目的
Chaneglog producer 的主要目的是为了在 Paimon 表上产生流读的 changelog, 所以如果只是批读的表是可以不用设置 Chaneglog producer 的。
一般对于数据库如 MySQL 来说, 当执行的语句涉及数据的修改例如插入、更新、删除时,MySQL 会将这些数据变动记录在 binlog 中。相当于额外记录一份操作日志, 类似于 Paimon 中的 input changelog producer 的模式
存储形式
Chaneglog 一般是以单独的 changelog 文件的形式存储的,也是在 snapshot commit 期间提交的。在每次 Snapshot 的元数据中就会记录 changelogManifestList。因此在 Snapshot 过期时,也会一起过期。
Changelog producer 有四种模式,分别是 None,input,lookup,full comapction。一般来说,是要以尽可能低的代价生成 Changelog 这四种的生成代价是由低到高的。
4种模式
None
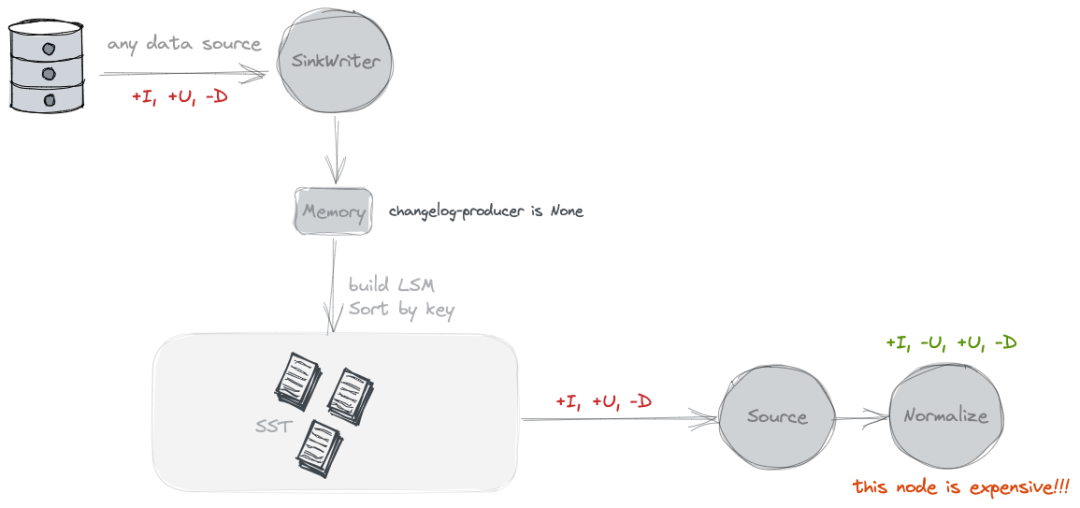
默认就是 none, 这种模式下在 Paimon 侧不会额外存储数据. Source 读取的时候, 就是将 snapshot 的 delta list 文件读取出来, 就是本次 Snapshot 的增量 Changelog 了.
那么在这种模式下,对于一个主键写入两条INSERT数据,批式查询读出来是一个合并后的值,流式查询应该读出来是两个 INSERT 数据,实际上这个changelog是不对的,应该读取第二条的时间应该是 -U +U 才对。
CREATE TABLE T (a INT,b INT,c STRING,PRIMARY KEY (a) NOT ENFORCED
)
WITH (
'merge-engine' = 'deduplicate'
,'changelog-producer' = 'none'
,'continuous.discovery-interval' = '1s' --discovery-interval设置为1秒
);
BlockingIterator<Row, Row> iterator = streamSqlBlockIter("SELECT * FROM T");sql("INSERT INTO T VALUES(1, 1, '1')");
// 两次插入之间间隔2s, 这样source可以读取到两次snapshot的数据
Thread.sleep(2000);
sql("INSERT INTO T VALUES(1, 1, '2')");assertThat(iterator.collect(3)).containsExactlyInAnyOrder(Row.ofKind(RowKind.INSERT, 1, 1, "1"),Row.ofKind(RowKind.INSERT, 2, 2, "2"));
// 第一次commit
Successfully commit snapshot #1 (path /warehouse/default.db/T/snapshot/snapshot-1) by user 6434ee5c-ad2e-4564-a32c-568104392533 with identifier 9223372036854775807 and kind APPEND.
// 扫描到第一个snapshot
start snapshotId: 1
// 第二次commit
Successfully commit snapshot #2 (path /warehouse/default.db/T/snapshot/snapshot-2) by user ce0b10c0-e63f-4db0-ab90-1c542e832791 with identifier 9223372036854775807 and kind APPEND.
