知乎:lym
链接:https://zhuanlan.zhihu.com/p/890327005

如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包括时间成本。
基于prompt确实不行(情况包括格式输出不稳定、格式输出基本不对、任务不完全会、任务完全不会等情况,难度逐渐加大),选择上SFT微调。
业务场景基本用不到强化学习,强化解决的是最后一公里的问题,可以理解为有两种非常接近的输出(这两种输出都非常接近目标输出,此时已经解决了90%的问题),强化学习会对相同的输入,打压其中一种不希望的输出,同时增强另一种更接近目标的希望的输出(从DPO loss就可以看出)。强化是用来应对细微输出差异的,并且业务场景优先用DPO,DPO只需要pair对数据,更好构造。PPO的reward model几乎没有开源的,需要的数据更多,超参也更多,除非是逻辑或代码场景,在文本场景中,DPO效果是足够的。
业务数据质量最重要,数据量也不能少,越难的任务数据量越多
数据内容:要尽量和期望输出一致,这个一致既包括内容,也包括格式。不要期望垃圾数据能训练出好的VLM模型,不要寄希望于dalle3那种recaptioning,依靠泛化能力变换格式的玩法太高级了,我还把我不住。可以用 手工标注数据+GPT改写(甚至可以是Vision版本) 生成质量尽可能高的业务数据。改写用的GPT原本没有解决对应任务的能力也不要怕,在改写的prompt模板让它参考人工标注就行。
数据量:如果模型会该类任务,但仅是输出格式不稳定(比如json少个括号,文本输出少个\n什么的),几十到上百条业务数据就够了,不用考虑通用数据;一般普通业务需要千条业务数据(类似数据在VLM模型预训练的训练集出现过,但模型对于该任务处于会与不会区间),需要少量通用数据(10:1,1份通用)。如果特别难的task,VLM模型根本没见过(比如文生图生成数据,输出的文本也和输入图之间的关系需要重学),那需要1-2w条业务数据,通用数据5:1。
训练轮次:我训练的task就特别难,4B左右的模型甚至训练10个epoch测试集的loss还在下降。但是一般7B模型训5个epoch,70B模型训练2个epoch,就会开始过拟合了。下面是比较正常的收敛曲线。


当然还有些肯定不正确的曲线:


数据难度:可以用PPL衡量,也可以看训练集上测试的效果。
多个类型数据:先各自训练看效果,确保各自没有问题,再去混合。
训练流程
-
收集清洗改写增强广业务数据,同一个问题可以除了文本对话,还可以改写成选择判断,有帮助,而且这些形式更容易做评测,方便确认效果。
