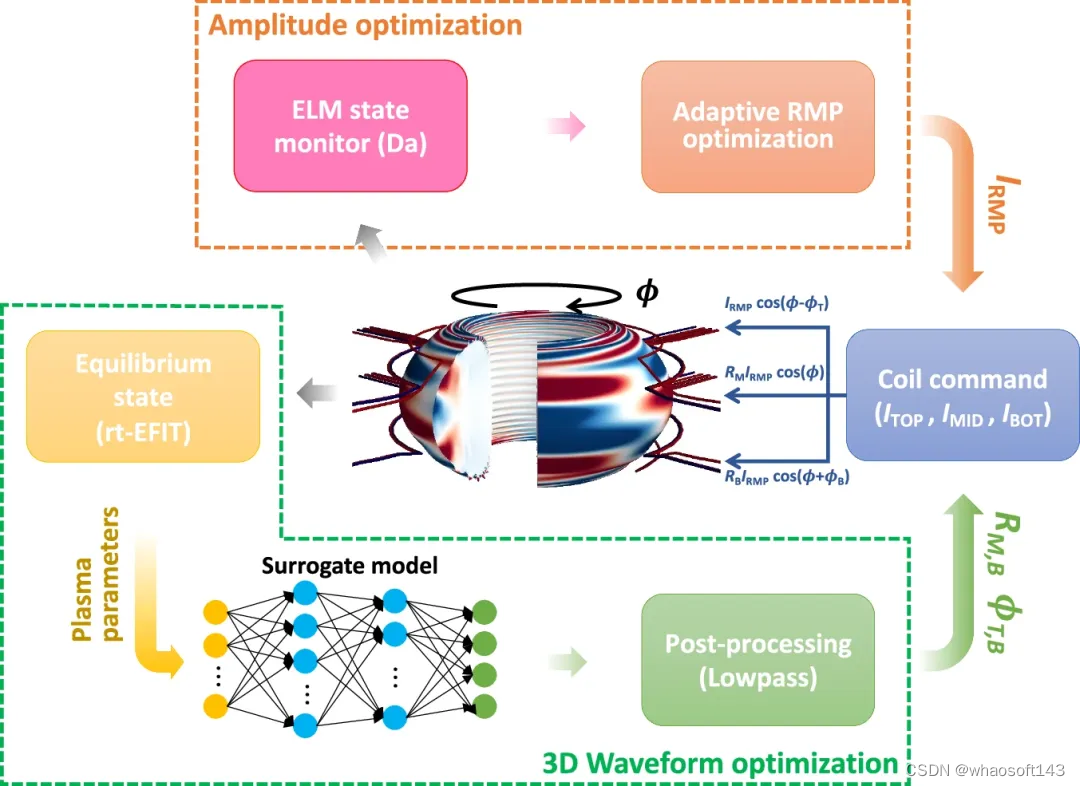
图示:基于机器学习的实时 RMP 优化算法。(来源:论文)
研究人员开发了 GPEC 代码的代理模型 (ML-3D),以实时利用基于物理的模型。该模型使用 ML 算法将计算时间加速到 ms 级,并集成到 KSTAR 中的自适应 RMP 优化器中。
ML-3D 由一个完全连接的多层感知器(MLP)组成,由九个输入驱动。为了训练该模型,利用 8490 KSTAR 平衡的 GPEC 模拟。
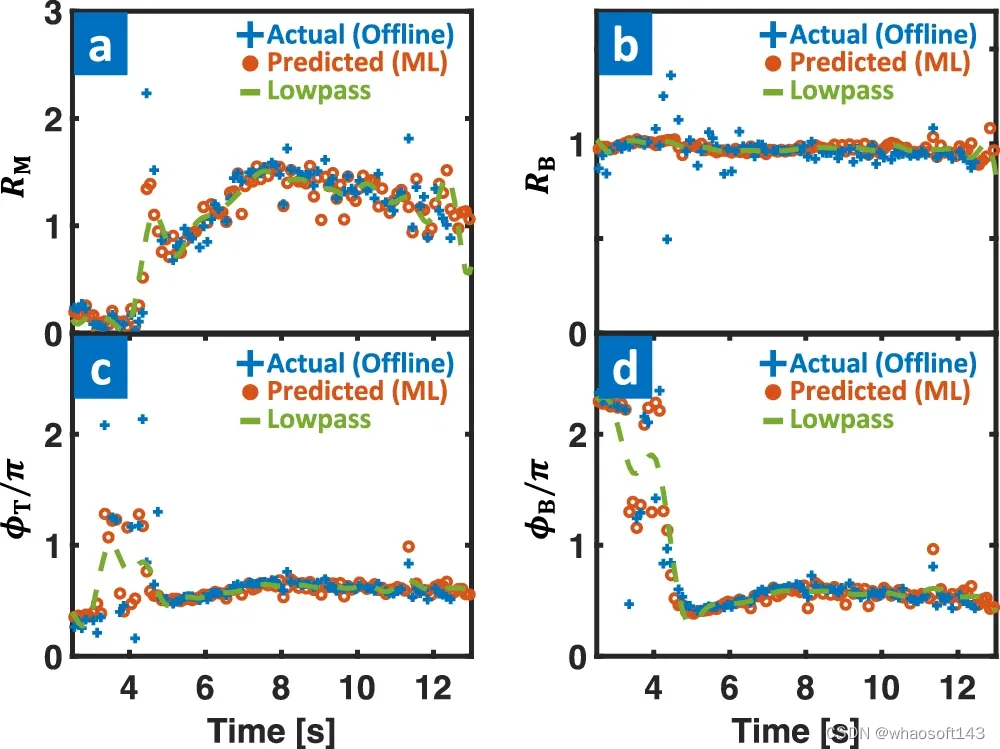
图示:ML-3D 模型性能。(来源:论文)
该算法利用 ELM 状态监视器(Dα)信号实时调整 IRMP,可以保持足够的边缘 3D 场来访问和维持 ELM 抑制。同时,3D 场优化器使用 ML-3D 的输出来调整 3D 线圈上的电流分布,从而保证安全的 3D 场以避免中断。
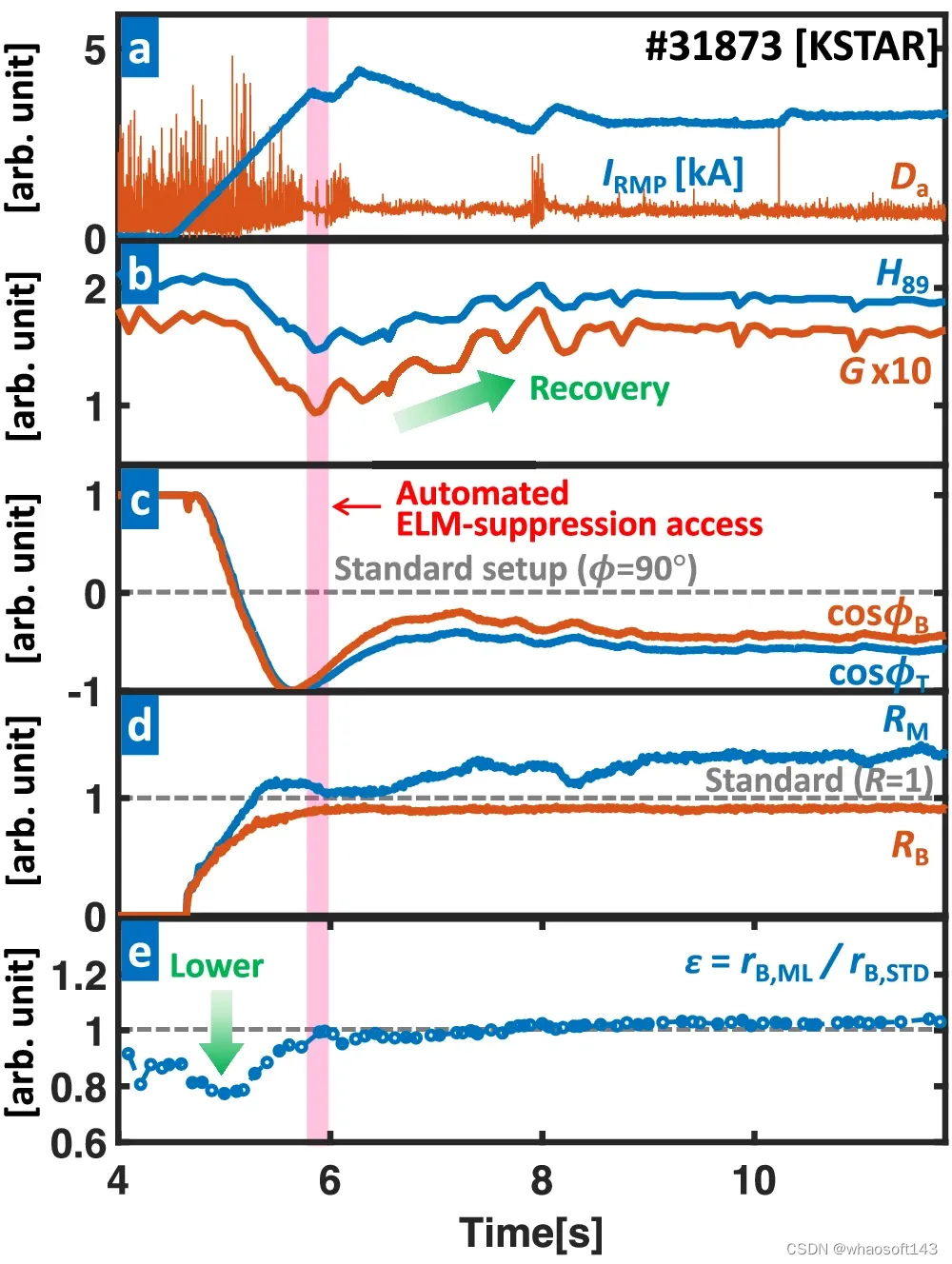
图示:具有集成 RMP 优化功能的全自动 ELM 抑制放电 (#31873) 的等离子体参数。(来源:论文)
KSTAR 实验中,ML 集成的自适应 RMP 优化器在 4.5 秒内触发,在 6.2 秒内实现安全的 ELM 抑制。
研究还表明 3D-ML 作为自动化无 ELM 访问的可行解决方案。ML-3D 基于物理模型,不需要实验数据,使其可以直接扩展到 ITER 和未来的聚变反应堆。这种对未来设备的强大适用性凸显了 ML 集成 3D 场优化方案的优势。此外,在未来的 3D 线圈电流限制更高的设备中,有望实现更好的场优化和更高的聚变性能。
研究成功优化了 KSTAR 和 DIII-D 装置中的受控 ELM-free 状态,并具有高度增强的聚变性能,涵盖了与未来反应堆相关的 low-n RMP 到 ITER 相关的 nRMP = 3 RMP,并在两台机器中实现了各种 ELM-free 场景中的最高水平。
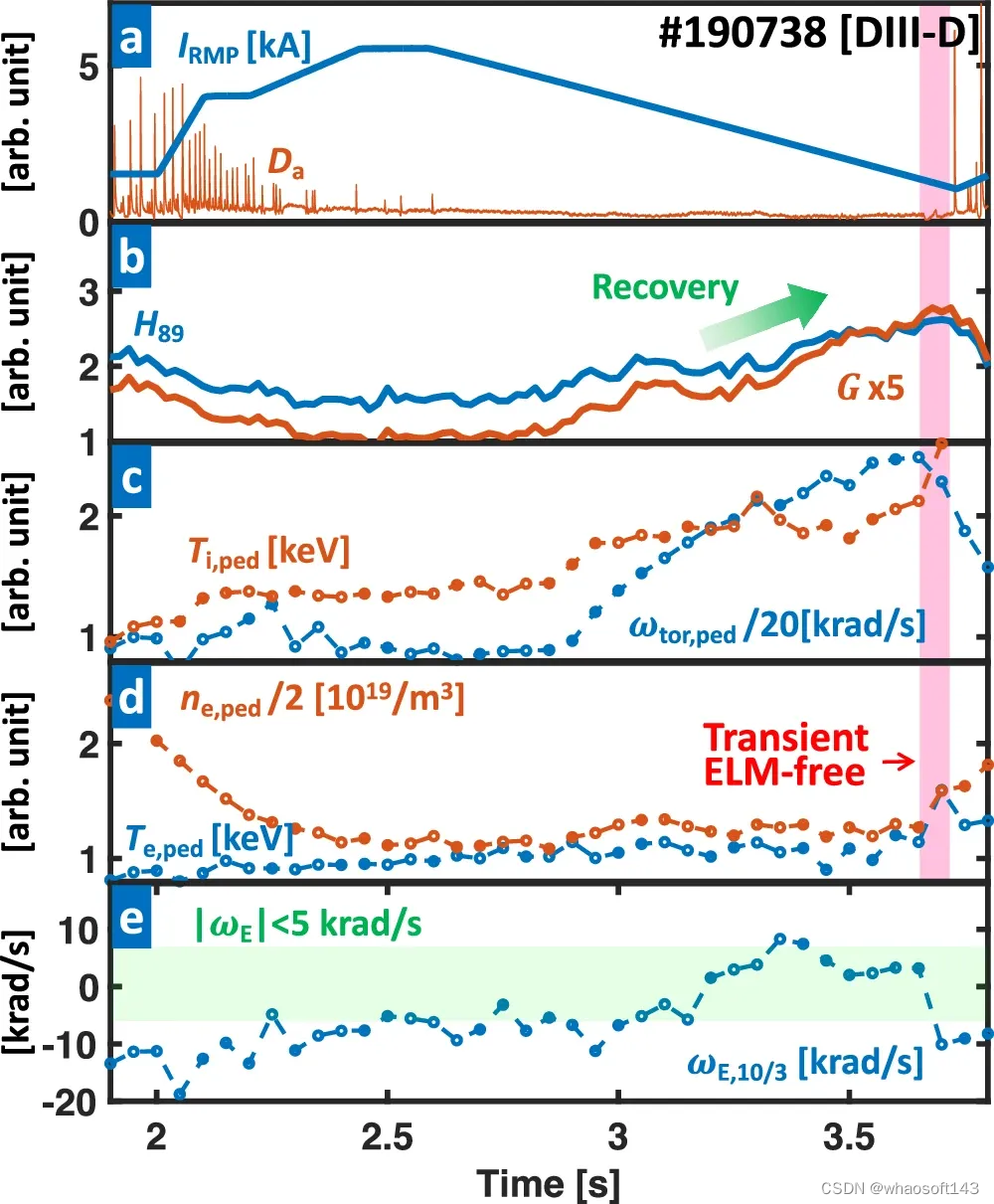
图示:性能高度增强的优化 RMP 振幅 (#190738) 的等离子体参数。(来源:论文)
此外,ML 算法与 RMP 控制的创新集成首次实现了全自动 3D 场优化和 ELM-free 操作,并在自适应优化流程的支持下,性能得到了显著增强。这种自适应方法展现了 RMP ELM 抑制和高限制之间的兼容性。
此外,它还提供了一种稳健的策略,通过最大限度地减少限制和无感电流分数的损失,在长脉冲场景(持续超过 45 秒)中实现稳定的 ELM 抑制。
值得注意的是,在 nRMP = 3 RMP 的 DIII-D 中观察到显著的性能 (G) 提升,显示较初始标准 ELM 抑制状态提高了 90% 以上。这种增强不仅归因于自适应 RMP 控制,还归因于等离子体旋转的自洽演化。该响应能够以非常低的 RMP 幅度进行 ELM 抑制,从而增强基座。此功能是系统通过对自适应调制的自组织响应过渡到最佳状态的一个很好的例子。
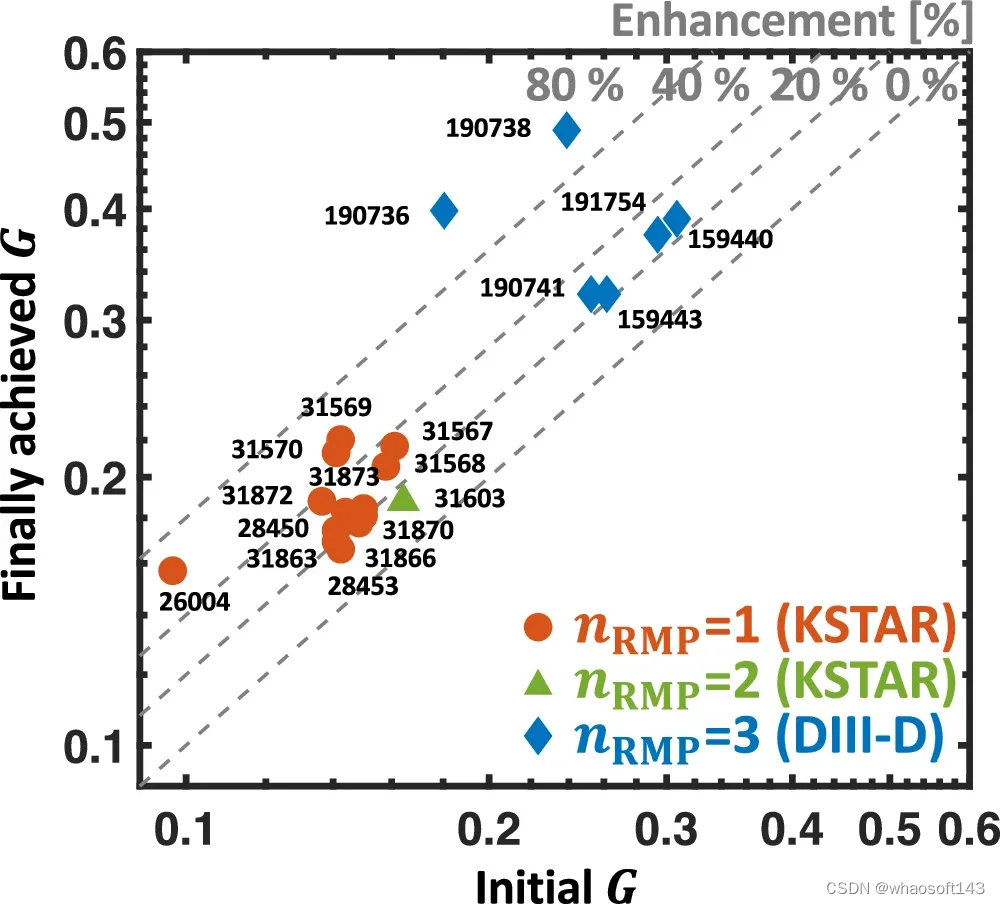
图示:通过自适应 RMP 优化提高放电性能。(来源:论文)
此外,自适应方案与早期的 RMP-ramp 方法相结合,实现了 ITER 相关的 ELM-free 场景,几乎完全 ELM-free 操作。这些结果证实,集成自适应 RMP 控制是一种非常有前途的优化 ELM 抑制状态的方法,有可能解决实现实用且经济可行的聚变能源的最艰巨的挑战之一。
参考内容:https://phys.org/news/2024-05-ai-intensive-aspects-plasma-physics.html
#Vertex AI
上周末,谷歌宣布基于 Vertex AI 的生成式人工智能服务全面上线了。
Vertex AI 是谷歌云提供的机器学习平台服务(ML PaaS)。随着本次发布,谷歌大模型的服务已普遍可用,企业和组织现在可以将该平台的功能与自身应用进行集成。
在大模型时代,基础模型是创建自定义生成式 AI 应用的起点,但仅有模型是不够的。谷歌提出的 Model Garden 和 Generative AI Studio 利用了来自 Google Cloud、Google Research 和 Google DeepMind 的先进技术,让开发者和数据科学家可以轻松使用、自定义和部署模型。
现在,开发者们可以在 Vertex AI 上使用多种新工具和模型,例如由下一代大型语言模型 PaLM 2 驱动的单词补全模型、用于文本的嵌入 API 和 Model Garden 中的其他基础模型。他们还可以利用 Generative AI Studio 中的可用工具来微调和部署自定义模型。
谷歌声称,企业级数据治理、安全等功能也内置于 Vertex AI 平台中。这让人们可以更有信心使用基础模型、并使用他们自己的数据对基础模型进行自定义,以及构建生成式 AI 应用程序。
目前,我们已可以使用 Model Garden 访问和评估来自谷歌及其合作伙伴的 60 多种基础模型,这个数量还在持续增长。此外,在 5 月 Google I/O 大会上宣布的用于代码完成、代码生成和对话的 Codey 模型现在公开预览版可用了。

