一、模型结构
1.1 模型思路
ResNet-RS是一种改进的ResNet架构,它在2021年由谷歌大脑和UC Berkeley的研究者们提出。ResNet-RS的提出基于对现有ResNet架构的深入研究,研究者们重新审视了ResNet的结构、训练方法以及缩放策略,并提出了一些改进措施。这些改进包括:- 在不改变模型结构的前提下,通过实验验证了不同的正则化方法及其组合的作用,得到了能提升性能的正则化策略。
- 提出了简单、高效的缩放策略,包括在可能发生过拟合的情况下优先缩放模型深度,以及更慢地缩放输入分辨率。
- 将上述正则化策略和缩放策略应用到ResNet中,提出了ResNet-RS系列,其性能全面超越了EfficientNet系列。
ResNet-RS 是:改进的缩放策略、改进的训练方法、ResNet-D 修改(He 等人,2018 年)和 SqueezeExcitation 模块(Hu 等人,2018 年)的组合。
原文如下:
Revisiting ResNets- Improved Training and Scaling Strategies.pdf
1.2 ResNet-RS模型改进
1.改进的训练过程: ResNet-RS并没有在结构上进行大幅度的修改,而是专注于训练过程的优化。例如,它采用了一系列更现代的训练技巧,如学习率调度、数据增强和正则化等。这些改进使得ResNet-RS可以在不增加大量计算成本的情况下,比经典的ResNet取得更好的性能。
2. 调整的架构比例: 论文中提出了一些结构上的调整,例如通过调整卷积层的通道数和层数比例,使得网络在更深的层次上能更有效地传递梯度,减少了梯度消失问题。
3. 正则化方法: ResNet-RS引入了多种正则化方法,如Dropout、Label Smoothing、Stochastic Depth和CutMix。这些正则化技巧有助于缓解过拟合,并提高模型的泛化能力。
4. 增强的数据增强技术: ResNet-RS使用了现代的数据增强技术,如AutoAugment和RandAugment。这些方法在训练过程中生成了更多的高质量样本,进一步提高了模型的鲁棒性。
5. 优化的训练超参数: 该模型通过使用预热学习率调度、Cosine Annealing学习率策略,以及精细调优的超参数(如批量大小和权重衰减)来优化训练过程,从而使模型更快收敛并达到更高的精度。
1.3 ResNet-RS 架构细节
1.3.1 ResNet-D架构
ResNetRS是在ResNet-D架构上面的改进,ResNet-D架构的结构如下: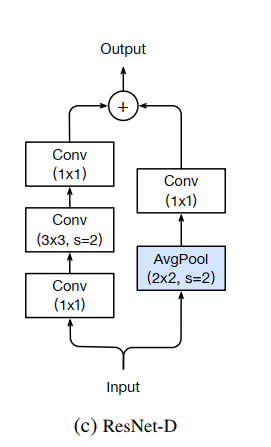
注意,残差边上多了个池化操作。
ResNet-D (He et al., 2018) 结合了对原始 ResNet 架构的以下四个调整。
- 首先,在 InceptionV3 (Szegedy et al., 2016) 中首次提出,将干中的 7×7 卷积替换为三个较小的 3×3 卷积。
- 其次,在下采样块的残差路径中切换前两个卷积的步幅大小。
- 第三,将下采样块的skip connection路径中的 stride-2 1×1 卷积替换为 stride-2 2×2 平均池化,然后是non-strided 1×1 卷积。
- 第四,去除 stride2 3×3 max pool layer,下采样发生在下一个bottleneck block的第一个 3×3 卷积中。
1.3.2 ResNet-RS架构
下图显示了使用的所有 ResNet 深度的块布局。 ResNet-50 到 ResNet-200 使用 He 等人的标准块配置。 ResNet-270 及更高版本主要扩展 c3 和 c4 中的块数,作者尝试保持它们的比例大致恒定。作者根据经验发现,在较低阶段添加块会限制过度拟合,因为较低层中的块具有显着较少的参数,即使所有块具有相同数量的 FLOP。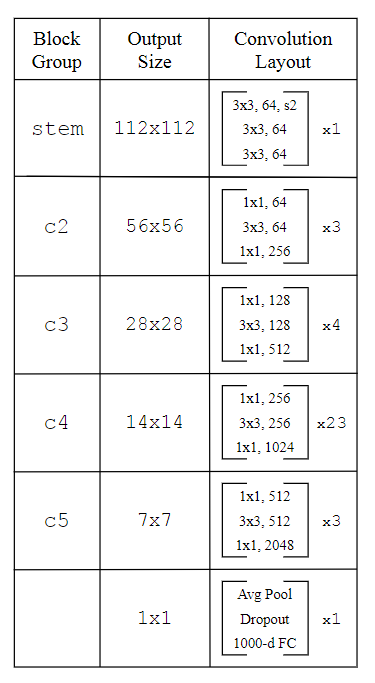
与经典ResNet相比,ResNet-RS不仅在精度上表现更好,还在计算效率方面进行了优化。在图像分类任务(如ImageNet)上,ResNet-RS能够在同样或更少的计算资源下获得比ResNet更高的精度。
二、 数据准备
2.1. 设置GPU
- 如果设备上支持GPU就使用GPU,否则使用CPU
- MacOS设备使用的是MPS
import torch
import torch.nn as nn# 设置硬件设备,如果有GPU则使用,没有则使用cpu
def get_device():if torch.cuda.is_available(): # cudadevice = "cuda"elif torch.backends.mps.is_available(): # macosdevice = "mps"else: # cpu"cpu"return torch.device(devicedevice = get_device()
device
device(type='cuda')
2.2. 导入数据
读取数据并进行查看:import os,PIL,random,pathlibdata_dir = "./data/26-data/"
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[-1] for path in data_paths]
classeNames
