1.前言
关于JS在渗透测试中的关键作用,想必不用过多强调,在互联网上也有许多从JS中找到敏感信息从而拿下关键系统的案例。大部分师傅喜欢使用findsomething之类的浏览器插件,也有使用诸如Unexpected.information以及APIFinder之类的Burp插件,也有师傅喜欢使用packerfuzzer和JSFinder之类的工具。上述脚本和工具都是非常优秀的,笔者在日常测试中也经常将上述工具结合着使用。但是,如果只是单独使用上面的部分脚本和工具,实际上能找到的攻击面是比较狭隘的,并且也不能比较全面地去搜集JS中存在的,可能被我们利用的信息。
本文作为渗透测试中的JS分析中的第一篇文章,就打算来和师傅们分享一下我喜欢在JS中提取哪些信息,以及我用到的工具、脚本、规则,可能不是最全面的,但应该是最常用和实用的,有不足之处希望师傅们指出。这个系列后续还会出一篇文章介绍怎样从JS中提取参数辅助接口测试,出一到两篇文章介绍提取JS的几个场景,师傅们点点关注哦。
2.JS接口提取二三事
一提到JS信息的提取,最老生常谈的一点当然是从JS中提取接口,然后去测试各个接口的问题。但关键问题在于,我们应该用什么样的方法去尽可能全面地提取JS中的接口呢?很多师傅这时候就会想到,我用findsomething这样的插件不就一把梭了吗?非也,不如我们来看这样一个情况,下面的案例来自小队以往的项目:

看到这样一个网站,其使用webpack技术打包JS
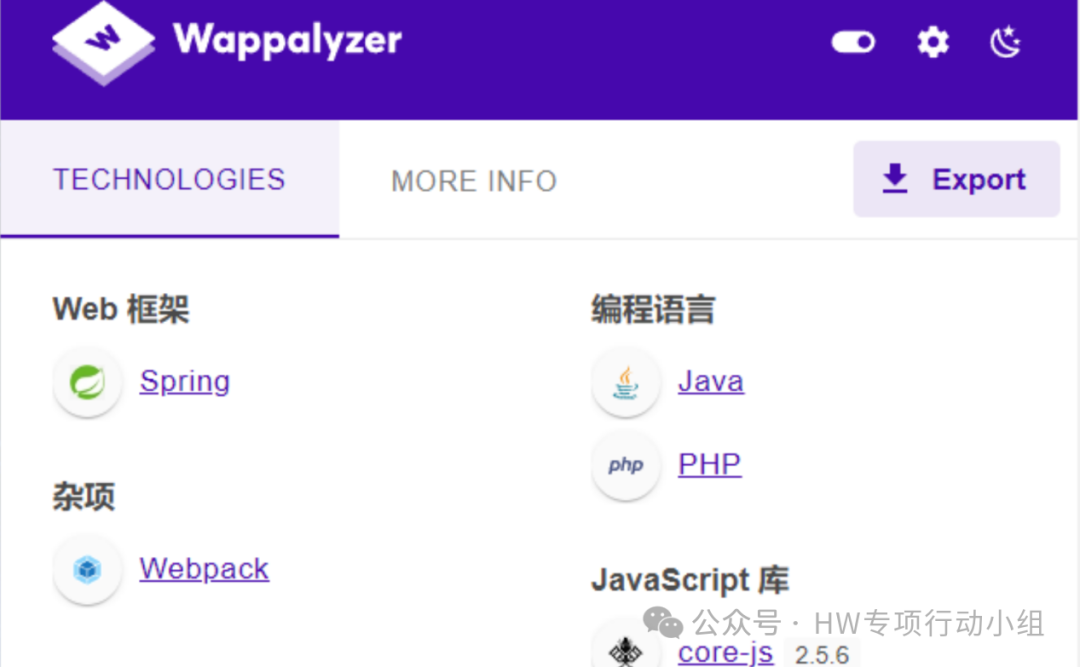
我们打开findsomething,可以看到findsomething直接被致盲了,什么接口都没有找到
实际上,由于webpack压缩了很多js文件,findsomething并没有深入测试webpack的功能,因此findsomething在很多情况,只是找到了浮在海面上的一点点冰山,却忽视了隐藏在海面下的更多的细节。
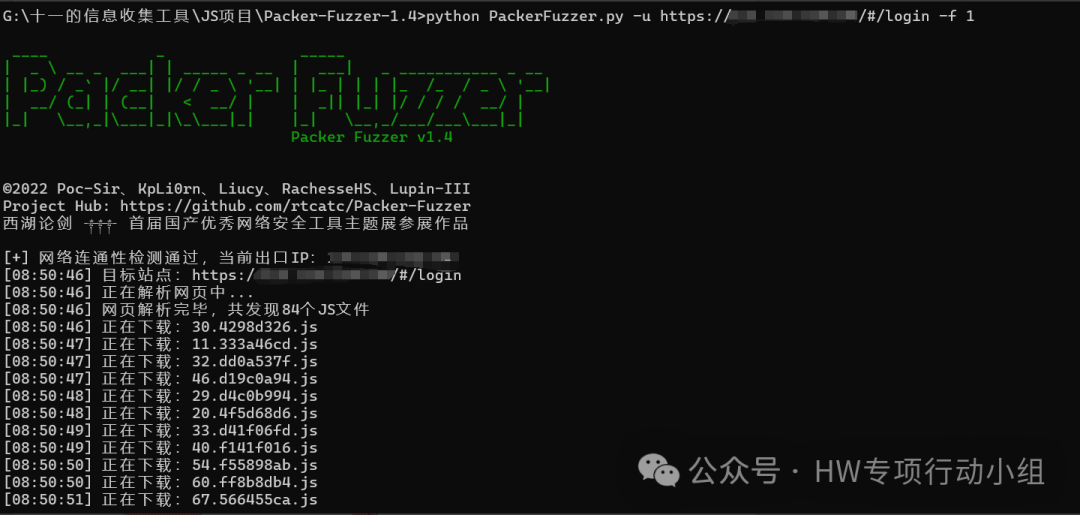
这种情况本来是打算留到JS提取的不同场景和师傅们分享的,由于在本文的这个场景也非常合适,所以提前分享出来了。言归正传,这种情况我们应该怎么去提取JS中的接口呢?我们只需要用到一些针对webpack情况的工具即可。这里我用的是packerfuzzer:
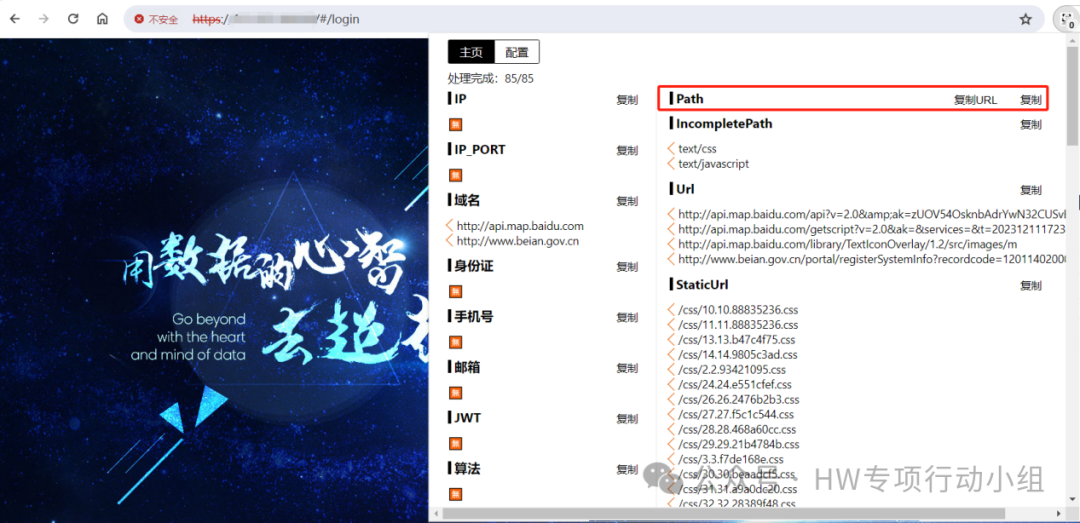
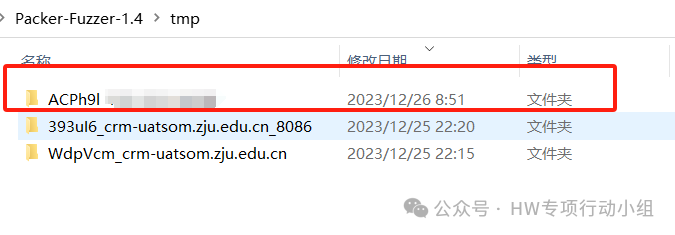
Packer-Fuzzer会把所有的JS文件保存到tmp目录中
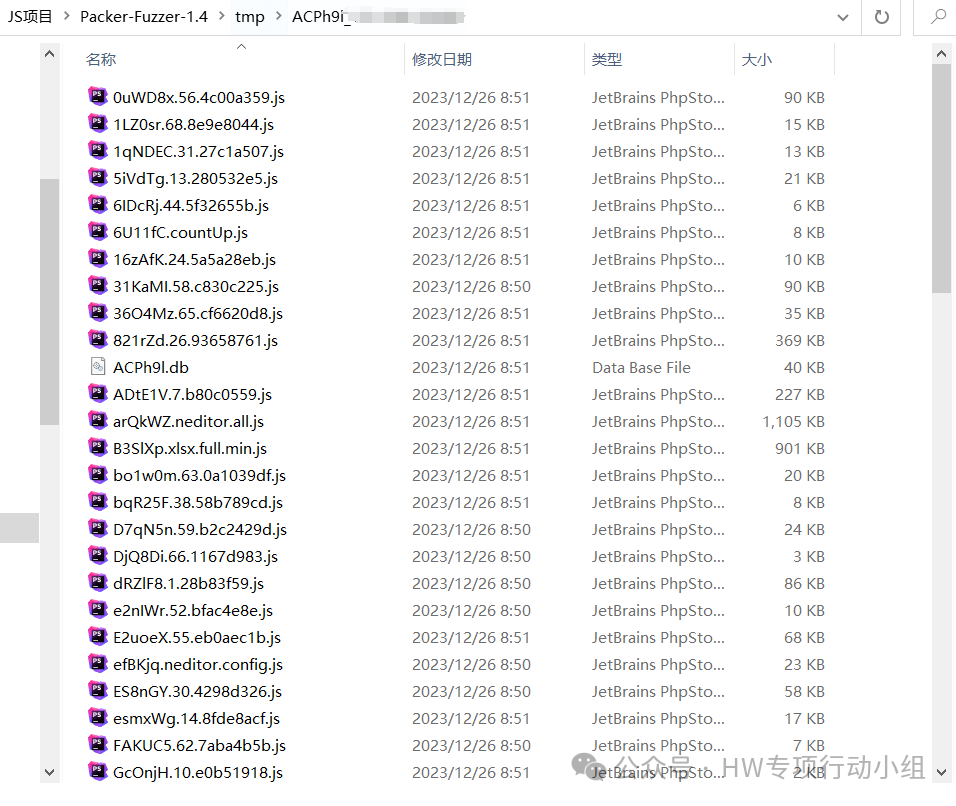
由于packerfuzzer在自动测试过程中可能会让你输入接口的“初级目录”,在前后端分离的场景下需要用一些参数指定后端,因此实际上我并不喜欢用packerfuzzer自动测试,我喜欢提取出接口和后端后自己用burp的intruder去测试。因此这里有一个脚本用于处理packerfuzzer下载回来的JS文件:
这脚本最开始也是我在Github上乱翻找到的,我对其正则做了一些优化。这个正则其实很好理解,该脚本会匹配被单引号或者双引号包裹起来的字符串,如果字符串被/分割,则将其提取。所以能够很全面地提取js中的接口uri,以上文的案例为例,我们用packerfuzzer+接口脚本,直接就可以提取出大量接口,并且有部分接口只能被这个小脚本的正则匹配到:
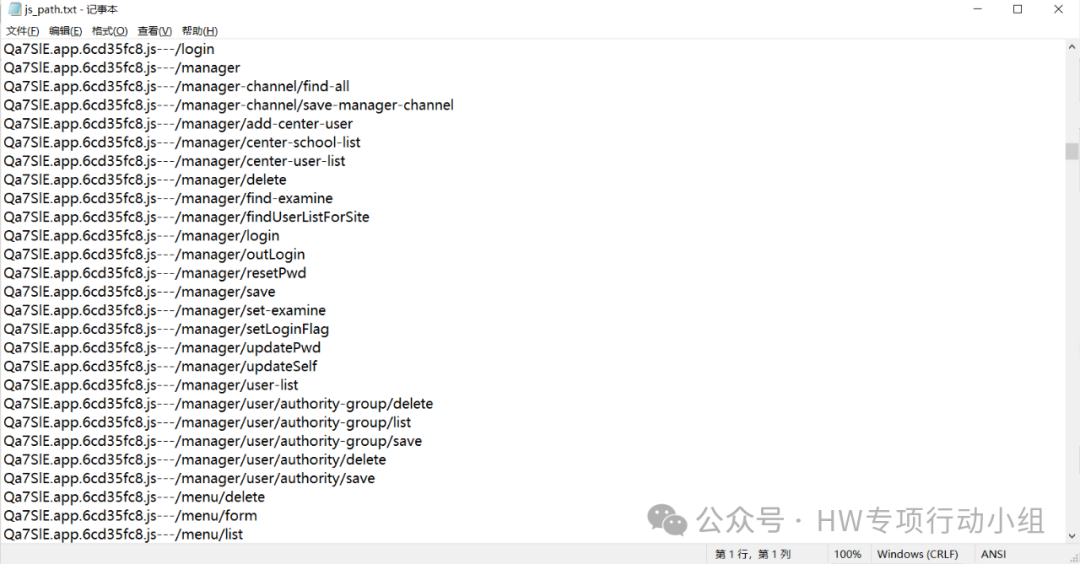
是不是比单纯使用findsomething强大多了?因此,我现在非常喜欢使用packerfuzzer充当一个“JS下载器”,然后用这个脚本来提取接口,对于绝大部分普通情况,packerfuzzer可以完美下载JS,对于部分使用webpack的特殊情况,更是只有packerfuzzer能够胜任。
那么这是不是说,我们提取JS接口的核心就是我们的小脚本,packerfuzzer就是纯纯的下载器呢?也绝对不是这样的。还记得我们说,我们提取接口的脚本的规则是“匹配被单引号或者双引号包裹起来的字符串,如果字符串被/分割,则将其提取”。那假如一个很奇葩的写法,接口uri不被单引号、双引号包裹,或者其中没有/呢?这听着似乎非常匪夷所思,这样写JS不会运行异常?然而笔者在某次众测中真就遇到了这样的情况,这回换小脚本抓瞎了,但是packerfuzzer却能找到一些接口。还是打开tmp目录:

其中有一个.db文件,使用随便一个数据库管理工具打开它

在这种情况下,packerfuzzer的规则仍然可以找到很多接口,还是很有用的。
那这是不是又说明,我们只需要小脚本+packerfuzzer结合着用,就可以应付所有情况,findsomething和Unexpected.information这类插件直接淘汰就好呢?也不尽然,我们再分享一个案例,也来自于笔者的企业SRC挖掘案例(本来也打算留到后续的文章介绍,这里也先分享出来)。
上图的这个网站,直接查看其前端并没有找到任何和app.js index.js main.js等比较经典的和webpack相关的文件。
然而查看burp的history,却发现该网站加载了app.js,并且unexpected information插件成功在其中匹配到了各种信息

在这种情况下,packerfuzzer可能在一定程度上失灵,但是unexpected information和findsomething却有可能找到我们需要的信息。
总之,上面我们就大概介绍了要如何去提取接口uri。除了普通的接口,上述技巧亦可能找到一些pdf、docx之类的文档,攻击者可能从这些乱七八糟的文件甚至是图片中再找到一些敏感信息,这里就不继续展开了。
上面介绍这些情况,其实主要是和大家说明,这些脚本和工具都很棒,但他们都不是全能的,在不同场景下,侧重使用的脚本和工具都不同,不能单单依赖某一种。不过我实测packerfuzzer+小脚本这种用法的泛用性很高,对策性一般,鉴定为超大杯,推荐各位师傅试一试。
3.目录FUZZ和接口提取的奇妙搭配
通过上述方法我们就一定能万无一失的提取所有接口了吗?
我们假设你通过分析JS找到了很多接口,比如
http://test.hack.com/api/test/admin/delete
http://test.hack.com/api/test/admin/edit
http://test.hack.com/api/test/admin/get
这种时候我们要注意了,接口的命名一般都和功能高度相关。这里有管理员用户的删除(delete)、编辑(edit)、获取(get)
那么你还能想到什么?是不是有可能能有添加(add、create)。那我们可以注意FUZZ这个点
http://test.hack.com/api/test/admin/add
http://test.hack.com/api/test/admin/create
总之就是有“添加”这个意思的单词。对于增删改查的接口关键词,我自己总结了一些。
查询(获取信息)``search list select query get find
删除(删除某个数据)``del Delete
编辑(更新某个信息)``Update Up edit Change
添加(增加某个信息)``add create new
我们FUZZ的思路不止于此,再设想一个场景。我们现在获得了这样一些接口:
http://test.hack.com/api/test/user/add
http://test.hack.com/api/test/user/update
可以看到,是对普通用户进行添加和更新的接口。那我们猜想,是否可能存在对管理员用户进行添加和更新的接口呢?我们可以尝试FUZZ:
http://test.hack.com/api/test/FUZZ/add
当然,实战中不一定完全符合上面这个接口路径,比如下面这个呢?
http://test.hack.com/api/test/adminDelete
http://test.hack.com/api/test/adminEdit
http://test.hack.com/api/test/adminGet
很显然还是能看出规则。
总之就是要提醒你,多观察接口,推测其功能,然后根据功能去FUZZ,毕竟你要实现一个web功能,基本都要有对应的增删改查接口,我们可以依据这个思想去试试。说不定就添加用户进后台了。上述思想其实也不止于测试接口,部分传统的动态脚本网站,其实靠上述思想也能找到很多有趣的东西。一个最简单的例子,比方说:
http://test.hack.com/admin/login.jsp
是不是可以尝试去找找
http://test.hack.com/admin/register.jsp
当然,上述操作在实战中肯定不能手动试,需要一个比较强大的字典去进行FUZZ,这里推荐FFUF这款工具,非常快,非常自由,而且可以FUZZ uri甚至整个数据包中的任何位置。
不过,目录FUZZ和接口提取、测试的缘分远不止于此,在某些情况下,我们是否可以通过FUZZ JS文件,找到后端的一些文件打开突破口呢?还是以某个企业SRC的案例为例:
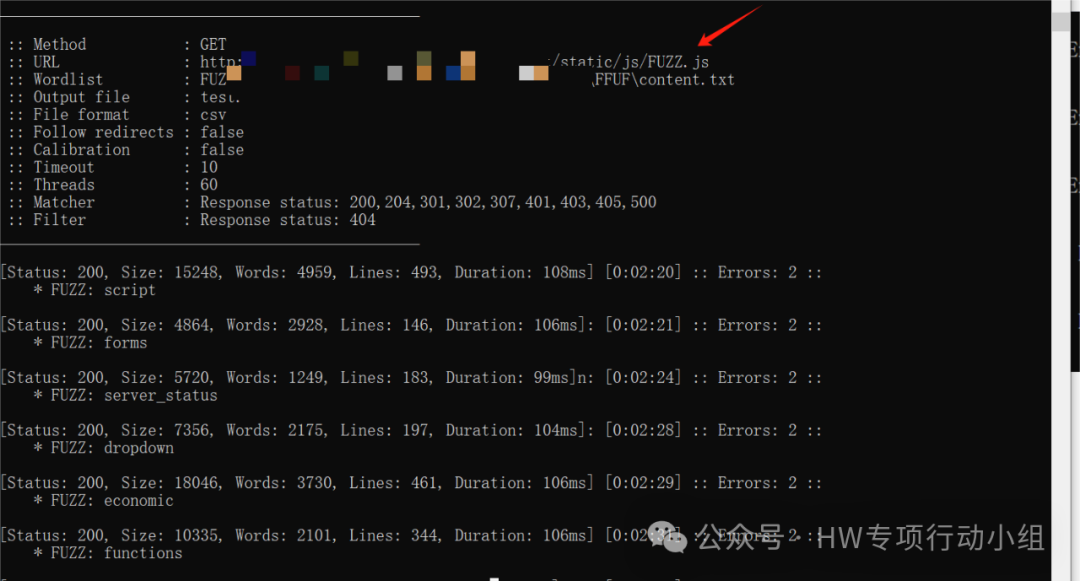
这就是另一个故事了,后续我们在提取JS的不同场景中会进一步介绍这些东西。
4.后端啊,你在哪里?
上面我们就分享了从JS中提取接口uri的一些方法,几个现成的工具组合着用就行。但是,提取出这些接口uri之后,我们要怎么提取后端地址,又要怎么拼接测试呢?这其中又有很多值得说到的点。首先我们来介绍第一种和JS无关的方法。我将其称之为“现有功能分析法”,听着很高大上,其实很EZ,简单来说你一个网站,页面上肯定有很多功能,以登录场景为例,肯定是有一个登录的功能嘛。那我们可以抓取登录的数据包,观察其接口的uri规则,而且在你访问某个网站的时候,很多时候会先访问一些接口来完成初始化,或者获取你的某些状态,在没有登录点的情况下,通过这些接口也是可以的。
比方说我们调用http://test.com/#/login的登录点