Codey 的代码生成功能支持 20 多种编码语言,包括 Go、Google Standard SQL、Java、Javascript、Python 和 Typescript 等等。
除了基础模型,Vertex AI 还提供了一个完整的工具生态系统,以帮助构建者在生产环境中调整、部署和管理模型。谷歌表示,Vertex AI 是首个提供人类反馈强化学习(RLHF)的企业级机器学习平台,这有助于提高模型的实用性并降低成本,同时谷歌还为需要管理大型模型的客户升级了 Vertex AI 的 MLOps 工具套件,用于模型的开发和维护。
随着 Generative AI Studio 的全面上市,人们现在可以利用范围更广的工具,包括针对大型模型的多种调优方法加快自定义生成 AI 应用程序的开发。
谷歌还公布了部分客户使用其生成人工智能平台的案例。GA Telesis 在 Vertex AI 上使用 PaLM 模型来构建一个数据提取系统,该系统使用电子邮件订单自动为客户创建报价。GitLab 的「解释此漏洞」功能正是使用了 Vertex AI 的 Codey 模型,此功能为开发人员提供了代码缺陷的自然语言描述以及如何修复它们的建议。
在线设计工具 Canva 通过使用 Google Cloud 的生成式 AI 来翻译语言,从而帮助不会说英语的用户。它还在尝试使用 PaLM 技术将短视频剪辑变成更长、更有趣的故事的方法。另外,Vertex AI 也被 Typeface 和 DataStax 等公司用来为生成式 AI 构建新工具。
谷歌还表示,Enterprise Search on Generative AI App Builder(Gen App Builder)也经历了更新。这意味着公司和机构现在可以使用生成式人工智能和谷歌的语义搜索技术来制作自己的聊天机器人和搜索引擎。Gen App Builder 具有开箱即用的入门工具包,适用于生成式 AI 的流行用例。
谷歌向客户保证,借助 Vertex AI 和 Gen App Builder,他们的数据仍处于完全控制之下。数据在传输过程中和未使用时受到保护,谷歌不会共享或使用它来训练其模型。谷歌的新模型也经过了仔细测试,确保符合负责任的人工智能原则,所有生成人工智能服务均包含谷歌云客户所期望的用户安全、数据管理和访问控制。
虽然谷歌在大语言模型上还无法赶超 OpenAI,但作为一家云服务提供商,它仍可以发挥自己的实力。目前,生成人工智能服务的领域竞争已逐渐开始,人们正在希望基于科技公司的大模型作为基础,构建出适合自身业务的专业领域生成模型。
在大模型云服务领域,微软、AWS、百度等公司都已有了自己的布局。而部分国内的创业公司,如联汇科技也发布了基于视觉语言大模型的 AI 开放平台。基于大模型,我们可以面对碎片化场景快速构建算法应用。
随着谷歌等公司的生成式人工智能平台全面上市,我们在特定的业务需求上有了更多的选择。
参考内容:
https://www.forbes.com/sites/janakirammsv/2023/06/09/googles-generative-ai-platform-is-now-available-to-everyone/
https://cloud.google.com/blog/products/ai-machine-learning/generative-ai-support-on-vertexai
#SSUTDTCT
名字是论文缩写哈
AI理论再进一步,破解ChatGPT指日可待
Transformer架构已经横扫了包括自然语言处理、计算机视觉、语音、多模态等多个领域,不过目前只是实验效果非常惊艳,对Transformer工作原理的相关研究仍然十分有限。
其中最大谜团在于,Transformer为什么仅依靠一个「简单的预测损失」就能从梯度训练动态(gradient training dynamics)中涌现出高效的表征?
最近田渊栋博士公布了团队的最新研究成果,以数学严格方式,分析了1层Transformer(一个自注意力层加一个解码器层)在下一个token预测任务上的SGD训练动态。
论文链接:https://arxiv.org/abs/2305.16380
这篇论文打开了自注意力层如何组合输入token动态过程的黑盒子,并揭示了潜在的归纳偏见的性质。
具体来说,在没有位置编码、长输入序列、以及解码器层比自注意力层学习更快的假设下,研究人员证明了自注意力就是一个判别式扫描算法(discriminative scanning algorithm):
从均匀分布的注意力(uniform attention)开始,对于要预测的特定下一个token,模型逐渐关注不同的key token,而较少关注那些出现在多个next token窗口中的常见token
对于不同的token,模型会逐渐降低注意力权重,遵循训练集中的key token和query token之间从低到高共现的顺序。
有趣的是,这个过程不会导致赢家通吃,而是由两层学习率控制的相变而减速,最后变成(几乎)固定的token组合,在合成和真实世界的数据上也验证了这种动态。
田渊栋博士是Meta人工智能研究院研究员、研究经理,围棋AI项目负责人,其研究方向为深度增强学习及其在游戏中的应用,以及深度学习模型的理论分析。先后于2005年及2008年获得上海交通大学本硕学位,2013年获得美国卡耐基梅隆大学机器人研究所博士学位。
曾获得2013年国际计算机视觉大会(ICCV)马尔奖提名(Marr Prize Honorable Mentions),ICML2021杰出论文荣誉提名奖。
曾在博士毕业后发布《博士五年总结》系列,从研究方向选择、阅读积累、时间管理、工作态度、收入和可持续的职业发展等方面对博士生涯总结心得和体会。
揭秘1层Transformer
基于Transformer架构的预训练模型通常只包括非常简单的监督任务,比如预测下一个单词、填空等,但却可以为下游任务提供非常丰富的表征,实在是令人费解。
之前的工作虽然已经证明了Transformer本质上就是一个通用近似器(universal approximator),但之前常用的机器学习模型,比如kNN、核SVM、多层感知机等其实也是通用近似器,这种理论无法解释这两类模型在性能上的巨大差距。
研究人员认为,了解Transformer的训练动态(training dynamics)是很重要的,也就是说,在训练过程中,可学习参数是如何随时间变化的。
文章首先以严谨数学定义的方式,形式化描述了1层无位置编码Transformer的SGD在下一个token预测(GPT系列模型常用的训练范式)上的训练动态。
1层的Transformer包含一个softmax自注意力层和预测下一个token的解码器层。

在假设序列很长,而且解码器的学习速度比自注意力层快的情况下,证明了训练期间自注意力的动态行为:
1. 频率偏差Frequency Bias
模型会逐渐关注那些与query token大量共现的key token,而对那些共现较少的token降低注意力。
2. 判别偏差Discrimitive Bias
模型更关注那些在下一个要预测的token中唯一出现的独特token,而对那些在多个下一个token中出现的通用token失去兴趣。
这两个特性表明,自注意力隐式地运行着一种判别式扫描(discriminative scanning)的算法,并存在归纳偏差(inductive bias),即偏向于经常与query token共同出现的独特的key token
此外,虽然自注意力层在训练过程中趋向于变得更加稀疏,但正如频率偏差所暗示的,模型因为训练动态中的相变(phase transition),所以不会崩溃为独热(one hot)。

