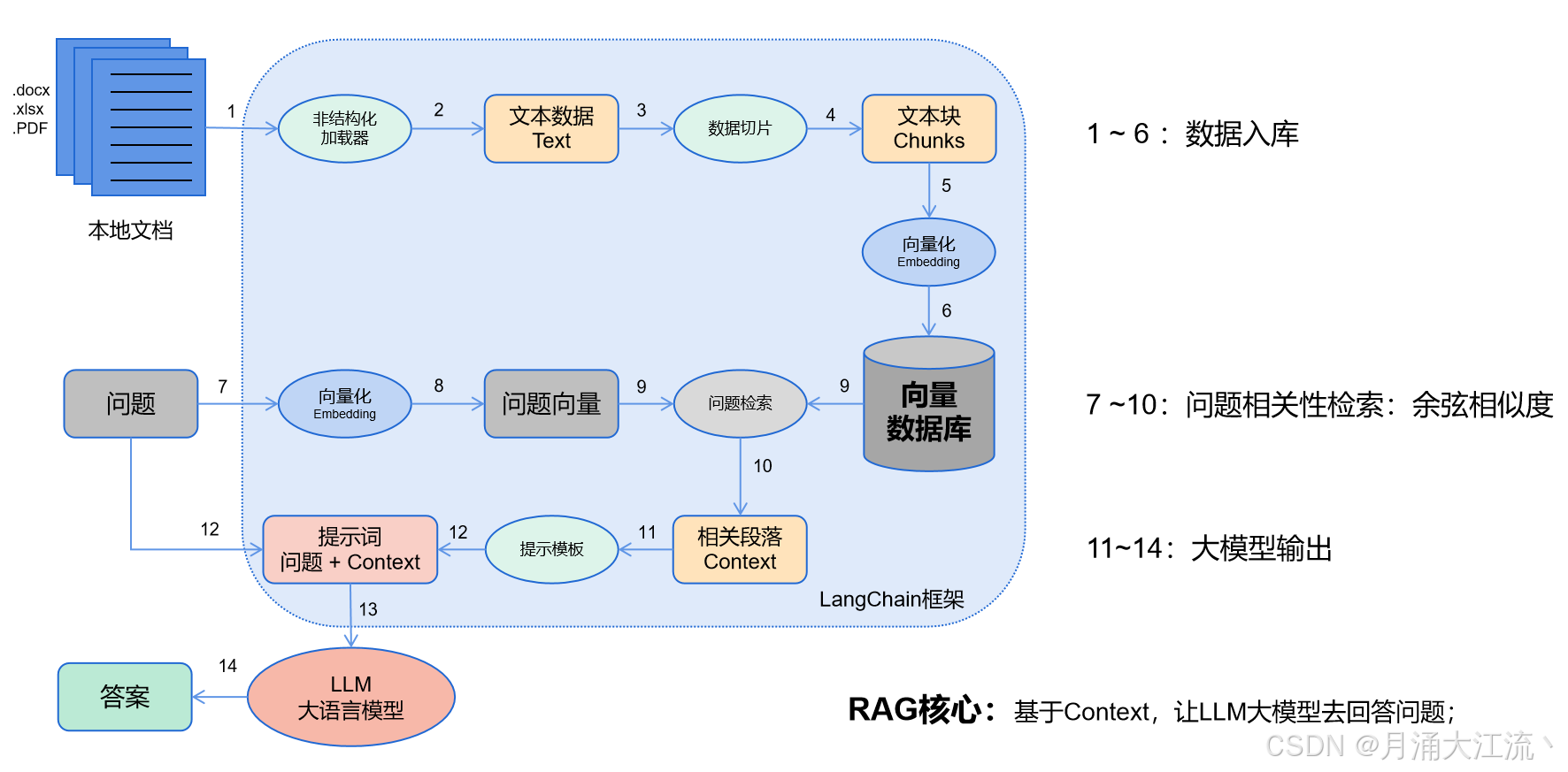
一、 RAG流程图
- 数据入库:读取本地数据并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中(下图1——6步);
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context(下图7——10步);
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动(下图11——15步)
RAG的本质:是为了弥补大模型在特定领域下知识的不足,整个过程相对稳定,大模型可发挥的空间较少;
- RAG流程中前两步是核心:数据入库 + 相关性检索。
- 主要难点在:知识管理(非结构化加载器做文件解析 + 数据如何切片)、知识检索、知识重排序

二、 RAG代码实现
from sentence_transformers import SentenceTransformer, util
from transformers import BartForConditionalGeneration, BartTokenizer
import torch# # [1]:初始化检索模型 (Sentence-BERT)
retrieval_model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')# # [2]:文档向量化
documents = ["Machine learning is a field of artificial intelligence that uses statistical techniques.","Deep learning is a subset of machine learning that uses neural networks.","Natural language processing is a field of AI focused on the interaction between computers and humans.","RAG stands for Retrieval-Augmented Generation, a framework that combines document retrieval and generation.",
]
document_embeddings = retrieval_model.encode(documents, convert_to_tensor=True)# # [3]:初始化生成模型 (BART)
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
generator_model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')def retrieve_documents(query, top_k=2):"""查询数据,召回相关的文档:param query:问题:param top_k:最相关的K个答案进行召回:return:"""# # 计算查询 query 与所有文档的相似性分数(使用余弦相似度),并返回最相关的top_k个结果query_embedding = retrieval_model.encode(query, convert_to_tensor=True)cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]top_results = torch.topk(cos_scores, k=top_k)relevant_docs = [documents[idx] for idx in top_results.indices]return relevant_docsdef generate_answer(query, relevant_docs):"""基于召回文档生成最后答案:param query: 问题:param relevant_docs: 召回的最相关的 top_k 个文档:return:"""input_text = query + " " + " ".join(relevant_docs)inputs = tokenizer(input_text, return_tensors="pt", max_length=512, truncation=True)# # query + relevant_docs作为新输入,用于生成新结果summary_ids = generator_model.generate(inputs['input_ids'], max_length=150, num_beams=4, early_stopping=True)answer = tokenizer.decode(summary_ids[0], skip_special_tokens=True)return answerquery = "What is RAG in AI?"
