文章汇总
当前的问题
目前可学习的提示符号主要用于适应任务的单一阶段(即适应提示),容易导致过度拟合风险。
动机

提示符将分两个阶段逐步优化。在初始阶段,学习增强提示,**通过使用大量未标记的领域图像数据对齐其预测逻辑,从更大的高级CLIP教师模型中提取领域一般知识(**见图1(b)左)。在第二阶段,采用先前研究[24,25,58,64 - 66]采用的方法,通过随后与第一阶段的固定增压提示级联来优化自适应提示,以微调下游任务(见图1(b)右)。
解决办法
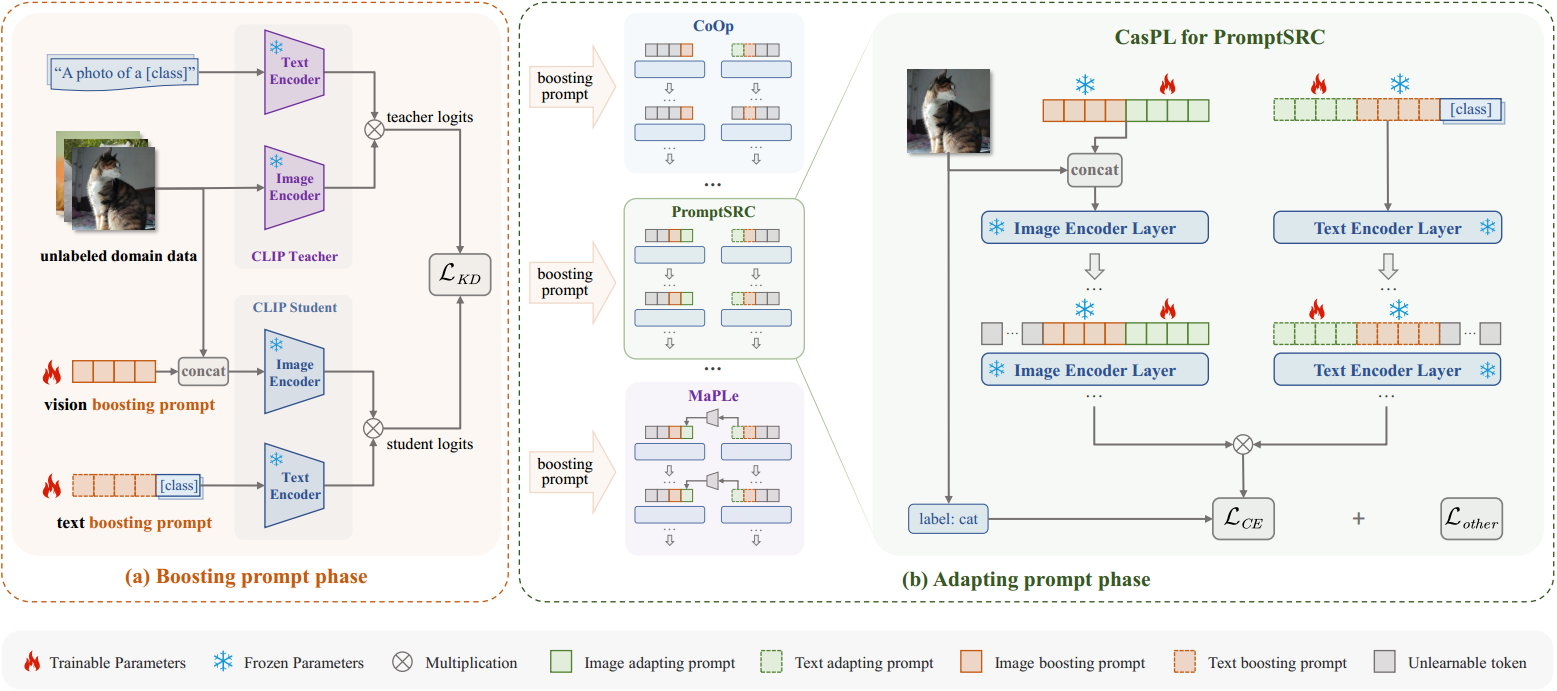
将可学习的提示分为Boosting prompt和Adapting prompt。在第一个阶段(Boosting prompt phase)通过知识蒸馏训练Boosting prompt;在第二个阶段(Adapting prompt phase)固定之前训练的Boosting prompt,此时就像CoOp那样训练Boosting prompt phase。
摘要
当应用于下游任务时,提示学习作为一种有效的方法来提高视觉语言模型(VLMs)的性能,如CLIP。然而,目前可学习的提示符号主要用于适应任务的单一阶段(即适应提示),容易导致过度拟合风险。在这项工作中,我们提出了一个新的级联提示学习(CasPL)框架,使提示学习同时服务于通用和特定的专业知识(即促进和适应提示)。具体来说,CasPL是一种新的学习范式,包括可学习提示的两个不同阶段:第一个增强提示是通过使用大量未标记的领域图像对齐其预测逻辑,从一个更大的高级CLIP教师模型中提取领域一般知识。然后,第二个适应提示与冻结的第一组串联,以微调下游任务,遵循先前研究中采用的方法。通过这种方式,CasPL可以有效地将领域通用和任务特定的表示捕获到明确不同的渐进提示组中,从而潜在地减轻目标领域中的过拟合问题。值得注意的是,CasPL作为一个即插即用的模块,可以无缝地集成到任何现有的提示学习方法中。CasPL在性能和推理速度之间实现了更好的平衡,这对于在资源受限的环境中部署较小的VLM模型特别有益。与之前最先进的方法PromptSRC相比,CasPL在11个图像分类数据集上对基本类的平均改进为1.85%,对新类的平均改进为3.44%,对谐波均值的平均改进为2.72%。代码可在https://github.com/megvii-research/CasPL公开获取。
1.介绍
图1:CasPL与以往提示学习方法的比较。(a)以前的方法采用单相提示技术来适应领域数据集。(b) CasPL引入了级联的多种提示,具有多种功能,包括提升和适应提示阶段。©以前的有或没有我们的CasPL的提示学习方法在基类到新任务上的表现。结果是11个数据集的平均值。