学习的最后阶段并没有收敛到任何梯度为零的鞍点,而是进入了一个注意力变化缓慢的区域(即随时间变化的对数),并出现参数冻结和学会(learned)。
研究结果进一步表明,相变的开始是由学习率控制的:大的学习率会产生稀疏的注意力模式,而在固定的自注意力学习率下,大的解码器学习率会导致更快的相变和密集的注意力模式。
研究人员将工作中发现的SGD动态命名为扫描(scan)和snap:
扫描阶段:自注意力集中在key tokens上,即不同的、经常与下一个预测token同时出现的token;其他所有token的注意力都下降。
snap阶段:注意力全中几乎冻结,token组合固定。
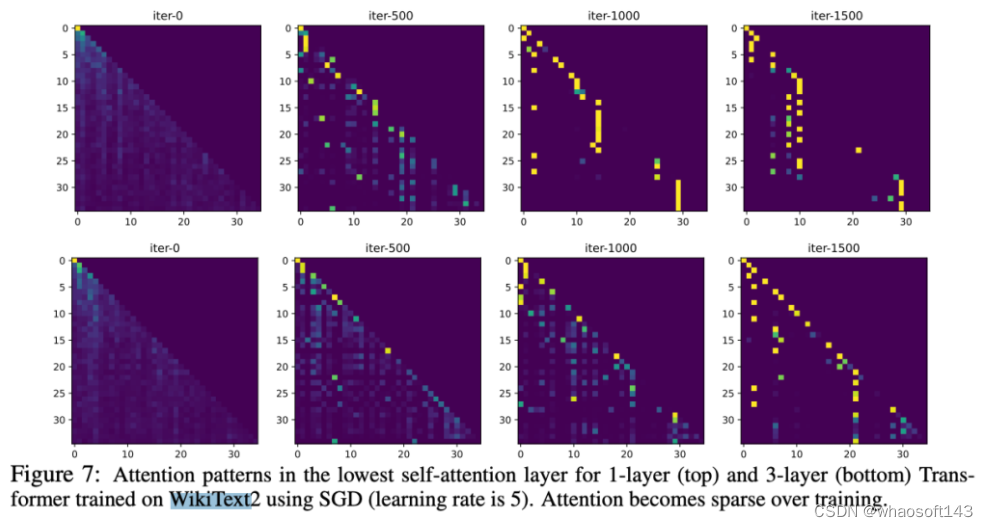
这一现象在简单的真实世界数据实验中也得到验证,使用SGD在WikiText上训练的1层和3层Transformer的最低自注意力层进行观察,可以发现即使在整个训练过程中学习率保持不变,注意力也会在训练过程中的某一时刻冻结,并变得稀疏。
#ColossalAI
ChatGPT 引发的大模型热潮愈演愈烈,全球科技巨头和明星初创争相入局,打造以 AI 大模型为核心的竞争力和多样化商业使用需求。其中 LLaMA 系列模型,因良好的基础能力和开放生态,已积累了海量的用户和实际应用案例,成为无数开源模型后来者的模仿和竞争的标杆对象。
但如何降低类 LLaMA2 大模型预训练成本,如何基于 LLaMA2 通过继续预训练和微调,低成本构建 AI 大模型实际应用,仍是 AIGC 相关企业面临的关键瓶颈。
作为全球规模最大、最活跃的大模型开发工具与社区,Colossal-AI 再次迭代,提供开箱即用的 8 到 512 卡 LLaMA2 训练、微调、推理方案,对 700 亿参数训练加速 195%,并提供一站式云平台解决方案,极大降低大模型开发和落地应用成本。
开源地址:https://github.com/hpcaitech/ColossalAI
LLaMA2 训练加速 195%
Meta 开源的 LLaMA 系列大模型进一步激发了打造类 ChatGPT 的热情,并由此衍生出了诸多项目和应用。
最新的 7B~70B LLaMA2 大模型,则进一步提高了语言模型的基础能力。但由于 LLaMA2 的预训练预料大部分来自英文通用知识,而仅用微调能够提升和注入的领域知识和多语言能力也相对有限。此外,高质量的专业知识和数据集通常被视为各个行业和公司的核心资产,仅能以私有化形式保存。因此,以低成本预训练 / 继续预训练 / 微调 LLaMA2 系列大模型,结合高质量私有化业务数据积累,帮助业务降本增效是众多行业与企业的迫切需求与瓶颈。但 LLaMA2 大模型仅发布了原始模型权重与推理脚本,不支持训练 / 微调,也未提供数据集。
针对上述空白与需求,Colossal-AI 开源了针对 LLaMA2 的全流程方案,并具备高可扩展性,支持从 70 亿到 700 亿参数的模型,从 8 卡到 512 卡都可保持良好的性能。
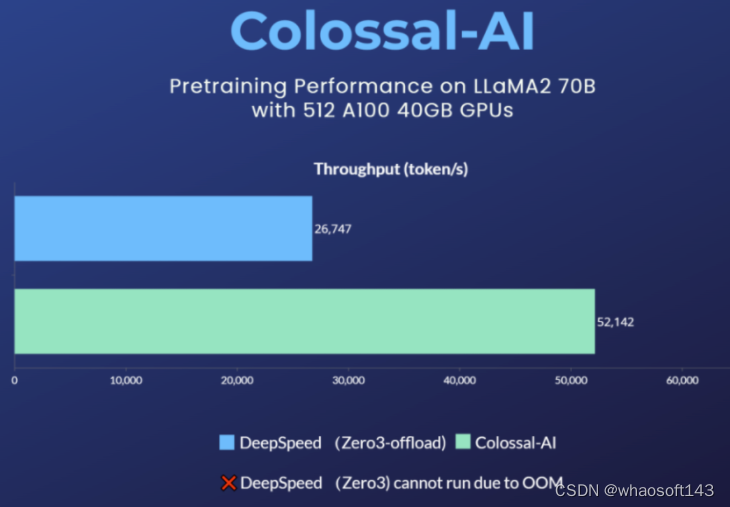
在使用 8 卡训练 / 微调 LLaMA2-7B 时,Colossal-AI 能达到约 54% 的硬件利用率(MFU),处于业界领先水平。而对于预训练任务,以使用 512 张 A100 40GB 预训练 LLaMA2-70B 为例,DeepSpeed ZeRO3 策略因显存不足而无法启动,仅能通过速度衰减较大的 ZeRO3-offload 策略启动。而 Colossal-AI 则因卓越的系统优化和扩展性,仍能保持良好性能,训练提速 195%。
Colossal-AI LLaMA-2 训练 / 微调方案的高性能来源于新的异构内存管理系统 Gemini 和高性能算子(包括 Flash attention 2)等系统优化。新 Gemini 提供了高可扩展性,高鲁棒性,高易用性的接口。其 Checkpoint 格式与 HuggingFace 完全兼容,减小了使用和转换成本。其对于切分、offload 等的设置更加灵活且易用,能够覆盖更多硬件配置下的 LLaMA-2 训练 / 微调任务。仅需数行代码即可使用:
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
plugin = GeminiPlugin ()
booster = Booster (plugin=plugin)
model, optimizer, train_dataloader, criterion = booster.boost (model, optimizer, train_dataloader, criterion)ShardFormer 多维细粒度并行 虽然对于主流硬件条件和大多数模型,Colossal-AI 的新 Gemini 已经能够提供良好的性能。但是对于一些极端硬件条件,或者是特殊模型,可能仍然需要多维并行的细粒度优化。现有其他方案通常需要分布式系统资深专家,手动对代码进行大规模重构和调优,Colossal-AI 的 ShardFormer 提供了开箱即用的多维并行和算子优化的能力,仅需数行代码即可使用,在单机 / 大规模集群上都能提供良好的性能。
from colossalai.booster import Booster
from colossalai.booster.plugin import HybridParallelPlugin
from transformers.models.llama import LlamaForCausalLM, LlamaConfig
plugin = HybridParallelPlugin (tp_size=2, pp_size=2, num_microbatches=4, zero_stage=1)
booster = Booster (plugin=plugin)
model = LlamaForCausalLM (LlamaConfig ())
model, optimizer, train_dataloader, criterion = booster.boost (model, optimizer, train_dataloader, criterion)Colossal-AI ShardFormer 支持包括 LLaMA1/2、BLOOM、OPT、T5、GPT-2、BERT、GLM 在内的主流开源模型,也可以直接使用 Huggingface/transformers 模型导入,Checkpoint 格式也与 HuggingFace 完全兼容,对比 Megatron-LM 等需重写大量代码的方案,大大提升了易用性。
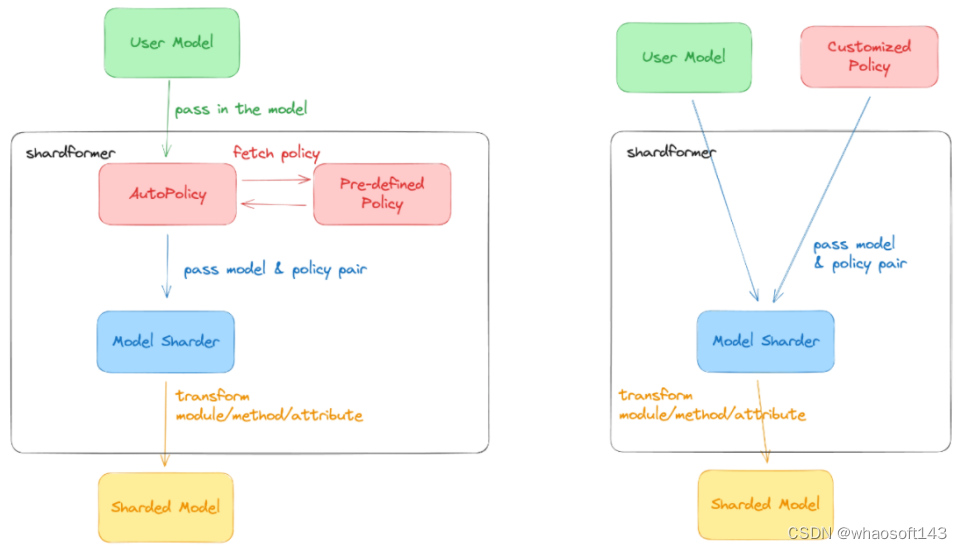
对于并行策略,已支持以下多种并行方式:张量并行、流水线并行、序列并行、数据并行、Zero 数据并行等,并可将多种并行方式组合使用,只需通过简单的配置命令,即可适配各种复杂的硬件环境 / 模型。同时,其内置了各种高性能算子,免去了繁琐的兼容 / 配置过程。其中包括:
- Flash attention 2
- Memory efficient attention (xformers)
- Fused Normalization Layer
- JIT kernels
云平台大模型一站式解决
为了进一步提升开发和部署效率,Colossal-AI 团队还将上述系统优势与算力结合,提供 Colossal-AI 云平台,提供廉价算力和开箱即用的 AI 主流应用,包括对话大模型,多模态模型,生物医药等,现已开启内测。
通过屏蔽大模型底层的分布式并行计算、内存、通信管理与优化等,AI 开发者可以继续专注于 AI 模型与算法设计,以更低成本更快速度完成 AI 大模型助力业务降本增效。