# # 召回与查询相关的文档
relevant_docs = retrieve_documents(query)
print("Retrieved Documents:", relevant_docs)# # 基于召回的文档生成答案
answer = generate_answer(query, relevant_docs)
print("Generated Answer:", answer)
三、 RAG改进方向
主要为提升检索的准确率,提高回复的质量。
3.1、检索前
- 增强数据颗粒度:校准知识库数据,在确保准确性的前提下,使内容变得简洁、准确、无冗余;
- 调整数据切片长度:找到合适的切片长度,使每个文本块chunks保存的知识互相独立,没有信息交叉;
- 添加元数据:比如使用【日期、价格】等元数据加强敏感数据的检索,增强相关性;
- 假设性问题:为每个chunks创建假设性问题来解决文档间的不一致问题;
- 动态更新知识库:涉及时效性问题时,比如金融、新闻等领域,可以通过API动态更新数据库,增强知识库的时效性;
- 模型微调:利用特定领域的语料来微调Embedding模型 + 基座模型,将特定知识嵌入到模型中
3.2、检索中
- 知识库分类:将相近知识存入同一个知识库,检索过程中先对问题进行分类,再在对应知识库中查找相关数据;
- 多轮检索:针对复杂问题,通过多轮检索逐步聚焦目标文档。第一次检索后,可以将初步结果再次作为输入,进行二次筛选,找到更加精确的信息;
- 动态文档扩展:对检索到的文档进行扩展,如使用知识图谱、外部API或其他数据库进行补充,从而丰富大模型的上下文信息;
- 多模态输入:结合文本、图片、视频等多模态信息,可以更全面地为问题提供背景支持,提升回答的精度;
- 多模型集成:引入多个模型的回答,然后通过加权、打分等方法选出最佳答案。或者让不同模型分别进行回答,后续结合打分机制选取最优解;
- 改进检索算法:设计更为复杂的模块对召回的结果进行精细化排序,提高召回质量,如基于Dense Passage Retrieval (DPR) 或者使用语义搜索技术(如FAISS)来代替传统的BM25检索方法;
3.3、检索后
- 答案验证与过滤:结合规则库或知识库,对生成的答案进行验证。例如可以通过正则表达式、领域规则等,检查生成内容是否符合逻辑或事实,过滤掉明显错误的回答;
- 不确定检测:通过设定阈值来识别并提示用户答案的不确定性,或者引导进一步的问题澄清;
- 提示词精炼:压缩无关上下文,突出关键段落,减少总体长度;
- 选用更好的模型:提高知识处理能力,增加输出长度;
四. 改进RAG:DPR检索实现
不同的检索模型有不同的召回性能。选择更好的检索模型可以显著提高召回准确率。
Dense Retrieval(稠密检索):相比于传统的基于词频的检索模型(如TF-IDF或BM25),稠密向量检索模型可以捕捉语义信息,尤其在长查询或含有复杂句子时表现更好。常见的稠密检索模型包括:
- DPR(Dense Passage Retrieval):基于双塔模型(query encoder和document encoder)将查询和文档嵌入到同一个向量空间,计算其余弦相似度来进行召回。
- Sentence-BERT:基于BERT的句子级向量模型,能够在语义层面上更好地理解查询和文档。
Hybrid Retrieval(混合检索):结合稠密检索和稀疏检索。可以同时使用BM25和DPR的结果,将二者结合进行召回。
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer
import torch# # [1]:初始化 DPR 模型和 Tokenizer
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")# # [2]:文档向量化