上图就是一个登录点的uri。这里我们引入一个“初级目录”的概念,打引号是因为绝大多数情况下这并不是真正的目录。
什么意思呢?我们以Spring开发为例,对SpringSSM比较熟悉的小伙伴应该知道,我们可以在配置文件里添加一个配置项:
server.servlet.context-path
比方说
server.servlet.context-path=/vsk
这样,你的web应用的所有uri前面都要加一层/test1,比方说我给登录的动作配置一个RequestMapping,为@RequestMapping(“/virsical-auth/oauth/token”);
那么如果我想通过WEB访问这个动作,应该访问的uri应该是:
/vsk/virsical-auth/oauth/token
(当然这里是简化过的,实际上真正的构成规则我猜测是设置初始路径为/vsk,然后负责登录相关功能的controller设置为/virsical-auth,然后给Controller里的具体方法设置为/oauth/token)
通过上面这个例子你想到了什么?没错,我们上面抓到的那个数据包,有可能是以/vsk作为初始路径。然后我们通过前文的提取接口相关的技术找到的接口uri可能是/virsical-auth/oauth/token,这样我们就知道怎么拼接了,就可以得到/vsk/virsical-auth/oauth/token。
当然实战中绝大部分都是黑盒的情况,你通过现有功能看到这么一个uri,其实也不一定能百分百判断到底哪个是初级uri,比方说上述情况。有可能是/vsk作为初级uri,亦可能是/vsk/virsical-auth/作为初级uri,这个需要靠经验来判断。如果你怕判断有误,最好的办法就是多拼接几次,比如:
http://test.com/vsk/ <—接口依次拼接在这后面
http://test.com/vsk/virsical-auth/ <—接口依次拼接在这后面
http://test.com/vsk/virsical-auth/oauth/ <—接口依次拼接在这后面
以此类推,不过一般比较少出现这种情况。上述是“初级目录”的情况,还有一种情况则是前后端分离。这个也很好理解。比方说你访问的网站是:
http://admin.test.com/#/login
然而负责提供服务的后端地址可能是:
http://api.admin.test.com/api/admin/login
http://admin.test.com:8080/api/admin/login
这些抓包都很容易看出来,就不赘述了。此外还有一种很有趣的情况,还是以我们上面提取出的接口为例:
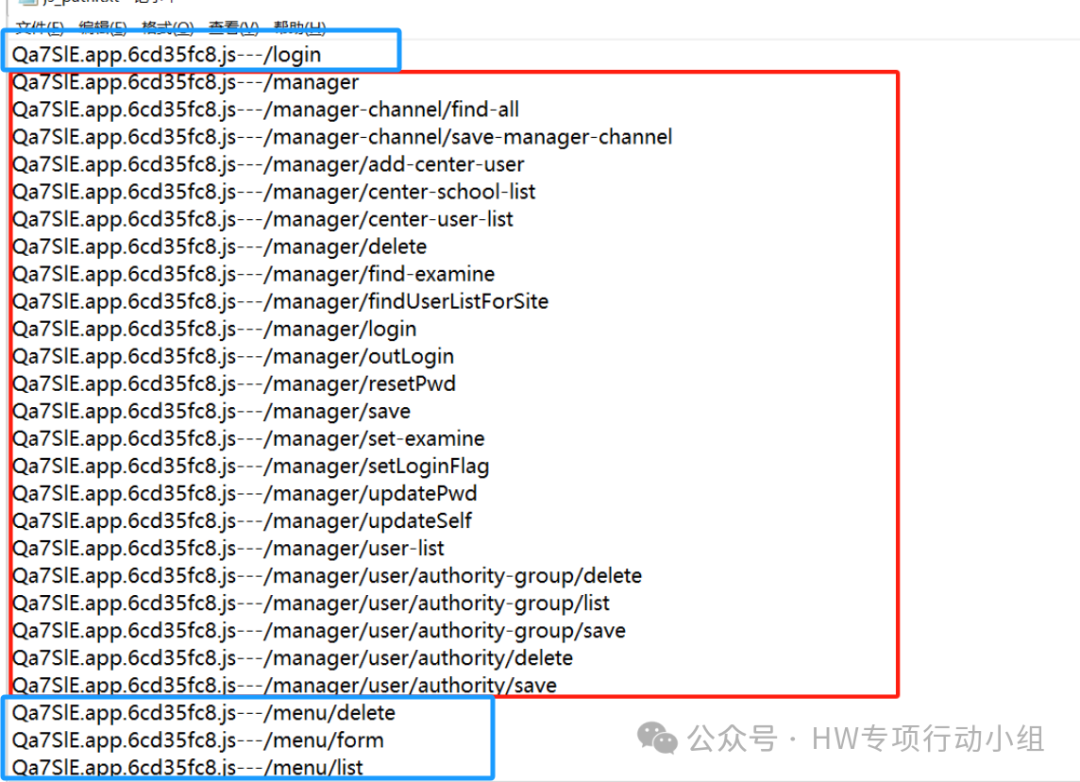
注意看蓝框标注的部分,这些“接口”uri比其它接口uri显著短得多,而且规则也不一样,很多时候你把他们与后端或者“初级路径”做拼接去请求,却发现直接404了,那么这种是什么呢?这些实际上大部分是前端uri,相信师傅们经常能看到
http://test.com/#/login
http://test.com/#/index
这样的路径,这实际上就是前端的uri,当然不一定每个系统都是这样,也得因地制宜地去观察规则,比方说在上图中,我们尝试访问:
http://test.com/#/menu/list
也有可能直接去访问到一些鉴权没做好的页面,去看到一些信息或者调用某些功能。
同样地,我们要想,上述这种“现有功能分析法”就足够了吗?这登录点又何尝不是冰山一角呢?让我们来假设这么一些情况:
情况一:某个后台,访问即重定向到SSO登录,能加载出JS,但是在这个过程中不会访问多余的接口,也没有登录之类的现成功能点给我们调用。这样我们没法通过现有功能去获取到接口uri,这对我们判断“初级路径”就会造成很大阻碍,更何况如果目标采用前后端分离,我们都不知道后端在哪里,又该怎么拼接接口测试呢?
情况二:还是某个后台,假如开发的思维非常严谨,给每个Controller都设置了一个RequestMapping,比方说登录相关功能可能放在/login/这个uri下,普通用户的功能放在/user/,管理员的功能放在/admin/。也就是说,我们至少有可能存在三种“初级路径”,在这种情况下,即使我们有一个登录的现有功能,我们也只是获取到了/login/这个初级路径,而我们提取的接口uri肯定绝大部分都是分布在/user/和/admin/两个路径下,在这种情况下,实际上也相当于我们忽略掉了绝大部分的接口。
那么这又该如何破局呢?其实也非常ez,因为他这些后端地址包括“初级路径”,肯定不是无中生有搞出来的,这些东西肯定都在JS里。比方说上面的那个多个初级路径的情况,在JS中大概率存放了一些地址:
http://api.test.com/login/
http://api.test.com/user/
http://api.test.com/admin/
当用户访问对应功能,比方说普通用户修改自己的密码,前端会取出:
/userApi/changePwd
然后和对应的地址做拼接:
http://api.test.com/user/userApi/changePwd
然后发起一次请求。
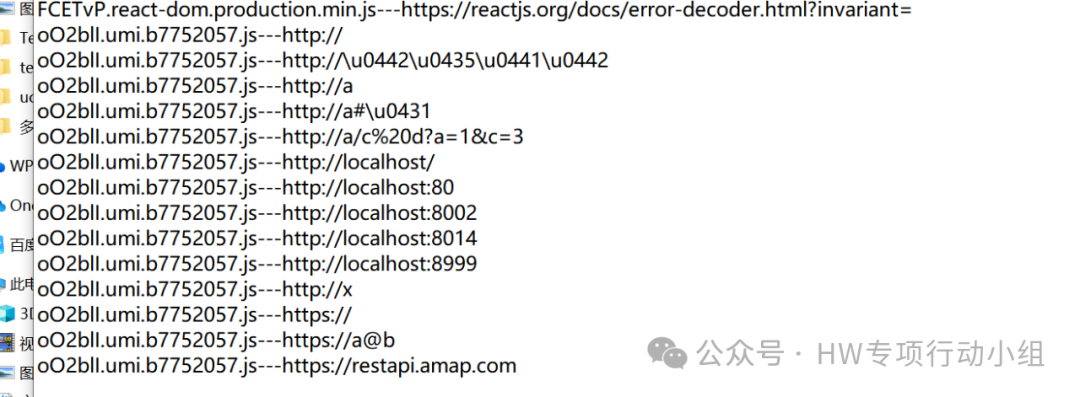
因此我们上述提取接口,实际上就是提取了所有类似/userApi/changePwd这样的uri。我们要找后端也很简单,写个正则专门匹配http://或https://开头的字符串即可:

这个正则也比较简单,效果大概是这样:
Unexpected information和findsomething也可以实现一部分这样的功能,如下图也是来自于某个企业src:

Unexpected information插件就帮我们找到了大量后端地址。
我们获取到所有可能的后端和初级路径之后,我比较喜欢的操作其实是采用笛卡尔积去依此拼接初级路径。简单来说:
后端字典 接口字典`` ``http://api1.test.com/ /user/getinfo`` ``http://api2.test.com/api/admin/ /user/register`` ``http://api2.test.com/api/ /manager/changeSetting
按照笛卡尔积拼接处理可以得到:
http://api1.test.com/user/getinfo` ` ``http://api1.test.com/user/register`` ``http://api1.test.com/manager/changeSetting`` ``http://api2.test.com/api/admin/user/getinfo` ` ``http://api2.test.com/api/admin/user/register`` ``http://api2.test.com/api/admin/manager/changeSetting`` ``http://api2.test.com/api/user/getinfo` ` ``http://api2.test.com/api/user/register`` ``http://api2.test.com/api/manager/changeSetting
然后我们把这个最终的列表丢给HTTPX之类的工具跑一遍,测测活,根据响应码和数据包长度去筛选出所有可用接口,管他什么后端、初级路径,一下就能找到了,要的就是笨办法!当然这一步要是乐意也可以用burp的Cluster bomb去搞,反正啥工具用得顺手就用啥工具去测活。
综上我们就简单介绍了怎么去提取后端,然后怎么去拼接测试。然而我们提取出后端或者别的地址后,也不要只盯着接口拼接和测活去搞,眼界开拓点,这些新找到的地址,靠常规的信息搜集手法不一定能找到,属于藏得比较深的资产,所以算是比较重要的攻击面,可以进一步对这些新的地址进行全端口扫描、漏扫或者其他测试手段,说不定就找到啥洞能直接一把梭getshell了。因此获取JS中的后端、地址实际上是两个目的,一个是与接口测试相结合,另一个则是打开新的攻击面。
5.通过FUZZ“初级路径”打开突破口
同样地,我们上面介绍了从JS和现有功能中去寻找后端地址和初级路径的一些方法和思想。但我们还是扪心自问一下,这就是全部了?
实际上并不是,我举一个例子就很好理解了,有些开发在写后端的时候,喜欢加一些用于测试的接口和页面,这些接口肯定不会放在js里,并且其uri和js中的正常接口可能截然不同。反正大部分情况下初级路径是不同的。因此有时候习惯性对后端地址FUZZ一下初级路径,会有很大收获。这里也给出一个企业src中的例子,虽然这个漏洞被修复了,不过我还是要进行很多改动,可能会影响一些观看体验。
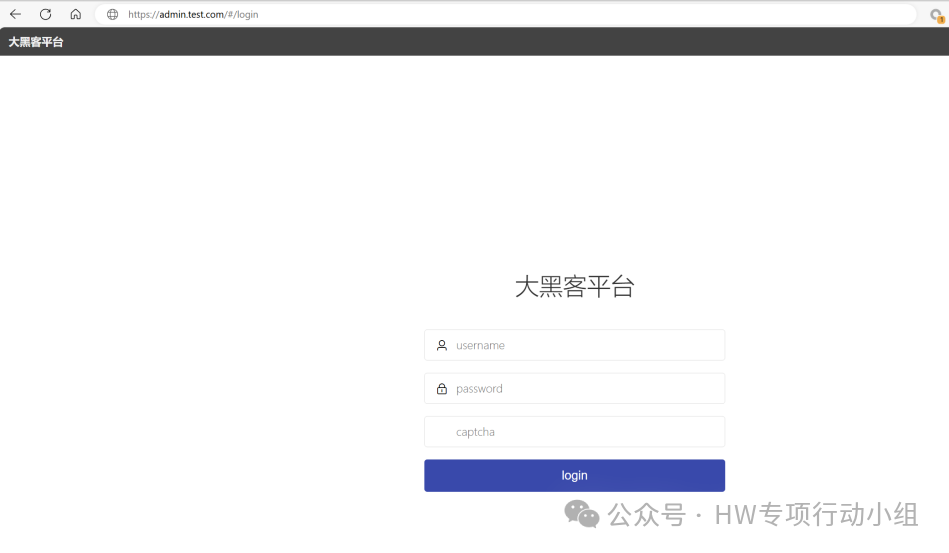
提取这个平台的后端和接口进行测试,除了登录接口全部鉴权,其默认初始路径为/api/
我根据其Title,在bing搜索类似网站:

找到一个ip,有可能是上述平台的测试版本,其页面内容和title同样是大黑客平台,对这个平台进行目录FUZZ

成功找到一个特殊的uri,其中返回所有测试接口信息,进一步拼接测试找到大量未授权接口。
上述案例出于保密性,因此用F12给页面内容全都修改了,并且省略了大量细节,但却是一个真实存在的案例,通过FUZZ初级目录和接口,找到了开发者遗留的测试接口文档,进一步找到大量接口未鉴权。总之,目录FUZZ是非常好的组合技,可以在很多意想不到的地方助我们一臂之力。
当然这里我们其实还可以拓展,那就是既然每一级目录下都可能有一些新东西,为什么我们不可以写一个插件去递归测试呢?比如java中常见的swaggerui、api-docs接口文档,再比如actuator端点泄露,druid未授权等问题,关于这块其实早就有很多很好用的插件了,例如Tsojanscan、APIKIT等等,强烈推荐师傅们使用(稍微有点跑题hhh)

