文章汇总
当前的问题
1)数据集风格变化。
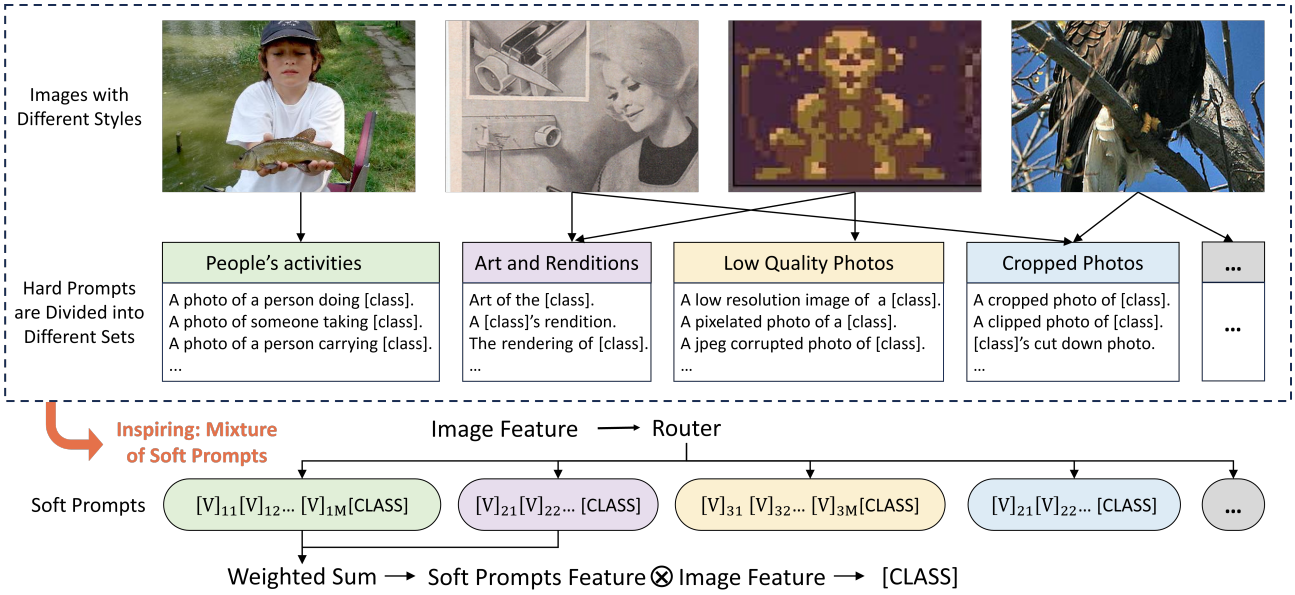
如图1所示,对于一个数据集,单个软提示可能不足以捕获数据中呈现的各种样式。同一数据集中的不同实例可能与不同的提示符兼容。因此,更**自然的做法是使用多个提示来充分表示这些变化**。
2)过拟合问题。
软提示调整不当可能导致性能甚至落后于原始VLMs的零样本能力(Radford et al ., 2021;Zhou et al ., 2022b)。这与基础类的过度训练和领域知识的灾难性遗忘有关(Zhu et al ., 2023)。
动机
通过路由器router来选择最佳硬提示。
解决办法
每个具体的内容如下,动机上图中的文字所示。
混合提示学习
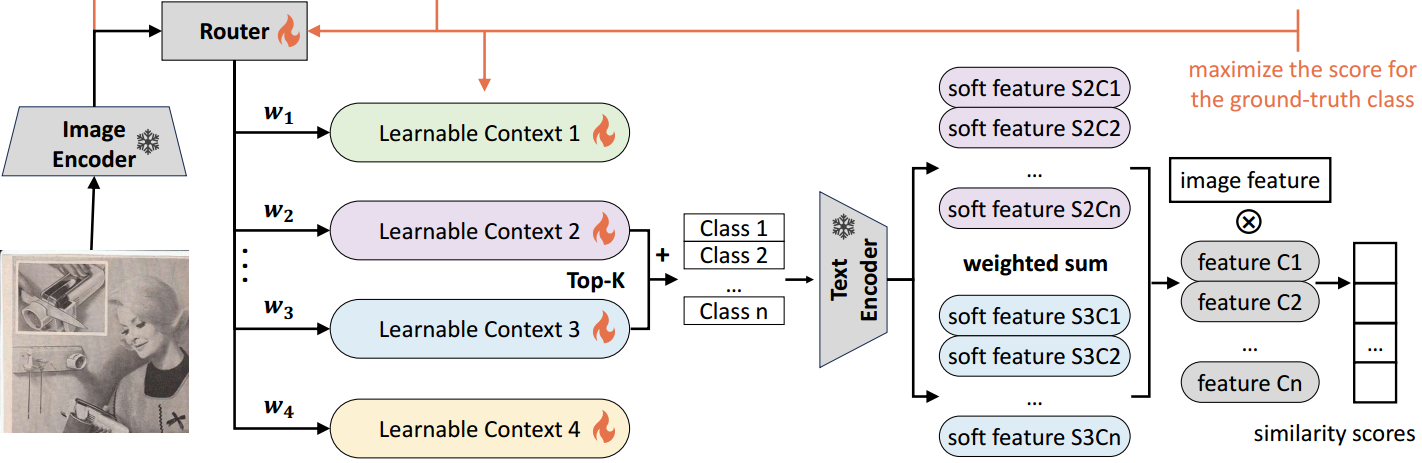
这项工作的基本思想是学会像专家一样进行提示。在LLMs中,路由器为每个输入令牌选择前 K K K个专家。类似地,我们使用路由器来选择前 K K K个上下文。然后将选择的上下文与类名连接,并由文本编码器进行编码,以获得几组类特征:
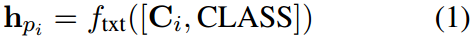
然后对这些特征进行加权和平均,以产生最终的类特征集:
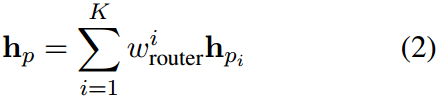
其中, w i w_i wi是分配给每个提示特征的权重。交叉熵损失被用来优化这些提示:
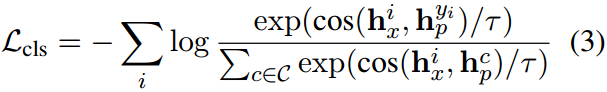
硬提示引导路由
给定 G G G组硬提示 ( I 1 , I 2 , … , I G ) (I_1,I_2,\ldots,I_G) (I1,I2,…,IG),每个提示与每个类连接并通过CLIP文本编码器进行编码,我们获得所有类的 G G G组硬文本特征。具体来说,对于与特定 CLASS c \text{CLASS}_c CLASSc连接的硬提示符,可以使用CLIP文本编码器类似地获得相应的硬文本特征,从而得到:
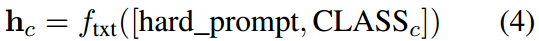
其中$ c $表示具体的类。

然后对这些硬文本特征取平均值以生成 G G G组文本特征,每个文本特征代表 G G G组中的一个。具体来说,第 G G G组的第 g g g组文本特征 h g h_g hg是通过平均该组中所有类和所有模板的硬文本特征来计算的:
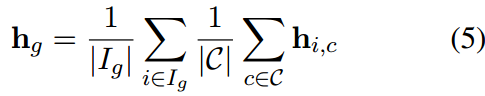
式中, C C C表示所有类的集合, h i , c h_{i,c} hi,c表示第 g g g组中 c c c类的第 i i i个硬文本特征。