像CLIP这样的视觉语言模型(VLMs)[43]由于其令人印象深刻的泛化能力,最近引起了人们的极大关注。使用对比损失对图像-文本对的广泛数据集进行训练,CLIP在开放词汇设置下展示了强大的表示技能。因此,各种研究[6,12,38,57,63]利用预训练的CLIP,对其进行微调,以适应特定领域的下游任务。在这些微调方法中,提示学习[2,29,30,35]得到了突出的地位。这包括修复预训练的模型并仅调整输入提示。该方法最初用于NLP中作为文本提示来微调大型语言模型[5],该方法已被验证并扩展到视觉[20,51,52]和视觉语言[24,25,31,64,65]任务中的应用。最近的一些研究[65,66]表明,使用自适应连续提示比使用固定文本提示产生更好的结果。随后,该领域的主要研究工作[24,25,37,58,64]主要集中在开发双重视觉语言或分层提示配方,以增强CLIP模型对下游任务的适应性,并取得了令人印象深刻的表现。
尽管取得了巨大的成功,但值得注意的是,在以往的研究中,自适应提示符号主要用于适应领域任务的奇异阶段(即自适应提示,见图1(a)),因此容易导致过拟合问题。在本文中,我们引入了一种新的即插即用框架,称为级联提示学习(CasPL),它包含两组不同的可学习提示,具有多个角色:促进和适应提示。这些提示符将分两个阶段逐步优化。在初始阶段,学习增强提示,通过使用大量未标记的领域图像数据对齐其预测逻辑,从更大的高级CLIP教师模型中提取领域一般知识(见图1(b)左)。在第二阶段,采用先前研究[24,25,58,64 - 66]采用的方法,通过随后与第一阶段的固定增压提示级联来优化自适应提示,以微调下游任务(见图1(b)右)。
CasPL有几个独特的优点。首先,以无监督的方式优化提升提示,使其能够利用大量未标记的领域数据。具体来说,提升提示符使用未标记的域图像从一个更大的高级CLIP教师那里提取一般的高级知识。这些知识固有地包含一般的领域先验,这反过来又加强了原始CLIP模型在该领域的过拟合风险(图1©)。其次,CasPL是一个即插即用的框架,可以并入任何现有的提示学习方法中。增强提示以极少的参数(< 0.1%)和可忽略的推理成本增强了原始CLIP模型对目标域数据的适应性。冻结的CLIP模型加上固定的助推提示符,可以看作是一个新的“原创”CLIP模型,类似于“变量变换”的数学概念$ (\text{CLIP} \leftarrow \text{CLIP}+\text{boosting prompt}) $。因此,更新后的“原始”CLIP模型自然可以适应任何现有的提示学习方法。第三,CasPL使较小的模型(ViT-B/16)能够匹配较大的模型(ViT-L/14)的性能,同时保持高效的推理。CasPL通过将冻结的提升提示合并到较小的模型中,并使用任何提示学习方法训练自适应提示,在推理速度和性能之间实现了更好的平衡。这对于在资源受限的环境中部署模型特别有益,因为只有较小的模型是可行的。
