Unity DOTS中的Archetype与Chunk
在Unity中,archetype(原型)用来表示一个world里具有相同component类型组合的entity。也就是说,相同component类型的entity在Unity内部会存储到一起,共享同一个archetype。
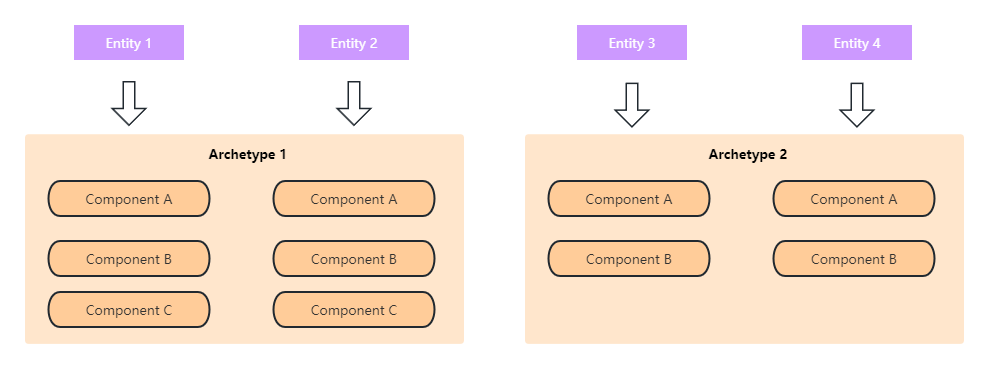
使用这样的设计,可以高效地通过component类型进行查询。例如,如果想查找所有具有component类型 A 和 B 的entity,那么只需找到表示这两个component的所有archetype,这比扫描所有entity更高效。
entity和componenet并不直接存储在archetype中,而是存储在称为chunk的连续内存块中。每个块由16KB组成,它们实际可以存储的entity数量取决于chunk所属archetype中component的数量和大小。 这样做可以更好匹配缓存行,同时也能更好支持并行操作。

对于一个chunk,它除了包含用于每种component类型的数组之外,还包含一个额外的数组来存储entity的ID。例如,在具有component类型 A 和 B 的archetype中,每个chunk都有三个数组:一个用于component A的数组,一个用于component B的数组,以及一个用于entity ID的数组。
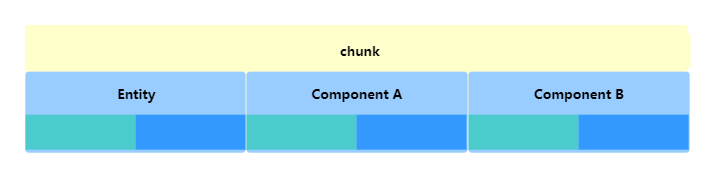
chunk中的数据是紧密连续的,chunk的每个entity都存储在每个数组连续的索引中。添加一个新的entity时,会将其存储在第一个可用索引中。而当从chunk中移除entity时,chunk的最后一个entity将被移动以填补空隙。添加entity时,如果对应archetype的所有chunk都已满,则Unity将创建一个全新的chunk。类似地,当从chunk中移除最后一个entity时,Unity会将该chunk进行销毁。
在编辑器中,Unity提供了Archetypes窗口,可以方便预览当前所有的archetype。我们先用代码创建4个entity,然后给它们分别添加两种component:
public partial struct FirstSystem : ISystem
{public void OnCreate(ref SystemState state) { Entity e1 = state.EntityManager.CreateEntity();Entity e2 = state.EntityManager.CreateEntity();Entity e3 = state.EntityManager.CreateEntity();Entity e4 = state.EntityManager.CreateEntity();state.EntityManager.AddComponentData(e1, new FirstComponent { Value = 1 });state.EntityManager.AddComponentData(e2, new FirstComponent { Value = 2 });state.EntityManager.AddComponentData(e3, new FirstComponent { Value = 3 });state.EntityManager.AddComponentData(e3, new SecondComponent { Value = 13 });state.EntityManager.AddComponentData(e4, new FirstComponent { Value = 4 });state.EntityManager.AddComponentData(e4, new SecondComponent { Value = 14 });}
}public struct FirstComponent : IComponentData
{public int Value;
}public struct SecondComponent : IComponentData
{public int Value;
}
那么,根据之前的分析,e1和e2应该属于同一个archetype,而e3和e4则属于另一个archetype。在编辑器中运行,观察Archetypes窗口,可以发现的确如此:
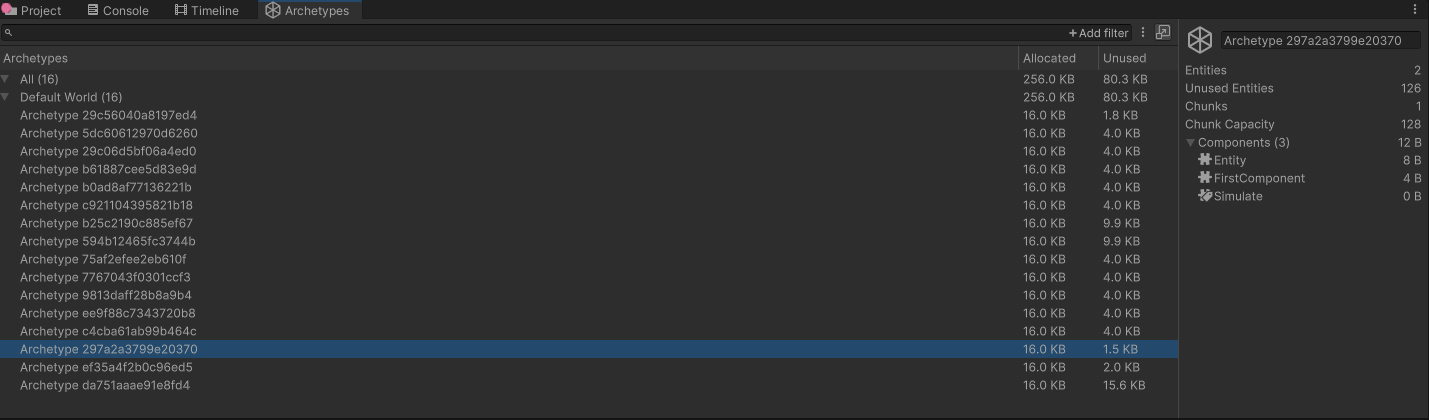
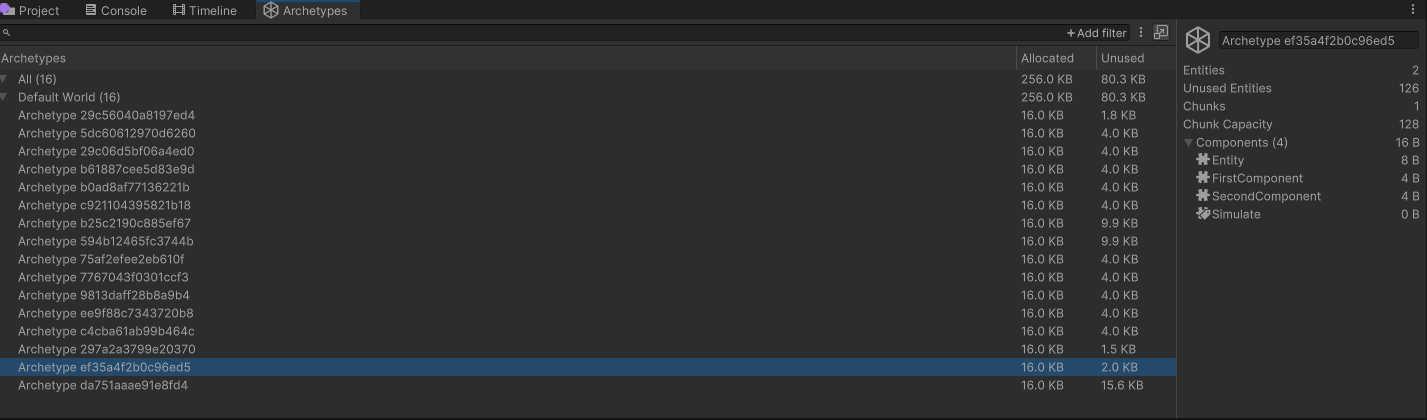
根据官网的解释,Archetypes窗口中可以观察到以下信息:
| Property | Description |
|---|---|
| Archetype name | The archetype name is its hash, which you can use to find the archetype again across future Unity sessions. |
| Entities | Number of entities within the selected archetype. |
| Unused Entities | The total number of entities that can fit into all available chunks for the selected Archetype, minus the number of active entities (represented by the entities stat). |
| Chunks | Number of chunks this archetype uses. |
| Chunk Capacity | The number of entities with this archetype that can fit into a chunk. This number is equal to the total number of Entities and Unused Entities. |