计算图像特征 v v v与每组文本特征之间的余弦相似度。然后将softmax函数应用于这些相似性分数,得到硬提示引导门控分布 W h a r d W_{hard} Whard,表示为:
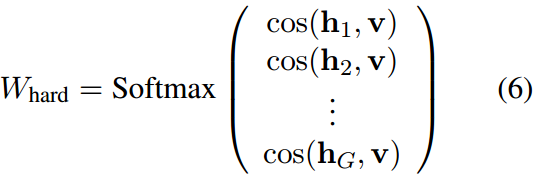
路由器的输出门控分布用 W r o u t e r W_{router} Wrouter表示。为了保证两个分布之间的一致性,采用KL散度作为约束,损失函数定义为:
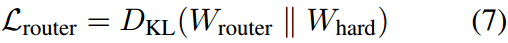
语义分组文本级监督
为了缓解过拟合问题,我们引入了语义分组文本级监督来缓解过拟合问题。
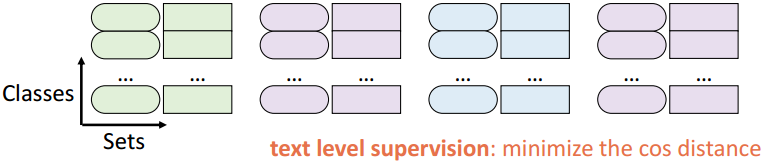
硬提示在语义上分为 G G G组 I 1 , I 2 , … , I G I_1,I_2,\dots,I_G I1,I2,…,IG。(详见A)。对于每一个可学习的软提示 t g s \textbf{t}^s_g tgs及其对应的硬提示组 I g I_g Ig,在该提示中填写的类别 y \text{y} y被归类为其所属类别 y y y的概率为:
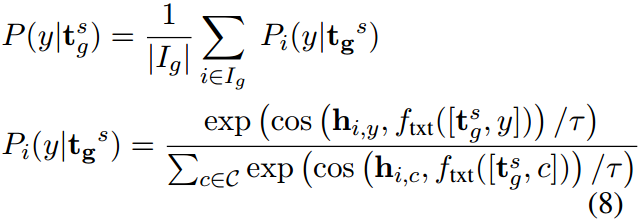
式中, P i ( y ∣ t g s ) P_i(y|\textbf{t}_g^s) Pi(y∣tgs)为应用于 y \text{y} y类的 t g s \textbf{t}_g^s tgs被分类为 I g I_g Ig应用于 y \text{y} y类中的第 i i i个硬模板的可能性, c o s ( ⋅ , ⋅ ) cos(\cdot,\cdot) cos(⋅,⋅)为余弦相似度, τ \tau τ为温度参数, C \mathcal{C} C为类集。
接下来,我们使用交叉熵损失来最小化编码的可学习软提示和编码空间中手动定义的文本提示之间的距离。损失函数可表示为:
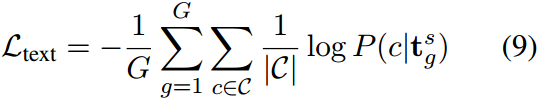
总的训练目标是
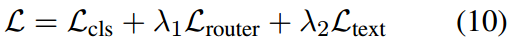
其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是平衡每个损失项重要性的权重。
摘要
随着像CLIP这样强大的预训练视觉语言模型(VLMs)的日益突出,许多研究都试图将VLMs结合起来用于下游任务。其中,提示学习已被证明是一种适应新任务的有效方法,它只需要少量的参数。然而,当前的提示学习方法面临两个挑战:第一,单个软提示难以捕获数据集中的各种风格和模式;其次,微调软提示容易过拟合。为了解决这些挑战,我们提出了一种结合路由模块的混合软提示学习方法。该模块能够捕获数据集的各种样式,并动态地为每个实例选择最合适的提示。