-
磨刀不误砍柴工:找一个小的VLM模型(2B~7B),按照默认微调参数对纯业务数据集上进行训练,设置较高的lr(1e-5)和较长的epoch(10轮)。训练好的模型在训练集上先测试(对,用什么训练用什么测!)。在训练集上进行测试是非常重要的,它可以一定程度排除数据集质量的问题,也不用担心过拟合的问题,同时也能确保框架底层没什么问题。别管数据质量多垃圾,别管在测试集泛化性有多差,在训练集上都应该有较好的学习效果。如果你的业务数据有多种形式,也可以在这个阶段进行配比的消融。
-
确保在训练集上没问题,再结合validation集上的曲线,应该可以大致确认:训练轮次(epoch)、业务数据配比、学习率、batch_size、文本长度、moe专家数量、并行配置(tp pp dp)等绝大部分超参。
PS:在VLM训练中,无论是预训练、对齐还是精调,用的都是SFT loss,没有Pretrain loss。学界可能比较喜欢用lora,但工业届全量调的更多,这俩区别不是很大,lora dim设置成128/256,scaling设置成64(dim的05倍),也能学很多东西。
如果只是输出格式不满意、不稳定,那么调LLM就够。如果全新的知识,那么vit和LLM以及二者间的中间层都放开比较好。参数量的大头在LLM中,但如果图片业务数据和预训练数据差异较大,vit放开也很重要。(上vit冻住,下vit放开,vit解冻后明显收敛更稳定)。我的任务比较难,肯定就是全放开训练了。

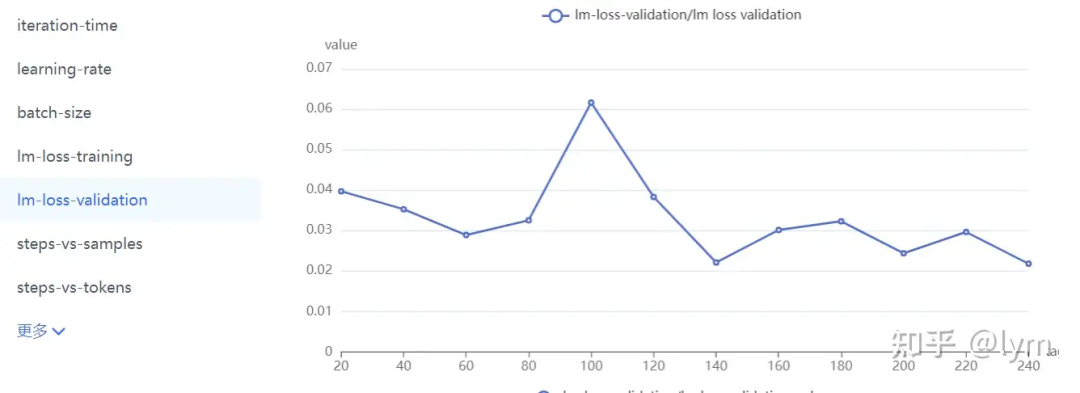
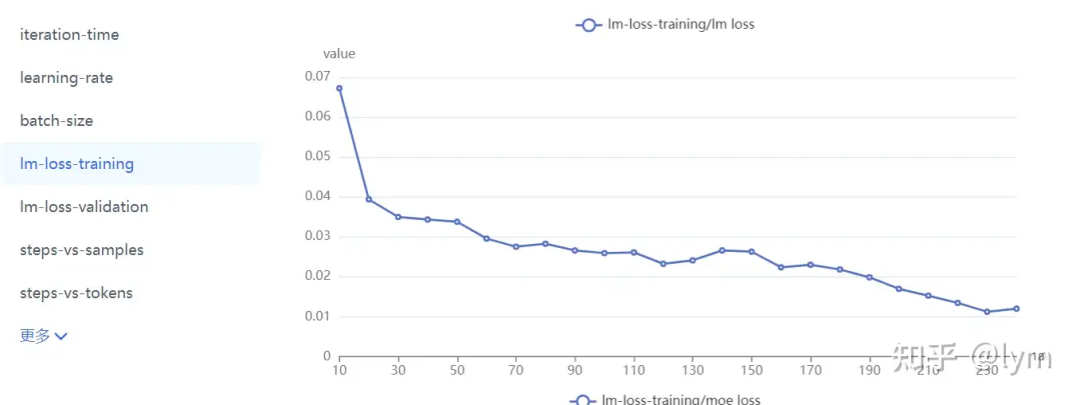
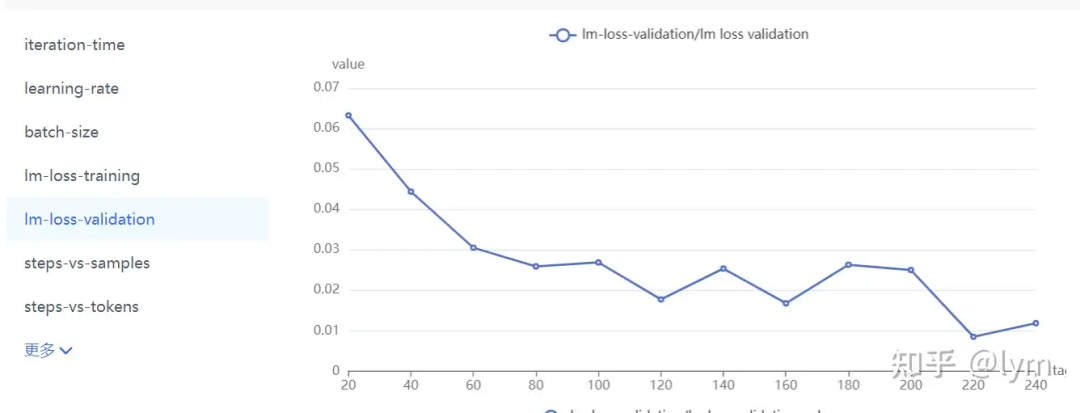
往里面加入通用数据,来维护原有通用能力(在业务垂域没搞明白前,一般先别考虑通用数据,否则变量太多,把握不住)。配比从10:1开始,不行可以试试5:1。通用数据包括两种,一种是caption,一种是instruct数据。caption数据的question基本都是”详细描述图中有什么?“,它在VLM预训练中是用来做一阶段的。Instruct数据的question就比较多样了,比如”图中叉子右边的茶杯是什么颜色的?“它一般对应预训练的二阶段微调。VLM这两个阶段虽然一阶段叫训练,二阶段叫对齐,但是loss形式是一样的,超参可能也只有学习率的差异,越往后学习率越小。全用instruct数据问题也不大,但instruct数据可能信息量可能不如caption对图片描述那么丰富,也更难收集一些。