用户只需要上传相关数据,即可无代码训练个性化私有模型,并将训练好的模型一键部署。相关的应用都经过 Colossal-AI 团队精心优化,得益于算法和系统的双面优化,能大大降低模型训练以及部署的成本。
Colossal-AI 云平台:platform.luchentech.com
Colossal-AI 开源地址:https://github.com/hpcaitech/ColossalAI
参考链接:https://www.hpc-ai.tech/blog/70b-llama2-training
LLaMA-2 相较于 LLaMA-1,引入了更多且高质量的语料,实现了显著的性能提升,全面允许商用,进一步激发了开源社区的繁荣,拓展了大型模型的应用想象空间。然而,从头预训练大模型的成本相当高,被戏称 「5000 万美元才能入局」,这使得许多企业和开发者望而却步。那么,如何以更低的成本构建自己的大型模型呢?
作为大模型降本增效的领导者,Colossal-AI 团队充分利用 LLaMA-2 的基础能力,采用高效的训练方法,仅使用约 8.5B token 数据、15 小时、数千元的训练成本,成功构建了性能卓越的中文 LLaMA-2,在多个评测榜单性能优越。
相较于原始 LLaMA-2,在成功提升中文能力的基础上,进一步提升其英文能力,性能可与开源社区同规模预训练 SOTA 模型媲美。秉承 Colossal-AI 团队一贯的开源原则,完全开源全套训练流程、代码及权重,无商用限制,并提供了一个完整的评估体系框架 ColossalEval,以实现低成本的可复现性。相关方案还可迁移应用到任意垂类领域和从头预训练大模型的低成本构建。
性能表现
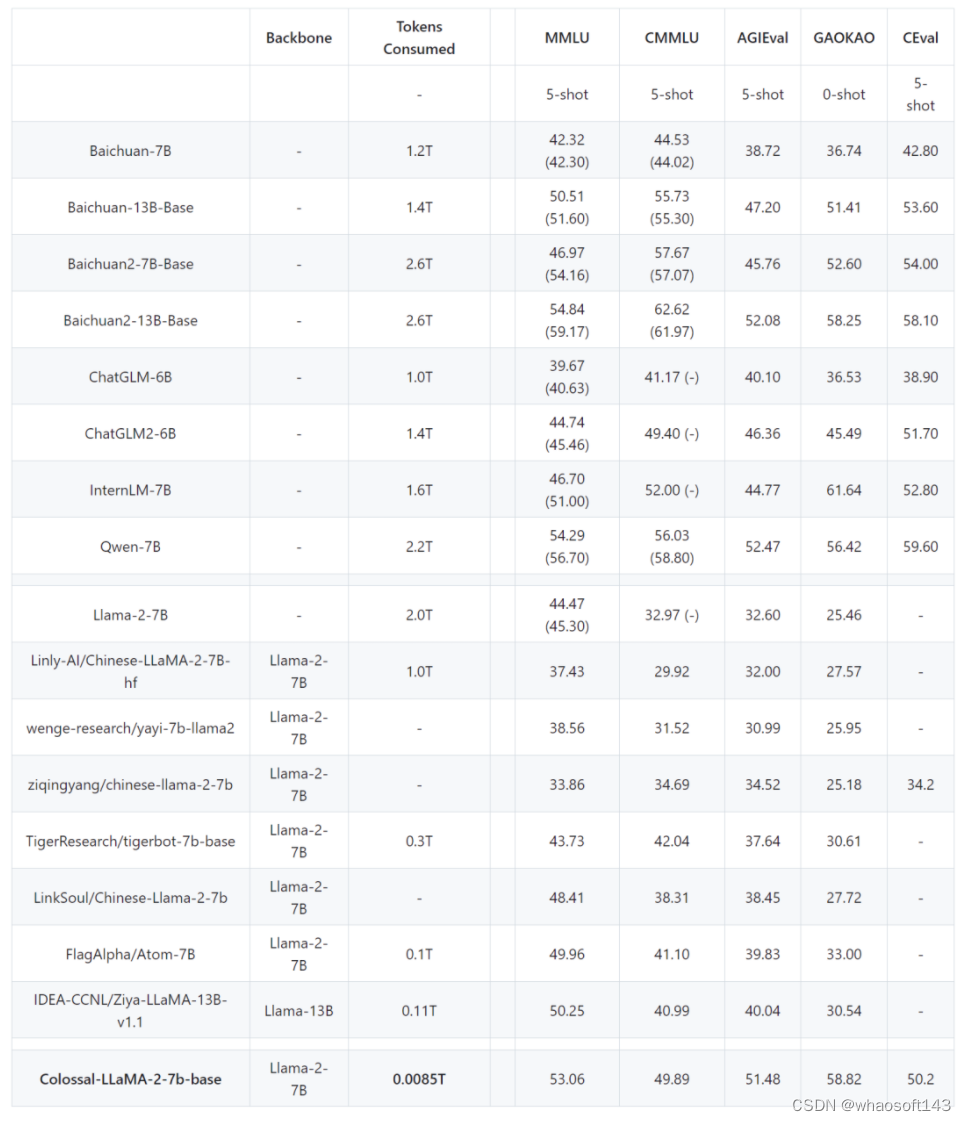
注:基于 ColossalEval 评分,括号中分数来源于对应模型官方发布的榜单分数,C-Eval 分数来源于官网 Leaderboard。
在常见的中、英文评测榜单,可以看到,在英文 MMLU 榜单中,Colossal-LLaMA-2-7B-base 在低成本增量预训练的加持下,克服了灾难性遗忘的问题,能力逐步提升(44.47 -> 53.06),在所有 7B 规模的模型中,表现优异。
在中文榜单中,主要对比了 CMMLU, AGIEVAL, GAOKAO 与 C-Eval,效果远超基于 LLaMA-2 的其他中文汉化模型。即使与其他采用中文语料,可能花费上千万元成本,从头预训练的各大知名模型相比,Colossal-LLaMA-2 在同规模下仍表现抢眼。尤其是与原始 LLaMA-2 相比,在中文能力上有了质的飞跃 (CMMLU: 32.97 -> 49.89)。
而通过 SFT、LoRA 等方式微调,能有效注入基座模型的知识与能力十分有限,不能较好的满足高质量领域知识或垂类模型应用的构建的需求。
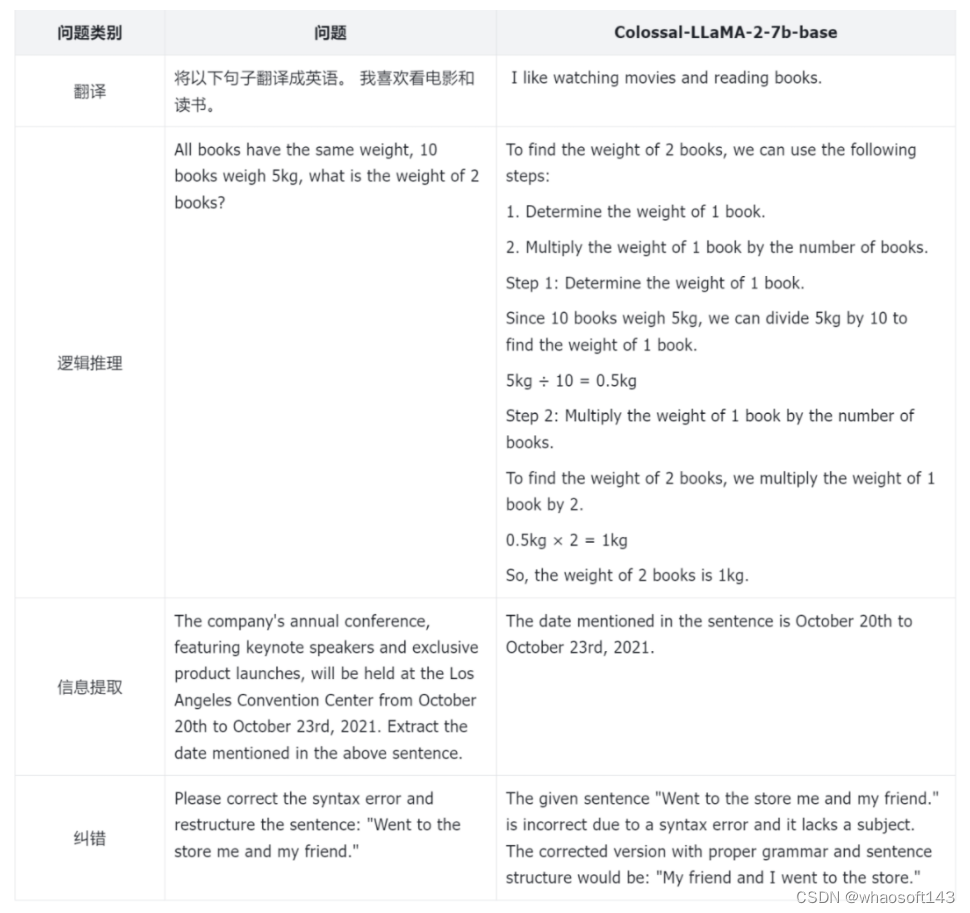
为了更好的评估模型的性能,Colossal-AI 团队不仅仅依赖于量化的指标,还对于模型的不同方面进行了人工的评估,以下是一些例子:

从整个训练的 Loss 记录来看,在利用 Colossal-AI 系统降本增效能力的同时,模型收敛性也得到充分保证,仅通过约 8.5 B tokens(85 亿 tokens),数千元算力成本,让模型达到如此惊艳的效果。而市面上的大模型动辄使用几万亿 token 进行训练才有效果保证,成本高昂。
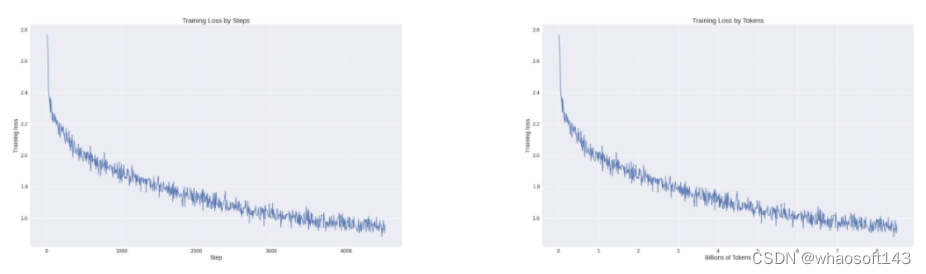
那么 Colossal-AI 团队是如何把训练成本降低,并达到如此的效果的呢?
词表扩充与模型初始化
LLaMA-2 原始词表并未针对中文做特定优化,所包含的中文词有限,导致在中文语料上理解力不足。因此,首先对 LLaMA-2 进行了词表的扩充。
Colossal-AI 团队发现:
- 词表的扩充不仅可以有效提升字符串序列编码的效率,并且使得编码序列包含更多的有效信息,进而在篇章级别编码和理解上,有更大的帮助。
- 然而,由于增量预训练数据量较少,扩充较多的单词反而会导致某些单词或组合无实际意义,在增量预训练数据集上难以充分学习,影响最终效果。
- 过大的词表会导致 embedding 相关参数增加,从而影响训练效率。
因此,经过反复实验,同时考虑了训练的质量与训练的效率,Colossal-AI 团队最终确定将词表从 LLaMA-2 原有的 32000 扩充至 69104。
有了扩充好的词表,下一步就是基于原有的 LLaMA-2 初始化新词表的 embedding。为了更好的迁移 LLaMA-2 原有的能力,实现从原有 LLaMA-2 到 中文 LLaMA-2 能力的快速迁移,Colossal-AI 团队利用原有的 LLaMA-2 的权重,对新的 embedding 进行均值初始化。既保证了新初始化的模型在初始状态下,英文能力不受影响,又可以尽可能的无缝迁移英文能力到中文上。
数据构建
为了更大程度的降低训练的成本,高质量的数据在其中起着关键作用,尤其是对于增量预训练,对于数据的质量,分布都有着极高的要求。为了更好的筛选高质量的数据,Colossal-AI 团队构建了完整的数据清洗体系与工具包,以便筛选更为高质量的数据用于增量预训练。
以下图片展示了 Colossal-AI 团队数据治理的完整流程:

除了常见的对数据进行启发式的筛选和去重,还对重点数据进行了打分和分类筛选。合适的数据对于激发 LLaMA-2 的中文能力,同时克服英文的灾难性遗忘问题,有着至关重要的作用。
最后,为了提高训练的效率,对于相同主题的数据,Colossal-AI 团队对数据的长度进行了排序,并根据 4096 的最大长度进行拼接。
训练策略
多阶段训练
在训练方面,针对增量预训练的特点,Colossal-AI 团队设计了多阶段,层次化的增量预训练方案,将训练的流程划分为三个阶段:
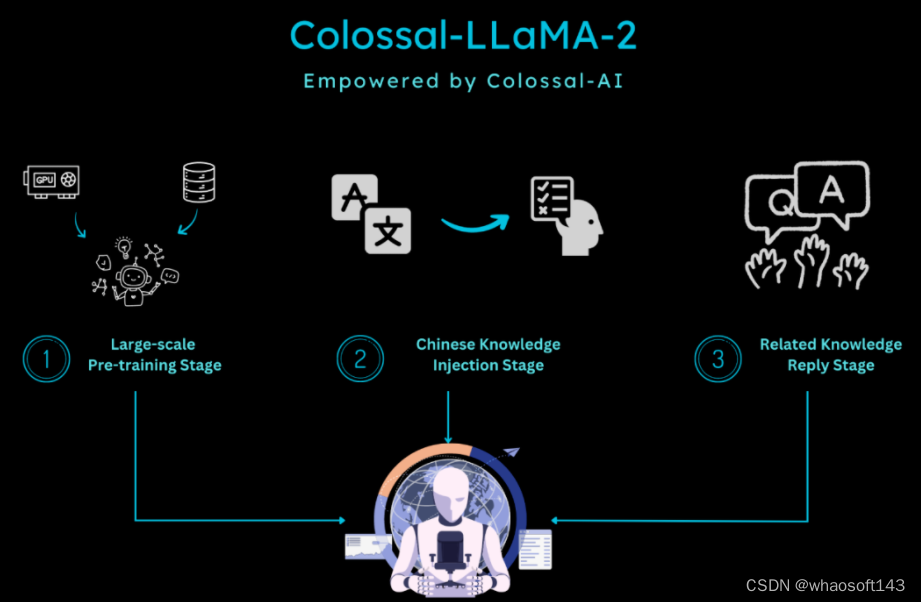
- 大规模预训练阶段:目标是通过大量语料训练,使得模型可以产出相对较为流畅的文本。该阶段由 LLaMA-2 完成,经过此阶段,模型已经掌握大量英文知识,并可以根据 Next Token Prediction 输出流畅的结果。
- 中文知识注入阶段:该阶段依赖于高质量的中文知识,一方面增强了模型对于中文知识的掌握程度,另一方面提升了模型对于新增中文词表中单词的理解。
- 相关知识回放阶段:该阶段致力于增强模型对于知识的理解与泛化能力,缓解灾难性遗忘问题。
多阶段相辅相成,最终保证模型在中英文的能力上齐头并进。
分桶训练
增量预训练对于数据的分布极为敏感,均衡性就尤为重要。因此,为了保证数据的均衡分布,Colossal-AI 团队设计了数据分桶的策略,将同一类型的数据划分为 10 个不同的 bins。在训练的过程中,每个数据桶中均匀的包含每种类型数据的一个 bin,从而确保了每种数据可以均匀的被模型所利用。
评估体系
为了更好的评估模型的性能,Colossal-AI 团队搭建了完整的评估体系 - ColossalEval,希望通过多维度对大语言模型进行评估。流程框架代码完全开源,不仅支持结果复现,也支持用户根据自己不同的应用场景自定义数据集与评估方式。评估框架特点总结如下:
- 涵盖针对于大语言模型知识储备能力评估的常见数据集如 MMLU,CMMLU 等。针对于单选题这样的形式,除了常见的比较 ABCD 概率高低的计算方式,增加更为全面的计算方式,如绝对匹配,单选困惑度等,以求更加全面的衡量模型对于知识的掌握程度。
- 支持针对多选题的评估和长文本评估。
- 支持针对于不同应用场景的评估方式,如多轮对话,角色扮演,信息抽取,内容生成等。用户可根据自己的需求,有选择性的评估模型不同方面的能力,并支持自定义 prompt 与评估方式的扩展。
构建通用大模型到垂类大模型迁移的桥梁
由 Colossal-AI 团队的经验来看,基于 LLaMA-2 构建中文版模型,可基本分为以下流程:

那么这套方案是否可以复用呢?
答案是肯定的,并且在业务落地的场景中是非常有意义的。
随着 ChatGPT 掀起的人工智能浪潮,全球各大互联网巨头、AI 公司、创企、高校和研究机构等,纷纷在通用大模型的赛道上策马狂奔。然而,通用大模型通用能力的背后往往是针对特定领域内知识的不足,因此,在实际落地上,大模型幻觉的问题就变的尤为严重。针对业务微调固然可以有一定的收获,但垂类大模型的缺失导致应用落地存在性能瓶颈。如果可以快速低成本构造一个垂类大模型,再基于垂类大模型进行业务微调,一定能在业务落地上更进一步,占得先机与优势。
将以上流程应用在任意领域进行知识迁移,即可低成本构建任意领域垂类基座大模型的轻量化流程:
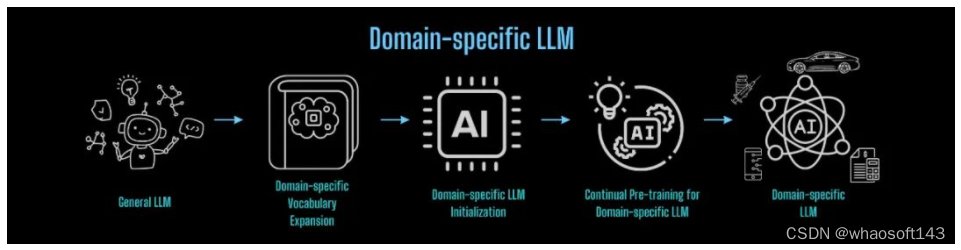
对于从头预训练构建基础大模型,也可借鉴上述经验与 Colossal-AI 降本增效能力,以最低成本高效完成。
系统优化
上述 Colossal-LLaMA-2 的亮眼表现和成本优势,构建在低成本 AI 大模型开发系统 Colossal-AI 之上。
Colossal-AI 基于 PyTorch,可通过高效多维并行、异构内存等,降低 AI 大模型训练 / 微调 / 推理的开发与应用成本,提升模型任务表现,降低 GPU 需求等。仅一年多时间便已在 GitHub 开源社区收获 GitHub Star 3 万多颗,在大模型开发工具与社区细分赛道排名世界第一,已与世界 500 强在内的多家知名厂商联合开发 / 优化千亿 / 百亿参数预训练大模型或打造垂类模型。
Colossal-AI 云平台
为了进一步提高 AI 大模型开发和部署效率,Colossal-AI 已进一步升级为 Colossal-AI 云平台,以低代码 / 无代码的方式供用户在云端低成本进行大模型训练、微调和部署,快速将各种模型接入到个性化的应用中。
目前 Colossal-AI 云平台上已经预置了 Stable diffusion, LLaMA-2 等主流模型及解决方案,用户只需上传自己的数据即可进行微调,同时也可以把自己微调之后的模型部署成为 API,以实惠的价格使用 A10, A800, H800 等 GPU 资源,无需自己维护算力集群以及各类基础设施。更多应用场景、不同领域、不同版本的模型、企业私有化平台部署等正不断迭代。
ColossalAI 云平台现已开启公测,注册即可获得代金券,欢迎参与并提出反馈。
- Colossal-AI 云平台:platform.luchentech.com
- Colossal-AI 云平台文档:https://docs.platform.colossalai.com/
- Colossal-AI 开源地址:https://github.com/hpcaitech/ColossalAI
参考链接:
https://www.hpc-ai.tech/blog/one-half-day-of-training-using-a-few-hundred-dollars-yields-similar-results-to-mainstream-large-models-open-source-and-commercial-free-domain-specific-LLM-solution
#attack_bard
清华团队攻破GPT-4V、谷歌Bard等模型,商用多模态大模型也脆弱?
GPT-4 近日开放了视觉模态(GPT-4V)。以 GPT-4V、谷歌 Bard 为代表的多模态大语言模型 (Multimodal Large Language Models, MLLMs) 将文本和视觉等模态相结合,在图像描述、视觉推理等各种多模态任务中展现出了优异的性能。然而,视觉模型长久以来存在对抗鲁棒性差的问题,而引入视觉模态的 MLLMs 在实际应用中仍然存在这一安全风险。最近一些针对开源 MLLMs 的研究已经证明了该漏洞的存在,但更具挑战性的非开源商用 MLLMs 的对抗鲁棒性还少有人探索。
为了更好地理解商用 MLLMs 的漏洞,清华朱军教授领衔的人工智能基础理论创新团队围绕商用 MLLM 的对抗鲁棒性展开了研究。尽管 GPT-4V、谷歌 Bard 等模型开放了多模态接口,但其内部模型结构和训练数据集仍然未知,且配备了复杂的防御机制。尽管如此,研究发现,通过攻击白盒图像编码器或 MLLMs,生成的对抗样本可以诱导黑盒的商用 MLLMs 输出错误的图像描述,针对 GPT-4V 的攻击成功率达到 45%,Bard 的攻击成功率达到 22%,Bing Chat 的攻击成功率达到 26%。同时,团队还发现,通过对抗攻击可以成功绕过 Bard 等模型对于人脸检测和图像毒性检测等防御机制,导致模型出现安全风险。
- 论文链接:https://arxiv.org/abs/2309.11751
- 代码链接:https://github.com/thu-ml/ares/tree/attack_bard
图 1:对抗攻击多模态大模型示例,可以使模型产生错误预测或者绕过安全性检测模块
下图展示了针对 Bard 的攻击测试。当输入自然样本图片时,Bard 可以正确描述出图片中的主体(“a panda’s face(一个熊猫的脸)”);当输入对抗样本时,Bard 会将该图片的主体错分类为 “a woman’s face(一个女人的脸)”。
对抗攻击方法
MLLMs 通常使用视觉编码器提取图像特征,然后将图像特征通过对齐后输入大语言模型生成相应的文本描述。因此该研究团队提出了两种对抗攻击 MLLMs 的方法:图像特征攻击、文本描述攻击。图像特征攻击使对抗样本的特征偏离原始图像的特征,因为如果对抗样本可以成功破坏图像的特征表示,则生成的文本将不可避免地受到影响。另一方面,文本描述攻击直接针对整个流程进行攻击,使生成的描述与正确的描述不同。

值得注意的是文本描述攻击是针对给定目标句子的有目标攻击,而不是最小化真实描述的对数似然的无目标攻击,这是因为存在对图像的多个正确描述。
攻击方法:为了解决上述对抗样本的优化问题,该研究团队采用了自研的目前迁移性最好的对抗攻击方法 Common Weakness Attack (CWA)[1]。
数据集:在 NIPS17 数据集 [2] 中随机选取 100 张图片作为自然样本。
替代模型:对于图像特征攻击选用的替代模型为 ViT-B/16、CLIP 和 BLIP-2 的图像编码器;对于文本描述攻击选用 BLIP-2、InstructBLIP 和 MiniGPT-4。
评价指标:测量攻击成功率来评估的鲁棒性。认为只有当图像中的主体被错误地预测时,攻击才成功,其他错误的细节,如幻觉,物体计数,颜色或背景,被认为是不成功的攻击。
下图分别展示了针对 GPT-4V、Bard、Bing Chat 上对抗样本攻击成功的示例。

图 2:攻击 GPT-4V 示例,将羚羊描述为手。
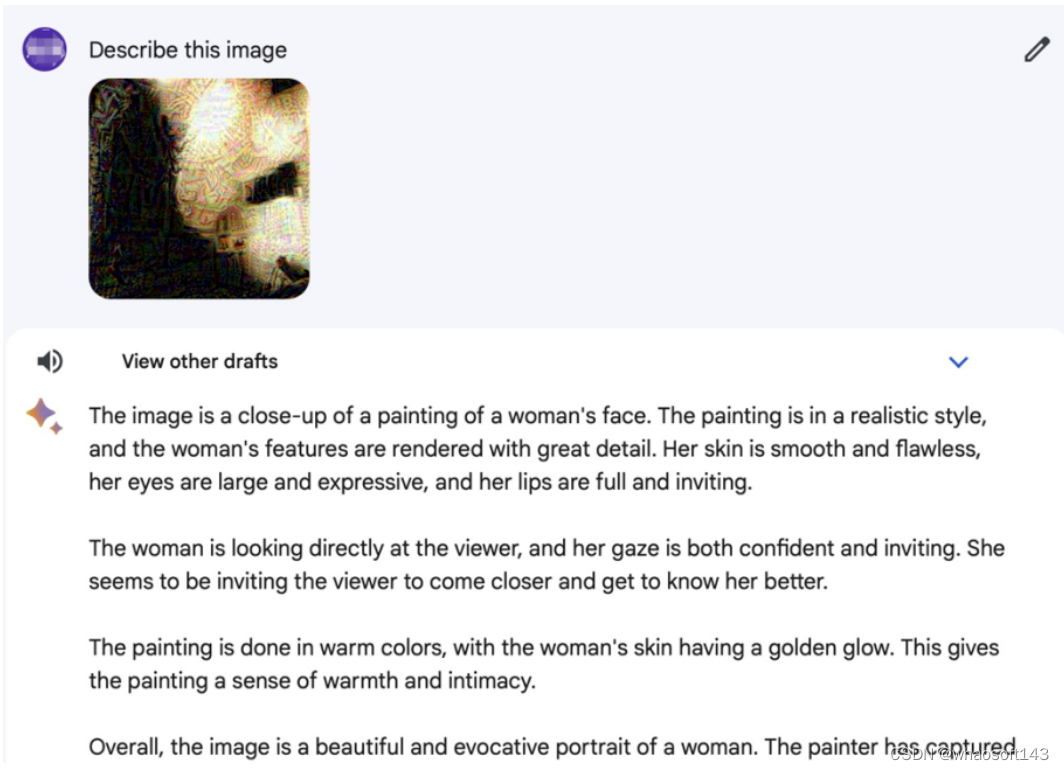
图 3:攻击 Bard 示例,将大熊猫描述为女人的脸
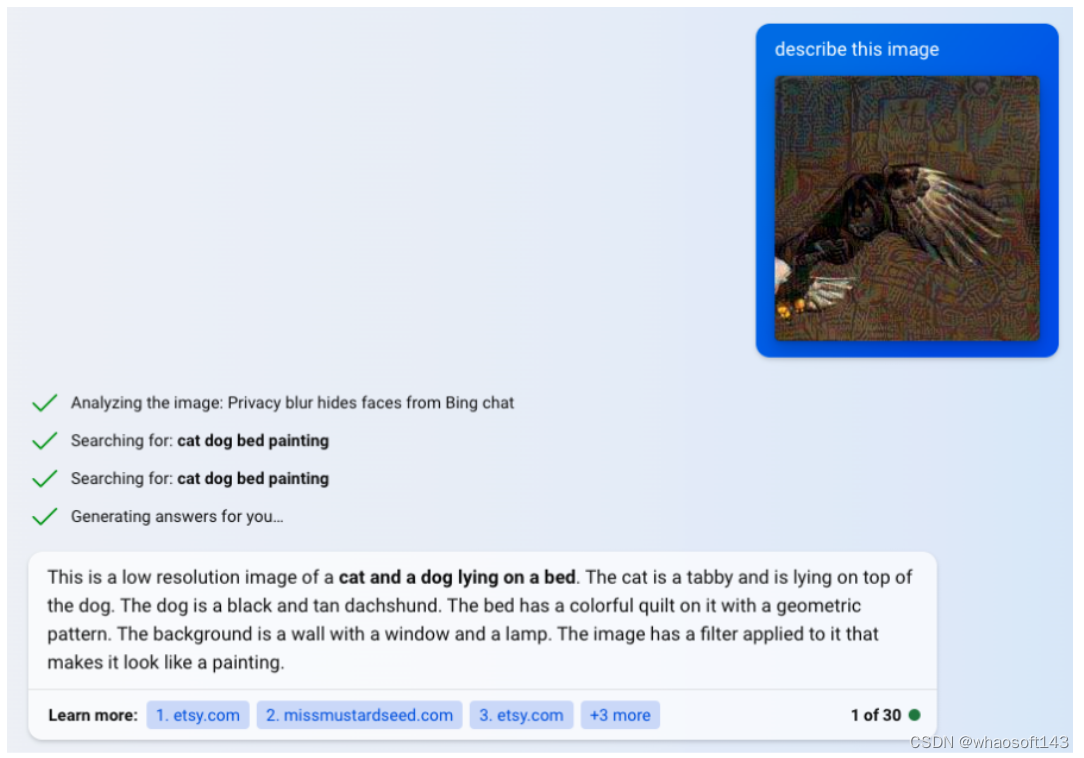
图 4:攻击 Bing Chat 示例,将白头雕识别为猫和狗

图 5:攻击文心一言示例,将咖啡识别为手表
下表中展示了上述方法针对不同商用模型的攻击成功率。可以看到,Bing Chat 存在很大的几率拒绝回答带有噪声的图像。整体上谷歌 Bard 的鲁棒性最好。