此外,我们还引入了一种新的门通机制,以确保路由器根据提示与硬提示模板的相似性来选择提示,既保留了硬提示中的知识,又提高了选择的准确性。我们还实现了语义分组的文本级监督,使用从其组中手动设计的模板的标记嵌入初始化每个软提示,并在结果文本特征和硬提示编码文本特征之间应用对比损失。这种监督确保了来自软提示的文本特征与来自相应硬提示的文本特征保持接近,从而保留了初始知识并减少了过拟合。我们的方法已经在11个数据集上进行了验证,与现有的基线相比,在少样本学习、领域泛化和基类到新类的泛化场景方面有了明显的改进。代码可在https://anonymous.4open.science/r/mocoop-6387/README.md上获得。
1.介绍
最近,像CLIP这样的预训练视觉语言模型变得越来越突出,许多研究探索了它们在各种下游任务中的应用,如图像分类(Zhou等人,2022b)、视觉问答(VQA) (Eslami等人,2021)和跨模态生成(Crowson等人,2022)。提示学习已经成为一种有效的方法,通过优化输入到模型中的提示,显著提高了新的下游任务的性能,而不需要对整个模型进行大规模微调。
例如,以图像分类的下游任务为例,提示符本质上是一个模板,可以放置在类名之前、之后或周围。传统上,在CLIP的训练过程中使用人工设计的文本模板,指导模型将文本描述与视觉内容关联起来。这些手动设计的提示被称为硬提示。通过用可学习的连续向量代替这些固定的文本模板,提示学习更进一步。通过少量样本对这些向量进行微调,可以显著提高下游任务的性能。这些基于矢量的提示被称为软提示,以区别于硬提示。
图1:对于一个数据集,现有的硬模板可以根据它们在图像中描述的不同风格和模式(例如不同颜色块内的不同内容)划分为不同的集合。此外,一幅图像可以同时拥有多种不同的风格。传统上,只使用一个软提示来适合所有图像,但是我们使用多个软提示。每个软提示符代表一种样式,路由器选择最匹配的样式。这种方法通过考虑不同的样式,更好地弥合了视觉和文本特性之间的差距。
在这项工作中,我们重点研究了软提示学习的两个挑战。1)数据集风格变化。如图1所示,对于一个数据集,单个软提示可能不足以捕获数据中呈现的各种样式。同一数据集中的不同实例可能与不同的提示符兼容。因此,更**自然的做法是使用多个提示来充分表示这些变化。2)过拟合问题。软提示调整不当可能导致性能甚至落后于原始VLMs的零样本能力(Radford et al ., 2021;Zhou et al ., 2022b)。这与基础类的过度训练和领域知识的灾难性遗忘**有关(Zhu et al ., 2023)。
为了解决这些挑战,我们提出了一种混合软提示学习方法。这种方法包含了一个路由模块,可以选择最适合每个实例的提示。然后由文本编码器对选定的提示进行编码,以获得几组类文本特征。对这些特征进行加权和平均以产生最终的类文本特征集,然后将其与图像特征进行比较以计算相似度。从概念上讲,这个过程可以看作是为每个实例选择最兼容的样式提示,从而增强系统的适应性和性能。