['malignant', 'benign']
2.3 数据可视化
2.4 划分数据集
total_datadir = './data/26-data/'# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([160, 160]), # 将输入图片resize成统一尺寸transforms.RandAugment(magnitude=10), transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
使用torch.utils.data.random_split()和torch.utils.data.DataLoader()创建训练和测试数据集:
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
查看数据集shape
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
Shape of X [N, C, H, W]: torch.Size([32, 3, 160, 160])
Shape of y: torch.Size([32]) torch.int64
三、Pytorch实现ResNet-RS模型
3.1 定义Stem层
ResNet-D型Stem块,StemBlock 作为网络的起始层,用3个卷积层对输入图像进行初步处理。class StemBlock(nn.Module):def __init__(self, channel_in, channel_out):super(StemBlock, self).__init__()channel = int(channel_out / 2) # 输出通道数的一半# 定义初始层的结构self.stem = nn.Sequential(nn.Conv2d(channel_in, channel, kernel_size=(3, 3), stride=2, padding=1, bias=False), # 第一层卷积nn.BatchNorm2d(channel), # 批归一化nn.ReLU(inplace=True), # ReLU 激活函数nn.Conv2d(channel, channel, kernel_size=(3, 3), stride=1, padding=1, bias=False), # 第二层卷积nn.BatchNorm2d(channel), # 批归一化nn.ReLU(inplace=True), # ReLU 激活函数nn.Conv2d(channel, channel_out, kernel_size=(3, 3), stride=1, padding=1, bias=False) # 第三层卷积)self.init_weights() # 初始化权重def init_weights(self):# 初始化卷积层和批归一化层的权重for _, module in self.named_modules():if isinstance(module, nn.Conv2d):nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')if isinstance(module, nn.BatchNorm2d):nn.init.ones_(module.weight) # 批归一化权重初始化为1nn.init.zeros_(module.bias) # 批归一化偏置初始化为0def forward(self, x):return self.stem(x) # 前向传播,返回经过初始层的结果3.2 定义残差单元
每个残差块包含多个卷积层,使用1x1和3x3卷积实现降维和特征提取class Block(nn.Module):def __init__(self, channel_in, channel_out, stride, identity):super(Block, self).__init__()channel = int(channel_out / 4) # 输出通道数的1/4self.se = SEBlock(channel_in) # Squeeze-and-Excitation模块# 1x1 卷积层self.bn1 = nn.BatchNorm2d(channel_in) # 批归一化self.relu1 = nn.ReLU(inplace=True) # ReLU 激活self.conv1 = nn.Conv2d(channel_in, channel, kernel_size=(1, 1), bias=False) # 1x1 卷积# 3x3 卷积层self.bn2 = nn.BatchNorm2d(channel) # 批归一化self.relu2 = nn.ReLU(inplace=True) # ReLU 激活self.conv2 = nn.Conv2d(channel, channel, kernel_size=(3, 3), stride=stride, padding=1, bias=False) # 3x3 卷积# 1x1 卷积层self.bn3 = nn.BatchNorm2d(channel) # 批归一化self.drop_out = DropPath(drop_prob=0.) # 