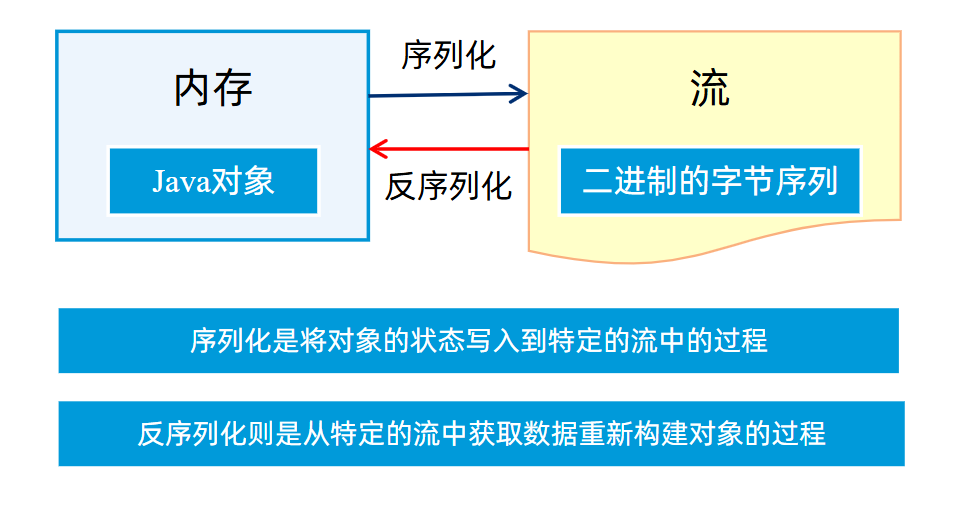
前言
在24年10.26/10.27两天,我司七月在线举办的七月大模型机器人线下营时,我们带着大家一步步复现UMI「关于什么是UMI,详见此文:UMI——斯坦福刷盘机器人:从手持夹持器到动作预测Diffusion Policy(含代码解读)」,比如把杯子摆到杯盘上(其中1-2位学员朋友还亲自自身成功做到该任务)
此外,我还特地邀请了针对UMI做了改进工作的fastumi作者之一丁老师给大家在线分享,毕竟UMI本身有不少局限性,比如耦合性太强、原装硬件的成本太高(比如UR5e、WSG50夹爪)且不方便换成国产硬件、复杂的SLAM算法
所以才有对于UMI的局限性
- 丁老师那边侧重不断推进umi的改进:fastumi「详见此文:Fast-UMI——改进斯坦福UMI的硬件:用RealSense T265替代SLAM且实现机械臂的迁移与平替」,他们也将在11月上旬开源软件代码
当然,我司七月后续也会尝试下fastumi,预计12月中旬左右完成 - 我司七月则先侧重推进dexcap,预计11月份内完成
至于原装umi效果的提升(调参数、采集数据集 训练模型、标定坐标关系),则在做dexcap或者fastumi过程中,如来得及则顺便把这点做了,否则 则和后续的某波b端层面的原装umi效果提升需求一块做
且在和丁老师沟通中,还聊到清华高阳团队也复现了UMI,不过他们是完全用的国外比较昂贵的硬件(Franka机械臂、WSG50夹爪),且即便如此,竟然也没达到UMI原始论文中的效果(误差难以达到6mm以内),至于原论文中的效果不好达到的原因,则众说纷纭了..