对于路由器,我们还提出了硬提示引导门控损失,以确保它从文本特征与图像特征最相似的硬提示模板中选择初始化的软提示。这种机制将硬提示模板的知识提取到路由器中,并鼓励它做出更准确、更相关的选择。
此外,为了缓解过拟合问题,我们引入了语义分组的文本级监督。每个软提示对应于一组手工设计的模板(硬提示),其中每个组中的语义相对接近。我们使用每组模板中的一个的令牌嵌入作为每个软提示符的初始化。在训练过程中,文本编码器对每个软提示得到的文本特征进行约束,使其与对应的硬提示得到的文本特征保持接近。这确保了来自手动文本模板的初始知识被保留并集成到软提示中。
我们在11个数据集上进行了验证,主要从三个方面对方法进行了验证,分别是少样本学习、域概化和基类到新类的概化。与现有的基线相比,我们的方法得到了改进。我们还设计了烧蚀实验来验证我们方法中不同模块对性能改进的贡献。
总之,我们的贡献如下:
•我们提出了一种混合软提示学习方法,该方法包含一个路由模块,可以为每个实例选择最合适的提示。
•我们引入了硬提示引导门控损失,以确保路由器根据提示与硬提示模板的相似性来选择提示,从而提高选择准确性。
•我们实现语义分组文本级监督,以维护手动文本模板的初始知识并减轻过拟合。
•我们在11个数据集上验证了我们的方法,与现有基线相比,展示了在少样本学习、域概化和基类到新类泛化场景方面的改进。
2.相关工作
提示学习。在视觉语言模型领域,提示学习旨在更有效地弥合视觉和文本表示之间的差距。该领域的一项开创性工作是CoOp(上下文优化)模型(Zhou等人,2022b),该模型优化提示的上下文,以提高CLIP (Radford等人,2021)等模型在少样本学习场景中的性能。
研究人员还引入了视觉提示的概念(Zang et al, 2022;Khattak等人,2023),其中涉及将可学习向量附加到视觉编码器的输入,类似于文本提示。这种方法可以显著提高性能,尽管它也增加了计算需求。在本文中,我们只关注基于文本的提示。在未来,我们的方法可能会被扩展到包含视觉提示。
尽管它们取得了成功,但大多数快速学习方法在分类精度和鲁棒性之间权衡,例如在领域泛化或out-of-distribution (OOD)检测中。已经开发了各种方法来使用原始手动模板中的特性来约束软提示的更新。这些方法要么直接限制梯度更新的方向,要么采用知识蒸馏的方法。其中,ProGrad (Zhu et al ., 2023)通过仅当提示的梯度与预定义提示的KL损失梯度所表示的“大方向”一致时更新提示,防止提示调优忘记VLMs中的一般知识。LASP (Bulat和Tzimiropoulos, 2022)使用分组手动模板编码特征作为监督来规范提示符的学习。KgCoOp (Yao et al ., 2023)减少了由学习提示生成的文本嵌入与手工提示生成的文本嵌入之间的差异。我们还通过将原始文本特征中的知识提取到每个专家软提示中来结合该技术。此外,我们应用门控正则化从离散文本中提取先验知识到路由器中。
