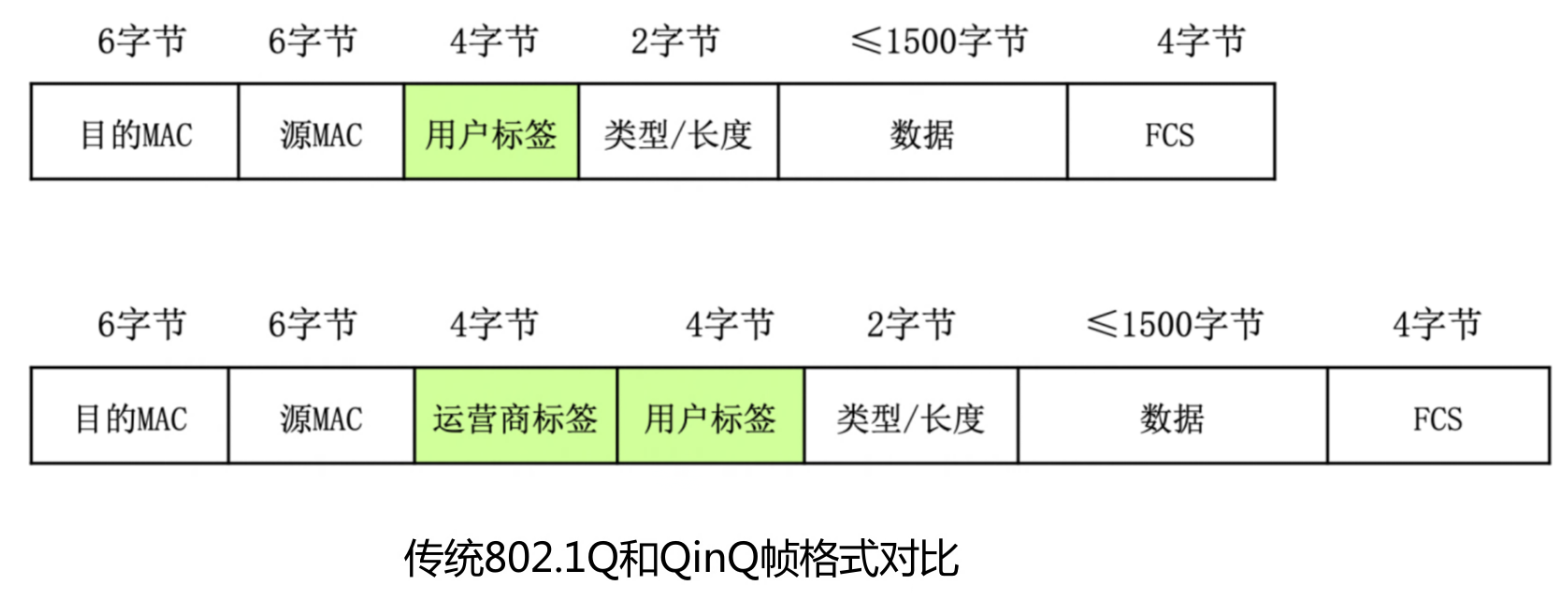
文章目录
- 一、实验目的
- 二、实验要求
- 三、实验原理
- (一)Java Classpath
- (二)Eclipse Hadoop插件
- 四、实验环境
- 五、实验内容和步骤
- (一)配置master服务器classpath
- (二)使用master服务器编写HDFS读写程序
- (三)安装与配置Eclipse Hadoop插件
- (四)使用Eclipse开发HDFS读写程序
- 六、实验结果
- 七、实验心得
一、实验目的
- 会在Linux环境下编写读写HDFS文件的代码;
- 会使用jar命令打包代码;
- 会在master服务器上运行HDFS读写程序;
- 会在Windows上安装Eclipse Hadoop插件;
- 会在Eclipse环境编写读写HDFS文件的代码;
- 会使用Eclipse打包代码;
- 会使用Xftp工具将实验电脑上的文件上传至master服务器。
二、实验要求
实验结束时,每位学生均已搭建HDFS开发环境;编写了HDFS写、读代码;在master机上执行了该写、读程序。通过实验了解HDFS读写文件的调用流程,理解HDFS读写文件的原理。
三、实验原理
(一)Java Classpath
Classpath设置的目的,在于告诉Java执行环境,在哪些目录下可以找到您所要执行的Java程序所需要的类或者包。
Java执行环境本身就是一个平台,执行于这个平台上的程序是已编译完成的Java程序(后面会介绍到Java程序编译完成之后,会以.class文件存在)。如果将Java执行环境比喻为操作系统,如果设置Path变量是为了让操作系统找到指定的工具程序(以Windows来说就是找到.exe文件),则设置Classpath的目的就是让Java执行环境找到指定的Java程序(也就是.class文件)。
有几个方法可以设置Classpath,较简单的方法是在系统变量中新增Classpath环境变量。以Windows 7操作系统为例,右键点击计算机→属性→高级系统设置→环境变量,在弹出菜单的“系统变量”下单击“新建”按钮,在“变量名”文本框中输入Classpath,在“变量值”文本框中输入Java类文件的位置。例如可以输入.; D:\Java\jdk1.7.0_79\lib\tools.jar; D:\Java\jdk1.7.0_79\lib\rt.jar,每一路径中间必须以英文;作为分隔。