随机丢弃部分路径self.conv3 = nn.Conv2d(channel, channel_out, kernel_size=(1, 1), bias=False) # 1x1 卷积# 跳跃连接self.identity = identity # 是否使用跳跃连接self.downsample = DownSample(channel_in, channel_out, stride) # 用于匹配特征图尺寸self.init_weights() # 初始化权重def init_weights(self):# 初始化卷积层和批归一化层的权重for _, module in self.named_modules():if isinstance(module, nn.Conv2d):nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')if isinstance(module, nn.BatchNorm2d):nn.init.ones_(module.weight) # 批归一化权重初始化为1nn.init.zeros_(module.bias) # 批归一化偏置初始化为0def forward(self, x):h = self.se(x) # 通过SEBlock进行通道加权h = self.bn1(h) # 批归一化h = self.relu1(h) # ReLU 激活h = self.conv1(h) # 1x1 卷积h = self.bn2(h) # 批归一化h = self.relu2(h) # ReLU 激活h = self.conv2(h) # 3x3 卷积h = self.bn3(h) # 批归一化h = self.drop_out(h) # 随机丢弃部分路径h = self.conv3(h) # 1x1 卷积shortcut = self.downsample(x) if self.identity else x # 跳跃连接y = h + shortcut # 残差连接return y # 返回输出
3.3 定义SEBlock单元模块
SEBlock(Squeeze-and-Excitation)模块,用于学习输入特征通道的权重。class SEBlock(nn.Module):def __init__(self, channel, ratio=0.25):super(SEBlock, self).__init__()reduced_channel = int(channel * ratio) # 降维通道数self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Sequential( # 全连接层nn.Linear(channel, reduced_channel, bias=False), # 降维nn.ReLU(inplace=True), # ReLU 激活nn.Linear(reduced_channel, channel, bias=False), # 恢复维度nn.Sigmoid() # 激活函数)def forward(self, x):b, c, _, _ = x.size() # 获取批大小和通道数y = self.avg_pool(x).view(b, c) # 平均池化y = self.fc(y).view(b, c, 1, 1) # 经过全连接层return x * y.expand_as(x) # 加权输入特征
3.4 定义DropPath模块
DropPath 是随机丢弃部分路径(stochastic depth)的实现class DropPath(nn.Module):def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_prob # 丢弃概率def forward(self, x):# 如果不丢弃或不在训练模式下,返回输入if self.drop_prob is None or self.drop_prob == 0 or not self.training:return xkeep_prob = 1 - self.drop_prob # 保留概率shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # 形状rand_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # 随机张量rand_tensor = rand_tensor.floor_() # 取整out = x.div(keep_prob) * rand_tensor # 丢弃路径的操作return out
3.5 定义DownSample
DownSample:用于在特征图尺寸变化时对跳跃连接进行匹配class DownSample(nn.Module):def __init__(self, channel_in, channel_out, stride):super(DownSample, self).__init__()if stride == 1:avg_pool = nn.Identity() # 如果 stride 为 1,不进行下采样else:avg_pool = nn.AvgPool2d(kernel_size=2, stride=stride) # 否则使用平均池化# 定义下采样的结构self.downsample = nn.Sequential(avg_pool,nn.Conv2d(channel_in, channel_out, kernel_size=(1, 1), bias=False) # 1x1 卷积)def forward(self, x):return self.downsample(x) # 前向传播