| Components | Displays the total number of components in the archetype and the total amount of memory assigned to them in KB. To see the list of components and their individual memory allocation, expand this section. |
| External Components | Lists the Chunk components and Shared components that affect this archetype. |
自此,我们对Unity的archetype和chunk有了基本的认识。接下来我们来看看源代码,深入一下细节部分。
在上面的例子中,我们使用EntityManager.CreateEntity这个函数来创建entity。函数内部会在创建entity之前,检查是否存在相应的archetype。由于此时尚不存在表示一个不含任何component类型的空entity的archetype,那么函数会先去创建archetype:
internal EntityArchetype CreateArchetype(ComponentType* types, int count, bool addSimulateComponentIfMissing)
{Assert.IsTrue(types != null || count == 0);EntityComponentStore->AssertCanCreateArchetype(types, count);ComponentTypeInArchetype* typesInArchetype = stackalloc ComponentTypeInArchetype[count + 2];var cachedComponentCount = FillSortedArchetypeArray(typesInArchetype, types, count, addSimulateComponentIfMissing);return CreateArchetype_Sorted(typesInArchetype, cachedComponentCount);
}
每个空的entity都要额外添加一个Simulate类型的component,这也是上面的截图中为何会多出一个component的原因。Unity首先会尝试从已有的空闲archetypes中寻找符合条件的archetype,没找到才会去真正创建一个。
public Archetype* GetOrCreateArchetype(ComponentTypeInArchetype* inTypesSorted, int count)
{var srcArchetype = GetExistingArchetype(inTypesSorted, count);if (srcArchetype != null)return srcArchetype;srcArchetype = CreateArchetype(inTypesSorted, count);return srcArchetype;
}
Unity的Archetype是一个非常复杂的struct,它记录了所代表的component信息,以及chunk信息,还有它们当前的状态:
[StructLayout(LayoutKind.Sequential)]
internal unsafe struct Archetype
{public ArchetypeChunkData Chunks;public UnsafeList<ChunkIndex> ChunksWithEmptySlots;public ChunkListMap FreeChunksBySharedComponents;public ComponentTypeInArchetype* Types; // Array with TypeCount elementspublic int* EnableableTypeIndexInArchetype; // Array with EnableableTypesCount elements// back pointer to EntityQueryData(s), used for chunk list cachingpublic UnsafeList<IntPtr> MatchingQueryData;// single-linked list used for invalidating chunk list cachespublic Archetype* NextChangedArchetype;public int EntityCount;public int ChunkCapacity;public int TypesCount;public int EnableableTypesCount;public int InstanceSize;public int InstanceSizeWithOverhead;public int ScalarEntityPatchCount;public int BufferEntityPatchCount;public ulong StableHash;public ulong BloomFilterMask;// The order that per-component-type data is stored in memory within an archetype does not necessarily match// the order that types are stored in the Types/Offsets/SizeOfs/etc. arrays. The memory order of types is stable across// runs; the Types array is sorted by TypeIndex, and the TypeIndex <-> ComponentType mapping is *not* guaranteed to// be stable across runs.// These two arrays each have TypeCount elements, and are used to convert between these two orderings.