documents = ["Machine learning is a field of artificial intelligence that uses statistical techniques.","Deep learning is a subset of machine learning that uses neural networks.","Natural language processing is a field of AI focused on the interaction between computers and humans.","RAG stands for Retrieval-Augmented Generation, a framework that combines document retrieval and generation.",
]# # 将文档库编码为稠密向量
context_embeddings = []
for doc in documents:inputs = context_tokenizer(doc, return_tensors="pt", truncation=True, padding=True)with torch.no_grad():embedding = context_encoder(**inputs).pooler_outputcontext_embeddings.append(embedding)
context_embeddings = torch.cat(context_embeddings, dim=0)# # [3]:编码查询为稠密向量
query = "What is RAG in AI?"
query_inputs = question_tokenizer(query, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():query_embedding = question_encoder(**query_inputs).pooler_output# # [4]:计算查询与文档的相似度
scores = torch.matmul(query_embedding, context_embeddings.T)
top_k = torch.topk(scores, k=2)# # [5]:打印最相关的文档
relevant_docs = [documents[i] for i in top_k.indices[0]]
print("Top relevant documents:", relevant_docs)
五、非文本内容处理(图片、表格、流程图)
5.1、图片
- 可以使用视觉模型(如 CLIP、ViT 等)将图像编码为向量,类似于文本的向量化。在检索阶段,通过将文本查询与图像向量进行相似度计算,实现图像的检索;
- OCR 处理图片中的文本:对于包含文本的图片(如流程图、图表等),可以使用 OCR(Optical Character Recognition,光学字符识别)技术提取图片中的文字,将其作为文本信息参与检索和生成流程;
5.2、表格
- 表格转为结构化数据:表格转化为JSON、CSV 等,然后通过匹配查询与表格中的字段,实现基于表格数据的检索和回答;
- 表格语义化:可以使用专门的表格理解模型(如 TAPAS)将表格转化为语义信息,使模型能够根据查询直接在表格中查找相关信息;
5.3、流程图
- 结构化理解:对于流程图,可以使用图像处理技术或者专门的流程图解析工具(如 Graphviz)将流程图结构化表示,将其转化为流程节点、关系的语义表示。例如,使用图卷积网络(GCN) 或其他图算法对流程图进行语义理解;
- 语义转换:将流程图中的结构转化为自然语言描述,供 RAG 模型使用,通过图像处理技术将流程图的各个元素(如节点和连线)提取出来,并转换为带有语义的描述。比如“从 A 节点经过 B 节点,最后到达 C 节点”可以转化为“流程从 A 开始,经过 B 后到达 C”
5.4、多模态融合
- 多模态模型:如果希望同时处理文本、图像、表格等多种模态,可以使用多模态模型,如 CLIP(处理图像和文本)或 VisualBERT(结合图像和文本进行推理)。
- 多模态融合检索与生成:通过将不同模态的输入(图像、表格、文本等)编码为统一的向量空间,能够实现多模态信息的融合。RAG 的查询阶段可以同时检索文本、表格和图像,生成阶段则利用不同模态的信息来生成准确的答案