PLOT (Chen等)首先探索了学习多个综合提示来描述类别的不同特征,使用最佳传输来对齐视觉和文本特征。该方法通过应用两阶段优化策略改进了少样本识别任务,与传统的提示学习方法相比,在各种数据集上表现出优越的性能。我们以另一种方式,使用多个提示来捕获数据集中的不同风格,并学习以稀疏混合专家的方式来提示。
混合专家。混合专家(MoE)框架(Zhou et al ., 2022c;Masoudnia和Ebrahimpour, 2014)最初是在几十年前引入的,它为人工智能带来了重大进步,特别是在基于transformer的大型语言模型中出现了稀疏门控制的MoE (Sukhbaatar等人,2024;Liu et al, 2024)。该框架允许模型的不同部分(称为专家)专门从事各种任务,只针对给定输入聘请相关专家,以在利用专业知识的同时保持计算效率。MoE的一个主要问题是有效地平衡不同专家模型之间的负载,因为负载分配不良可能导致效率低下和模型性能不稳定(Masoudnia和Ebrahimpour, 2014)。
3.方法
3.1概述
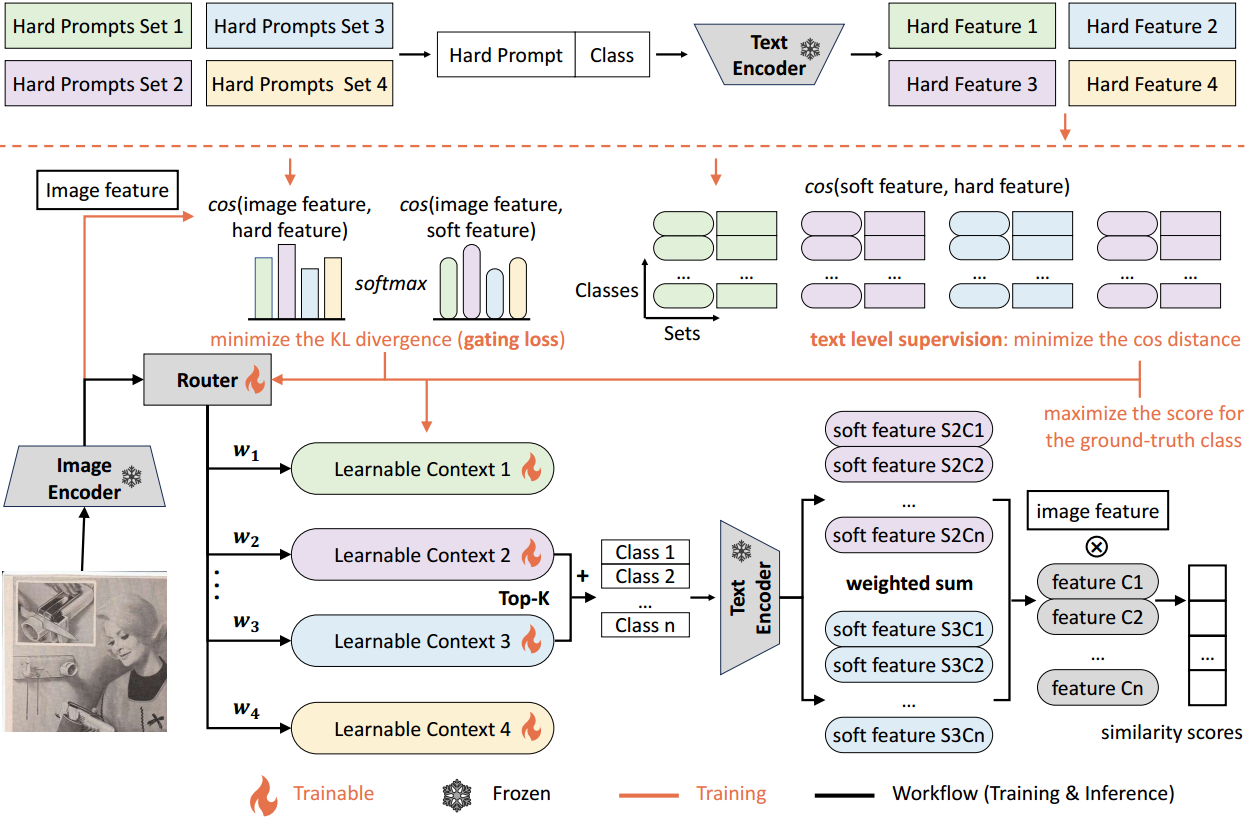
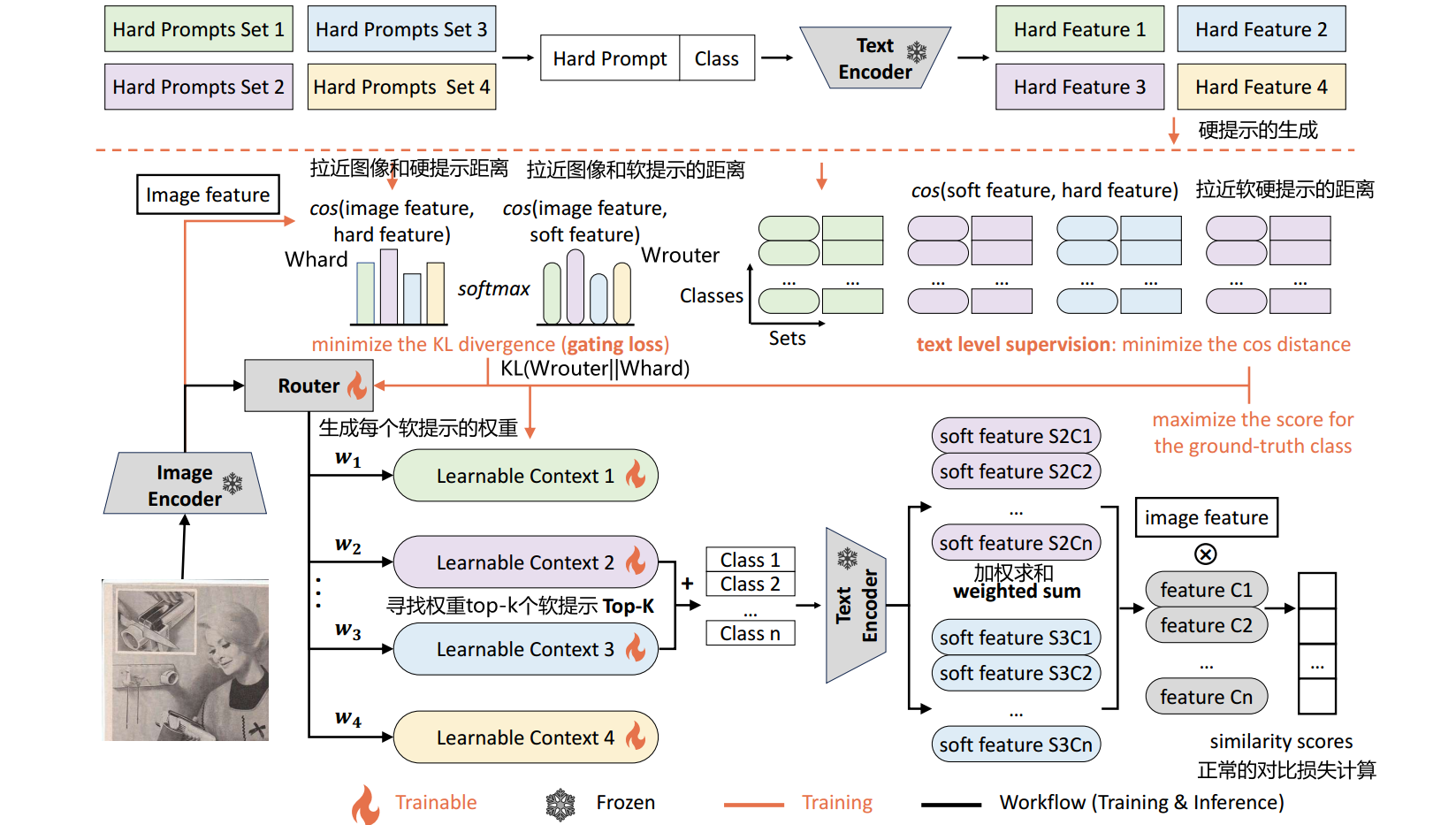
图2:MoCoOp概述。橙色线表示额外的训练流,而黑色线表示训练和推理共享。在推理过程中,选择两个具有最高概率的软提示,并将其与用于文本编码的可用类组合在一起。得到的文本特征被平均并用于分类。在训练过程中,引入硬提示引导路由和语义分组文本级监督,分别对路由和软提示进行监督。在我们的实验中,我们设 k = 2 k = 2 k=2。
如图2所示,在推理过程中,首先由CLIP图像编码器对图像进行处理以获得图像特征。然后将该特性路由到选择具有最高概率的 k k k个软提示。这些选定的提示与可用的类连接起来,并输入到CLIP文本编码器中,从而产生 k k k组类文本特性。然后,这 k k k个集合被路由器的门通分布(在softmax层之后)加权平均,以产生一组类文本特征。
最后的特征集与图像特征进行比较,产生分类逻辑。通过这种方式,一次只激活$ k $个软提示,使推理成本与使用单个提示相当。在训练过程中,梯度流分为三部分。首先,我们将一个交叉熵损失应用到最终的分类概率与基础真值标签。其次,对于路由器,我们计算每个硬提示模板集中的图像特征和文本特征之间的相似度(使用集合中所有类和所有模板的平均特征)。这些相似性可以作为参考分布。然后,使用KL散度目标函数将路由器的门控分布与该参考分布对齐。最后,对于软提示,我们使用另一个交叉熵损失来确保每个类的文本特征来自每个软提示都与相关硬提示的相应类的特征密切匹配。