3.6 定义全局池化层
作为全局平均池化层,将空间维度池化成1x1# 作为全局平均池化层,将空间维度池化成1x1
class GlobalAvgPool2d(nn.Module):def __init__(self):super(GlobalAvgPool2d, self).__init__()def forward(self, x):# 平均池化到 1x1,并展平为 (batch_size, num_channels)return F.avg_pool2d(x, kernel_size=x.size()[2:]).view(-1, x.size(1))
3.7 搭建 ResNet-RS 网络
class ResNetRS(nn.Module):def __init__(self, output_dim):super(ResNet50rs, self).__init__()self.stem = StemBlock(channel_in=3, channel_out=64)# Block 1self.id1 = Block(channel_in=64, channel_out=256, stride=2, identity=True)self.block1 = nn.ModuleList([Block(channel_in=256, channel_out=256, stride=1, identity=False) for _ in range(2)])# Block 2self.id2 = Block(channel_in=256, channel_out=512, stride=2, identity=True)self.block2 = nn.ModuleList([Block(channel_in=512, channel_out=512, stride=1, identity=False) for _ in range(3)])# Block 3self.id3 = Block(channel_in=512, channel_out=1024, stride=2, identity=True)self.block3 = nn.ModuleList([Block(channel_in=1024, channel_out=1024, stride=1, identity=False) for _ in range(5)])# Block 4self.id4 = Block(channel_in=1024, channel_out=2048, stride=2, identity=True)self.block4 = nn.ModuleList([Block(channel_in=2048, channel_out=2048, stride=1, identity=False) for _ in range(2)])self.avg_pool = GlobalAvgPool2d() # 全局平均池化层self.dropout = nn.Dropout(p=0.25)self.fc = nn.Linear(2048, output_dim, bias=False)def forward(self, x):h = self.stem(x)h = self.id1(h)for block in self.block1:h = block(h)h = self.id2(h)for block in self.block2:h = block(h)h = self.id3(h)for block in self.block3:h = block(h)h = self.id4(h)for block in self.block4:h = block(h)h = self.avg_pool(h)h = self.dropout(h)h = torch.relu(h)h = self.fc(h)y = torch.log_softmax(h, dim=-1)return y
3.8 查看模型摘要
======================================================================
Layer (type:depth-idx) Param #
======================================================================
ResNet50rs --
├─StemBlock: 1-1 --
│ └─Sequential: 2-1 --
│ │ └─Conv2d: 3-1 864
│ │ └─BatchNorm2d: 3-2 64
│ │ └─ReLU: 3-3 --
│ │ └─Conv2d: 3-4 9,216
│ │ └─BatchNorm2d: 3-5 64
│ │ └─ReLU: 3-6 --
│ │ └─Conv2d: 3-7 18,432
├─Block: 1-2 --
│ └─SEBlock: 2-2 --
