简介
性能基准测试是 HPC 的标志。最现代的超级计算机是具有异构架构的计算节点集群。在这样的节点中,我们可以看到经典 CPU 和专用计算协处理器 (GPU)。本教程介绍了使用基于 InfiniBand 写入带宽 (ib_write_bw) 构建的定制脚本对 NVIDIA GPUDirect 远程直接内存访问 (GPUDirect RDMA) 进行基准测试的方法。
使用 ib_write_bw.sh 脚本对 GPUDirect RDMA 进行基准测试提供了一种简单有效的机制,可以在 HPC 群集中执行 GPUDirect RDMA 基准测试,而无需担心软件安装、依赖项或配置。此脚本包含在 OCI HPC 堆栈 2.10.2 及更高版本中。包含所有接口详细信息的综合测试报告将显示在 OCI 堡垒控制台上,并存储在 /tmp 中以供将来参考。
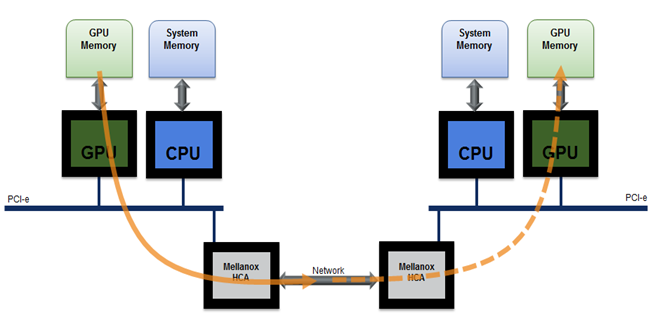
Remote Direct Memory Access (RDMA) 允许外设组件互连 Express (PCIe) 设备直接访问 GPU 内存。NVIDIA GPUDirect RDMA 专为满足 GPU 加速需求而设计,可在远程系统中的 NVIDIA GPU 之间进行直接通信。它是一种技术,能够使用 PCI Express 的标准功能在 GPU 与第三方对等设备之间实现数据交换的直接路径。它在特斯拉和四功能级 GPU 上启用,GPUDirect RDMA 依赖于 NVIDIA GPU 在 PCI Express 基本地址寄存器区域中公开部分设备内存的功能。
GPU RDMA
Perftest Package 是用 Uverbs 编写的测试集合,用于作为性能微基准。它包含一组带宽和延迟基准,例如:
-
发送:
ib_send_bw和ib_send_lat -
RDMA 读取:
ib_read_bw和ib_read_lat -
RDMA 写入:
ib_write_bw和ib_write_lat -
RDMA 原子:
ib_atomic_bw和ib_atomic_lat -
本机以太网(使用 MOFED2 时)-
raw_ethernet_bw和raw_ethernet_la
注:
perftest软件包需要使用计算统一设备体系结构 (Compute Unified Device Architecture,CUDA) 进行编译,才能使用 GPUDirect 功能。
在本教程中,我们将重点介绍使用 InfiniBand 写入带宽 (ib_write_bw) 发送事务的 GPUDirect RDMA 带宽测试,该测试可用于使用 RDMA 写入事务测试带宽和延迟。我们将使用本机 ib_write_bw 的定制包装脚本自动执行安装和测试过程。此脚本可用于在集群中的两个 GPU 节点之间检查 ib_write_bw。如果节点上安装了 CUDA,则执行将使用 CUDA 重新编译 perftest 软件包。
目标
- 使用基于
ib_write_bw构建的定制脚本对 NVIDIA GPUDirect RDMA 进行基准测试。
先决条件
-
CUDA 工具包 11.7 或更高版本。
-
安装 NVIDIA Open-Source GPU Kernel Modules 版本 515 或更高版本。
使用 CUDA DMA-BUF 手动安装 perftest
继续手动安装之前,请确保满足所有先决条件,我们将安装在支持的 GPU 配置上。
-
配置/使用。
-
导出以下环境变量
LD_LIBRARY_PATH和LIBRARY_PATH。export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHexport LIBRARY_PATH=/usr/local/cuda/lib64:$LIBRARY_PATH
-
-
克隆
perftest系统信息库并使用 CUDA 进行编译。git clone https://github.com/linux-rdma/perftest.git -
克隆后,请使用以下命令。
cd perftest/ ./autogen.sh && ./configure CUDA_H_PATH=<path to cuda.h> && make -j, e.g.: ./autogen.sh && ./configure CUDA_H_PATH=/usr/local/cuda/include/cuda.h && make -j因此,-use_cuda= 标志将可用于添加到命令行:
./ib_write_bw -d ib_dev --use_cuda=<gpu index> -a
注:使用
ib_write_bw手动测试 GPUDirect RDMA 需要卸载现有软件包并使用 CUDA 重新编译它。在继续基准测试之前,我们需要手动验证节点配置、GPU 计数和节点上的活动 RDMA 接口。
解决方案概览
ib_write_bw.sh 是一个脚本,它通过自动执行与之相关的所有手动任务来简化 GPUDirect RDMA 基准测试过程。可以使用所有参数直接从堡垒本身触发此脚本。无需在传统的客户机/服务器模型中运行。脚本在执行期间执行以下检查。如果这些检查中的任何一个失败,它将退出并显示错误。
- 节点配置。
- CUDA 安装。
- 安装的 GPU 总数和输入的 gpu ID。
- 服务器和客户机上的活动 RDMA 接口。
- 支持的配置
- BM.GPU.B4.8
- BM.GPU.A100-v2.8
- BM.GPU4.8
- 先决条件
- 支持的 GPU 配置。
- 安装的 CUDA 驱动程序和工具包。
如果所有检查都已通过,ib_write_bw.sh 将生成和执行一个可执行的手册来执行安装和配置。
脚本
-
名称:
ib_write_bw.sh -
位置:
/opt/oci-hpc/scripts/ -
堆栈:
HPC -
堆栈版本:
2.10.3 and above
使用情况
sh ib_write_bw.sh -h Usage: ./ib_write_bw.sh -s <server> -n <node> -c <y> -g <gpu id> Options: s Server hostname n Client hostname. c Enable cuda (Default: Disabled) g GPU id (Default: 0) h Print this help. Logs are stored at /tmp/logs e.g., sh ./ib_write_bw.sh -s compute-permanent-node-1 -n compute-permanent-node-2 -c y -g 2 Supported shapes: BM.GPU.B4.8,BM.GPU.A100-v2.8,BM.GPU4.8
输出样