// 扫描到delta文件
scan with delta 2
// 输出数据
[+I[1, 1, 1]]
[+I[1, 1, 1], -U[1, 1, 1]]
[+I[1, 1, 1], -U[1, 1, 1], +U[1, 1, 2]]
-
ChangelogNormalize
可以看到流读的输出产生了正确的 changelog, 但是实际上 none 模式读取的时候是没有这个 -U. 具体可以通过 debug ValueContentRowDataRecordIterator 来查看真实读取的数据. 那这个 changelog 消息从哪里来呢 ? 实际上这个流读任务会产生 ChangelogNormalize 算子.

if (isUpsertSource(resolvedSchema, table.tableSource) ||isSourceChangeEventsDuplicate(resolvedSchema, table.tableSource, config)
) {// generate changelog normalize node// primary key has been validated in CatalogSourceTableval primaryKey = resolvedSchema.getPrimaryKey.get()val keyFields = primaryKey.getColumnsval inputFieldNames = newScan.getRowType.getFieldNamesval primaryKeyIndices = ScanUtil.getPrimaryKeyIndices(inputFieldNames, keyFields)val requiredDistribution = FlinkRelDistribution.hash(primaryKeyIndices, requireStrict = true)// 给source添加pk shuffleval requiredTraitSet = rel.getCluster.getPlanner.emptyTraitSet().replace(requiredDistribution).replace(FlinkConventions.STREAM_PHYSICAL)val newInput: RelNode = RelOptRule.convert(newScan, requiredTraitSet)// 本质上就是按照 PK进行last row计算, 用于生成PK的changelognew StreamPhysicalChangelogNormalize(scan.getCluster,traitSet,newInput,primaryKeyIndices,table.contextResolvedTable)
}
// 表示source是upsert的source
public static boolean isUpsertSource(ResolvedSchema resolvedSchema, DynamicTableSource tableSource) {if (!(tableSource instanceof ScanTableSource)) {return false;}ChangelogMode mode = ((ScanTableSource) tableSource).getChangelogMode();boolean isUpsertMode =mode.contains(RowKind.UPDATE_AFTER) && !mode.contains(RowKind.UPDATE_BEFORE);boolean hasPrimaryKey = resolvedSchema.getPrimaryKey().isPresent();// 只发送update_after, 不发送update_before, 并且设置了pkreturn isUpsertMode && hasPrimaryKey;
}
可以看到在这种模式下, 默认下游流读的时候是会生成 ChangelogNormalize 算子的, 类似于一个 Last Row 的算子, 实际上就是每条 input 流入的时候, 因为插件告诉 Planner, 我这个 source 只能产生 Upsert 消息(Insert, Update_after, Delete) , 所以下游通过 Normalize 节点自己来生成 Changelog.
所以 none 模式其实本身发送的 changlog 确实是不全的, 但是通过下游 changelog normalize 补足了这个 Changelog. 所以类似于 MySQL 中 binlog 生成的行为, 他其实也是存在查找前镜像的过程的, 只不过将查找的过程放到了下游的流任务中.
当下游不依赖完整的 Chaneglog, 比如下游也是个同步, 那么下游任务是可以通过参数 scan.remove-normalize 来移除 Normalize 的, 通过伪造 ChangelogMode 为 all 来绕过.
但是这里其实还有一个问题, 下游的 ChaneglogNormalize 节点是有 ttl 的, 假如我某个 key 更新是在 ttl 之后到来, 那么可能导致第二条 Insert/update_after 到来的时候又被当做一条 insert 消息下发, 其实会有数据不准确的问题存在的.
-
DeltaFollowUpScanner
流式读取的时候会分为两个部分, 历史 + 增量. 有一些模式是不需要读历史数据的, 但是增量部分一般都是要读的. 历史部分是读取的某个时刻的快照. 而增量的数据是读取的 CommitKind 为 Append 的 snapshot 所对应的 delta list. 所以其实这种流读模式下, delta scanner 只会读取 L0 的文件.