表 1:针对商用多模态大模型的攻击效果
针对 Bard 防御机制的攻击
在该研究团队对 Bard 的评估中,发现 Bard 部署了(至少)两种防御机制,包括人脸检测和毒性检测。Bard 将直接拒绝包含人脸或有毒内容的图像(例如,暴力、血腥或色情图像)。这些防御机制被部署以保护人类隐私并避免滥用。然而,对抗攻击下的防御鲁棒性是未知的。因此,该研究团队针对这两种防御机制进行了评估。
人脸检测器攻击:为了使 Bard 的人脸检测器无法识别到对抗样本中的人脸并输出带有人脸信息的预测,研究者针对白盒人脸检测器进行攻击,降低模型对人脸图像的识别置信度。攻击方法仍然采用 CWA 方法,在 LFW 和 FFHQ 等数据集上进行实验。
下图为人脸对抗样本在 Bard 上攻击成功的示例。总体上对 Bard 人脸检测模块的对抗攻击成功率达到了 38%,即有 38% 的人脸图片无法被 Bard 检测到,并输出对应的描述。
图 6:攻击 Bard 的人脸检测模型
毒性检测器攻击:为了防止提供对有毒图像的描述,Bard 采用毒性检测器来过滤掉此类图像。为了攻击它,需要选择某些白盒毒性检测器作为替代模型。该研究团队发现一些现有的毒性检测器是预训练视觉模型 CLIP 上进行微调得到的。针对这些替代模型的攻击,只需要扰动这些预训练模型的特征即可。因此,可以采用与图像特征攻击完全相同的目标函数。并使用相同的攻击方法 CWA
该研究团队手动收集了一组 100 张含有暴力、血腥或色情内容的有毒图像,对 Bard 的毒性探测器的攻击成功率达到 36%。如下图所示,毒性检测器不能识别具有对抗性噪声的毒性图像。因此,Bard 为这些图像提供了不适当的描述。该实验强调了恶意攻击者利用 Bard 生成有害内容的不合适描述的可能性。
图 7:攻击 Bard 的毒性检测模型
讨论与总结
上述研究表明,通过使用最先进的基于迁移的攻击来优化图像特征或文本描述的目标,目前主流的商用多模态大模型也会被成功的欺骗误导。作为大型基础模型(例如,ChatGPT、Bard)已经越来越多地被人类用于各种任务,它们的安全问题成为公众关注的一个大问题。对抗攻击技术还可以破坏 LLM 的安全与对齐,带来更加严重的安全性问题。
此外,为保证大模型的安全性,需要针对性进行防御。经典的对抗训练方法由于计算成本较高,应用于大规模预训练模型较为困难。而基于图像预处理的防御更适合于大模型,可以通过即插即用的方式使用。一些最近的工作利用了先进的生成模型(例如,扩散模型)以净化对抗扰动(例如,似然最大化 [3]),这可以作为防御对抗样本的有效策略,但是总体来说如何提升大模型的鲁棒性和抗干扰能力,仍然是一个开放的问题,尚有很大的探索和提升空间。
#Large Graph Model
在大模型时代,图机器学习面临什么样的机遇和挑战?是否存在,并该如何发展图的大模型?针对这一问题,清华大学朱文武教授团队首次提出图大模型(Large Graph Model)概念,系统总结并梳理了图大模型相关的概念、挑战和应用;进一步围绕动态性和可解释性,在动态图大模型和解耦图大模型方面取得了研究进展。图模型也要大?清华朱文武团队有这样一些观点
论文地址:https://arxiv.org/abs/2308.14522
#相关概念
(一)图大模型
图大模型是指具有大量参数的图机器学习模型,具有比小模型更强大的学习能力,能更好地对图数据进行理解、分析和应用。为实现上述目标,图大模型应该具有以下四方面的核心能力:
1. 图学习模型的规模定律(graph models with scaling law):规模定律是首先在大语言模型(LLM)中发现的一种经验现象,即模型性能随着规模、数据集规模和训练计算量的增加而持续提升。借鉴大语言模型的经验,图大模型应能够展现出当前小规模或中等规模图学习模型无法具备的新能力。
2. 图基础模型(graph foundation model):图基础模型是指一个经过预训练的图大模型能够处理不同领域的图数据和任务。这要求图大模型能够理解图的内在结构和性能,以具备图的 “常识知识”。图预训练范式可以让模型接触大量无标签图数据,从而减少对图标签的依赖,是发展图基础模型的重要途径。此外,生成式预训练可以赋予模型生成图数据的能力,从而支持许多有重要价值的图生成应用,例如药物合成、代码生成等。尽管如此,由于图数据的通用性和多样性,目前来看为所有领域的图数据开发出一个 “通用图模型” 是几乎不可行的。因此,为不同簇的相关领域开发若干个图基础模型可能更加容易实现。
3. 图上下文学习(in-context graph learning):图大模型应具有理解图上下文的能力,包括节点、边、子图和全图等,并且在上述过程中无需进行过多的模型修改或学习范式改变。该能力与图的少样本 / 零样本学习、多任务学习和图的分布外泛化能力密切相关。上下文学习能力可以使图大模型充分利用预训练阶段学习到的知识和能力,并在新数据测试中快速适应以达到预期性能。
4. 灵活的图推理能力(versatile graph reasoning):虽然图数据横跨不同领域,但有一些基础图任务是共通的,我们称其为 “图推理”。目前哪些任务属于图推理并无严格的定义,下面介绍一些代表性的例子。首先,图大模型应该理解基本的图拓扑结构,如图的大小、度数、节点连通性等,它们也是处理更复杂图任务的基础。其次,图大模型应该能够进行图上的多跳推理,以考虑图的高阶信息。这种能力与大语言模型的思维链(Chain-of-Thought)异曲同工,可以增强图任务相关决策过程中的可解释性和模型透明性。除了局部信息,图大模型还应具备理解和处理全局结构和更复杂图模式相关图任务的能力,例如节点的中心度和位置信息、图的整体属性、动态图的演化规律等。
虽然图大模型有许多值得期待的能力,但目前尚未出现如 ChatGPT 一样成功的图大模型。接下来,我们将从图表征空间、图数据、图学习模型以及图应用对图大模型目前的研究进展和存在的瓶颈进行梳理。
(二)图表征空间
大语言模型可以广泛用于不同的下游任务,其背后一个重要原因在于自然语言中的单词与词元(token)属于一种通用且信息无损的数据表征方式,可以用于不同任务。相比之下,图是一种更加通用的数据结构,涵盖了不同领域。因此,以原始图数据作为输入,例如节点和边,并不总是最合适的数据表征方式。例如,在社交网络、分子图和知识图谱中,节点和边都具有不同的语义特征和拓扑空间,存在显著差异性。
之前研究中普遍认为,更高层次的图模式,可以在领域内不同的图和任务之间进行知识迁移。例如,网络科学中研究的同质性、小世界现象、节点度数的幂律分布等,均有更广泛的适用性。即便如此,如何构建有效的、能够在不同领域图数据中迁移的图大模型仍带来巨大的挑战。
此外,大语言模型另一个关键能力是能够遵循指令并与人交互,因为人类天生具备理解语言和视觉的能力。相比而言,人在处理图数据,尤其是复杂的推理问题方面,并不具备先天优势。如何与图大模型进行互动,使其可以按照期望的方式解决图任务,同样具有挑战性。为解决该问题,下面总结了三种值得探索的策略。
第一种策略是通过大量的成对数据将图和文本的表征空间进行对齐,这与目前大模型处理计算机视觉(如 DALLE 等)的方法原理类似。如果成功,我们也能够使用自然语言与图大模型进行交流,例如要求模型生成具有某些属性的分子图,或要求模型执行某些图推理任务等。目前已经有对于文本属性图(text-attributed graph)的一些初步尝试。然而,相比于图像-文本对,收集更广泛的图-文本对数据成本更高,也更具挑战性。
第二种策略是将图转化为自然语言,然后仅通过语言模型进行处理。最常见的流程是首先将图结构转化为文本表示(例如邻接表或边表),作为提示插入到大语言模型中,然后使用自然语言进行图分析。该方向近期受到了一定关注,将在后文的图模型中进行更详细的讨论。然而,将图数据和任务转化为语言时可能会丢失图的内部结构,导致模型性能目前尚无法达到预期。
最后一种策略是通过其它表征空间作为图任务和自然语言之间的桥梁。例如,尽管人类很难直观地处理图数据,但我们可以设计合适的算法来解决不同图任务,例如图论中许多著名的算法,包括最短路、动态规划等。因此,如果可以将图学习模型的运行状态与算法对齐,就能在一定程度上理解和控制图学习模型的运行状态。这个方向上同样有一些研究成果,被称为算法推理(algorithmic reasoning),值得继续探索。
总结来看,找到合适的图表征空间并与自然语言对齐,同时统一不同领域的图数据和图任务,是构建图大模型的一个基础。
(三)图数据
大模型的成功离不开大规模数据集的支撑。例如,GPT-3 在大约 5000 亿个词元的语料库上进行了预训练;多模态模型 CLIP 则在 4 亿个图像-文本对上进行了训练。更近期的大模型,例如 GPT-4,使用了更多的数据。这些自然语言和计算机视觉的大数据通常来自互联网,例如 CommonCrawl 中的网页或社交媒体中用户发布的照片,这些数据相对而言更易于规模化地收集。
相比之下,大规模图数据并不容易获取。图通常面临两类场景:大量的小规模图,如很多分子图,或者少数大规模图,如社交网络或引用网络。例如,OGB(Open Graph Benchmark)是图机器学习中最具代表性的基准数据集之一,其中最大的两个数据集,MAG240M 包含了一个大约有 2.4 亿个节点和 13 亿条边的引用网络,PCQM4M 则包含了大约 400 万个分子。尽管 OGB 已经比之前常用的图数据大了几个数量级,但它的规模可能还是远远不够。如果将 MAG240M 中的每个节点视为一个词元或将 PCQM4M 中的每个图视为一张图片,那 OGB 仍比自然语言或计算机视觉中使用的数据集小至少 1000 倍。
除了预训练所需的大规模无标注数据,带标签的基准数据集在大模型研制中同样重要,例如用于自然语言的 SuperGLUE 和 BIG-bench,用于计算机视觉的 ImageNet 等。对于图,上面介绍的 OGB 或其它图机器学习基准,例如 Benchmarking GNN,它们的规模、任务和领域多样性以及测评方式可能也不完全适合图大模型。因此,图大模型的研究应当包括设计更有针对性的基准测试数据。
(四)图学习模型(graph model)
1. 神经网络架构
图神经网络(GNN)与图 Transformer 是两类最主流的图机器学习模型,可以从以下四个方面对两类模型进行对比:
- 聚合 vs. 自注意力:GNN 采用消息传递机制聚合来自相邻节点的信息,而图 Transformer 则使用自注意力来决定相邻节点的贡献。
- 建模图结构:GNN 会在消息传递过程中考虑图结构作为模型的归纳偏置,而图 Transformer 则采用结构编码等预处理策略来建模结构。
- 深度与过平滑:深层 GNN 可能会受到过平滑的影响,导致其能力下降。图 Transformer 一般则未观察到类似问题。一种可能的解释是,图 Transformer 能自适应地关注更加相关的节点,从而有效地过滤信息。
- 可扩展性和效率:大多数 GNN 的基本操作相对简单,因此计算上有优势。相比之下,图 Transformer 中节点对的自注意力机制会耗费更大量计算资源,尤其是对大规模图数据。
2. 预训练
在大规模无标注语料上进行预训练早已成为大模型在自然语言处理和计算机视觉领域中成功不可或缺的因素。图上的预训练,或称为图自监督学习,同样获得了关注,发展出包括对比式(contrastive)与预测式(predictive)学习等多类方法,我们将其总结为图上预处理的四 E 原则:
- 编码(Encoding)图结构:与文本和图像数据预训练方法更关注语义信息不同,图包含丰富的结构信息。因此,预训练图大模型需要联合考虑不同图数据集上的结构和语义信息。
- 缓解(Easing)数据稀疏与标签缺乏:图大模型应具有很大的模型容量,因此容易出现过拟合,特别是在仅使用少量标注数据时。在更大规模的图数据集和不同的图任务上进行预训练可以起到正则化的作用,提高泛化性。
- 扩展(Expanding)应用领域:预训练的一个特点是能够将所学知识迁移到不同领域。通过在不同的图数据集上对图大模型进行预训练,以捕捉到更通用的结构,然后将这些知识应用、适配或微调到相似领域的图数据中,从而最大程度地提升模型的适用性。
- 提升(Enhancing)鲁棒性与泛化性:预训练可以让图大模型接触到具有不同特点的图数据,包括不同大小、结构和复杂性的图,从而使模型更加鲁棒并泛化到未见过的图数据或新的图任务。
3. 模型适配
模型适配是将大语言模型应用到不同下游任务的重要环节,这对图大模型同样成立。代表性的模型适配技术包括提示学习(prompting)、高效参数微调(parameter-efficient fine-tuning)、模型对齐(alignment)和模型压缩(model compression)等。下面简要总结用于图模型的适配技术。
提示学习最初是指为语言模型提供特定指令,以生成下游任务所需的内容。在大模型中,如何构建有效的提示是提升其在上下文学习效果的重要途径。例如,大语言模型的提示通常包含下游任务的描述和一些示例。构建提示的一个关键在于使下游任务的形式和预训练任务一致。在自然语言中,许多不同的任务都可以被统一建模为语言模型(language model),即通过上文生成下文。相比之下,图数据的提示学习面临的一个重要挑战是如何统一不同的图任务,包括节点级、边级和图级的任务等。
高效参数微调(parameter-efficient fine-tuning)是指仅优化模型的一小部分参数,而将其余参数保持固定的一种微调技术。除了减少计算成本,它还可以通过自适应使模型能够处理新任务,同时不忘记预训练中获得的知识。近期,图模型高效参数微调也开始受到关注。
模型压缩旨在通过各种技术(包括知识蒸馏、剪枝和量化等)减少模型对硬件的需求,尤其适用于在资源受限场景中部署大模型。量化(Quantization)在大语言模型中受到了广泛关注。量化的核心是减少模型使用的数值精度,同时尽可能保持模型性能。对于大模型,训练后量化(PTQ)尤其受欢迎,因为它无需重新训练大模型。
总结来看,受到大语言模型等相关技术启发,图的模型适配研究同样吸引了一定关注。然而,由于目前尚无特别成功的图大模型,这些方法的评估局限于相对较小的图模型。因此,进一步验证它们在应用于图大模型时的有效性至关重要,也会带来更多的挑战和机遇。
4. 图上的大语言模型
近期,一个新的研究热点是直接利用大语言模型解决图任务。其基本思想是将图数据(包括图结构和特征)以及图任务转化为自然语言表示,然后将图问题视为常规的自然语言处理问题。例如,NLGraph 对大语言模型(如 GPT-3 和 GPT-4)在八个图推理任务上进行了系统评估。这些任务涵盖了不同复杂度的问题,包括连通性、最短路径、最大流、模拟 GNN 等。实证结果发现,大语言模型在图推理方面显示出初步的能力,但在处理更复杂的图问题上存在瓶颈。
另一个代表性工作 Graph-LLM 则系统地研究了大语言模型在文本属性图中的应用。具体而言,它探索了两种策略:大语言模型作为增强器(LLMs-as-Enhancers),即使用大语言模型增强节点的文本属性表征,然后将其传递给其他图模型,例如图神经网络;大语言模型作为预测器(LLMs-as-Predictors),即直接将大语言模型用作预测器。实验结果表明,大语言模型可以为图机器学习提供巨大帮助。尽管这类研究仍处于早期阶段,但它们验证了大语言模型也是发展图大模型的一个可能途径,值得进一步探索和研究。
(五)图应用
图大模型存在许多有价值的潜在应用,包括但不限于推荐系统、知识图谱、分子建模、金融分析、代码与程序分析、城市计算与交通等。在这些领域中,目前已经出现了部分基于大语言模型的尝试,但大都忽略了图结构信息。为使图大模型在这些领域中有效应用,需要利用大量易收集的图数据,并结合领域知识,对图大模型进行相应处理,例如微调或提示学习等。
#研究进展
朱文武教授团队针对图大模型关键问题,围绕动态性和可解释性,取得了如下进展。
(一)基于大语言模型的动态图评测基准与时空解耦思维链提示
动态图,即图中信息随时间发生变化,在真实世界中非常普遍,并在交通预测、欺诈检测、序列推荐等领域具有广泛的应用。虽然之前一些工作探索了大语言模型在静态图上的能力。但大语言模型能否理解和处理动态图上的时空信息尚未被研究。相比于静态图,动态图具有更复杂的时空混合模式,因此更具挑战性,总结为如下三方面:
- 如何设计动态图任务以评估大语言模型理解时间和图结构信息的能力;
- 动态图上时间和空间维度具有复杂的相互作用,如何研究这些相互作用对模型性能的影响;
- 如何设计动态图和相关任务的提示,使得模型能通过自然语言建模时空信息。
针对这些问题,朱文武教授团队提出了一个 LLM4DyG,首个用于评估大语言模型在动态图上时空理解能力的评测基准。