// - MemoryOrderIndex is the order an archetype's component data is actually stored in memory. This is stable across runs.// - IndexInArchetype is the order that types appear in the archetype->Types[] array. This is *not* necessarily stable across runs.// (also called IndexInTypeArray in some APIs)public int* TypeMemoryOrderIndexToIndexInArchetype; // The Nth element is the IndexInArchetype of the type with MemoryOrderIndex=Npublic int* TypeIndexInArchetypeToMemoryOrderIndex; // The Nth element is the MemoryOrderIndex of the type with IndexInArchetype=N// These arrays each have TypeCount elements, ordered by IndexInArchetype (the same order as the Types array)public int* Offsets; // Byte offset of each component type's data within this archetype's chunk buffer.public ushort* SizeOfs; // Size in bytes of each component typepublic int* BufferCapacities; // For IBufferElementData components, the buffer capacity of each component. Not meaningful for non-buffer components.// Order of components in the types array is always:// Entity, native component data, buffer components, managed component data, tag component, shared components, chunk componentspublic short FirstBufferComponent;public short FirstManagedComponent;public short FirstTagComponent;public short FirstSharedComponent;public short FirstChunkComponent;public ArchetypeFlags Flags;public Archetype* CopyArchetype; // Removes cleanup componentspublic Archetype* InstantiateArchetype; // Removes cleanup components & prefabspublic Archetype* CleanupResidueArchetype;public Archetype* MetaChunkArchetype;public EntityRemapUtility.EntityPatchInfo* ScalarEntityPatches;public EntityRemapUtility.BufferEntityPatchInfo* BufferEntityPatches;// @macton Temporarily store back reference to EntityComponentStore.// - In order to remove this we need to sever the connection to ManagedChangesTracker// when structural changes occur.public EntityComponentStore* EntityComponentStore;public fixed byte QueryMaskArray[128];
}
其中,TypesCount表示archetype所保存的数据种类,一般就是entity+component类型数量,这里空entity自带一个Simulate的component,那么TypesCount即为2;Types就是对应的类型数组了;EntityCount为当前archetype所拥有的entity数量;ChunksWithEmptySlots表示archetype中所有空闲chunk的索引列表,archetype就是通过它来为entity指定chunk的;然后,一系列First打头的Component(FirstBufferComponent,FirstManagedComponent,FirstTagComponent,FirstSharedComponent,FirstChunkComponent)表示在type数组中第一个出现该类型的索引;SizeOfs是一个比较重要的字段,它表示每个component type所占的内存大小,通过它可以进而计算出archetype最多可拥有entity的数量,也就是ChunkCapacity字段;在此基础上,还可以计算出每个component type在chunk中的起始位置Offsets;最后,Chunks是一个ArchetypeChunkData类型的字段,它用来记录archetype中所有chunk的状态。
有了archetype之后,就可以进入创建entity的阶段了,那么下一步,Unity会先查找是否有可用的chunk,没有的话就得真正分配内存,去创建一个:
ChunkIndex GetChunkWithEmptySlots(ref ArchetypeChunkFilter archetypeChunkFilter)