input
不查找旧值, 额外写Chaneglog
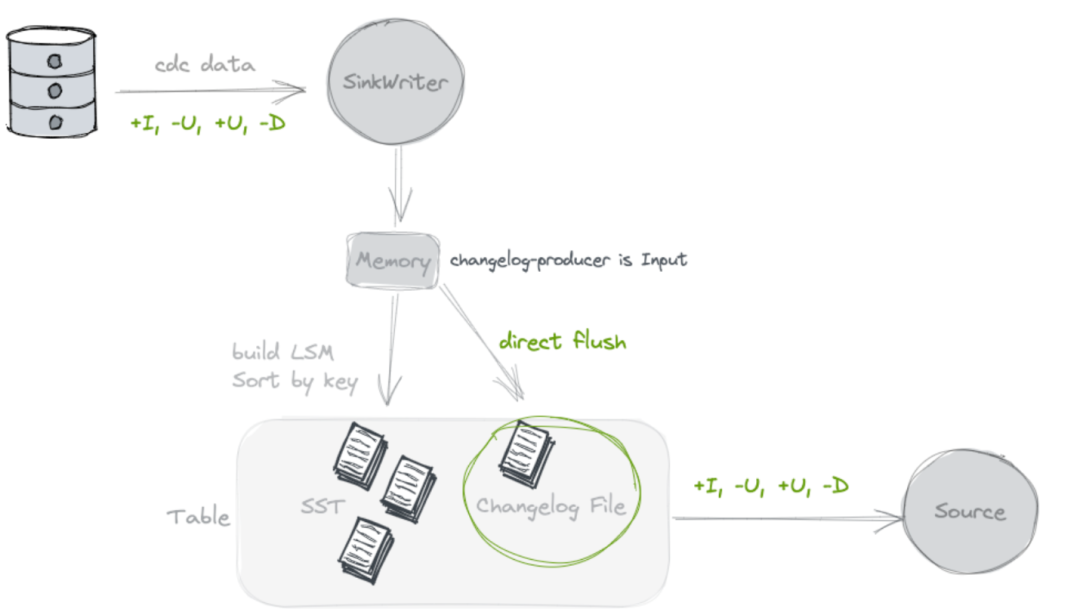
写数据过程中双写一份文件, 作为 Changelog.
理论上来说这种模式应该是很轻量的一种了, 因为首先额外的一份存储是都省不了的, 在 None 模式中,虽然在 Paimon 侧没有占用额外的存储, 但是在下游的流任务的状态中, 其实是有一份全量表的额外存储的开销的. 所以如果 input 模式不考虑存储开销, 计算开销已经是最低了, 因为这种模式不查找旧值.
也因此, 这种模式解决不了的一个问题是, 如果我的输入源就是没有完整 Changelog 的, 比如我从一份有重复数据的离线表导入 Paimon, 那么即使双写一份数据作为 Changelog, 这份 Changelog 也是不对的, 里面可能存在同一个主键的重复数据.
这种模式对于 CDC 的数据源是适用的. 那 None 模式对于 cdc 的数据源是否适用呢 ? 其实是不适用的, 上面我们提到 None 模式的流读其实就是读取 L0的文件, 那么我们只要看 L0的文件是否包含 Key 的变更记录. 因为 write buffer 会有合并的逻辑, 所以, 对于 CDC 的数据, L0中可能会是已经在内存合并后的数据. 比如同一个 key 的-U 和+U 消息, 同时写入, 那么在 writer buffer 写入的时候就已经只保留+U 消息了, 所以 None 模式中 L0文件中的数据, 可能已经是合并后的数据, 对于 CDC 的数据也不适用.
那么是不是可以在内存中不进行合并, L0写入之后在后续 compact 的时候才进行合并, 这样 None 模式就可以替换 input 的功能, 这样不引入额外双写的代价, 也不用额外查找, 就可以保留上游 cdc 数据的完整 Change log.