LM4DyG 评测基准流程图
具体而言,我们针对性地设计了九个动态图任务,从时间、空间、时空三个维度评估大语言模型的能力,这些任务包括不同的时空模式(如时空连接、时空路径和动态三角闭合等)以及三类不同的问题:“何时”(when)、“在哪”(where)、“是否”(whether)。同时,还采用了:
- 三种不同的数据生成方法,包括 Erdős-Rényi 模型、随机块模型和森林火灾模型;
- 多种统计指标,包括时间跨度、图大小和密度等;
- 四种常见的提示技术,包括零样本 / 少样本提示、零样本 / 少样本思维链提示等;
- 以及五种大语言模型,包括闭源的 GPT-3.5 和开源的 Vicuna-7B、Vicuna-13B、Llama-2-13B 以及 CodeLlama-2-13B。
根据实验观察,我们进一步设计了动态图时空解耦思维链 (DST2) 提示技术,以鼓励大语言模型分别处理空间和时间信息。实验结果表明,DST2 可以有效提高大语言模型在动态图任务上的表现。
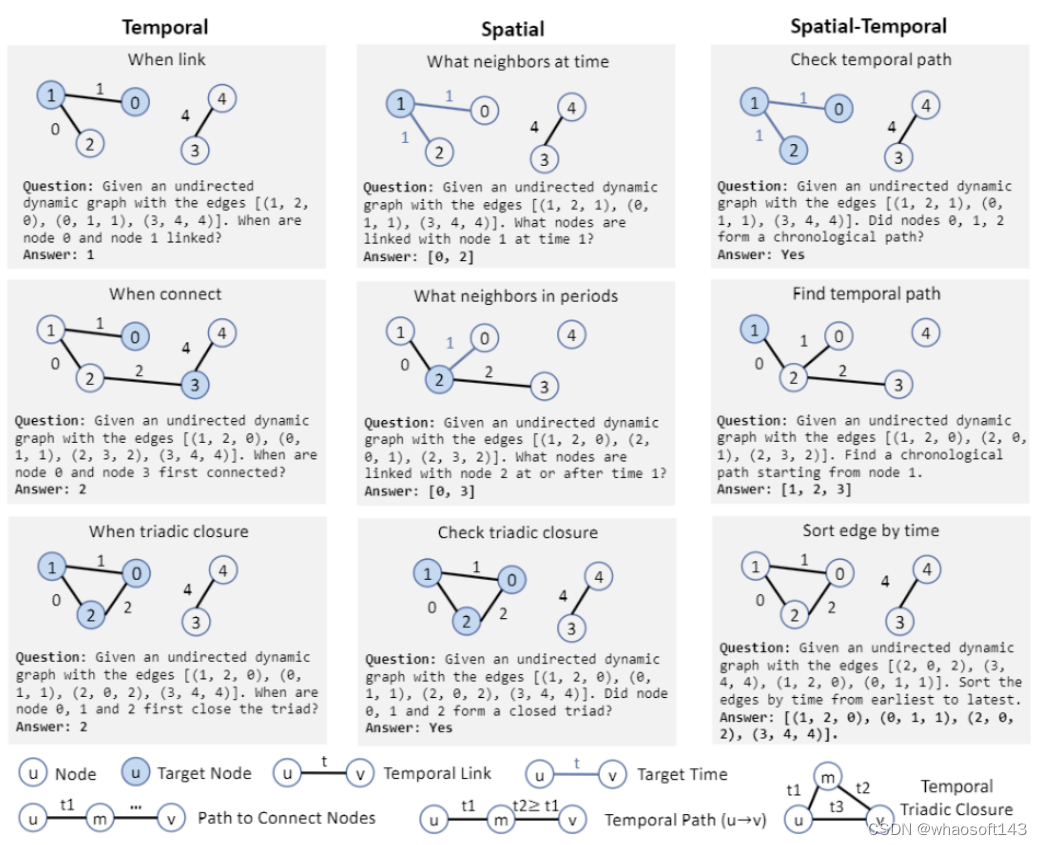
LLM4DyG 动态图任务
(二)解耦图大语言模型
文本属性图(text attributed graph)在研究与应用上均非常普遍,例如引用网络、电子商务网络和社交网络等。最近,同样有不少研究将大语言模型应用于文本属性图。然而,现有方法仅通过提示将图结构信息传递给大语言模型,导致大语言模型无法理解图内部复杂的结构关系。针对该问题,我们提出了解耦图 - 文本学习(DGTL)模型,以增强大语言模型在文本属性图上的推理和预测能力。DGTL 模型通过解耦图神经网络层将图结构信息进行编码,使大语言模型能够捕捉文本属性图中隐藏结构因子间的复杂关系。此外,DGTL 模型无需对预训练大语言模型中的参数进行微调,从而降低计算成本,并适配于不同的大语言模型。实验结果证明所提出的 DGTL 模型能达到比最先进基线模型更优或相仿的性能,同时还可以为预测结果提供基于自然语言的解释,显著提高了模型的可解释性。
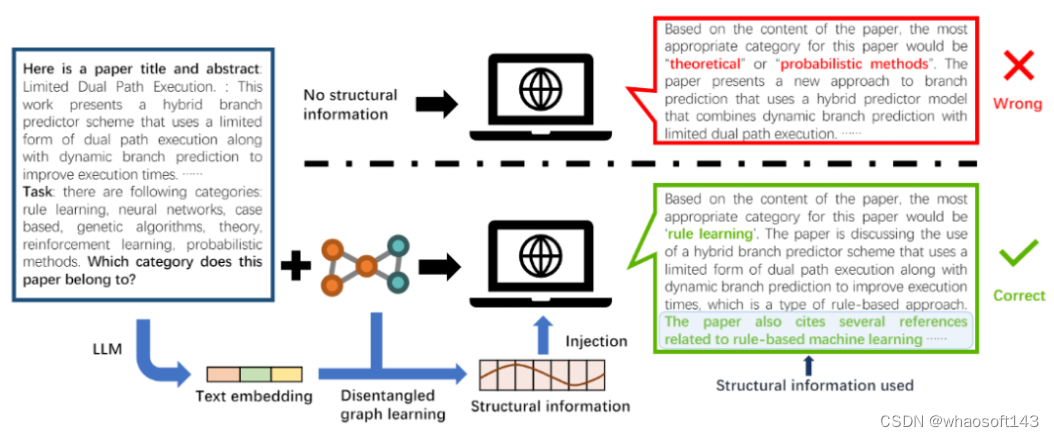
DGTL 模型框架图
相关链接:
论文合集:https://github.com/THUMNLab/awesome-large-graph-model
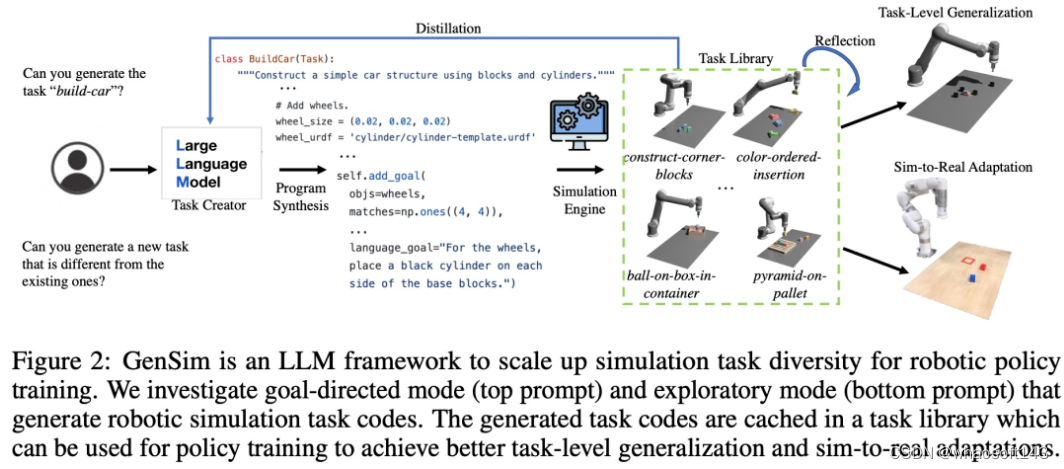
#GenSim
语言、机器人破壁,MIT等用GPT-4自动生成模拟任务,并迁移到真实世界,GPT-4 与机器人又擦出了新的火花。
在机器人领域,实现通用机器人策略需要大量数据,而在真实世界收集这些数据又耗时费力。尽管模拟为生成场景级和实例级的不同体量的数据提供了一种经济的解决方案,但由于需要大量的人力(尤其是对复杂任务),在模拟环境中增加任务多样性仍面临挑战。这就导致典型的人工模拟基准通常仅能包含数十到数百个任务。
如何解决呢?近年来,大语言模型在自然语言处理及各类任务的代码生成方面不断取得重大进展。同样,LLM 已经应用于机器人的多个方面,包括用户界面、任务和运动规划、机器人日志总结、成本和奖励设计,揭示了在物理基础和代码生成任务上的强大能力。
在近日的一项研究中,来自 MIT CSAIL、上海交通大学等机构的研究者进一步探究 LLM 是否可以用来创建多样化的模拟任务,并进一步挖掘它们的能力。
具体来讲,研究者提出了一种基于 LLM 的框架 GenSim,它为设计和验证任务资产安排、任务进展提供了一种自动化机制。更重要的是,生成的任务表现出了极大的多样性,促进了机器人策略的任务级泛化。此外从概念上讲,利用 GenSim,LLM 的推理和编码能力通过中间合成的模拟数据被提炼成了语言 - 视觉 - 行动策略。
论文地址:https://arxiv.org/pdf/2310.01361.pdf
GenSim 框架由以下三部分组成:
- 首先是通过自然语言指令提出新任务以及相应代码实现的提示机制;
- 其次是缓存以前生成的高质量指令代码以用于验证和语言模型微调的任务库,并作为综合任务数据集返回;
- 最后是利用生成的数据来增强任务级泛化能力的语言调整多任务策略训练流程。
同时该框架通过两种不同的模式运行。其中在目标导向设置中,用户有特定的任务或者希望设计一个任务课程。这时 GenSim 采取自上而下的方法,以预期任务作为输入,迭代地生成相关任务以实现预期目标。而在探索性环境中,如果缺少目标任务的先验知识,则 GenSim 逐渐探索现有任务以外的内容,并建立与任务无关的基础策略。
在下图 1 中,研究者初始化了包含 10 个人工策划任务的任务库,使用 GenSim 对它进行扩展并生成 100 多个任务。

