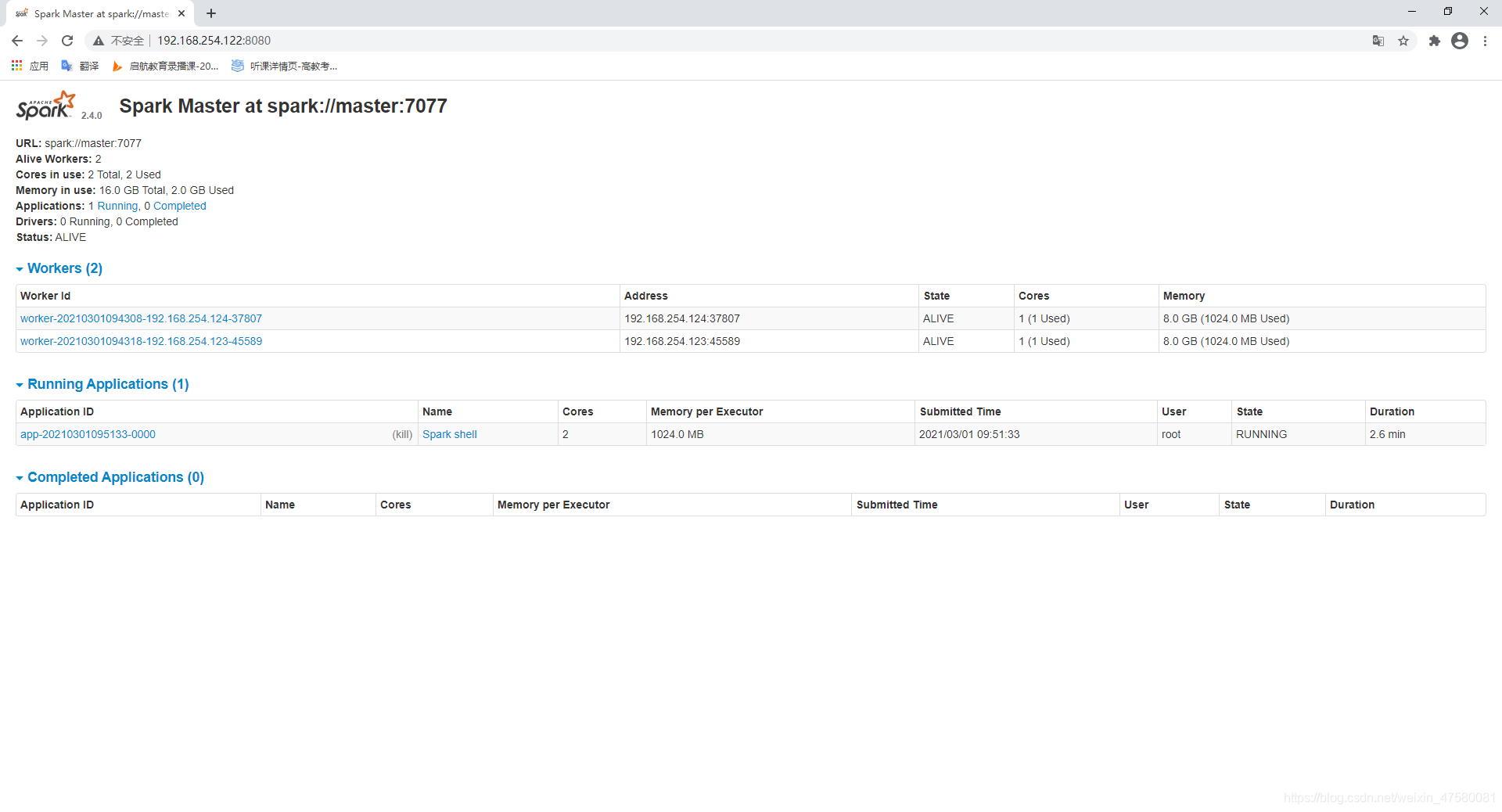
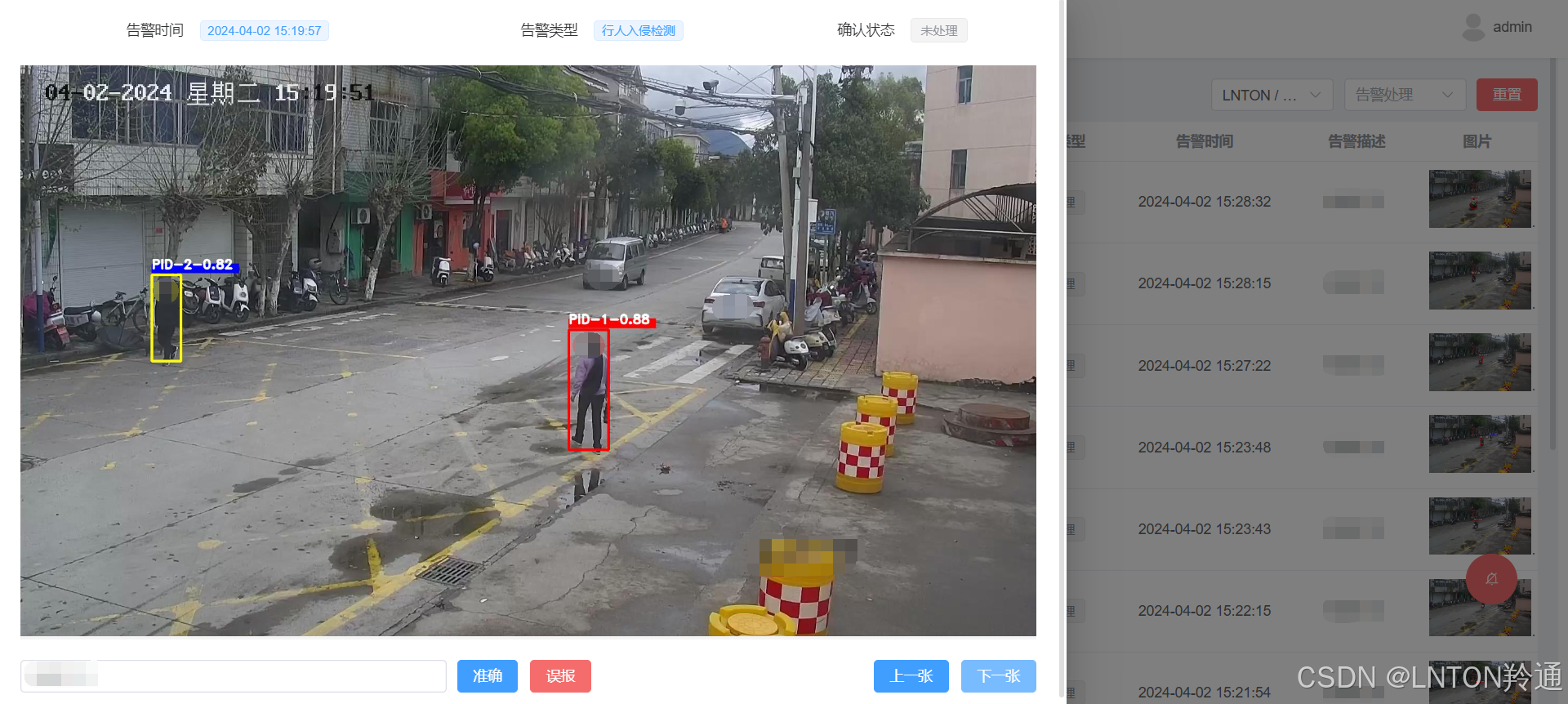
(一)可以借鉴:
1. 计算机视觉的论文,都会在第一页的右上角,放上一张好看的图!
2.bottleNet的设计——很大程度上节省了计算FLOPs开销,这是Resnet50及其更大版本都会用到的设计。