Lookup
查找旧值, 额外存储Chaneglog
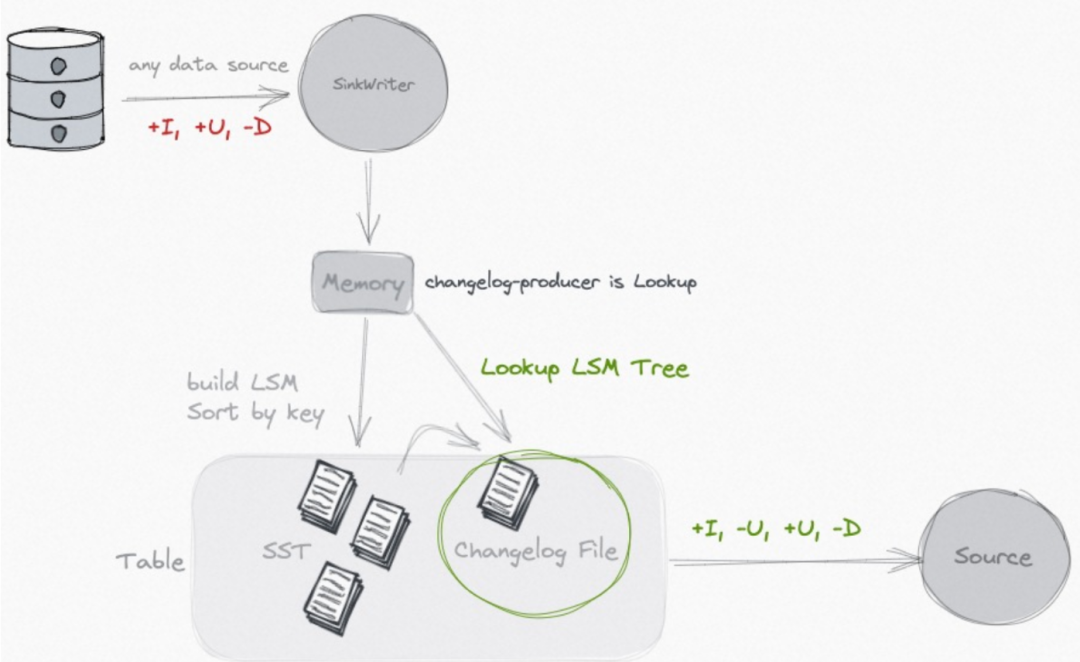
如果不是 CDC 的数据源, 或者此 Paimon 表本身在写入的过程中还有计算逻辑(如 partial-update/aggregation), 那么以上两种模式都不能生成正确的 Changelog.
lookup 的做法, 如其名字, 就是在 compaction 的过程中, 会去向高层查找本次新增 key 的旧值, 如果没有查找到, 那么本次的就是新增 key, 如果有查找到, 那么就生成完整的 UB 和 UA 消息.
-
LookupCompaction
如何保证本次写入的数据一定能够产生的 Chaneglog. 首先按照 Universal Compaction策略挑选文件参与本次 compaction. 如果没有挑选到, 那么会通过 LookupCompaction 策略来挑选, 这里其实隐含了, 如果 Universal Compaction 产生了 Compaction Unit, 一定包含所有的 L0文件.通过 LookupCompaction 策略会将 L0 文件进行 Compaction.
-
LookupMergeFunction
在 Compaction rewrite 的过程中, 会将相同 key 的数据喂给 LookupMergeFunction.
public KeyValue getResult() {// 1. Find the latest high level recordIterator<KeyValue> descending = candidates.descendingIterator();while (descending.hasNext()) {KeyValue kv = descending.next();if (kv.level() > 0) {if (highLevel != null) {descending.remove();} else {highLevel = kv;}} else {containLevel0 = true;}}// 2. Do the merge for inputsmergeFunction.reset();candidates.forEach(mergeFunction::add);return mergeFunction.getResult();
}
candidates 存储的相同 key 的多个 SortedRun 的数据
插入顺序是 sequence number 的增序.对于非 L0 的 kv, sequence 越大, level 越小. 因此 candidates 中的 level 是递减的, 最后的一部分是 L0的. 可以参见一部分 LookupChangelogMergeFunctionWrapperTest
按照 candidates 倒序查找就是, 找到最近的 highlevel 的 value
-
LookupChangelogMergeFunctionWrapper
public ChangelogResult getResult() {reusedResult.reset();KeyValue result = mergeFunction.getResult();if (result == null) {return reusedResult;}KeyValue highLevel = mergeFunction.highLevel;boolean containLevel0 = mergeFunction.containLevel0;// 1. No level 0, just return// 1. No level 0, just return// 没有level 0的数据, 意味着没有新数据产生// 那么没有changelog文件产生, 只是高层文件的合并if (!containLevel0) {return reusedResult.setResult(result);}// 2. With level 0, with the latest high level, return changelog// 出现了highlevel的value, 很幸运, 这样直接就可以得出change log了.if (highLevel != null) {// For first row, we should just return old value. And produce no changelog.setChangelog(highLevel, result);return reusedResult.setResult(result);}// 3. Lookup to find the latest high level record// 向更高level中查找这个key先前的数据, 为了产生变更流代价还是挺高的// org.apache.paimon.mergetree.LookupLevels#lookuphighLevel = lookup.apply(result.key());if (highLevel != null) {// 找到了更高level的数据, 那么别浪费这个结果, 可以再次进行合并, 得到一个更新的值, 并生成UB和UA消息mergeFunction2.reset();mergeFunction2.add(highLevel);mergeFunction2.add(result);result = mergeFunction2.getResult();setChangelog(highLevel, result);} else {// 没有找到更高level的数据, 那么Changelog就是一条insertsetChangelog(null, result);}return reusedResult.setResult(result);
}根据 LookupMergeFunction#getResult 得到的 containLevel0 和 highLevel 的信息, 以及高层 Lookup 完成 Change log 的生成. 在 Lookup 的过程中需要进行文件的二分查找, 以及 Lookup file 的索引文件构建, 整体代价还是比较高的.