│ │ └─AdaptiveAvgPool2d: 3-8 --
│ │ └─Sequential: 3-9 2,048
│ └─BatchNorm2d: 2-3 128
│ └─ReLU: 2-4 --
│ └─Conv2d: 2-5 4,096
│ └─BatchNorm2d: 2-6 128
│ └─ReLU: 2-7 --
│ └─Conv2d: 2-8 36,864
│ └─BatchNorm2d: 2-9 128
│ └─DropPath: 2-10 --
│ └─Conv2d: 2-11 16,384
│ └─DownSample: 2-12 --
│ │ └─Sequential: 3-10 16,384
├─ModuleList: 1-3 --
│ └─Block: 2-13 --
│ │ └─SEBlock: 3-11 32,768
│ │ └─BatchNorm2d: 3-12 512
│ │ └─ReLU: 3-13 --
│ │ └─Conv2d: 3-14 16,384
│ │ └─BatchNorm2d: 3-15 128
│ │ └─ReLU: 3-16 --
│ │ └─Conv2d: 3-17 36,864
│ │ └─BatchNorm2d: 3-18 128
│ │ └─DropPath: 3-19 --
│ │ └─Conv2d: 3-20 16,384
│ │ └─DownSample: 3-21 65,536
│ └─Block: 2-14 --
│ │ └─SEBlock: 3-22 32,768
│ │ └─BatchNorm2d: 3-23 512
│ │ └─ReLU: 3-24 --
│ │ └─Conv2d: 3-25 16,384
│ │ └─BatchNorm2d: 3-26 128
│ │ └─ReLU: 3-27 --
│ │ └─Conv2d: 3-28 36,864
│ │ └─BatchNorm2d: 3-29 128
│ │ └─DropPath: 3-30 --
│ │ └─Conv2d: 3-31 16,384
│ │ └─DownSample: 3-32 65,536
├─Block: 1-4 --
│ └─SEBlock: 2-15 --
│ │ └─AdaptiveAvgPool2d: 3-33 --
│ │ └─Sequential: 3-34 32,768
│ └─BatchNorm2d: 2-16 512
│ └─ReLU: 2-17 --
│ └─Conv2d: 2-18 32,768
│ └─BatchNorm2d: 2-19 256
│ └─ReLU: 2-20 --
│ └─Conv2d: 2-21 147,456
│ └─BatchNorm2d: 2-22 256
│ └─DropPath: 2-23 --
│ └─Conv2d: 2-24 65,536
│ └─DownSample: 2-25 --
│ │ └─Sequential: 3-35 131,072
├─ModuleList: 1-5 --
│ └─Block: 2-26 --
│ │ └─SEBlock: 3-36 131,072
│ │ └─BatchNorm2d: 3-37 1,024
│ │ └─ReLU: 3-38 --
│ │ └─Conv2d: 3-39 65,536
│ │ └─BatchNorm2d: 3-40 256
│ │ └─ReLU: 3-41 --
│ │ └─Conv2d: 3-42 147,456
│ │ └─BatchNorm2d: 3-43 256
│ │ └─DropPath: 3-44 --
│ │ └─Conv2d: 3-45 65,536
│ │ └─DownSample: 3-46 262,144
│ └─Block: 2-27 --
│ │ └─SEBlock: 3-47 131,072
│ │ └─BatchNorm2d: 3-48 1,024
│ │ └─ReLU: 3-49 --
│ │ └─Conv2d: 3-50 65,536
│ │ └─BatchNorm2d: 3-51 256
│ │ └─ReLU: 3-52 --
│ │ └─Conv2d: 3-53 147,456
│ │ └─BatchNorm2d: 3-54 256
│ │ └─DropPath: 3-55 --
│ │ └─Conv2d: 3-56 65,536
│ │ └─DownSample: 3-57 262,144
│ └─Block: 2-28 --
│ │ └─SEBlock: 3-58 131,072
│ │ └─BatchNorm2d: 3-59 1,024
│ │ └─ReLU: 3-60 --
│ │ └─Conv2d: 3-61 65,536
│ │ └─BatchNorm2d: 3-62 256
│ │ └─ReLU: 3-63 --
│ │ └─Conv2d: 3-64 147,456
│ │ └─BatchNorm2d: 3-65 256
│ │ └─DropPath: 3-66 --
│ │ └─Conv2d: 3-67 65,536
│ │ └─DownSample: 3-68 262,144
├─Block: 1-6 --
│ └─SEBlock: 2-29 --
│ │ └─AdaptiveAvgPool2d: 3-69 --
│ │ └─Sequential: 3-70 131,072