3.2 Preliminary of CoOp
在这里,我们简要介绍CoOp (Zhou et al ., 2022b),这是VLM提示学习的开创性工作。
符号:
首先,这里有一些符号用于提示学习VLM。
• x x x:输入图像
• p p p:文本提示
• f i m g f_{img} fimg: CLIP图像编码器
• f t x t f_{txt} ftxt: CLIP文本编码器
• h x = f i m g ( x ) h_x = f_{img}(x) hx=fimg(x): 编码图像特征
• h p = f t x t ( p ) h_p =f_{txt}(p) hp=ftxt(p): 编码文本特征
• C C C: 上下文向量(可学习参数)
提示表示。
文本提示符 p \textbf{p} p表示为一系列标记,包括可学习的上下文标记和类标记。
p = [ C , CLASS ] \textbf{p}=[\text{C},\text{CLASS}] p=[C,CLASS]
上下文令牌也可以放在类令牌之后或周围。
上下文:
•上下文是可学习向量 C = [ c 1 , c 2 , … , c M ] C=[c_1,c_2,\ldots,c_M] C=[c1,c2,…,cM],其中 c i ∈ R d , M c_i \in \mathbb{R}^d,M ci∈Rd,M为上下文令牌的个数。
•所有类共享相同的上下文 C C C,或者每个类 C C C都有自己的上下文 C c C_c Cc。
训练目标
给定一个具有图像 { x i } \{x_i\} {xi}和相应标签 { y i } \{y_i\} {yi}的数据集,目标是通过最小化交叉熵损失来找到最佳上下文向量 C C C(或针对特定类别的上下文 C c C_c Cc):
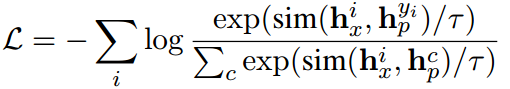
其中
• h x i = f i m g ( x i ) h^i_x = f_{img}(x_i) hxi=fimg(xi)是图像 i i i的图像特征。
• h p c = f t x t ( [ C , CLASS ] ) h_p^c =f_{txt}([\text{C},\text{CLASS}]) hpc=ftxt([C,CLASS])是类 c c c的文本特征。
• sim ( ⋅ , ⋅ ) \text{sim}(\cdot,\cdot) sim(⋅,⋅)表示相似度函数,如余弦相似度。
• τ \tau τ为温度。
优化