{var archetype = archetypeChunkFilter.Archetype;fixed(int* sharedComponentValues = archetypeChunkFilter.SharedComponentValues){var chunk = archetype->GetExistingChunkWithEmptySlots(sharedComponentValues);if (chunk == ChunkIndex.Null)chunk = GetCleanChunk(archetype, sharedComponentValues);return chunk;}
}
注意到这里函数返回的是ChunkIndex类型,它不是真正意义上的chunk,而是对chunk的二次封装,用来方便快捷地存取chunk的数据,以及记录chunk的各种状态与属性。ChunkIndex只有一个int类型的value变量,表示当前chunk在所有chunk中的位置。虽然Unity声称每个chunk只有16KB大小,但是实际分配内存时,并不是按16KB进行分配,而是会一口气先分配好1 << 20字节也就是64 * 16KB大小的内存,这块内存被称为mega chunk。所有mega chunk的内存指针都保存在大小为16384个ulong类型的连续内存中,因此ChunkIndex记录的是全局索引,第一步先索引到某个mega chunk,然后再定位到真正的chunk地址。

internal Chunk* GetChunkPointer(int chunkIndex)
{var megachunkIndex = chunkIndex >> log2ChunksPerMegachunk;var chunkInMegachunk = chunkIndex & (chunksPerMegachunk-1);var megachunk = (byte*)m_megachunk.ElementAt(megachunkIndex);var chunk = megachunk + (chunkInMegachunk << Log2ChunkSizeInBytesRoundedUpToPow2);return (Chunk*)chunk;
}
Chunk是一个相对简单的数据结构,前64字节为chunk头部,后面才是数据内容。
[StructLayout(LayoutKind.Explicit)]
internal unsafe struct Chunk
{// Chunk header START// The following field is only used during serialization and won't contain valid data at runtime.// This is part of a larger refactor, and this field will eventually be removed from this struct.[FieldOffset(0)]public int ArchetypeIndexForSerialization;// 4-byte padding to keep the file format compatible until further changes to the header.[FieldOffset(8)]public Entity metaChunkEntity;// The following field is only used during serialization and won't contain valid data at runtime.// This is part of a larger refactor, and this field will eventually be removed from this struct.[FieldOffset(16)]public int CountForSerialization;[FieldOffset(28)]public int ListWithEmptySlotsIndex;// Special chunk behaviors[FieldOffset(32)]public uint Flags;// SequenceNumber is a unique number for each chunk, across all worlds. (Chunk* is not guranteed unique, in particular because chunk allocations are pooled)[FieldOffset(kSerializedHeaderSize)]public ulong SequenceNumber;// NOTE: SequenceNumber is not part of the serialized header.// It is cleared on write to disk, it is a global in memory sequence ID used for comparing chunks.public const int kSerializedHeaderSize = 40;// Chunk header END// Component data buffer// This is where the actual chunk data starts.// It's declared like this so we can skip the header part of the chunk and just get to the data.public const int kBufferOffset = 64; // (must be cache line aligned)[FieldOffset(kBufferOffset)]public fixed byte Buffer[4];public const int kChunkSize = 16 * 1024;public const int kBufferSize = kChunkSize - kBufferOffset;public const int kMaximumEntitiesPerChunk = kBufferSize / 8;public const int kChunkBufferSize = kChunkSize - kBufferOffset;
}