事实上JDK 7.0默认就会到当前工作目录(上面的.设置),以及JDK的lib目(这里假设是D:\Java\jdk1.7.0_796\lib)中寻找Java程序。所以如果Java程序是在这两个目录中,则不必设置Classpath变量也可以找得到,将来如果Java程序不是放置在这两个目录时,则可以按上述设置Classpath。
如果所使用的JDK工具程序具有Classpath命令选项,则可以在执行工具程序时一并指定Classpath。例如:javac -classpath classpath1;classpath2...其中classpath1、classpath 2是实际要指定的路径。也可以在命令符模式下执行以下的命令,直接设置环境变量,包括Classpath变量(这个设置在下次重新打开命令符模式时就不再有效):set CLASSPATH=%CLASSPATH%;classpath1;classpath2...总而言之,设置Classpath的目的,在于告诉Java执行环境,在哪些目录下可以找到您所要执行的Java程序(.class文件)。
(二)Eclipse Hadoop插件
Eclipse是一个跨平台的自由集成开发环境(IDE)。通过安装不同的插件,Eclipse可以支持不同的计算机语言,比如C++和Python等开发工具,亦可以通过hadoop插件来扩展开发Hadoop相关程序。
实际工作中,Eclipse Hadoop插件需要根据hadoop集群的版本号进行下载并编译,过程较为繁琐。为了节约时间,将更多的精力用于实现读写HDFS文件,在大数据实验一体机的相关下载页面中已经提供了2.7.1版本的hadoop插件和相关的hadoop包下载,实验人员可以直接下载这些插件,快速在Eclipse中进行安装,开发自己的hadoop程序。
四、实验环境
- 云创大数据实验平台:

- Java 版本:jdk1.7.0_79
- Hadoop 版本:hadoop-2.7.1
- Eclipse 版本:eclipse-jee-luna-SR2-win32-x86_64
五、实验内容和步骤
该实验的前提是部署HDFS,具体步骤可参考:【大数据技术基础 | 实验三】HDFS实验:部署HDFS
这里采用一键搭建的方式,将HDFS部署完成并启动Hadoop集群(包括hdfs和yarn),使用jps命令查看进程:



(一)配置master服务器classpath
使用SSH工具登录master服务器,执行命令:
vim /etc/profile
编辑该文件,将末尾加入如下几行:
JAVA_HOME=/usr/local/jdk1.7.0_79/
export HADOOP_HOME=/usr/cstor/hadoop
export JRE_HOME=/usr/local/jdk1.7.0_79//jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"

添加成功之后保存文件,然后再执行如下命令,让刚才设置的环境变量生效:
source /etc/profile
(二)使用master服务器编写HDFS读写程序
1. 在master服务器编写HDFS写程序
在master服务器上执行命令vim WriteFile.java,编写HDFS写文件程序:
vim WriteFile.java
在文件内写入如下java程序代码然后保存退出。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WriteFile {public static void main(String[] args)throws Exception{Configuration conf=new Configuration();FileSystem hdfs = FileSystem.get(conf);Path dfs = new Path("/weather.txt");FSDataOutputStream outputStream = hdfs.create(dfs);outputStream.writeUTF("nj 20161009 23\n");outputStream.close();}
}


2. 编译并打包HDFS写程序
使用javac编译刚刚编写的java代码,并使用jar命令打包为hdpAction1.jar。
javac WriteFile.java
jar -cvf hdpAction1.jar WriteFile.class

3. 执行HDFS写程序
在master服务器上使用hadoop jar命令执行hdpAction1.jar:
hadoop jar ~/hdpAction1.jar WriteFile
查看是否已生成weather.txt文件,若已生成,则查看文件内容是否正确:
hadoop fs -ls /
hadoop fs -cat /weather.txt

4. 在master服务器编写HDFS读程序
在master服务器上执行命令vim ReadFile.java,编写HDFS读文件程序:
vim ReadFile.java
然后填入如下java程序:
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;public class ReadFile {public static void main(String[] args) throws IOException {Configuration conf = new Configuration();Path inFile = new Path("/weather.txt");FileSystem hdfs = FileSystem.get(conf);FSDataInputStream inputStream = hdfs.open(inFile);System.out.println("myfile: " + inputStream.readUTF());inputStream.close();}
}


5. 编译并打包HDFS读程序
使用javac编译刚刚编写的代码,并使用jar命令打包为hdpAction2.jar。
javac ReadFile.java
jar -cvf hdpAction2.jar ReadFile.class

6. 执行HDFS读程序
在master服务器上使用hadoop jar命令执行hdpAction2.jar,查看程序运行结果:
hadoop jar ~/hdpAction2.jar ReadFile

(三)安装与配置Eclipse Hadoop插件
关闭Eclipse软件,将hadoop-eclipse-plugin-2.7.1.jar文件拷贝至eclipse安装目录的plugins文件夹下。(该jar包可以到文末链接下载)