我们的贡献可以总结如下:
-我们提出了一个新的串级提示学习框架,包括促进和适应提示阶段。据我们所知,CasPL是第一个为VLM引入具有多个阶段的级联不同提示的,这是一个用于微调VLM的全新学习范例。
-我们证明了增强提示可以从大量未标记的领域图像中提取高级教师的领域一般知识,从而获得卓越的识别性能和高效的推理。
-作为一个即插即用的框架,CasPL可以无缝集成到任何现有的提示学习方法中,参数可以忽略不计(提高提示令牌,< 0.1%),引入的额外推理成本可以忽略不计。
-与之前最先进的方法PromptSRC相比,在11个图像分类数据集上,CasPL对基本类的平均改进为1.85%,对新类的平均改进为3.44%,对谐波平均值的平均改进为2.72%。
2.相关工作
视觉语言模型。像CLIP[43]和ALIGN[19]这样的基础视觉语言模型(VLMs)近年来在各种任务中取得了重大进展[6,10,12,38,57,60,63]。一个代表性的作品是CLIP,它采用对比损失来同时优化两个编码器,使图像和文本都映射到共享嵌入空间。这个空间有助于配对图像和文本之间的视觉和语言表示的对齐。此外,VLMs的成功在很大程度上依赖于大量训练数据的可用性——例如,CLIP和ALIGN利用了4亿个和10亿个网络图像-文本对。由于广泛的训练数据,预训练的VLMs对开放词汇表表现出强大的视觉表示能力。因此,零样本迁移学习可以很容易地解决各种视觉任务。
提示学习。提示学习代表了NLP领域中一种新的训练范式[34]。这种方法通过需要输入调整而不是微调预训练模型中的所有参数来简化训练过程。微调需要原始的手动提示设计[2,11,45],当依赖基于自然语言的离散提示时,充满了挑战和不稳定性[29,62]。最近的发展绕过了这些离散提示,而不是专注于学习连续提示来取代它们的前辈[30]。受NLP中提示学习成功的启发,研究人员也证明了它在视觉任务中的适用性[20,52]。为了提高使用VLMs解决下游任务的效率,CoOp[65]在CLIP的语言分支中引入了可学习的提示,用于模型微调。MaPLe[24]和UPT[58]认识到VLMs的多模态特性,采用多模态信息交互来促进提示学习。此外,一些工作侧重于解决微调过程中的过拟合问题。CoCoOp[64]引入了一种基于视觉特征的条件提示。ProGrad[66]提出了一个提示对齐梯度,以防止提示调谐忘记一般知识。PromptSRC[25]利用正则化框架来确保模型在适应特定任务的同时保持通用性。DePT[59]将特定基础知识从特征通道解耦到一个孤立的特征空间。必须强调的是,所有当前的方法都集中在单个阶段优化可学习提示。相比之下,我们的研究采用了一种独特的方法,通过逐步研究提示符号的不同角色和阶段,从而开发了一个称为级联提示学习(CasPL)的新框架。