│ └─BatchNorm2d: 2-30 1,024
│ └─ReLU: 2-31 --
│ └─Conv2d: 2-32 131,072
│ └─BatchNorm2d: 2-33 512
│ └─ReLU: 2-34 --
│ └─Conv2d: 2-35 589,824
│ └─BatchNorm2d: 2-36 512
│ └─DropPath: 2-37 --
│ └─Conv2d: 2-38 262,144
│ └─DownSample: 2-39 --
│ │ └─Sequential: 3-71 524,288
├─ModuleList: 1-7 --
│ └─Block: 2-40 --
│ │ └─SEBlock: 3-72 524,288
│ │ └─BatchNorm2d: 3-73 2,048
│ │ └─ReLU: 3-74 --
│ │ └─Conv2d: 3-75 262,144
│ │ └─BatchNorm2d: 3-76 512
│ │ └─ReLU: 3-77 --
│ │ └─Conv2d: 3-78 589,824
│ │ └─BatchNorm2d: 3-79 512
│ │ └─DropPath: 3-80 --
│ │ └─Conv2d: 3-81 262,144
│ │ └─DownSample: 3-82 1,048,576
│ └─Block: 2-41 --
│ │ └─SEBlock: 3-83 524,288
│ │ └─BatchNorm2d: 3-84 2,048
│ │ └─ReLU: 3-85 --
│ │ └─Conv2d: 3-86 262,144
│ │ └─BatchNorm2d: 3-87 512
│ │ └─ReLU: 3-88 --
│ │ └─Conv2d: 3-89 589,824
│ │ └─BatchNorm2d: 3-90 512
│ │ └─DropPath: 3-91 --
│ │ └─Conv2d: 3-92 262,144
│ │ └─DownSample: 3-93 1,048,576
│ └─Block: 2-42 --
│ │ └─SEBlock: 3-94 524,288
│ │ └─BatchNorm2d: 3-95 2,048
│ │ └─ReLU: 3-96 --
│ │ └─Conv2d: 3-97 262,144
│ │ └─BatchNorm2d: 3-98 512
│ │ └─ReLU: 3-99 --
│ │ └─Conv2d: 3-100 589,824
│ │ └─BatchNorm2d: 3-101 512
│ │ └─DropPath: 3-102 --
│ │ └─Conv2d: 3-103 262,144
│ │ └─DownSample: 3-104 1,048,576
│ └─Block: 2-43 --
│ │ └─SEBlock: 3-105 524,288
│ │ └─BatchNorm2d: 3-106 2,048
│ │ └─ReLU: 3-107 --
│ │ └─Conv2d: 3-108 262,144
│ │ └─BatchNorm2d: 3-109 512
│ │ └─ReLU: 3-110 --
│ │ └─Conv2d: 3-111 589,824
│ │ └─BatchNorm2d: 3-112 512
│ │ └─DropPath: 3-113 --
│ │ └─Conv2d: 3-114 262,144
│ │ └─DownSample: 3-115 1,048,576
│ └─Block: 2-44 --
│ │ └─SEBlock: 3-116 524,288
│ │ └─BatchNorm2d: 3-117 2,048
│ │ └─ReLU: 3-118 --
│ │ └─Conv2d: 3-119 262,144
│ │ └─BatchNorm2d: 3-120 512
│ │ └─ReLU: 3-121 --
│ │ └─Conv2d: 3-122 589,824
│ │ └─BatchNorm2d: 3-123 512
│ │ └─DropPath: 3-124 --
│ │ └─Conv2d: 3-125 262,144
│ │ └─DownSample: 3-126 1,048,576
├─Block: 1-8 --
│ └─SEBlock: 2-45 --
│ │ └─AdaptiveAvgPool2d: 3-127 --
│ │ └─Sequential: 3-128 524,288
│ └─BatchNorm2d: 2-46 2,048
│ └─ReLU: 2-47 --
│ └─Conv2d: 2-48 524,288
│ └─BatchNorm2d: 2-49 1,024
│ └─ReLU: 2-50 --
│ └─Conv2d: 2-51 2,359,296
│ └─BatchNorm2d: 2-52 1,024
│ └─DropPath: 2-53 --
│ └─Conv2d: 2-54 1,048,576
│ └─DownSample: 2-55 --
│ │ └─Sequential: 3-129 2,097,152
├─ModuleList: 1-9 --
│ └─Block: 2-56 --
│ │ └─SEBlock: 3-130 2,097,152