随后,Unity会在该chunk中为要创建的entity分配索引,索引为当前chunk的entity数量,因为之前提到chunk的数据都是连续排布的,中间并不存在空隙。
static int AllocateIntoChunk(Archetype* archetype, ChunkIndex chunk, int count, out int outIndex)
{outIndex = chunk.Count;var allocatedCount = Math.Min(archetype->ChunkCapacity - outIndex, count);SetChunkCount(archetype, chunk, outIndex + allocatedCount);archetype->EntityCount += allocatedCount;return allocatedCount;
}
根据索引,就可以将chunk中属于该entity的部分(entity id,component type)进行初始化,clear内存等操作,自此,一个entity就算创建完成了。
for (var t = 1; t != typesCount; t++)
{var offset = offsets[t];var sizeOf = sizeOfs[t];var dst = dstBuffer + (offset + sizeOf * dstIndex);if (types[t].IsBuffer){for (var i = 0; i < count; ++i){BufferHeader.Initialize((BufferHeader*)dst, bufferCapacities[t]);dst += sizeOf;}}else{UnsafeUtility.MemClear(dst, sizeOf * count);}
}
接下来,再为entity添加component,那么原来entity所在的chunk和archetype不再满足要求,需要将entity移动到新的chunk和archetype中,这种行为在Unity中被称作structural change。在AddComponent之前,Unity首先会检查entity是否已有该component,同一类型的component只允许存在一个。这个时候archetype就发挥作用了,只需要去archetype中查找component type是否存在即可:
public bool HasComponent(Entity entity, ComponentType type)
{if (Hint.Unlikely(!Exists(entity)))return false;var archetype = GetArchetype(entity);return ChunkDataUtility.GetIndexInTypeArray(archetype, type.TypeIndex) != -1;
}
如果entity没有该component,那么就需要找一下符合条件的archetype以及空闲的chunk。
ChunkIndex GetChunkWithEmptySlotsWithAddedComponent(ChunkIndex srcChunk, ComponentType componentType, int sharedComponentIndex = 0)
{var archetypeChunkFilter = GetArchetypeChunkFilterWithAddedComponent(srcChunk, componentType, sharedComponentIndex);if (archetypeChunkFilter.Archetype == null)return ChunkIndex.Null;return GetChunkWithEmptySlots(ref archetypeChunkFilter);
}
新的archetype和chunk都有了,剩下的就是move操作了,先把数据从源chunk拷贝到目标chunk中去,更新目标archetype,然后再清理源chunk,更新源archetype。
int Move(in EntityBatchInChunk srcBatch, ChunkIndex dstChunk)
{var srcChunk = srcBatch.Chunk;var srcArchetype = GetArchetype(srcChunk);var dstArchetype = GetArchetype(dstChunk);var dstUnusedCount = dstArchetype->ChunkCapacity - dstChunk.Count;var srcCount = math.min(dstUnusedCount, srcBatch.Count);var srcStartIndex = srcBatch.StartIndex + srcBatch.Count - srcCount;var partialSrcBatch = new EntityBatchInChunk{Chunk = srcChunk,StartIndex = srcStartIndex,Count = srcCount};ChunkDataUtility.Clone(srcArchetype, partialSrcBatch, dstArchetype, dstChunk);fixed (EntityComponentStore* store = &this){ChunkDataUtility.Remove(store, partialSrcBatch);}return srcCount;
}
前面提到过,当从chunk中移除entity时,chunk的最后一个entity将被移动以填补空隙。其实就是个简单的拷贝内存操作:
var fillStartIndex = chunk.Count - fillCount;Copy(entityComponentStore, chunk, fillStartIndex, chunk, startIndex, fillCount);
Reference
[1] Archetypes concepts
[2] 深入理解ECS:Archetype(原型)
[3] Archetypes window reference
[4] Structural changes concepts