VLMs中的知识蒸馏。知识蒸馏的目标[17,22,32,33,47,55,61]是将教师模型的专业知识转移到学生模型中,从而提高学生模型的性能。近年来,关于利用VLMs进行知识蒸馏的研究激增[8,31,49,50,53,56]。例如,LP-CLIP[27]结合了一个可学习的线性探测层用于知识蒸馏,CLIP- kd[56]通过预训练学生CLIP模型的权重来探索各种蒸馏策略的效果,而Tiny-CLIP[53]在预训练阶段通过亲和模仿和权重继承来训练未成年学生CLIP模型。与之前的方法相比,我们第一阶段的蒸馏是为领域蒸馏而设计的,而不是大规模的预训练。此外,已经有研究将CLIP的能力提炼成传统的CNN [13,14]/ViT[7]架构,用于开放词汇对象检测[12,36,63]和语义分割[21]等任务中的知识提炼,这与本工作中使用的基于CLIP的师生范式不同。
VLMs中的无监督学习。通过采用伪标签的概念,将无监督学习纳入VLM的提示学习中有一种趋势[18,27,31,40,41]。伪标签最初是作为半监督技术开发的[28],需要一部分标记数据来训练生成这些标签的基线模型。然而,VLM的出现使得对这种标记数据的需求已经过时。UPL[18]和LaFTer[41]在提示学习中采用无监督学习为目标数据集生成伪标签。ENCLIP[40]使用由CLIP生成的迭代细化的伪标签进行无监督训练。我们的工作不是利用伪标签,而是使用未标记的领域数据,在vlm的快速学习中结合了无监督学习和知识蒸馏。
3.方法
我们开发了一种方法来调查和验证各种功能提示的潜力。我们的级联提示学习(CasPL)框架的概述如图2所示。与以前的方法不同,我们的方法明确地概述了提示的多个阶段。在接下来的章节中,我们将深入研究第3.1节中的CLIP架构和提示学习方法。随后,我们将在第3.2节中详细介绍所提出的CasPL框架。
3.1 Preliminaries
我们的方法建立在预训练的CLIP的基础上[43]。具体来说,我们使用了基于视觉transformer(ViT)[7]的CLIP模型,其特征是文本编码器和图像编码器。
在图像编码器中,将图像 I ∈ R H × W × 3 I\in \mathbb{R}^{H\times W\times 3} I∈RH×W×3划分为多个patch,然后投影到patch embedding中。这些贴片嵌入作为transformer块的输入,从最终输出得到图像特征 x ∈ R d x\in \mathbb{R}^{d} x∈Rd。