Full Compaction
查找旧值, 额外存储 Chaneglog
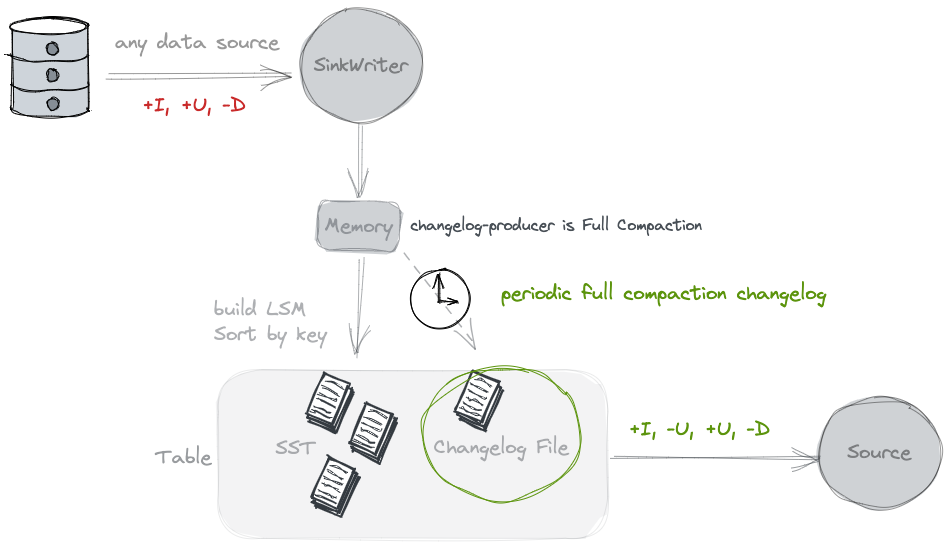
这种模式下一般通过设置 full-compaction.delta-commits 定期进行 full compact, 因为 full compact 其实代价是比较高的. 所以这种模式整体的开销也是比较大的. 但是在 full compact 的过程中, 其实数据都会被写到最高层, 所以所有 value 的变化都是可以推演出来的.
-
FullChangelogMergeFunctionWrapper
public ChangelogResult getResult() {reusedResult.reset();if (isInitialized) {KeyValue merged = mergeFunction.getResult();// 没有topLevelif (topLevelKv == null) {// merged结果为ADD消息, 那么产生insert的消息. 如果merge完是一条DELETE消息, 相当于这条消息的Changelog还没有下发就已经删除了, 所以这个Changelog就不下发了.if (merged != null && isAdd(merged)) {reusedResult.addChangelog(replace(reusedAfter, RowKind.INSERT, merged));}} else {// 有topLevel的数据, merged结果为空或者为DELETE消息, 那么产生UB和UA消息if (merged == null || !isAdd(merged)) {reusedResult.addChangelog(replace(reusedBefore, RowKind.DELETE, topLevelKv));} else if (!changelogRowDeduplicate|| !valueEqualiser.equals(topLevelKv.value(), merged.value())) {reusedResult.addChangelog(replace(reusedBefore, RowKind.UPDATE_BEFORE, topLevelKv)).addChangelog(replace(reusedAfter, RowKind.UPDATE_AFTER, merged));}}return reusedResult.setResultIfNotRetract(merged);} else {// 只有一个value, 并且这个value不在topLevel, 那么就是本次新的Changelog, 置为 insert 数据.if (topLevelKv == null && isAdd(initialKv)) {reusedResult.addChangelog(replace(reusedAfter, RowKind.INSERT, initialKv));}// either topLevelKv is not null, but there is only one kv,// so topLevelKv must be the only kv, which means there is no change//// or initialKv is not an ADD kv, so no new key is addedreturn reusedResult.setResultIfNotRetract(initialKv);}