接下来,我们需要准备本地的Hadoop环境,用于加载hadoop目录中的jar包,只需解压hadoop- 2.7.1.tar.gz文件。

现在,我们需要验证是否可以用Eclipse新建Hadoop(HDFS)项目。打开Eclipse软件,依次点击File->New->Other,查看是否已经有 Map/Reduce Project 的选项。


这里如果没有出现这个选项的话,需要去Eclipse安装路径下的configuration文件中把org.eclipse.update删除,这是因为在org.eclipse.update文件夹下记录了插件的历史更新情况,它只记忆了以前的插件更新情况,而你新安装的插件它并不记录,之后再重启Eclipse就会出现这个选项了。
第一次新建Map/Reduce项目时,需要指定hadoop解压后的位置。如图所示。

(四)使用Eclipse开发HDFS读写程序
1. 使用Eclipse编写并打包HDFS写文件程序
打开Eclipse,依次点击File->New->Map/Reduce Project或File->New->Other->Map/Reduce Project,新建项目名为WriteHDFS的Map/Reduce项目。
新建WriteFile类并编写如下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;public class WriteFile {public static void main(String[] args)throws Exception{Configuration conf=new Configuration();FileSystem hdfs = FileSystem.get(conf);Path dfs = new Path("/weather.txt");FSDataOutputStream outputStream = hdfs.create(dfs);outputStream.writeUTF("nj 20161009 23\n");outputStream.close();}
}
注意:因为本实验平台大数据集群是使用的jdk1.7版本,必须要使用相同版本才行,如果你是jdk1.8版本,也不用重新配置1.7版本,只需要在Eclipse切换执行环境就行,具体操作如下:

接着,在Eclipse左侧的导航栏选中该项目的WriteFile.java文件,点击Export->Java->JAR File,导出为hdpAction1.jar。


然后填写导出文件的路径和文件名,自定义:

然后点击下一步,再点击下一步,然后配置程序主类,这里必须要选择主类,不然后面上传到服务器就会一直报错。

最后点击完成就打包完成。
2. 上传HDFS写文件程序jar包并执行
使用WinSCP、XManager或其它SSH工具的sftp工具上传刚刚生成的hdpAction1.jar包至master服务器:

然后在master服务器上使用如下命令执行hdpAction1.jar:
hadoop jar ~/hdpAction1.jar WriteFile
查看是否已生成weather.txt文件,若已生成,则查看文件内容是否正确:
hadoop fs -ls /
hadoop fs -cat /weather.txt

3. 使用Eclipse编写并打包HDFS读文件程序
打开Eclipse,依次点击File->New->Map/Reduce Project或File->New->Other->Map/Reduce Project,新建项目名为ReadHDFS的Map/Reduce项目。这里建项目的方法和前面的一样,不再详细描述了。
新建ReadFile类并编写如下代码:
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;public class ReadFile {public static void main(String[] args) throws IOException {Configuration conf = new Configuration();Path inFile = new Path("/weather.txt");FileSystem hdfs = FileSystem.get(conf);FSDataInputStream inputStream = hdfs.open(inFile);System.out.println("myfile: " + inputStream.readUTF());inputStream.close();}
}
在Eclipse左侧的导航栏选中该项目,点击Export->Java->JAR File,导出为hdpAction2.jar。和前面一样进行导包操作,注意要选择主类!
4. 上传HDFS读文件程序jar包并执行
使用WinSCP、XManager或其它SSH工具的sftp工具上传刚刚生成的hdpAction2.jar包至master服务器,并在master服务器上使用hadoop jar命令执行hdpAction2.jar,查看程序运行结果:

hadoop jar ~/hdpAction2.jar ReadFile

六、实验结果
1. HDFS写程序运行结果:
2. HDFS读程序运行结果:
七、实验心得
在本次HDFS实验中,我成功地完成了HDFS文件的读写操作,并对Hadoop分布式文件系统的工作原理有了更深入的理解。实验的主要步骤包括在Linux环境中编写Java代码,用于向HDFS中写入和读取文件。通过使用Eclipse IDE进行代码开发,并将代码打包成JAR文件后,我在Hadoop集群的master服务器上运行了这些程序。
实验的关键环节之一是掌握Java Classpath的设置方法,并理解Eclipse Hadoop插件的安装与配置。通过正确配置master服务器的环境变量,我顺利实现了HDFS读写程序的运行,并成功验证了实验结果。在实验过程中,还学会了使用Xftp等工具将本地开发的程序上传至master服务器,并执行相应的命令来测试HDFS文件的操作。
总体而言,实验帮助我加深了对HDFS分布式文件系统的理解,特别是在大数据环境中文件的存储和读取操作,这为后续的Hadoop开发奠定了良好的基础。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/d872381814a0
提取码:qjda






![SpringCloudAlibaba[Nacos]注册配置中心注册与发现服务](https://i-blog.csdnimg.cn/direct/82524745dc35478988b2860eefee6d77.png)