另一方面,对于文本编码器,输入$ T 通常是一个固定的模板,例如““ a p h o t o o f a [ c l a s s ] ”,其中 [ c l a s s ] 表示对应的类别。该输入被标记为单词嵌入,然后将其输入到转换器块中,从而从最终输出中得到文本特征 通常是一个固定的模板,例如““a photo of a [class]”,其中[class]表示对应的类别。该输入被标记为单词嵌入,然后将其输入到转换器块中,从而从最终输出中得到文本特征 通常是一个固定的模板,例如““aphotoofa[class]”,其中[class]表示对应的类别。该输入被标记为单词嵌入,然后将其输入到转换器块中,从而从最终输出中得到文本特征y\in \mathbb{R}^{d}$。通过计算图像特征与一组文本特征之间的相似度,我们可以通过预训练的CLIP建立一个零样本分类器,得到的预测概率为:
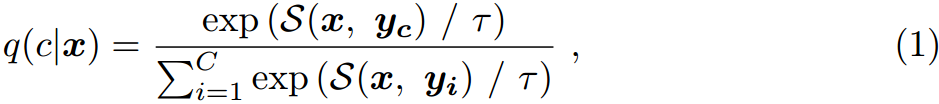
式中, S ( ⋅ , ⋅ ) \mathcal{S}(\cdot,\cdot) S(⋅,⋅)表示余弦相似度, c c c表示类别, y c y_c yc表示对应的文本特征, y i y_i yi表示第 i i i类的文本特征, c c c表示类别数, τ \tau τ为温度超参数[17]。
现有的提示学习方法[30,65]没有使用手动文本模板,而是在文本编码器的输入中附加一组可学习的提示。文本模板“a photo of a [class]”被替换为“ p 1 t p 2 t p 3 t … p n t [ c l a s s ] p^t_1 \ p^t_2 \ p^t_3 \ldots p^t_n\ [class] p1t p2t p3t…pnt [class]”,其中 p i t ( i ∈ 1 , … , N ) p^t_i (i\in 1,\dots,N) pit(i∈1,…,N)表示文本分支可学习提示, N N N表示可学习提示的个数。类似地,我们可以在补丁嵌入之后附加另一组可学习的标记,如 { I c l s , I 1 , I 2 , … , I M , p 1 v , p 2 v , … , p N v } \{I_{cls},I_1,I_2,\dots,I_M,p^v_1,p^v_2,\dots,p^v_N\} {Icls,I1,I2,…,IM,p1v,p2v,…,pNv},其中 I c l s I_{cls} Icls表示类令牌, I i ( i ∈ 1 , … , N ) I_i (i\in 1,\dots,N) Ii(i∈1,…,N)表示一个patch embedding, M M M表示patch embedding的个数, p i v ( i ∈ 1 , … , N ) p^v_i (i\in 1,\dots,N) piv(i∈1,…,N)表示视觉分支可学习标记, N N N表示可学习提示的个数。一些研究[20,24,25]证明了在图像和文本编码器中将可学习提示纳入不同深度的有效性。因此,我们在设计增强提示的格式时遵循这些实践。