而高阳团队的复现UMI的工作对应的论文为《Data Scaling Laws in Imitation Learning for Robotic Manipulation》,当然,他们这篇论文主要是为了探讨机器人领域的数据缩放定律,只是刚好用的UMI而已,但考虑到其对「我司UMI的改进及机器人训练数据收集工作」有一定的参考和启发性,故本文解读下该篇论文
第一部分 清华高阳团队提出:机器人领域中的scaling law
1.1 数据缩放定律实验的前置准备工作
1.1.1 数据缩放定律的制定、数据来源
现有最大的数据库Open X-Embodiment(OXE)(Padalkar等人,2023)包含来自22种机器人化身的超过100万条机器人轨迹。OXE扩展的主要目标是开发一个基础的机器人模型,以促进不同机器人之间的正迁移学习
然而,在新环境中部署此类模型仍需进行数据收集以进行微调。相比之下,清华高阳团队的扩展目标是训练一种策略,可以直接在新环境和未知对象中部署,消除微调的需求
在泛化维度上,他们使用行为克隆(BC)来训练单任务策略。然而,许多通过BC训练的策略表现出较差的泛化性能。这种泛化问题在两个维度上表现出来
- 环境——泛化到以前未见过的环境,这可能涉及光照条件的变化、干扰物体、背景变化等
- 物体——泛化到与人类演示中同类的新物体,这些物体在颜色、大小、几何形状等属性上有所不同
故,对于环境变化,他们通过在各种自然环境中收集人类演示来扩大真实场景的数量;对于对象变化,他们通过获取大量同类日常物品来扩大可访问对象的数量
为简单起见,他们考虑一个场景
- 其中一个操控任务的演示数据集是在
个环境
和
个同类操控对象
中收集的
每个环境可以包含任意数量的干扰对象,只要它们与操控对象不属于同一类别 - 在一个环境
中,对每个对象
收集K个演示
他们使用测试分数S在训练中未见过的环境和对象上评估策略的性能。本文中的数据缩放定律旨在:
- 描述
和变量
之间的关系,特别是泛化能力如何依赖于环境、对象和演示的数量
- 以及根据这种关系,确定实现所需泛化水平的有效数据收集策略
在数据来源上,我们选择使用通用操作接口UMI来收集数据,毕竟其作为手持夹具,可以比较方便且独立的收集大量演示数据,当然了,由于UMI依赖于SLAM来捕获末端执行器的动作,在纹理缺乏的环境中可能会遇到挑战
1.1.2 策略学习、验证评估
在策略学习上
他们采用扩散策略来建模我们收集的大量数据,且使用基于CNN的U-Net(Ronneberger等,2015)作为噪声预测网络,并采用DDIM(Song等,2020a)来减少推理延迟,实现实时控制
且为了进一步提高性能,他们还做了两项改进
- DINOv2视觉编码器:在他们的实验中,对DINOv2 ViT(Oquab等,2023)的微调表现优于ImageNet预训练的ResNet(He等,2016;Deng等,2009)和CLIP ViT(Radford等,2021)
他们将这一改进归因于DINOv2特征能够显式捕捉图像中的场景布局和物体边界(Caron等,2021)。这些信息对于增强空间推理至关重要,这对机器人控制尤其有利(Hu等,2023b;Yang等,2023;Kim等,2024)。为了确保模型容量在数据扩展时不成为瓶颈,我们使用了足够大的模型,ViT-Large/14(Dosovitskiy等,2020) - 时间集成:扩散策略每
步预测一个动作序列,每个序列的长度为
(
),且仅执行前
步
且他们观察到,执行的动作序列之间的不连续性会在切换时导致动作抖动。为了解决这个问题,他们实施了ACT 提出的时间集成策略
具体来说,策略在每个时间步进行预测,导致动作序列重叠。在任意给定的时间步,多重预测的动作使用指数加权方案进行平均,平滑过渡并减少动作不连续性
在效果的验证评估上,他们进行严格的评估以确保结果的可靠性
- 首先,为了评估策略的泛化性能,专门在未见过的环境或未见过的物体上进行测试
- 其次,使用测试人员分配的分数作为主要评估指标。每个操作任务分为若干阶段或步骤(通常为 2-3 个),每个阶段有明确的评分标准(见附录 D),每个步骤最多可获得 3 分
然后报告归一化分数,定义为