sh ib_write_bw.sh -s compute-permanent-node-14 -n compute-permanent-node-965 -c y -g 1 Shape: "BM.GPU4.8" Server: compute-permanent-node-14 Client: compute-permanent-node-965 Cuda: y GPU id: 1 Checking interfaces... PLAY [all] ******************************************************************************************************************************* TASK [Gathering Facts] ******************************************************************************************************************* ok: [compute-permanent-node-14] ok: [compute-permanent-node-965] TASK [check cuda] ************************************************************************************************************************ ok: [compute-permanent-node-965] ok: [compute-permanent-node-14] . . Testing active interfaces... mlx5_0 mlx5_1 mlx5_2 mlx5_3 mlx5_6 mlx5_7 mlx5_8 mlx5_9 mlx5_10 mlx5_11 mlx5_12 mlx5_13 mlx5_14 mlx5_15 mlx5_16 mlx5_17 ib_server.sh 100% 630 2.8MB/s 00:00 ib_client.sh 100% 697 2.9MB/s 00:00 Server Interface: mlx5_0 initializing CUDA Listing all CUDA devices in system: CUDA device 0: PCIe address is 0F:00 CUDA device 1: PCIe address is 15:00 CUDA device 2: PCIe address is 51:00 CUDA device 3: PCIe address is 54:00 CUDA device 4: PCIe address is 8D:00 CUDA device 5: PCIe address is 92:00 CUDA device 6: PCIe address is D6:00 CUDA device 7: PCIe address is DA:00 Picking device No. 1 [pid = 129753, dev = 1] device name = [NVIDIA A100-SXM4-40GB] creating CUDA Ctx making it the current CUDA Ctx cuMemAlloc() of a 131072 bytes GPU buffer allocated GPU buffer address at 00007f29df200000 pointer=0x7f29df200000 --------------------------------------------------------------------------------------- RDMA_Write BW Test Dual-port : OFF Device : mlx5_0 Number of qps : 1 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON ibv_wr* API : ON TX depth : 128 CQ Moderation : 1 Mtu : 4096[B] Link type : Ethernet GID index : 3 Max inline data : 0[B] rdma_cm QPs : OFF Data ex. method : Ethernet --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x008b PSN 0xe4ad79 RKey 0x181de0 VAddr 0x007f29df210000 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:19:196 remote address: LID 0000 QPN 0x008b PSN 0x96f625 RKey 0x181de0 VAddr 0x007f9c4b210000 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:16:13 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] CPU_Util[%] 65536 407514 0.00 35.61 0.067920 0.78
测试概要
GPUDirect 计算节点每个接口的 RDMA 测试概要将显示在堡垒上,相同内容将存储在堡垒上的文件夹 /tmp/ib_bw 中。
它查找的重要参数是 BW average[Gb/sec]。
************** Test Summary ************** Server interface: mlx5_0 #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] CPU_Util[%] 65536 407514 0.00 35.61 0.067920 0.78 --------------------------------------------------------------------------------------- Server interface: mlx5_1 #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] CPU_Util[%] 65536 407569 0.00 35.61 0.067929 0.78 --------------------------------------------------------------------------------------- Server interface: mlx5_2 #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] CPU_Util[%] 65536 407401 0.00 35.60 0.067901 0.78 ---------------------------------------------------------------------------------------
参考:
使用 InfiniBand 写入带宽对 NVIDIA GPUDirect RDMA 进行基准测试