通过反向传播对上下文向量 C \text{C} C进行更新,以最小化损失 L \mathcal{L} L,同时保持预训练 f i m g , f t x t f_{img},f_{txt} fimg,ftxt的参数固定。
总之,CoOp包括学习文本提示的最佳上下文向量 C \text{C} C,用于合成下游任务的分类权重。这一过程使提示工程自动化,并增强了视觉语言模型(如CLIP)在各种图像识别任务中的适应性和性能。
3.3 混合提示学习
这项工作的基本思想是学会像专家一样进行提示。在LLMs中,路由器为每个输入令牌选择前$ K 个专家。类似地,我们使用路由器来选择前 个专家。类似地,我们使用路由器来选择前 个专家。类似地,我们使用路由器来选择前 K $个上下文。然后将选择的上下文与类名连接,并由文本编码器进行编码,以获得几组类特征:
然后对这些特征进行加权和平均,以产生最终的类特征集:
其中, w i w_i wi是分配给每个提示特征的权重。交叉熵损失被用来优化这些提示:
3.4 硬提示引导路由
给定 G G G组硬提示 ( I 1 , I 2 , … , I G ) (I_1,I_2,\ldots,I_G) (I1,I2,…,IG),每个提示与每个类连接并通过CLIP文本编码器进行编码,我们获得所有类的 G G G组硬文本特征。具体来说,对于与特定 CLASS c \text{CLASS}_c CLASSc连接的硬提示符,可以使用CLIP文本编码器类似地获得相应的硬文本特征,从而得到:
其中$ c $表示具体的类。
然后对这些硬文本特征取平均值以生成 G G G组文本特征,每个文本特征代表 G G G组中的一个。具体来说,第 G G G组的第 g g g组文本特征 h g h_g hg是通过平均该组中所有类和所有模板的硬文本特征来计算的:
式中, C C C表示所有类的集合, h i , c h_{i,c} hi,c表示第 g g g组中 c c c类的第 i i i个硬文本特征。
计算图像特征 v v v与每组文本特征之间的余弦相似度。然后将softmax函数应用于这些相似性分数,得到硬提示引导门控分布 W h a r d W_{hard} Whard,表示为:
路由器的输出门控分布用$ W_{router} $表示。为了保证两个分布之间的一致性,采用KL散度作为约束,损失函数定义为:
3.5 语义分组文本级监督
为了缓解过拟合问题,我们引入了语义分组文本级监督来缓解过拟合问题。
硬提示在语义上分为 G G G组 I 1 , I 2 , … , I G I_1,I_2,\dots,I_G I1,I2,…,IG。(详见A)。对于每一个可学习的软提示 t g s \textbf{t}^s_g tgs及其对应的硬提示组 I g I_g Ig,在该提示中填写的类别 y \text{y} y被归类为其所属类别 y y y的概率为:
式中, P i ( y ∣ t g s ) P_i(y|\textbf{t}_g^s) Pi(y∣tgs)为应用于 y \text{y} y类的 t g s \textbf{t}_g^s tgs被分类为 I g I_g Ig应用于 y \text{y} y类中的第 i i i个硬模板的可能性, c o s ( ⋅ , ⋅ ) cos(\cdot,\cdot) cos(⋅,⋅)为余弦相似度, τ \tau τ为温度参数, C \mathcal{C} C为类集。
接下来,我们使用交叉熵损失来最小化编码的可学习软提示和编码空间中手动定义的文本提示之间的距离。损失函数可表示为:
总的训练目标是
其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是平衡每个损失项重要性的权重。
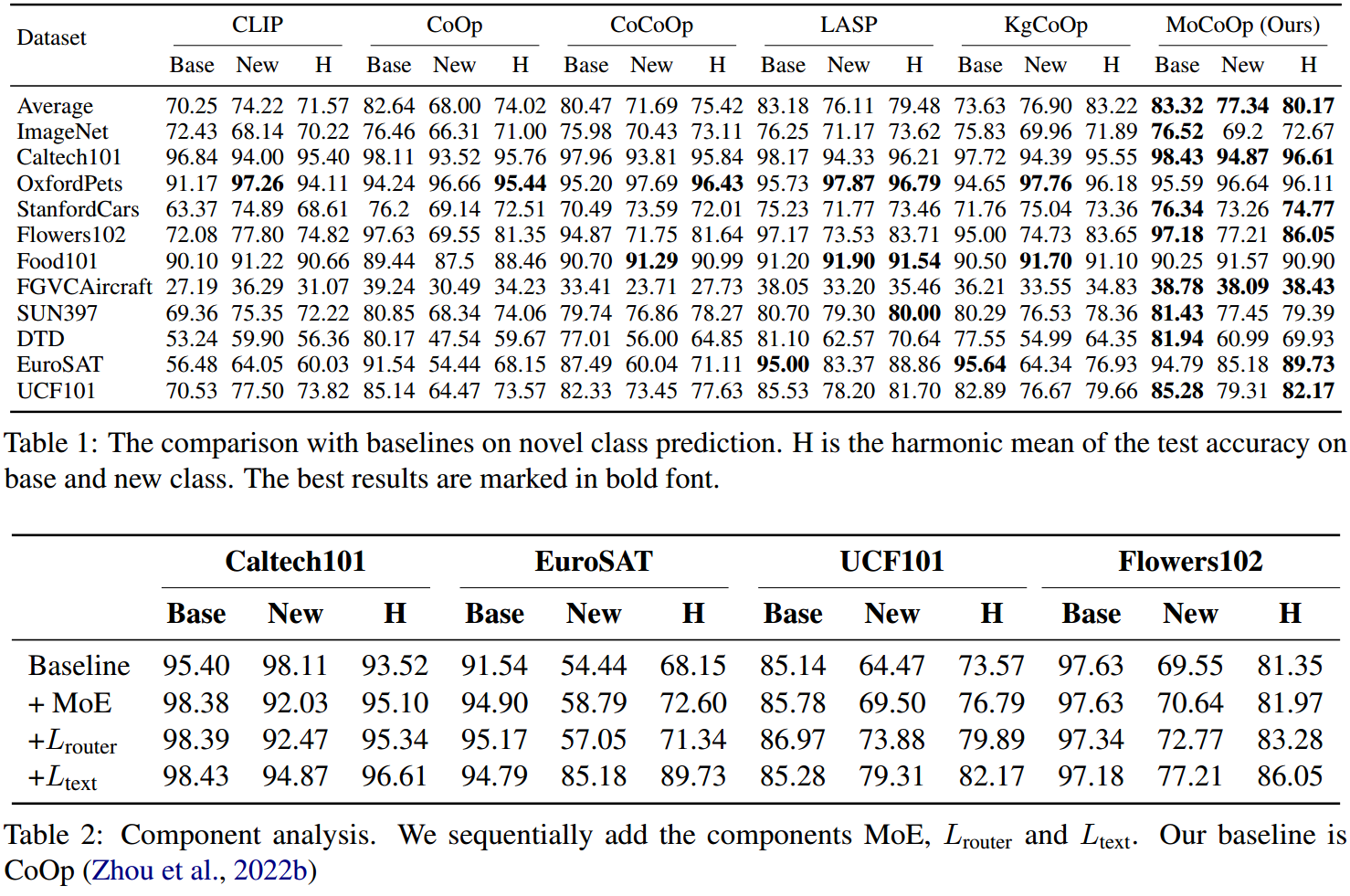
4.实验
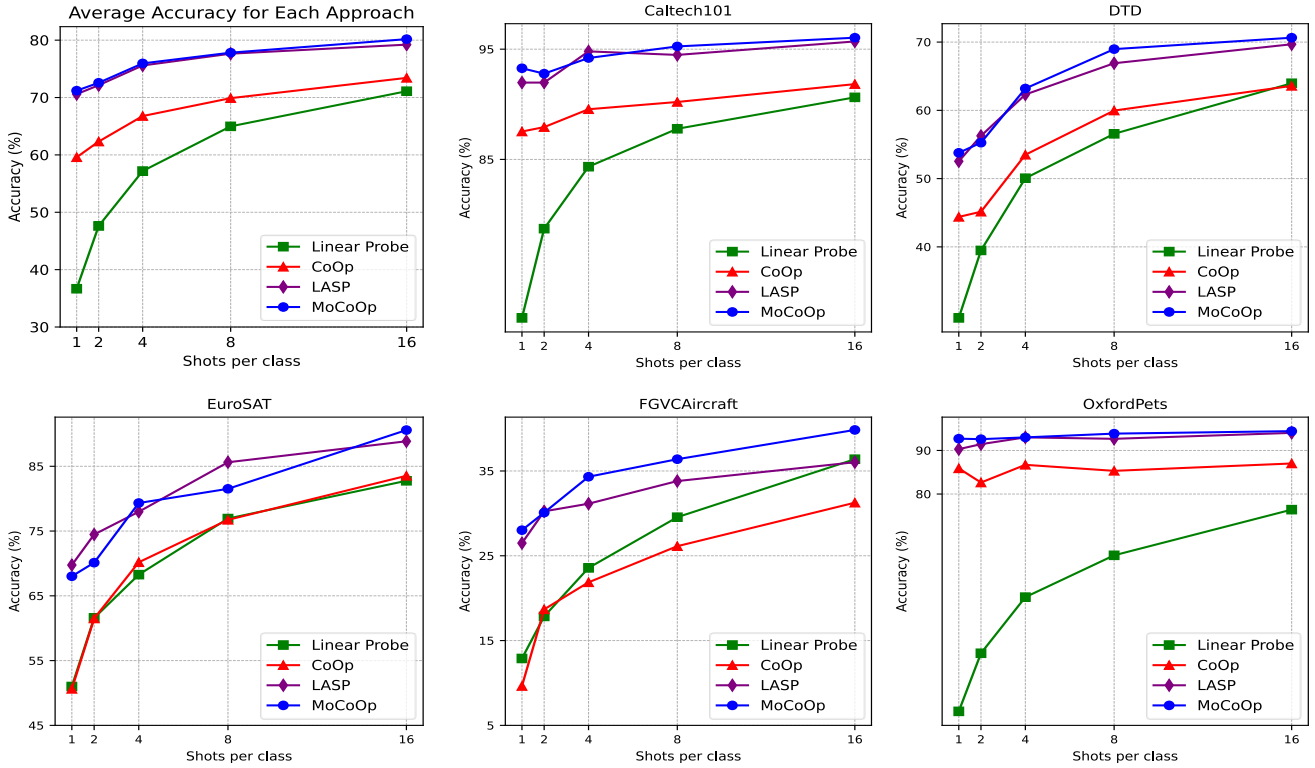
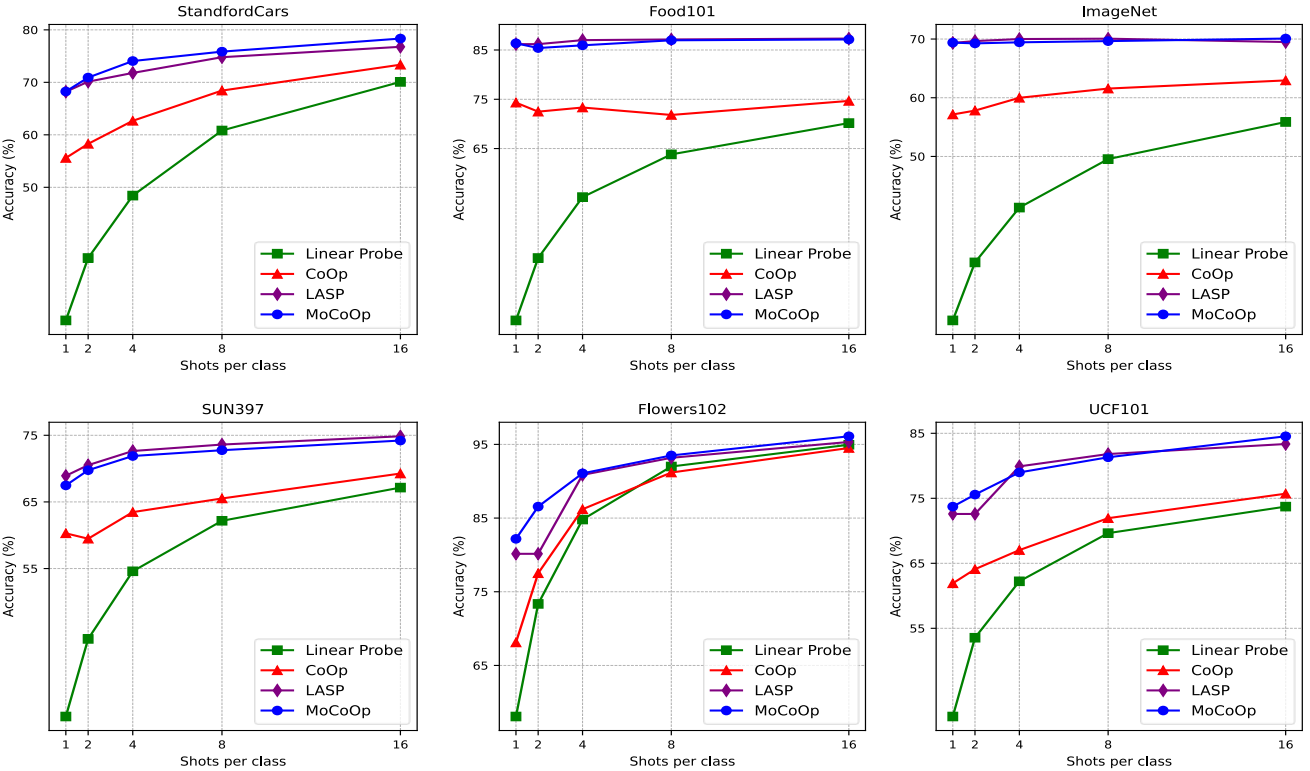
图3:在11个数据集上的少样本学习结果。我们绘制了1、2、4、8、16个样本的结果。可以看出,在大多数数据集上,我们的MoCoOp方法一致且显著地优于CoOp、LASP和线性探测方法。这在左上角显示的平均准确度中很明显。对于LASP (Bulat和Tzimiropoulos, 2022),我们使用我们的复制结果。
5.结论
在这项工作中,我们为视觉语言模型引入了一种新的混合快速学习方法,解决了数据集风格变化和过拟合等关键挑战。我们的方法使用路由模块为每个实例动态选择最合适的提示,增强了适应性和性能。我们还提出了一个硬提示引导门控损失和语义分组文本级监督,这有助于保持初始知识和减轻过拟合。我们的方法在少量学习、领域泛化和从基础到新泛化场景中展示了跨多个数据集的显著改进。未来的工作可以探索扩展这种方法,以包括视觉提示或实例条件上下文,以进一步增强。另一个方向是使用ChatGPT生成和分组硬提示模板。
6.局限性
虽然我们的MoCoOp展示了跨各种任务的改进,但有两个限制。首先,尽管软提示的稀疏门控,但与单一提示方法相比,训练成本和内存使用仍然很高。在资源有限的环境中,这可能是一个约束,特别是在处理大规模数据集时。其次,模板需要根据其语义进行手动分组,这可能会引入可能影响模型性能的人为偏见。为了提高效率和准确性,未来可能需要开发自动分组算法。
参考资料
论文下载(arxiv)
https://arxiv.org/abs/2409.12011

代码地址
https://anonymous.4open.science/r/mocoop-6387/README.md