3.Resnet在detection任务中也做得很好,所以,其实很多任务都可以先用resnet作为baseline,嘻嘻!
(二)启发点:
1. 李沐讲解的时候,其实无意中告诉了我们如何真正去看这中训练迭代error曲线图:
(1)首先是这个“断崖下降点”,欸,我在第二点好像就讲到了原因,嘻嘻。
(2)然后是整个曲线,你要理解的一点是,有时候虽然error一直没有降下去,但是,只要一直在动,你想想,有时候就是因为learning_rate设置得比较大,所以一直在各个“山顶”跳来跳去,所以error可能一直比较高,但是没关系,至少它还在不断的在“找”在优化。而一旦断崖式的调整了learning rate,error能够较快的下降,就是因为它决定在“某一座”山上开始望“这座山”的脚下跑了。!!!

2. 其实残差连接的设计,在90年代就已经在用了,它就叫shortcut —— 所以,大部分工作其实前人都是做过的,想过的,但是,如果你能够做好就是好工作,原创新的设计现在已经很少很少了。
3.对了,李沐还讲到一件事情,
![]()
![]()
为什么这里比赛的点还要更底一些呢?
答:没错,就是因为

比赛,为了分数更高一些,大家都会做很多不同的设计,比如这里的不同crop,然后使用“超级大招”——merge,也就是我们经常在比赛的决胜阶段用到的融合绝技,很可惜,这并不是什么好的创新点,只能算作一个工程性的做法,merge融合本身有点像是朝着test数据集fitting,这样做的泛化性会差,不过比赛的话就只看你有多接近了。
4.对残差网络更多理论解释与分析:
(1)首先,是梯度方向传播的时候,因为多加了一个x,每次的偏导-梯度更加不容易趋近于0
——这个可以保证训练速度更快(趋于收敛)
(2)其实,一般更deeper的网络后面层如果都是identity作用,也是可以的,但是就是因为复杂度过高,导致了这样的结果很难出现。而残差连接很大程度是降低了原来的复杂度的
(3)评论区这位说的也有道理

![[RK3566-Android11] 使用SPI方式点LED灯带-JE2815/WS2812,实现呼吸/渐变/随音量变化等效果](https://i-blog.csdnimg.cn/direct/e8603e947a4c401fb2b8c0f917678676.png)