6.来点凭据 来点token 来点AK/SK
在前文,我们介绍了要如何提取接口uri,如何寻找后端地址和初级路径,对于攻击者来说,其实已经可以开始测试了,但这也还不是JS中的全部。相信很多师傅也能看到很多案例,比如从JS中提取AK/SK然后梭哈云资产的。这也正是我们接下来要讨论的点,我们还需要从JS里提取哪些敏感信息。
首先我们很容易想到一些要素,比如手机号、邮箱、身份证,因为很多提取JS并分析的场景都是那种后台登录点,提取这些信息,我们可能可以找到潜藏的用户名,或者我们可以通过这些信息去进行密码重置等操作,再或者结合裤子进一步查找信息。在部分场景下,甚至只能通过邮箱或手机号作为用户名登录。因此搜集这些实际上是为了后续的密码喷洒、爆破相关攻击路线服务的。给出提取正则(python)如下:
#邮箱匹配`` ``matches = re.findall(r'[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}', line)`` ``#手机号匹配`` ``matches = re.findall(r'(?<!\d)(13\d{9}|14[579]\d{8}|15[^4\D]\d{8}|166\d{8}|17[^49\D]\d{8}|18\d{9}|19[189]\d{8})(?!\d)', line)`` ``#身份证匹配`` ``matches = re.findall(r'\b\d{17}[\dXx]|\b\d{14}\d{1}|\b\d{17}[\dXx]', line)
顺这个思路想,我们在密码喷洒、爆破流程中常见验证码以及一些IP限制,在部分情况下,XFF伪造一个内部IP会是绕过方法,如果目标的鉴权机制检测到特定内部IP就直接放行,那就更爽了,因此我们还可以写个正则匹配IP:
#ip匹配`` ``matches = re.findall(r'\d+\.\d+\.\d+\.\d+', line)
继续思考,既然能找到账号,我们有没有可能找到密码呢?嗯,这个难度就大了,一般只能通过js中变量的赋值来找到蛛丝马迹,我们可以用正则匹配
Password =`` ``Password :
这样的关键字,从而找到一些密码的蛛丝马迹,通过这种思路,其实也可以去找AK/SK,两个相关的正则如下:
#密码匹配小正则`` ``matches = re.findall(r'(?:^|_)((?:username|password|key|auv)_)\s*[:=><]*\s*["\']([^"\']+)["\']', line)`` ``#匹配信息大正则`` ``matches = re.findall(r'(?i)((access_key|username|user|jwtkey|jwt_key|AESKEY|AES_KEY|appsecret|app_secret|access_token|password|admin_pass|admin_user|algolia_admin_key|algolia_api_key|alias_pass|alicloud_access_key|amazon_secret_access_key|amazonaws|ansible_vault_password|phone|aos_key|api_key|api_key_secret|api_key_sid|api_secret|api\.googlemaps\s+AIza|apidocs|apikey|apiSecret|app_debug|app_id|app_key|app_log_level|app_secret|appkey|appkeysecret|application_key|appspot|auth_token|authorizationToken|authsecret|aws_access|aws_access_key_id|aws_bucket|aws_key|aws_secret|aws_secret_key|aws_token|AWSSecretKey|b2_app_key|bashrc\ password|bintray_apikey|bintray_gpg_password|bintray_key|bintraykey|bluemix_api_key|bluemix_pass|browserstack_access_key|bucket_password|bucketeer_aws_access_key_id|bucketeer_aws_secret_access_key|built_branch_deploy_key|bx_password|cache_driver|cache_s3_secret_key|cattle_access_key|cattle_secret_key|certificate_password|ci_deploy_password|client_secret|client_zpk_secret_key|clojars_password|cloud_api_key|cloud_watch_aws_access_key|cloudant_password|cloudflare_api_key|cloudflare_auth_key|cloudinary_api_secret|cloudinary_name|codecov_token|config|conn\.login|connectionstring|consumer_key|consumer_secret|credentials|cypress_record_key|database_password|database_schema_test|datadog_api_key|datadog_app_key|db_password|db_server|db_username|dbpasswd|dbpassword|dbuser|deploy_password|digitalocean_ssh_key_body|digitalocean_ssh_key_ids|docker_hub_password|docker_key|docker_pass|docker_passwd|docker_password|dockerhub_password|dockerhubpassword|dot-files|dotfiles|droplet_travis_password|dynamoaccesskeyid|dynamosecretaccesskey|elastica_host|elastica_port|elasticsearch_password|encryption_key|encryption_password|env\.heroku_api_key|env\.sonatype_password|eureka\.awssecretkey)\s*[:=><]{1,2}\s*[\"\']{0,1}([0-9a-zA-Z\-_=+/]{8,64})[\"\']{0,1})', line)
如果你有其它想匹配的关键字,自己往上述正则中添加即可。
前面我们提了一嘴AK/SK,从JS中找这玩意真是典中典了,尤其是那些把文件传储存桶里的功能点,要尤其注意其是否把AK/SK硬编码在前端了。SK一般是无特征无规律可循的,不过AK是有规律的,AK的前四位一般是固定的,不同的云厂商则不同,详情可以参考这篇文章:
https://wiki.teamssix.com/cloudservice/more/
依据这篇文章,我们实际上可以写出一些提取AK的正则,并且SK一般都会和AK写在一起,因此只要在JS中定位到AK,那么离找到SK也不远了,正则如下:
#常见的云AK匹配`` ``matches = re.findall(r'''(['"]\s*(?:GOOG[\w\W]{10,30}|AZ[A-Za-z0-9]{34,40}|AKID[A-Za-z0-9]{13,20}|AKIA[A-Za-z0-9]{16}|IBM[A-Za-z0-9]{10,40}|OCID[A-Za-z0-9]{10,40}|LTAI[A-Za-z0-9]{12,20}|AK[\w\W]{10,62}|AK[A-Za-z0-9]{10,40}|AK[A-Za-z0-9]{10,40}|UC[A-Za-z0-9]{10,40}|QY[A-Za-z0-9]{10,40}|KS3[A-Za-z0-9]{10,40}|LTC[A-Za-z0-9]{10,60}|YD[A-Za-z0-9]{10,60}|CTC[A-Za-z0-9]{10,60}|YYT[A-Za-z0-9]{10,60}|YY[A-Za-z0-9]{10,40}|CI[A-Za-z0-9]{10,40}|gcore[A-Za-z0-9]{10,30})\s*['"])''', line)`` ``#谷歌云 AccessKey ID匹配`` ``matches = re.findall(r'\bAIza[0-9A-Za-z_\-]{35}\b', line)`` ``#金山云 AccessKey ID匹配`` ``matches = re.findall(r'\bAKLT[a-zA-Z0-9-_]{16,28}\b', line)`` ``#火山引擎 AccessKey ID匹配`` ``matches = re.findall(r'\b(?:AKLT|AKTP)[a-zA-Z0-9]{35,50}\b', line)`` ``#亚马逊 AccessKey ID匹配`` ``matches = re.findall(r'["''](?:A3T[A-Z0-9]|AKIA|AGPA|AIDA|AROA|AIPA|ANPA|ANVA|ASIA)[A-Z0-9]{16}["'']', line)`` ``#京东云 AccessKey ID匹配`` ``matches = re.findall(r'\bJDC_[0-9A-Z]{25,40}\b', line)