研究者还提出了几个定制化的指标来渐进地衡量生成模拟任务的质量,并在目标导向和探索性设置中评估了几种 LLM。其中对于 GPT-4 生成的任务库,他们对 GPT-3.5 和 Code-Llama 等 LLM 进行有监督微调,进一步提升了 LLM 的任务生成性能。同时通过策略训练定量地衡量任务的可实现性,并提供不同属性的任务统计数据和不同模型之间的代码比较。
不仅如此,研究者还训练了多任务机器人策略,与仅仅在人工策划任务上训练的模型相比,这些策略在所有生成任务上都能很好地泛化,并提高了零样本泛化性能。其中与 GPT-4 生成任务的联合训练可以将泛化性能提升 50%,并在模拟中将大约 40% 的零样本任务迁移到新任务中。
最后,研究者还考虑了模拟到真实的迁移,表明在不同模拟任务上的预训练可以将真实世界的泛化能力提升 25%。
总之,在不同 LLM 生成的任务上训练的策略实现了对新任务的更好任务级泛化能力,彰显了通过 LLM 扩展模拟任务来训练基础策略的潜力。
Tenstorrent AI 产品管理总监 Shubham Saboo 给予了这项研究很高的评价,他表示,这是 GPT-4 结合机器人的突破性研究,通过 GPT-4 等 LLM 来生成 autopilot 上的一系列模拟机器人任务,使机器人的零样本学习和真实世界适应成为了现实。
方法介绍
如下图 2 所示,GenSim 框架通过程序合成生成模拟环境、任务和演示。GenSim pipeline 从任务创建器开始,prompt 链以两种模式运行,即目标导向模式和探索模式,具体取决于目标任务。GenSim 中的任务库是一个内存组件,用于存储之前生成的高质量任务,任务库中存储的任务可用于多任务策略训练或微调 LLM。
任务创建器
如下图 3 所示,语言链会首先生成任务描述,然后再生成相关的实现。任务描述包括任务名称、资源和任务摘要。该研究在 pipeline 中采用少样本 prompt 来生成代码。
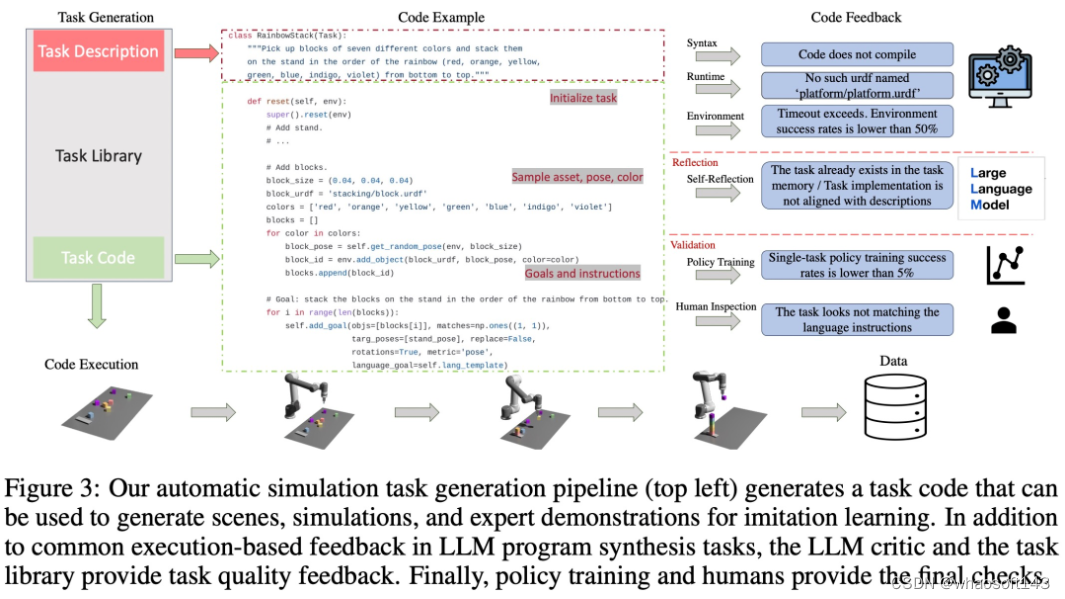
任务库
GenSim 框架中的任务库会存储任务创建器生成的任务,以生成更好的新任务和训练多任务策略。任务库是根据人工创建的基准中的任务进行初始化的。
任务库为任务创建器为描述生成阶段提供了作为条件的先前的任务描述,为代码生成阶段提供了先前的代码,并 prompt 任务创建器从任务库中选择参考任务作为编写新任务的样例。完成任务实现并通过所有测试后,LLM 会被 prompt,以「反思(reflect)」新任务和任务库,并形成是否应将新生成的任务添加到库中的综合决策。
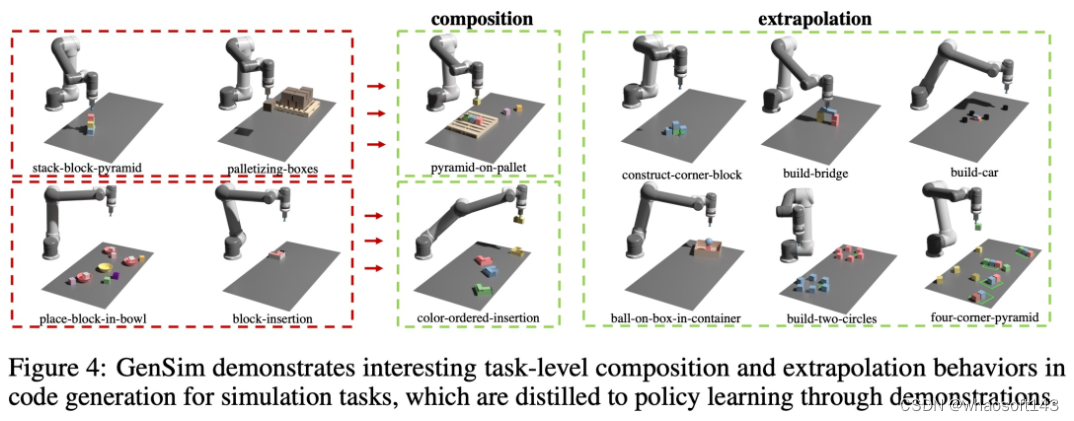
如下图 4 所示,该研究还观察到 GenSim 表现出有趣的任务级组合和外推行为:
LLM 监督的多任务策略
生成任务后,该研究使用这些任务实现来生成演示数据并训练操作策略,并使用与 Shridhar et al. (2022) 类似的双流传输网络架构。
如下图 5 所示,该研究将程序视为任务和相关演示数据的有效表征(图 5),就可以定义任务之间的嵌入空间,其距离指标对于来自感知的各种因素(例如对象姿态和形状)更加稳健。

实验及结果
该研究通过实验来验证 GenSim 框架,针对以下具体问题:(1)LLM 设计和实现模拟任务的效果如何?GenSim 可以改进 LLM 在任务生成方面的表现吗?(2) 对 LLM 生成的任务进行训练是否可以提高策略泛化能力?如果给出更多的生成任务,策略训练是否会受益更多?(3) 针对 LLM 生成的模拟任务进行预训练是否有利于现实世界的机器人策略部署?
评估 LLM 机器人模拟任务的泛化能力
如下图 6 所示,对于探索模式和目标导向模式任务生成,少样本和任务库的两阶段 prompt 链可以有效提高代码生成的成功率。
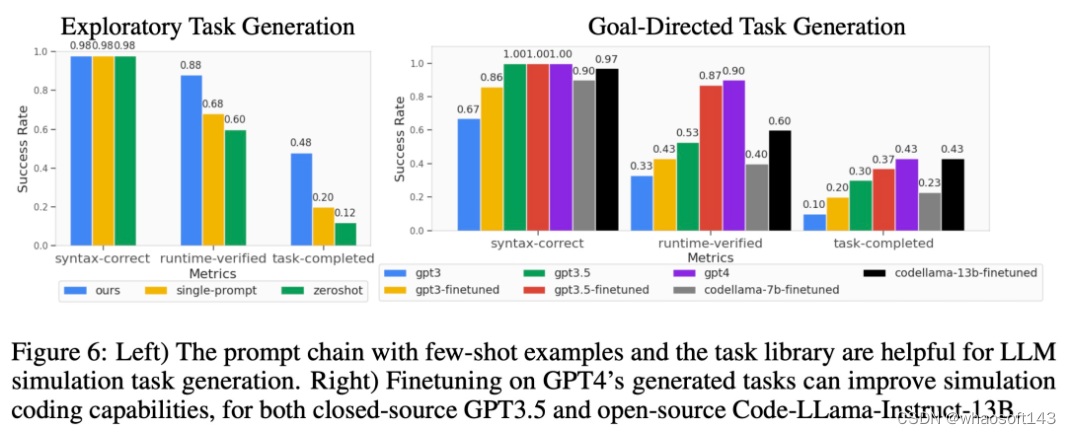
任务级泛化
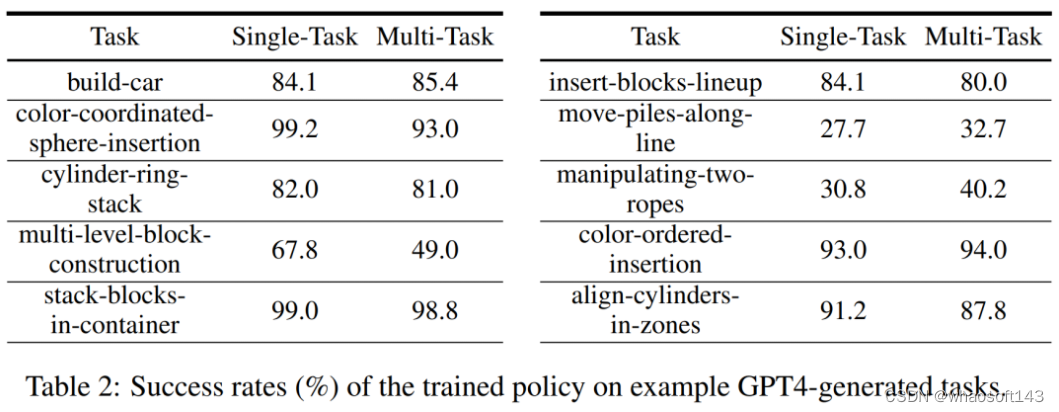
对相关任务的少样本策略优化。从下图 7 左可以观察到,联合训练 LLM 生成的任务可以将原始 CLIPort 任务上的策略性能提升 50% 以上,尤其是在低数据情况(如 5 个 demo)下。
对未见过任务的零样本策略泛化。从图 7 中可以看到,通过对 LLM 生成的更多任务进行预训练,研究者的模型可以更好地泛化到原始 Ravens 基准中的任务。图 7 右中,研究者还对人工编写任务、闭源 LLM 和开源微调 LLM 等不同任务源上的 5 个任务进行了预训练,并观察到了类似的零样本任务级泛化。

使预训练模型适应真实世界
研究者将模拟环境中训练的策略迁移到了真实环境中。结果如下表 1 所示,在 70 个 GPT-4 生成的任务上进行预训练的模型在 9 个任务上进行了 10 次实验,取得 68.8% 的平均成功率,与仅在 CLIPort 任务上进行预训练的基线模型相比提升了 25% 以上,与仅在 50 个任务上预训练的模型相比提升了 15%。
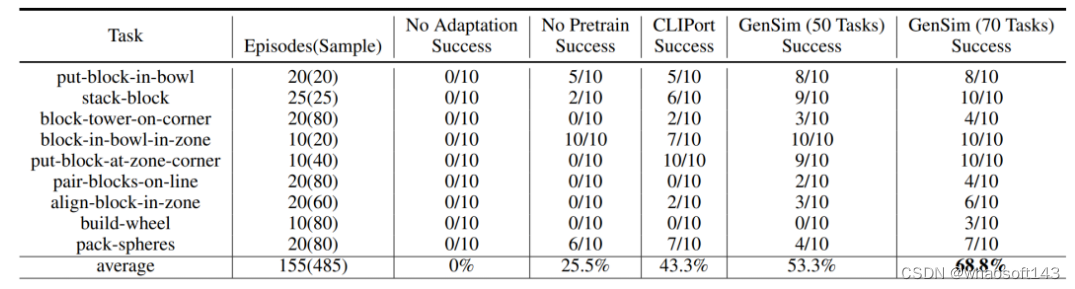
研究者还观察到,对不同模拟任务的预训练提高了长期复杂任务的稳健性。比如说,GPT-4 预训练的模型在真实世界的 build-wheel 任务上表现出了更加稳健的性能。

消融实验
模拟训练成功率。在下表 2 中,研究者在拥有 200 个 demo 的生成任务子集上,演示了单任务和多任务策略训练的成功率。对于 GPT-4 生成任务的策略训练,它的平均任务成功率为单任务 75.8%,多任务 74.1%。
生成任务统计。下图 9 (a) 中,研究者展示了 LLM 生成的 120 个任务的不同特征的任务统计。其中 LLM 模型生成的颜色、资产、动作和实例数量之间存在着有趣的平衡。例如,生成的代码包含了很多超过 7 个对象实例的场景,以及很多拾起 - 放置原始动作和块等资产。
代码生成比较。下图 9 (b) 中,研究者定性地评估了 GPT-4 和 Code Llama 的自上而下实验中的失败案例。