3.2 级联提示学习
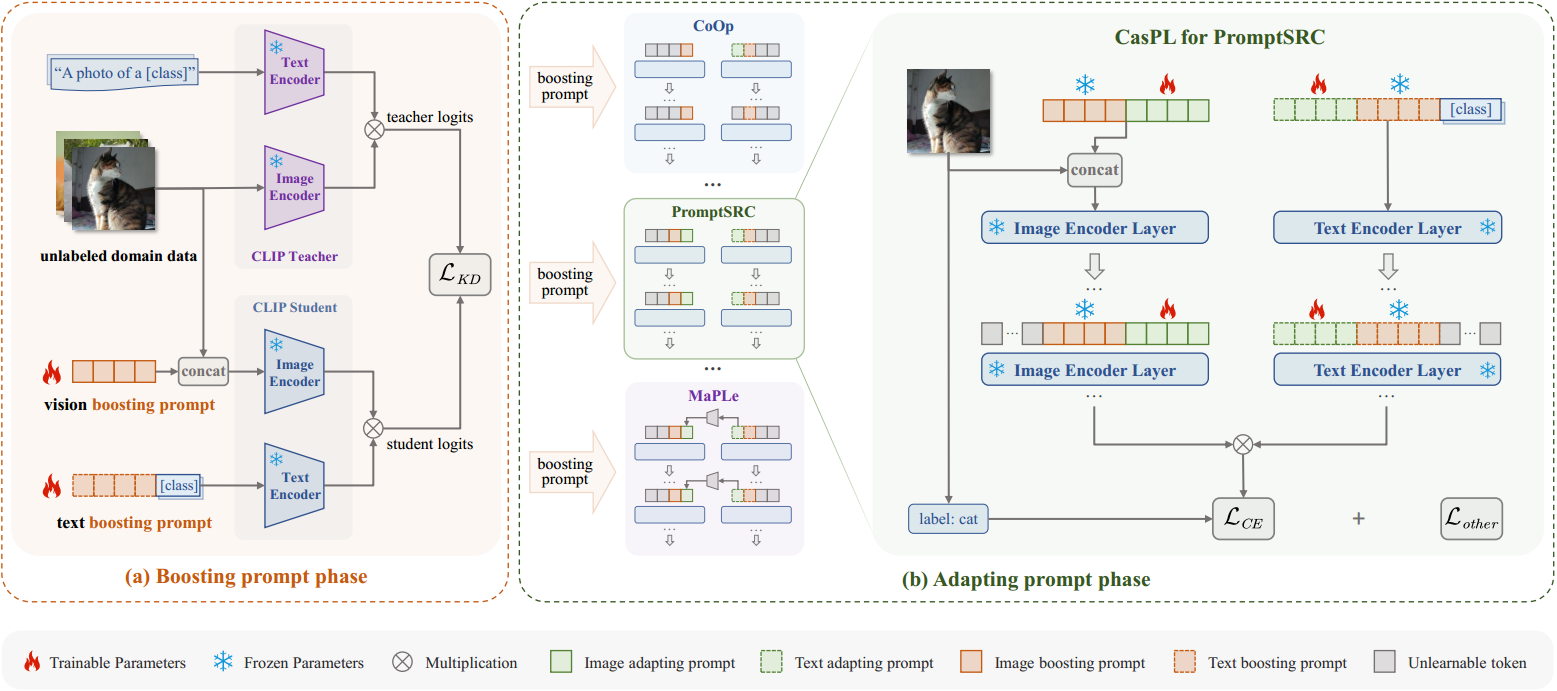
图2:我们提议的CasPL框架的概述。(a)我们利用一组增强提示,使学生CLIP模型能够从教师CLIP模型中提取一般领域知识,利用大量未标记的领域数据。(b)提升提示符可以作为插件无缝集成到现有的相关工作中。在这里,我们举例说明了与PromptSRC的集成,其中冻结的增强提示与可学习的自适应提示级联,而不改变任何损失函数。关于适应其他方法(如CoOp[65]、CoOp[64]、MaPLe[24])的更多细节见附录。
为了在每个特定领域的下游任务中寻求更好的泛化能力,我们提出了一种新的学习范式,将训练过程分为两个阶段,以研究提示符作为通用专家和特定专家的多重角色。在初始阶段,使用增强提示从较大的CLIP教师中提取高级领域一般知识,利用未标记的领域图像。在此之后,在第二阶段,自适应提示与冻结的第一组增强提示级联,以有效地处理特定于域的下游任务。因此,CasPL使较小的模型(ViT-B/16)能够像较大的模型(ViT-L/14))一样执行。
提升提示阶段
我们结合较大的CLIP教师模型,为目标CLIP学生模型生成一组提升提示。如3.1节所述,对于学生CLIP模型,我们使用“ p 1 t p 2 t p 3 t … p L t [ c l a s s ] p^t_1 \ p^t_2 \ p^t_3 \ldots p^t_L\ [class] p1t p2t p3t…pLt [class]"作为其文本编码器的输入, { I c l s , I 1 , I 2 , … , I M , p 1 v , p 2 v , … , p L v } \{I_{cls},I_1,I_2,\dots,I_M,p^v_1,p^v_2,\dots,p^v_L\} {Icls,I1,I2,…,IM,p1v,p2v,…,pLv}为图像编码器,其中棕色表示可学习的增强提示符, L L L表示增强提示令牌的长度。我们的目标是通过使用大量未标记的领域数据微调视觉和文本增强提示来改进其对领域一般知识的理解(见图2左)。学生的预测对数,记为 f s f^s fs,是通过将来自视觉和一组来自领域类别的文本的归一化特征相乘得到的。对于教师模型,我们在大多数情况下为文本编码器使用一个直接的文本模板“a photo of a [class]”(更多细节参见附录)。我们把老师预测的对数表示为 f T f^T fT。损失函数旨在通过利用大量未标记的域图像对齐它们的预测对数,损失函数可以表示为:
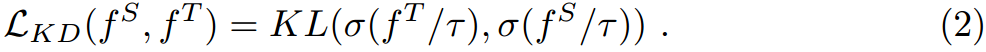
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示softmax操作, τ \tau τ为温度超参数, K L ( ⋅ , ⋅ ) KL(\cdot,\cdot) KL(⋅,⋅)表示Kullback-Leibler散度损失。整个提升提示,包括文本提示 { p 1 t p 2 t … p L t } \{p^t_1 \ p^t_2 \ldots p^t_L\} {p1t p2t…pLt}和视觉提示 { p 1 v p 2 v … p L v } \{p^v_1 \ p^v_2 \ldots p^v_L\} {p1v p2v…pLv},在第一阶段由式(2)优化。
适应提示阶段
所提出的CasPL涉及将冻结的增强提示与自适应提示级联。具体来说,从初始阶段学习到的固定助推提示是一个即插即用的提示模块,可以无缝集成到现有的任何提示学习方法中(见图2中)。当它与以前的提示学习框架合作时,文本编码器的输入扩展到“ p 1 t p 2 t p 3 t … p N t , p 1 t … p L t [ c l a s s ] p^t_1 \ p^t_2 \ p^t_3 \ldots p^t_N,p^t_1\ldots p^t_L\ [class] p1t p2t p3t…pNt,p1t…pLt [class]”。对于图像编码器,它变成 { I c l s , I 1 , I 2 , … , I M , p 1 v p 2 v … p L v , p 1 v p 2 v … p N v } \{I_{cls},I_1,I_2,\dots ,I_M,p^v_1 \ p^v_2 \ldots p^v_L,p^v_1 \ p^v_2 \ldots p^v_N\} {Icls,I1,I2,…,IM,p1v p2v…pLv,p1v p2v…pNv}。其中,棕色代表第一阶段的冻结提升提示,绿色代表该阶段的可学习适应提示。在这一阶段,我们的目标是像以前一样,在不改变现有提示学习框架的任何损失函数的情况下,通过对标记(少样本)图像的监督来学习自适应提示(见右图2)。
4.实验
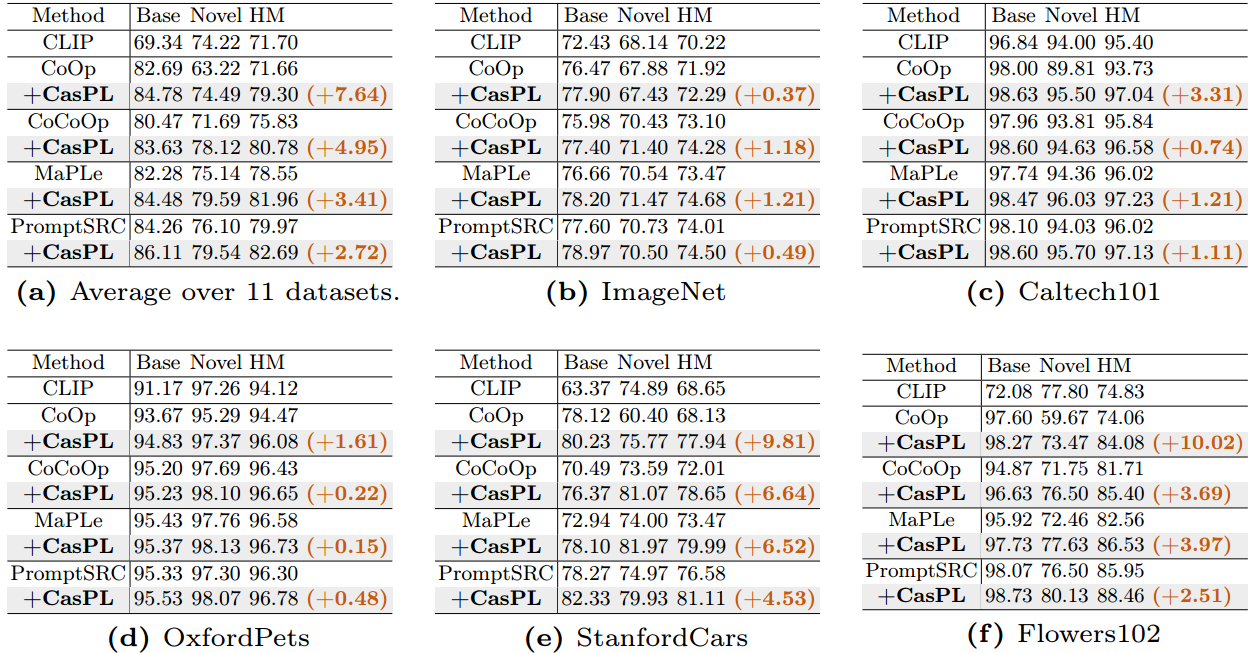
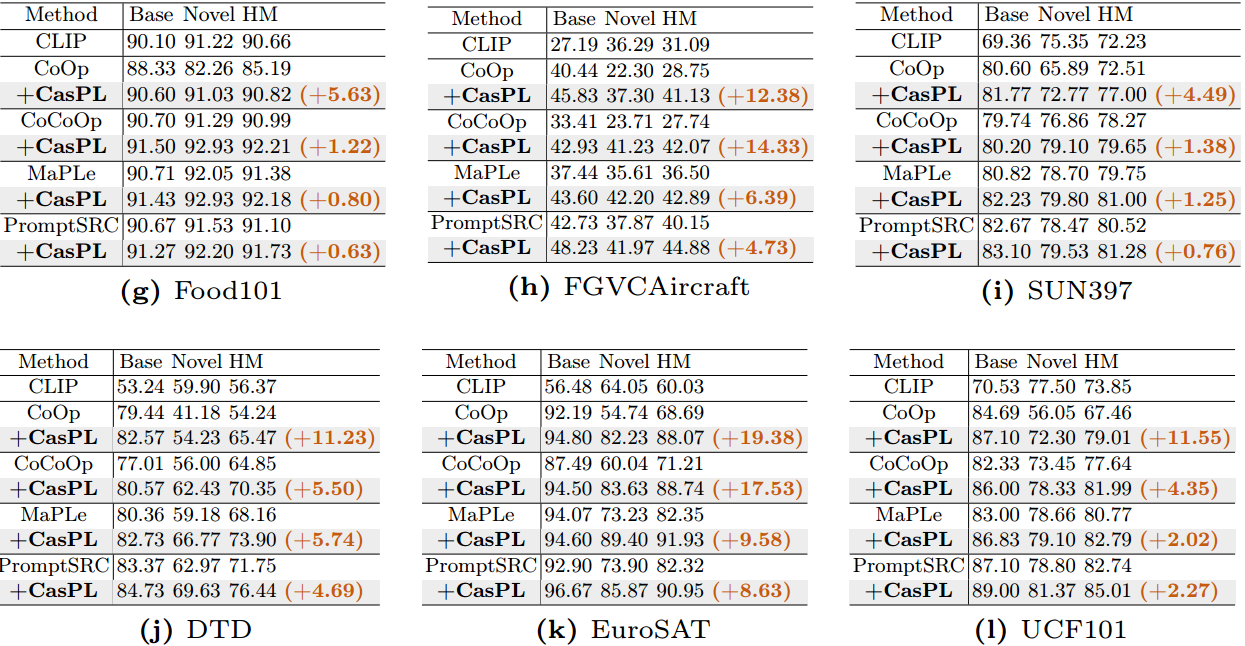
表1:与最先进的方法w/或w/o CasPL在基础到新泛化上的比较。CasPL持续改进11个数据集上的模型性能。
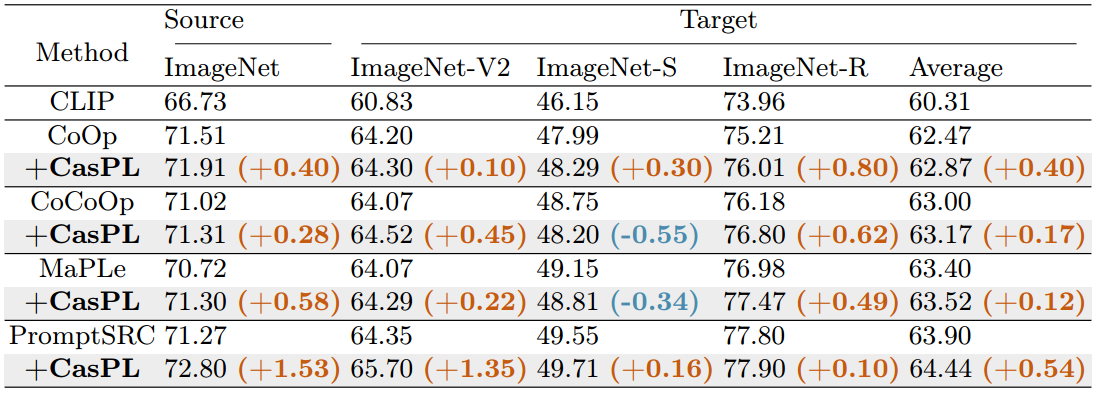