再接下来,我们还能想到什么呢?前面我们提到了一些明文的鉴权因素,比如用户名和密码。然而实际情况下我们经常遇到别的一些鉴权因素,比如JWT,再比如形如”Basic 一串base6
编码”这样格式的鉴权凭据,常见于请求头中。开发者有没有可能在测试前端的时候,在前端放了一些测试用户的鉴权凭据,上线后忘记删除呢?当然也是有可能的,笔者就遇到过这样的情况:
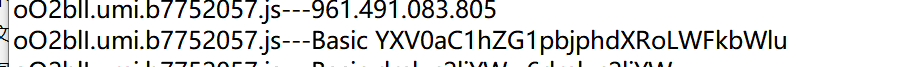
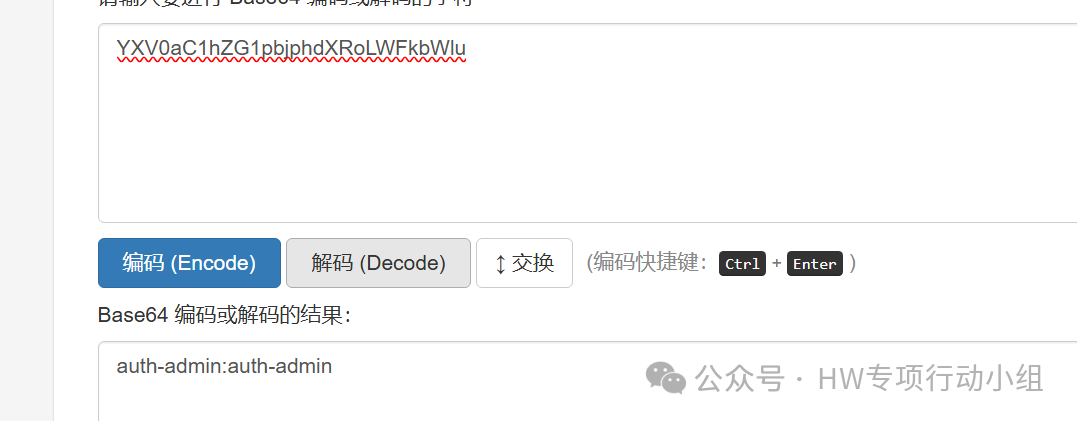
这里也给出几个相关正则:
#JWT Token匹配`` ``matches = re.findall(r'eyJ[A-Za-z0-9_/+\-]{10,}={0,2}\.[A-Za-z0-9_/+\-\\]{15,}={0,2}\.[A-Za-z0-9_/+\-\\]{10,}={0,2}', line)`` ``#PRIVATE KEY匹配`` ``matches = re.findall(r'-----\s*?BEGIN[ A-Z0-9_-]*?PRIVATE KEY\s*?-----[a-zA-Z0-9\/\n\r=+]*-----\s*?END[ A-Z0-9_-]*? PRIVATE KEY\s*?-----', line)`` ``#Auth Token匹配`` ``matches = re.findall(r'["''\[]*[Aa]uthorization["''\]]*\s*[:=]\s*[''"]?\b(?:[Tt]oken\s+)?[a-zA-Z0-9\-_+/]{20,500}[''"]?', line)`` ``#Basic Token匹配`` ``matches = re.findall(r'\b[Bb]asic\s+[A-Za-z0-9+/]{18,}={0,2}\b', line)`` ``#Bearer Token匹配`` ``matches = re.findall(r'\b[Bb]earer\s+[a-zA-Z0-9\-=._+/\\]{20,500}\b', line)
然后说到上述的Token和key,还有一种情况相信各位师傅也经常见到,那就是硬编码在JS里的钉钉、飞书、企微、微信小程序/公众号之类的key和token,能搞到这些东西并且能利用也大概率能搞个高危,下面也给出部分规则:
#slack webhook匹配`` ``matches = re.findall(r'\bhttps://hooks.slack.com/services/[a-zA-Z0-9\-_]{6,12}/[a-zA-Z0-9\-_]{6,12}/[a-zA-Z0-9\-_]{15,24}\b', line)`` ``#飞书 webhook匹配`` ``matches = re.findall(r'\bhttps://open.feishu.cn/open-apis/bot/v2/hook/[a-z0-9\-]{25,50}\b', line)`` ``#钉钉 webhook匹配`` ``matches = re.findall(r'\bhttps://oapi.dingtalk.com/robot/send\?access_token=[a-z0-9]{50,80}\b', line)`` ``#企业微信 webhook匹配`` ``matches = re.findall(r'\bhttps://qyapi.weixin.qq.com/cgi-bin/webhook/send\?key=[a-zA-Z0-9\-]{25,50}\b', line)`` ``#微信公众号匹配`` ``matches = re.findall(r'["''](gh_[a-z0-9]{11,13})["'']', line)`` ``#企业微信 corpid匹配`` ``matches = re.findall(r'["''](ww[a-z0-9]{15,18})["'']', line)`` ``#微信 公众号/小程序 APPID匹配`` ``matches = re.findall(r'["''](wx[a-z0-9]{15,18})["'']', line)`` ``#腾讯云 API网关 APPKEY匹配`` ``matches = re.findall(r'\bAPID[a-zA-Z0-9]{32,42}\b', line)
除此之外还有一些乱七八糟的应用的Token:
#grafana service account token匹配1`` ``matches = re.findall(r'\b(?:VUE|APP|REACT)_[A-Z_0-9]{1,15}_(?:KEY|PASS|PASSWORD|TOKEN|APIKEY)[\'"]*[:=]"(?:[A-Za-z0-9_\-]{15,50}|[a-z0-9/+]{50,100}==?)"', line)`` ``#grafana service account token匹配2`` ``matches = re.findall(r'\bglsa_[A-Za-z0-9]{32}_[A-Fa-f0-9]{8}\b', line)`` ``#grafana cloud api token匹配`` ``matches = re.findall(r'\bglc_[A-Za-z0-9\-_+/]{32,200}={0,2}\b', line)`` ``#grafana api key匹配`` ``matches = re.findall(r'\beyJrIjoi[a-zA-Z0-9\-_+/]{50,100}={0,2}\b', line)`` ``#Github Token匹配`` ``matches = re.findall(r'\b((?:ghp|gho|ghu|ghs|ghr|github_pat)_[a-zA-Z0-9_]{36,255})\b', line)`` ``#Gitlab V2 Token匹配`` ``matches = re.findall(r'\b(glpat-[a-zA-Z0-9\-=_]{20,22})\b', line)
把上面的所有正则综合起来,就能得到一个比较好用的敏感信息提取脚本了,我本地高了一些测试数据,提取结果像是下面这样:
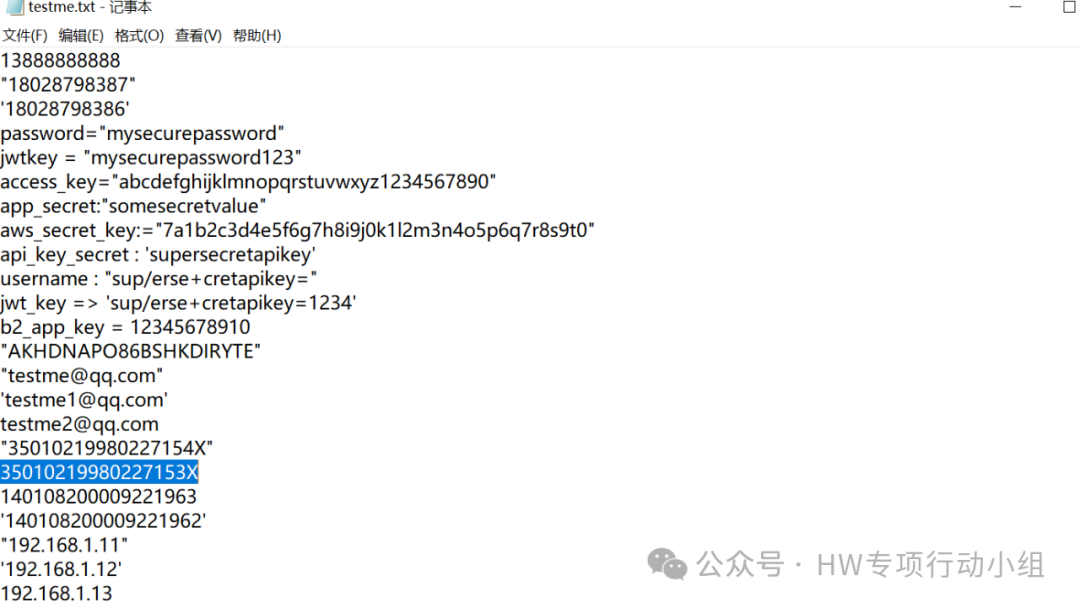
通过上述正则,我们就能搜集到JS中常见的敏感信息。当然你也可以把上述正则改写成适用于HaE等插件的版本,就可以解放双手了。不过由于本文的模式是把JS下载回本地然后用脚本跑,所以我还是自己搞了一个脚本本地提取敏感信息。上面有很多规则是从一个开源工具里扒出来魔改的,想半天想不起来是哪款工具了。
7.注释一点都不重要 //并不是
在我脑海里对一个案例印象很深刻,虽然想不起具体是哪篇文章,大意是一个师傅在测试过程中,从JS的注释里找到一个接口从而打开突破口(没记错的话应该是一个能执行SQL Server语句的执行点)。
并且有些时候,开发者可能也会把默认账号密码等敏感信息以注释的形式写在某个文件中,所以提取注释还是有可能找到一些敏感信息。
那么要怎从JS和HTML中提取注释呢,我写了下面这些正则:
match = re.search(r'\*/(.*)', line)`` ``matches = re.findall(r'//[^\n]*', line)`` ``match = re.search(r'/\*(.*)', line)`` ``matches = re.findall(r'<!--(?:.|\n)*?-->', line)
可以有效提取多种风格的注释,以下面这些数据为例:
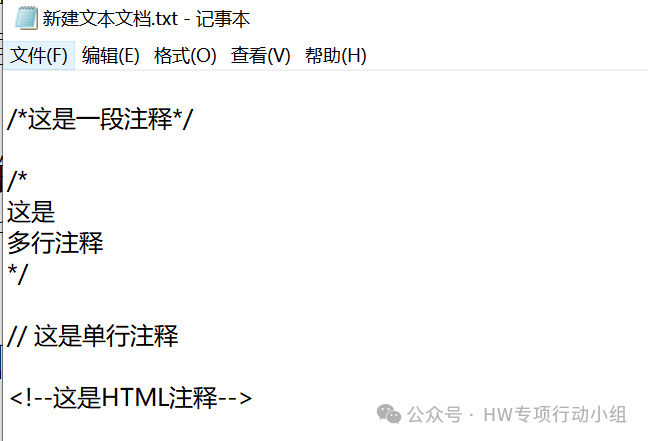
提取结果如下:
嗯,虽然格式很不好看,但是东西都提取出来了,能用,没毛病。
8.提取汉字以及可能的妙用
继续拓展一下,既然一些注释还有可能用得上的敏感信息多以中文的形式存在,那么有没有可能通过匹配所有中文,去找到一些敏感信息呢?还是以我自己的案例为例,我先是从JS中提取出一个测试手机号
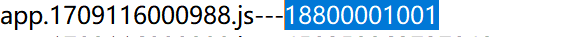
然后跟过去看前后文,找到了目标一个内部员工的名字