caption的数据我翻译了些sharegpt4o的,整理好了:
https://huggingface.co/datasets/LYM2024/share_gpt4o_zh?row=0
instruct数据用的ALLAVA-4V的,量太大了翻译的还没整理好。
https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
这俩我是1:1用的,没做严格消融。英文数据去llamafactory找就行,中文大部分得自己动手翻译。通用 数据也可以大量用英文,融合一点自己翻译的中文,效果也不会太差的。
然后我发现个特别有意思的现象,我的业务数据是diffusion生成的图片,上面这些数据是自然图片,业务数据的通用能力几乎没有被维护。解决方案:
-
用现有VLM对业务数据作captioning,因为caption的question与图无关,直接取sharegpt40的就行。直接生成大量业务图片的通用数据。
-
用LCM的SSD或SDXL模型做Img2Img,把正prompt置空,guidance_scale置0(最好negative输出的embedding取torch.zeros),strength强度设置0.025。用无引导生成生成有diffusion特征的图片。
-
训练可以分多个阶段,前面用质量差一点的大量数据,后面用质量高的小批量数据,提升最终效果。两阶段question的词汇可以作下隔离,即这两批数据的question最好有点小差异,后续推理测试只用高质量数据的question。实测高质量数据的需求大会大大降低。
-
我个人觉得,精调这种任务,如果数据量大,在7B小模型和72B大模型上,在业务(垂域)上效果差异并不大,因为我们一般更关心业务和垂域的性能,而非要成为全面的通才。
-
数据质量高可以训练久一些,数据质量差训练短一些,可以保留更好的泛化性。我们的数据比较短,训练10epoch的话,输出就非常短,往往不带主语。训练6epoch就会带一些,所以不是validation loss下降就是好事,它可能同时对应着通用loss的上升,稍微遇到些长尾问题,性能就会崩溃式下降。训练太短也不行,容易学不会,至少要保证训练5epoch,看看整体的结果。
知乎:lym
链接:https://zhuanlan.zhihu.com/p/890327005
如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包括时间成本。
