原始数据:
免费可下载原始参考数据

预测结果图:
根据测试数据test_data的真实值real_flow,与模型根据测试数据得到的输出结果pre_flow

完整源码:
#!/usr/bin/env python
# _*_ coding: utf-8 _*_import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as Data
from torchsummary import summary
import math
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import time
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
from matplotlib.font_manager import FontProperties # 画图时可以使用中文# 加载数据
f = pd.read_csv(r'C:\Users\14600\Desktop\AE86.csv')# 从新设置列标
def set_columns():columns = []for i in f.loc[2]:columns.append(i.strip())return columnsf.columns = set_columns()
f.drop([0, 1, 2], inplace=True)
# 读取数据
data = f['Total Carriageway Flow'].astype(np.float64).values[:, np.newaxis]class LoadData(Dataset):def __init__(self, data, time_step, divide_days, train_mode):self.train_mode = train_modeself.time_step = time_stepself.train_days = divide_days[0]self.test_days = divide_days[1]self.one_day_length = int(24 * 4)# flow_norm (max_data. min_data)self.flow_norm, self.flow_data = LoadData.pre_process_data(data)# 不进行标准化# self.flow_data = datadef __len__(self, ):if self.train_mode == "train":return self.train_days * self.one_day_length - self.time_stepelif self.train_mode == "test":return self.test_days * self.one_day_lengthelse:raise ValueError(" train mode error")def __getitem__(self, index):if self.train_mode == "train":index = indexelif self.train_mode == "test":index += self.train_days * self.one_day_lengthelse:raise ValueError(' train mode error')data_x, data_y = LoadData.slice_data(self.flow_data, self.time_step, index,self.train_mode)data_x = LoadData.to_tensor(data_x)data_y = LoadData.to_tensor(data_y)return {"flow_x": data_x, "flow_y": data_y}# 这一步就是划分数据@staticmethoddef slice_data(data, time_step, index, train_mode):if train_mode == "train":start_index = indexend_index = index + time_stepelif train_mode == "test":start_index = index - time_stepend_index = indexelse:raise ValueError("train mode error")data_x = data[start_index: end_index, :]data_y = data[end_index]return data_x, data_y# 数据与处理@staticmethoddef pre_process_data(data, ):norm_base = LoadData.normalized_base(data)normalized_data = LoadData.normalized_data(data, norm_base[0], norm_base[1])return norm_base, normalized_data# 生成原始数据中最大值与最小值@staticmethoddef normalized_base(data):max_data = np.max(data, keepdims=True) # keepdims保持维度不变min_data = np.min(data, keepdims=True)# max_data.shape --->(1, 1)return max_data, min_data# 对数据进行标准化@staticmethoddef normalized_data(data, max_data, min_data):data_base = max_data - min_datanormalized_data = (data - min_data) / data_basereturn normalized_data@staticmethod# 反标准化 在评价指标误差以及画图的使用使用def recoverd_data(data, max_data, min_data):data_base = max_data - min_datarecoverd_data = data * data_base - min_datareturn recoverd_data@staticmethoddef to_tensor(data):return torch.tensor(data, dtype=torch.float)# 划分数据