│ │ └─BatchNorm2d: 3-131 4,096
│ │ └─ReLU: 3-132 --
│ │ └─Conv2d: 3-133 1,048,576
│ │ └─BatchNorm2d: 3-134 1,024
│ │ └─ReLU: 3-135 --
│ │ └─Conv2d: 3-136 2,359,296
│ │ └─BatchNorm2d: 3-137 1,024
│ │ └─DropPath: 3-138 --
│ │ └─Conv2d: 3-139 1,048,576
│ │ └─DownSample: 3-140 4,194,304
│ └─Block: 2-57 --
│ │ └─SEBlock: 3-141 2,097,152
│ │ └─BatchNorm2d: 3-142 4,096
│ │ └─ReLU: 3-143 --
│ │ └─Conv2d: 3-144 1,048,576
│ │ └─BatchNorm2d: 3-145 1,024
│ │ └─ReLU: 3-146 --
│ │ └─Conv2d: 3-147 2,359,296
│ │ └─BatchNorm2d: 3-148 1,024
│ │ └─DropPath: 3-149 --
│ │ └─Conv2d: 3-150 1,048,576
│ │ └─DownSample: 3-151 4,194,304
├─GlobalAvgPool2d: 1-10 --
├─Dropout: 1-11 --
├─Linear: 1-12 4,096
======================================================================
Total params: 46,033,248
Trainable params: 46,033,248
Non-trainable params: 0
======================================================================
四、模型训练与测试
4.1 模型训练
loss_fn = nn.NLLLoss() # 创建损失函数
learn_rate = 0.00078125 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate, momentum=0.9, weight_decay=4e-5) # 优化器epochs = 20
train_loss = []
train_acc = []test_loss = []
test_acc = []for epoch in range(epochs):# model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)# model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
Epoch: 1, Train_acc:70.3%, Train_loss:0.940, Test_acc:78.2%,Test_loss:0.606
Epoch: 2, Train_acc:73.5%, Train_loss:0.634, Test_acc:79.7%,Test_loss:0.461
Epoch: 3, Train_acc:76.6%, Train_loss:0.519, Test_acc:79.5%,Test_loss:0.464
Epoch: 4, Train_acc:78.5%, Train_loss:0.488, Test_acc:80.2%,Test_loss:0.444
Epoch: 5, Train_acc:79.8%, Train_loss:0.457, Test_acc:81.2%,Test_loss:0.435
...
Epoch:17, Train_acc:84.7%, Train_loss:0.356, Test_acc:84.5%,Test_loss:0.361
Epoch:18, Train_acc:84.2%, Train_loss:0.366, Test_acc:85.5%,Test_loss:0.335
Epoch:19, Train_acc:84.7%, Train_loss:0.351, Test_acc:85.4%,Test_loss:0.338
Epoch:20, Train_acc:85.2%, Train_loss:0.351, Test_acc:87.4%,Test_loss:0.304
Done
4.3 结果可视化
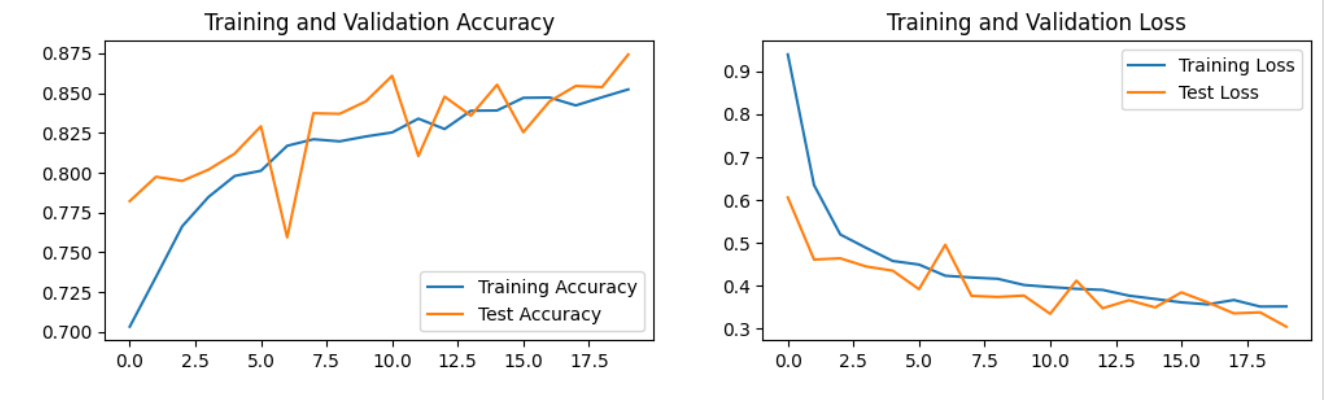
4.2 模型验证
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB') # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 预测训练集中的某张照片
predict_one_image(image_path='./data/26-data/benign/8863_idx5_x2551_y1451_class0.png', model=model, transform=train_transforms, classes=classes)
预测结果是:benign