基于prompt确实不行(情况包括格式输出不稳定、格式输出基本不对、任务不完全会、任务完全不会等情况,难度逐渐加大),选择上SFT微调。
业务场景基本用不到强化学习,强化解决的是最后一公里的问题,可以理解为有两种非常接近的输出(这两种输出都非常接近目标输出,此时已经解决了90%的问题),强化学习会对相同的输入,打压其中一种不希望的输出,同时增强另一种更接近目标的希望的输出(从DPO loss就可以看出)。强化是用来应对细微输出差异的,并且业务场景优先用DPO,DPO只需要pair对数据,更好构造。PPO的reward model几乎没有开源的,需要的数据更多,超参也更多,除非是逻辑或代码场景,在文本场景中,DPO效果是足够的。
业务数据质量最重要,数据量也不能少,越难的任务数据量越多
数据内容:要尽量和期望输出一致,这个一致既包括内容,也包括格式。不要期望垃圾数据能训练出好的VLM模型,不要寄希望于dalle3那种recaptioning,依靠泛化能力变换格式的玩法太高级了,我还把我不住。可以用 手工标注数据+GPT改写(甚至可以是Vision版本) 生成质量尽可能高的业务数据。改写用的GPT原本没有解决对应任务的能力也不要怕,在改写的prompt模板让它参考人工标注就行。
数据量:如果模型会该类任务,但仅是输出格式不稳定(比如json少个括号,文本输出少个\n什么的),几十到上百条业务数据就够了,不用考虑通用数据;一般普通业务需要千条业务数据(类似数据在VLM模型预训练的训练集出现过,但模型对于该任务处于会与不会区间),需要少量通用数据(10:1,1份通用)。如果特别难的task,VLM模型根本没见过(比如文生图生成数据,输出的文本也和输入图之间的关系需要重学),那需要1-2w条业务数据,通用数据5:1。
训练轮次:我训练的task就特别难,4B左右的模型甚至训练10个epoch测试集的loss还在下降。但是一般7B模型训5个epoch,70B模型训练2个epoch,就会开始过拟合了。下面是比较正常的收敛曲线。
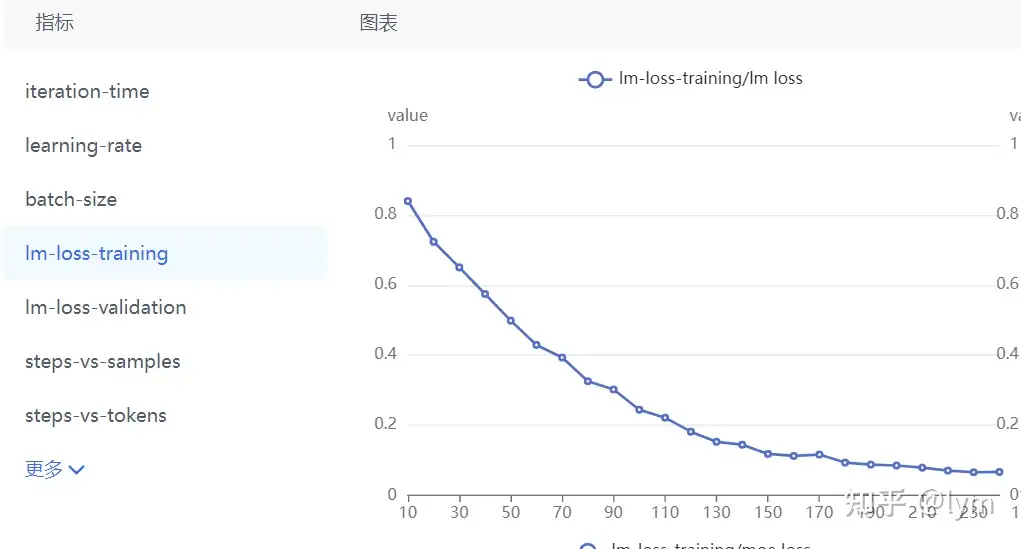
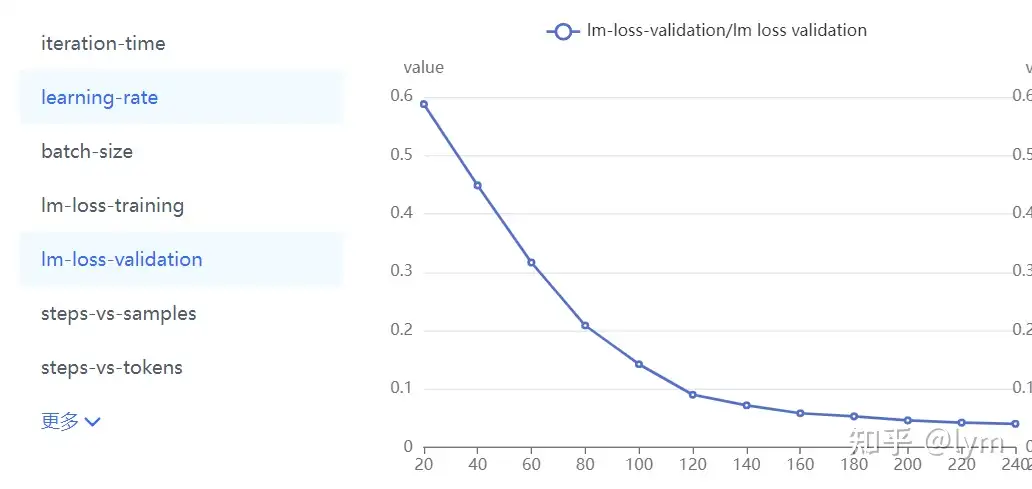
当然还有些肯定不正确的曲线:
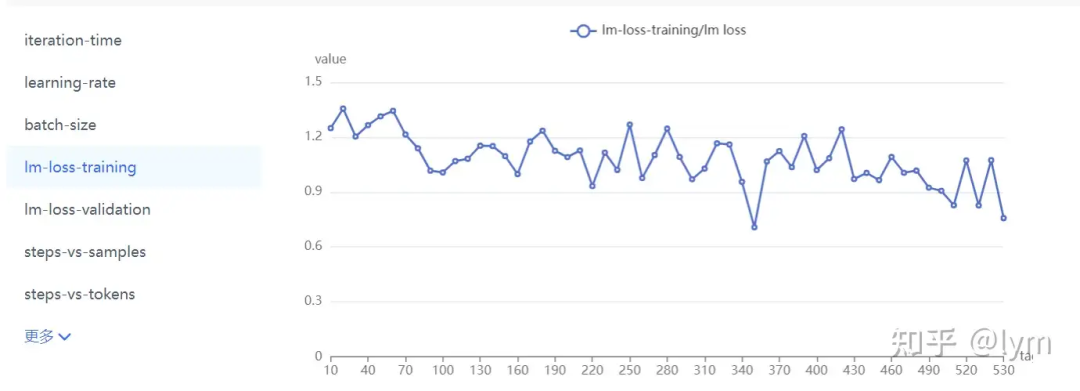
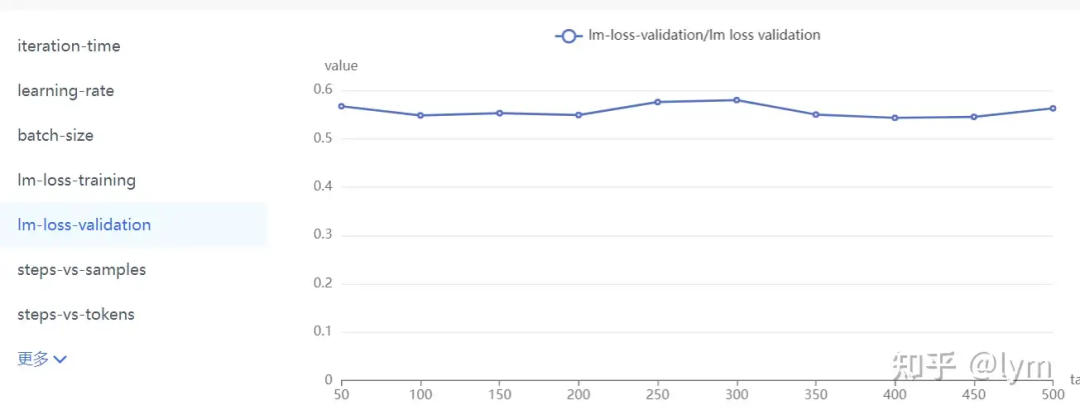
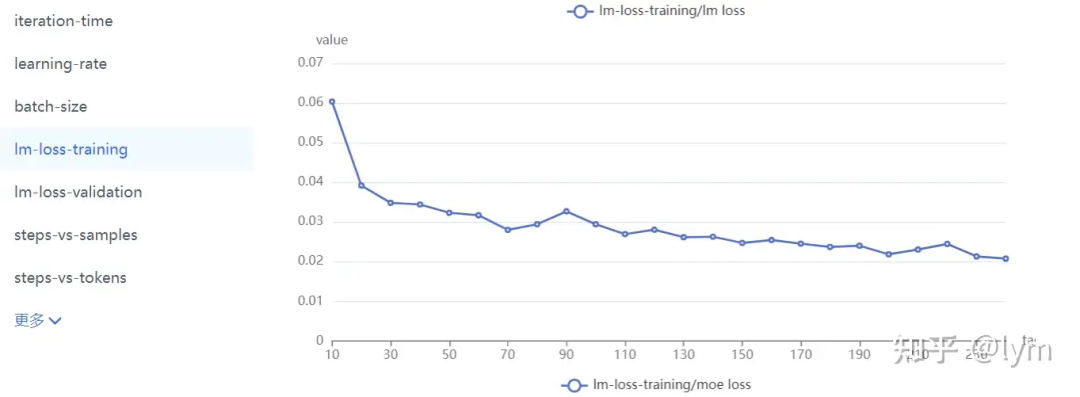