divide_days = [25, 5]
time_step = 5
batch_size = 48
train_data = LoadData(data, time_step, divide_days, "train")
test_data = LoadData(data, time_step, divide_days, "test")
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, )
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, )# LSTM构建网络
class LSTM(nn.Module):def __init__(self, input_num, hid_num, layers_num, out_num, batch_first=True):super().__init__()self.l1 = nn.LSTM(input_size=input_num,hidden_size=hid_num,num_layers=layers_num,batch_first=batch_first)self.out = nn.Linear(hid_num, out_num)def forward(self, data):flow_x = data['flow_x'] # B * T * Dl_out, (h_n, c_n) = self.l1(flow_x, None) # None表示第一次 hidden_state是0# print(l_out[:, -1, :].shape)out = self.out(l_out[:, -1, :])return out# 定义模型参数
input_num = 1 # 输入的特征维度
hid_num = 50 # 隐藏层个数
layers_num = 3 # LSTM层个数
out_num = 1
lstm = LSTM(input_num, hid_num, layers_num, out_num)
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(lstm.parameters())# 训练模型
lstm.train()
epoch_loss_change = []
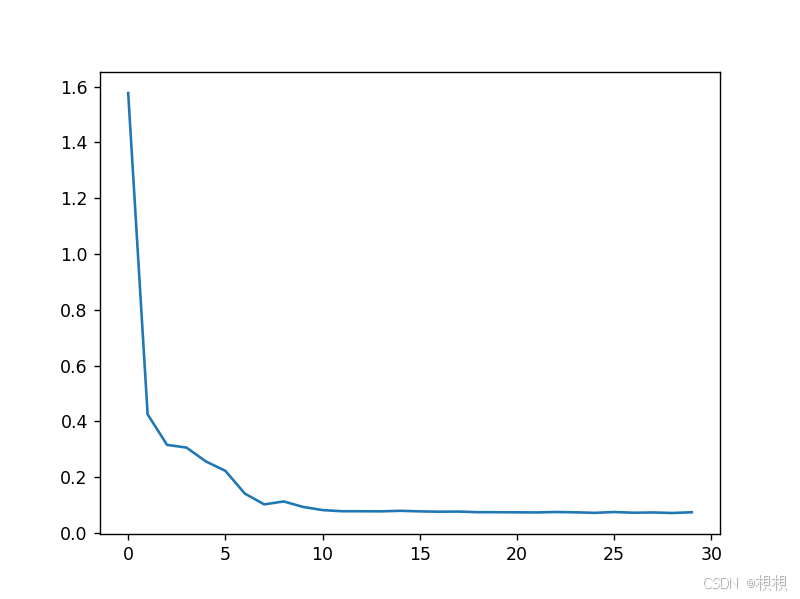
for epoch in range(30):epoch_loss = 0.0start_time = time.time()for data_ in train_loader:lstm.zero_grad()predict = lstm(data_)loss = loss_func(predict, data_['flow_y'])epoch_loss += loss.item()loss.backward()optimizer.step()epoch_loss_change.append(1000 * epoch_loss / len(train_data))end_time = time.time()print("Epoch: {:04d}, Loss: {:02.4f}, Time: {:02.2f} mins".format(epoch, 1000 * epoch_loss / len(train_data),(end_time - start_time) / 60))
plt.plot(epoch_loss_change)# 评价模型
lstm.eval()
with torch.no_grad(): # 关闭梯度total_loss = 0.0pre_flow = np.zeros([batch_size, 1]) # [B, D],T=1 # 目标数据的维度,用0填充real_flow = np.zeros_like(pre_flow)for data_ in test_loader:pre_value = lstm(data_)loss = loss_func(pre_value, data_['flow_y'])total_loss += loss.item()# 反归一化pre_value = LoadData.recoverd_data(pre_value.detach().numpy(),test_data.flow_norm[0].squeeze(1), # max_datatest_data.flow_norm[1].squeeze(1), # min_data)target_value = LoadData.recoverd_data(data_['flow_y'].detach().numpy(),test_data.flow_norm[0].squeeze(1),test_data.flow_norm[1].squeeze(1),)pre_flow = np.concatenate([pre_flow, pre_value])real_flow = np.concatenate([real_flow, target_value])pre_flow = pre_flow[batch_size:]real_flow = real_flow[batch_size:]
# # 计算误差
mse = mean_squared_error(pre_flow, real_flow)
rmse = math.sqrt(mean_squared_error(pre_flow, real_flow))
mae = mean_absolute_error(pre_flow, real_flow)
print('均方误差---', mse)
print('均方根误差---', rmse)
print('平均绝对误差--', mae)# 画出预测结果图
font_set = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=15) # 中文字体使用宋体,15号
plt.figure(figsize=(15, 10))
plt.plot(real_flow, label='Real_Flow', color='r', )
plt.plot(pre_flow, label='Pre_Flow')
plt.xlabel('测试序列', fontproperties=font_set)
plt.ylabel('交通流量/辆', fontproperties=font_set)
plt.legend()
# 预测储存图片
# plt.savefig('...\Desktop\123.jpg')plt.show()