表2:域概化。CasPL在源ImageNet数据集上的精度持续提高。在其他转移域,CasPL在大多数ImageNet-V2和ImageNet-S/-R上实现了显著的增强。
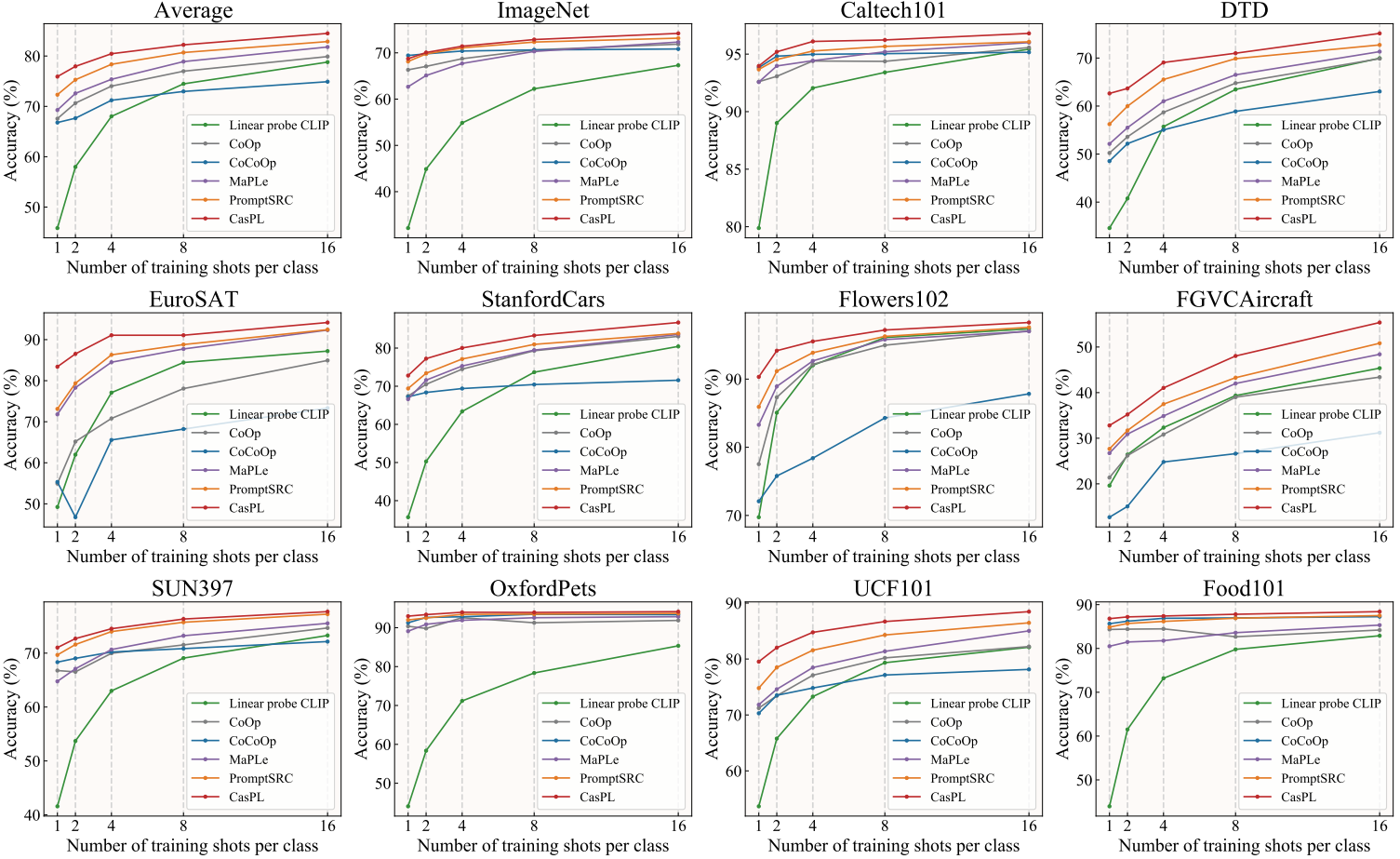
图3:CasPL在少样本图像识别设置下的性能比较。基于PromptSRC, CasPL在所有设置中实现了最高的性能改进。这些结果强调了CasPL的初始增强提示在从高级较大的CLIP中提取领域泛化能力中的作用。
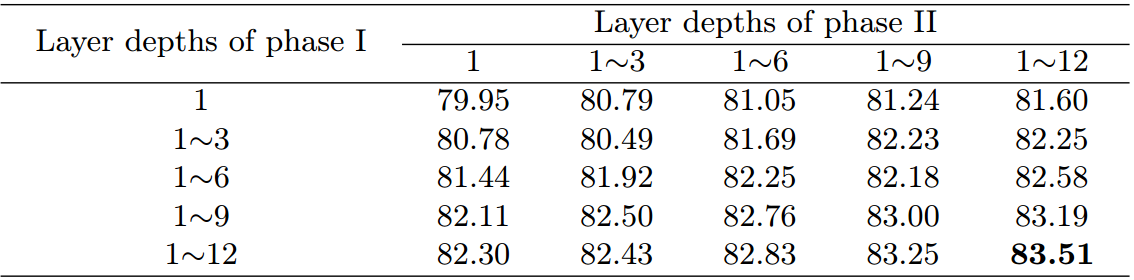
表5:采用谐波平均度量法对不同相位层深的烧蚀研究。一般来说,更深的层始终有助于提高性能。
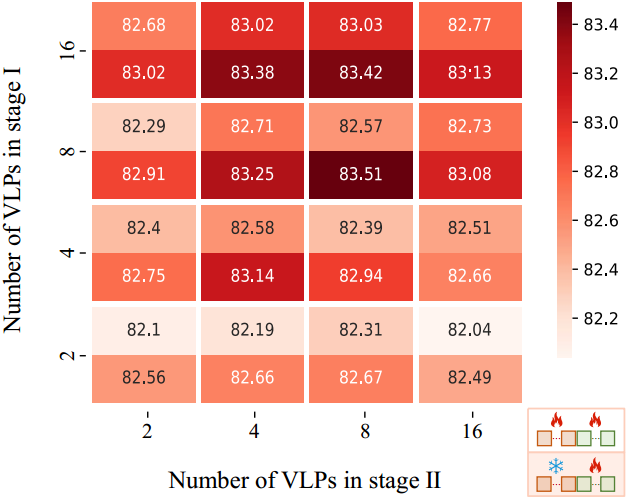
图4:不同阶段视觉语言提示符(VLPs)数量的消融研究,以及第二阶段增强提示符(即)是否可学习。

表6:通过对齐等效VLP数量的准确性比较。表示冻结提升提示,表示可学习适应提示。CasPL在相同的VLP令牌下总体上显著提高了性能。
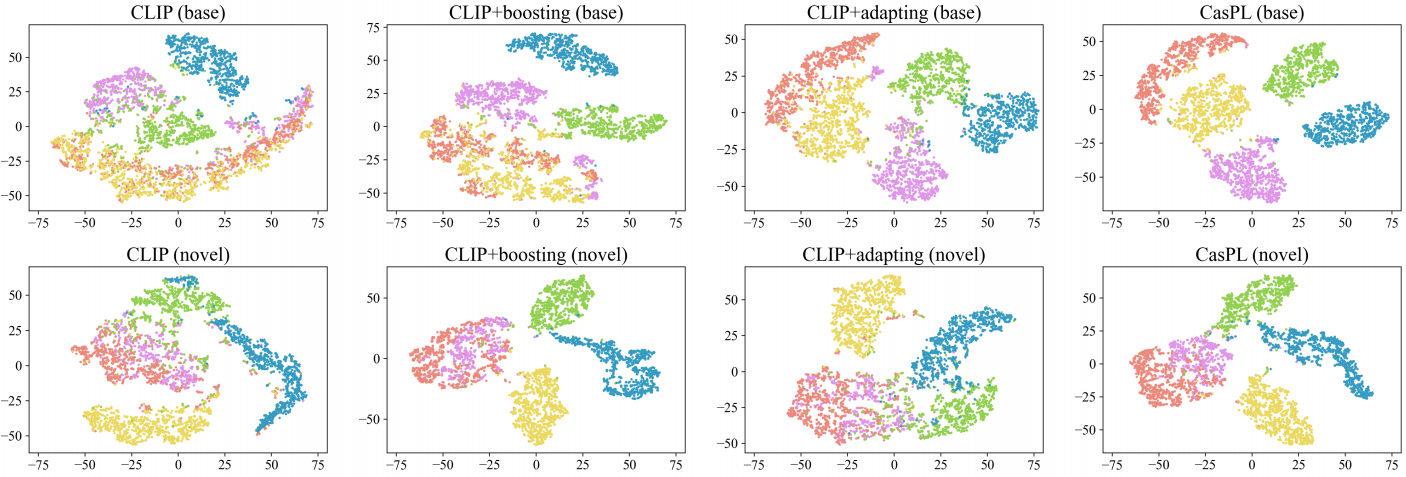
图5:不同方法在DTD数据集上的可视化。第一行和第二行分别描述了基础类或新类的可视化。CasPL减少了类内距离,增加了类间距离,显示了它的有效性。
5.结论
在本文中,我们引入了级联提示学习(CasPL)框架,该框架深入研究了提示在视觉语言模型中的不同作用,特别是促进和适应。CasPL是一种新的学习范式,它引入了两阶段的训练过程:第一阶段利用大量未标记的图像从更大的CLIP模型中提取知识,从而增强提示以获得更广义的知识。在第二阶段,冻结的增强提示与来自现有提示学习方法的更新的可学习的自适应提示级联。我们在11个数据集上全面验证了CasPL的有效性。我们预计我们的工作将为适应视觉语言模型的提示学习提供新的见解,并促进小型模型在资源受限环境中的部署。
限制和未来的工作:我们的CasPL将助推提示作为插件引入到现有方法中,其推理成本和额外参数可以忽略不计(< 0.1%)。然而,值得注意的是,第一阶段的提升提示需要在每个领域进行训练,这确实引入了额外的计算开销。在未来的研究中,我们的计划是探索利用大规模预训练的方法,使增强提示能够更好地泛化各种领域数据集,并最大限度地减少额外的计算时间。理想情况下,我们的目标是通过单个预训练课程来实现这一目标,从而消除了为每个领域训练单个提升提示的需要。
参考资料
论文下载(ECCV 2024)
https://arxiv.org/pdf/2409.17805

代码地址(暂未开源)
https://github.com/megvii-research/CasPL