数据难度:可以用PPL衡量,也可以看训练集上测试的效果。
多个类型数据:先各自训练看效果,确保各自没有问题,再去混合。
训练流程
-
收集清洗改写增强广业务数据,同一个问题可以除了文本对话,还可以改写成选择判断,有帮助,而且这些形式更容易做评测,方便确认效果。
-
磨刀不误砍柴工:找一个小的VLM模型(2B~7B),按照默认微调参数对纯业务数据集上进行训练,设置较高的lr(1e-5)和较长的epoch(10轮)。训练好的模型在训练集上先测试(对,用什么训练用什么测!)。在训练集上进行测试是非常重要的,它可以一定程度排除数据集质量的问题,也不用担心过拟合的问题,同时也能确保框架底层没什么问题。别管数据质量多垃圾,别管在测试集泛化性有多差,在训练集上都应该有较好的学习效果。如果你的业务数据有多种形式,也可以在这个阶段进行配比的消融。
-
确保在训练集上没问题,再结合validation集上的曲线,应该可以大致确认:训练轮次(epoch)、业务数据配比、学习率、batch_size、文本长度、moe专家数量、并行配置(tp pp dp)等绝大部分超参。
PS:在VLM训练中,无论是预训练、对齐还是精调,用的都是SFT loss,没有Pretrain loss。学界可能比较喜欢用lora,但工业届全量调的更多,这俩区别不是很大,lora dim设置成128/256,scaling设置成64(dim的05倍),也能学很多东西。
如果只是输出格式不满意、不稳定,那么调LLM就够。如果全新的知识,那么vit和LLM以及二者间的中间层都放开比较好。参数量的大头在LLM中,但如果图片业务数据和预训练数据差异较大,vit放开也很重要。(上vit冻住,下vit放开,vit解冻后明显收敛更稳定)。我的任务比较难,肯定就是全放开训练了。
往里面加入通用数据,来维护原有通用能力(在业务垂域没搞明白前,一般先别考虑通用数据,否则变量太多,把握不住)。配比从10:1开始,不行可以试试5:1。通用数据包括两种,一种是caption,一种是instruct数据。caption数据的question基本都是”详细描述图中有什么?“,它在VLM预训练中是用来做一阶段的。Instruct数据的question就比较多样了,比如”图中叉子右边的茶杯是什么颜色的?“它一般对应预训练的二阶段微调。VLM这两个阶段虽然一阶段叫训练,二阶段叫对齐,但是loss形式是一样的,超参可能也只有学习率的差异,越往后学习率越小。全用instruct数据问题也不大,但instruct数据可能信息量可能不如caption对图片描述那么丰富,也更难收集一些。