进一步寻找,还可以找到注册相关服务(未开放给普通用户)要求的密码规则:

(可能为后续密码爆破提供指导)
还找到了目标的一些办公地点相关的信息:

虽然这些都称不上有多敏感,也没法当作漏洞交上去,但是万一呢?很多时候我们的测试就缺了那么一点点的关键信息,就比如说上面的员工名字,万一裤子里正好有这家伙的常用密码,万一他名字的拼音就是账号呢?多关注一点细枝末节还是很有必要的。这里就不给正则和脚本了,因为我正在写(
9.一些奇思妙想
上面我们搜集这些信息大多都是用的正则表达式,还是比较死板的,总有一些乱七八糟的我们考虑不到的情况。刚好前段时间大模型炒的沸沸扬扬,有没有可能找一堆JS文件,丢给大模型训练,让帮我们提取出JS中的各种信息呢?目前小队的范师傅就在投喂相关的安全大模型。
10.结语
综上,我们就基本解决了“要从JS中提取什么”的问题,下一篇文章应该会讲讲我们可以用什么方法去获取接口的参数,毕竟上面我们只是找到存活的接口,但是后续测试还得找到参数呢,除了从JS里寻找参数以及参数FUZZ之外,还是有一些有趣的方法,师傅们点点关注不迷路哦。
11.附录
本文提到的一些工具的下载地址如下:
https://github.com/rtcatc/Packer-Fuzzer
https://github.com/momosecurity/FindSomething
https://github.com/ScriptKid-Beta/Unexpected_information
https://github.com/gh0stkey/HaE
https://github.com/Tsojan/TsojanScan
https://github.com/API-Security/APIKit
小脚本内容如下,想要改成提取其他信息的脚本,只需要替换或者增加新的正则即可:
import json``import re``import requests``import sys``import os`` ``fileurl=sys.argv[1]`` ``filemkdir=fileurl.split('_')[0]``if not os.path.exists(filemkdir):` `os.makedirs(filemkdir)`` `` ``#get path + 路径名称``paths=[]``for dirpath, dirnames, filenames in os.walk('./'+filemkdir):` `for file in filenames:` `with open("./"+filemkdir+"/"+file,"r",encoding='gb18030', errors='ignore') as f2:` `try:` `line=f2.readlines()` `for line in line:` `line=line.strip('\n').strip('\t')` `#print(line)` `p = re.findall('''(['"]\/[^][^>< \)\(\{\}]*?['"])''',line)` `#print(p)` `if p != None:` `#print(p)` `for path in p:` `path=path.replace(':"',"").replace('"',"")` `paths.append(file+"---"+path)` `except Exception as e:` `print(e)`` `` ``for var in sorted(set(paths)):` `with open (fileurl+'_path.txt',"a+",encoding='gb18030', errors='ignore') as paths:` `paths.write(var+'\n')
关于我们:
感谢各位大佬们关注,后续会坚持更新渗透漏洞思路分享、安全测试、好用工具分享以及挖掘SRC思路等文章,同时会组织不定期抽奖,希望能得到各位的关注与支持。
CNVD、EDU及SRC赏金,攻防演练资源分享(免杀,溯源,钓鱼等),各种新鲜好用工具,最新poc定期更新,以及一些好东西(还在学怎么挖通用漏洞吗快来扫码加入)
网络安全学习路线&学习资源

网络安全的知识多而杂,怎么科学合理安排?
下面给大家总结了一套适用于网安零基础的学习路线,应届生和转行人员都适用,学完保底6k!就算你底子差,如果能趁着网安良好的发展势头不断学习,日后跳槽大厂、拿到百万年薪也不是不可能!
初级网工
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
【“脚本小子”成长进阶资源领取】
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
零基础入门,建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习; 搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime; ·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完; ·用Python编写漏洞的exp,然后写一个简单的网络爬虫; ·PHP基本语法学习并书写一个简单的博客系统; 熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选); ·了解Bootstrap的布局或者CSS。
8、超级网工
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,贴一个大概的路线。感兴趣的童鞋可以研究一下,不懂得地方可以【点这里】加我耗油,跟我学习交流一下。
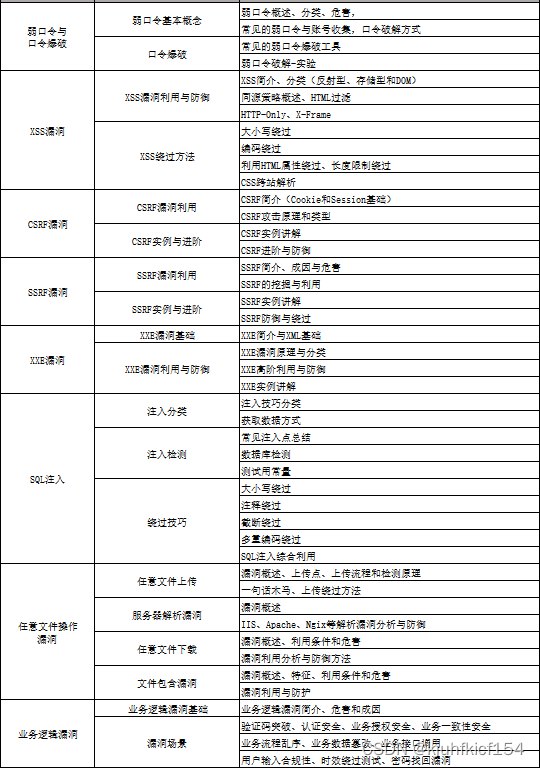
网络安全工程师企业级学习路线
如图片过大被平台压缩导致看不清的话,可以【点这里】加我耗油发给你,大家也可以一起学习交流一下。
一些我自己买的、其他平台白嫖不到的视频教程:

需要的话可以扫描下方卡片加我耗油发给你(都是无偿分享的),大家也可以一起学习交流一下。

结语
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失!!!











![YOLOv11[基础]】热力图可视化实践② | 视频版 | 输入为视频文件](https://i-blog.csdnimg.cn/direct/c507dc942ef745b8a22a1b0c952d66fe.png)