caption的数据我翻译了些sharegpt4o的,整理好了:
https://huggingface.co/datasets/LYM2024/share_gpt4o_zh?row=0
instruct数据用的ALLAVA-4V的,量太大了翻译的还没整理好。
https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
这俩我是1:1用的,没做严格消融。英文数据去llamafactory找就行,中文大部分得自己动手翻译。通用 数据也可以大量用英文,融合一点自己翻译的中文,效果也不会太差的。
然后我发现个特别有意思的现象,我的业务数据是diffusion生成的图片,上面这些数据是自然图片,业务数据的通用能力几乎没有被维护。解决方案:
-
用现有VLM对业务数据作captioning,因为caption的question与图无关,直接取sharegpt40的就行。直接生成大量业务图片的通用数据。
-
用LCM的SSD或SDXL模型做Img2Img,把正prompt置空,guidance_scale置0(最好negative输出的embedding取torch.zeros),strength强度设置0.025。用无引导生成生成有diffusion特征的图片。
-
训练可以分多个阶段,前面用质量差一点的大量数据,后面用质量高的小批量数据,提升最终效果。两阶段question的词汇可以作下隔离,即这两批数据的question最好有点小差异,后续推理测试只用高质量数据的question。实测高质量数据的需求大会大大降低。
-
我个人觉得,精调这种任务,如果数据量大,在7B小模型和72B大模型上,在业务(垂域)上效果差异并不大,因为我们一般更关心业务和垂域的性能,而非要成为全面的通才。
-
数据质量高可以训练久一些,数据质量差训练短一些,可以保留更好的泛化性。我们的数据比较短,训练10epoch的话,输出就非常短,往往不带主语。训练6epoch就会带一些,所以不是validation loss下降就是好事,它可能同时对应着通用loss的上升,稍微遇到些长尾问题,性能就会崩溃式下降。训练太短也不行,容易学不会,至少要保证训练5epoch,看看整体的结果。








![[Xshell] Xshell的下载安装使用及连接linux过程 详解(附下载链接)](https://i-blog.csdnimg.cn/direct/3e27ab7b15ba474e9ea0f0edb19e93b8.png)