最大值为1 - 最后,为了最大限度地减少测试人员的主观偏见,他们同时评估在不同规模数据集上训练的多种策略;每次执行都是从这些多种策略中随机选择的,同时确保物体和机械臂的初始条件相同,从而在策略之间实现公平比较
1.2 数据扩展规律的揭示
1.2.1 对「对象泛化、环境泛化、及两者联合泛化」的结果和定性分析
在任务的设计上,主要是完成倒水和鼠标这两个操作任务:

- 在倒水任务中,机器人执行三个步骤:
首先,它抓住随机放置在桌子上的饮水瓶
其次,它将水倒入杯子中
最后,它将瓶子放在红色杯垫上。这个任务要求精确,特别是在将瓶口对准杯子时 - 在鼠标排列任务中,机器人完成两个步骤:它拾起鼠标并将其放置在鼠标垫上,使其正面朝前。鼠标可能倾斜,需要机器人使用非抓握动作(即推动)先将其对齐
在对象泛化上,他们在相同环境中使用32个不同的对象来收集每个对象120个演示,总共为每个任务提供3,840个演示。且经过SLAM过滤后,Pour Water和MouseArrangement的有效演示数量分别减少到3,765和3,820
- 为了研究训练对象数量如何影响策略对未见对象的泛化能力,他们从32个对象池中随机选择2m个对象进行训练,其中,
- 此外,为了检查策略性能如何随演示数量的变化而变化,他们为每个选定的对象随机抽样2n个有效演示的分数,其中,
对于每个的组合,如果总演示数量超过100,他们就训练一个策略。总共训练了21个策略,并在与训练数据相同的环境中使用8个未见对象进行评估,每个对象进行5次试验。每个策略的平均归一化得分在40次试验中报告
下图展示展示了两个任务的结果(每条曲线对应使用的不同演示比例,归一化分数显示为训练对象数量的函数),可以得出几个关键观察:

- 随着训练对象数量的增加,策略在未见过对象上的表现随着示范比例的变化一致性提高
- 训练对象越多,每个对象所需的示范就越少
例如,在倒水任务中,使用8个对象进行训练时,使用12.5%示范的表现显著落后于使用100%示范的表现;然而,当使用32个对象进行训练时,这个差距几乎消失
换句话说,如果在都是8个对象训练时,12.5%示范比例下的表现远低于100%示范比例下的表现
但如果增加到32个对象进行训练时,12.5示范比例下的表现已经非常接近于100%示范比例下的表现
说明什么问题呢,说明随着对象数量的增加(比如从8个对象到32个对象),即便在低示范比例下(比如12.5%)的表现也会非常不俗 - 总之,对象泛化相对容易实现
性能曲线的初始斜率非常陡峭:但在100%的示范比例之下,仅用8个训练对象时,两个任务的归一化得分就超过0.8,当训练对象数量达到32时,得分超过0.9
这些得分对应于已经很好地泛化到同一类别内任何新对象的策略
在环境泛化上,为了探索训练环境数量对泛化的影响,他们在32个不同环境中使用相同的操作对象,每个环境收集120次示范,故对于倒水和鼠标排列,这分别产生了3424和3351个有效示范,然后
- 他们从32个可用环境中随机选择m个环境「
」进行训练,并且对于每个选择的环境,随机选择2n个有效示范「
」的分数
- 每个策略在8个未见过的环境中使用与训练中相同的对象进行评估,每个环境进行5次试验
具体如下图所示(每条曲线对应于使用不同比例的演示,归一化分数显示为训练环境数量的函数),可以看到

- 增加训练环境的数量可以提高策略在未见环境中的泛化性能。即使总演示次数保持不变,这一趋势仍然存在
说白了,训练环境的数量可以提高表现(同一演示比例之下,即在同一条颜色的线上,随着训练环境的数量增加而提高表现,看 ↗ ),且增加演示次数 亦可提高表现(即同一训练环境数量下,不同颜色线的表现不同,看 ↑ )
然而,虽然在每个环境中增加演示的比例最初会提升性能,但这种改进很快就会减弱,正如代表50%和100%演示使用的线条,有很大程度的重叠 - 对于这两个任务来说,环境泛化似乎比对象泛化更具挑战性
比如,比较上图和上上图,可以观察到当环境或对象的数量较少时,增加环境的数量带来的性能提升小于增加对象的数量。这反映在环境泛化的性能曲线较低的斜率上
接下来,咱们看下环境和对象的联合泛化,即探讨一个训练环境和对象同时变化的设置
- 从32个环境中收集数据,每个环境配对一个独特的对象
对于倒水和鼠标排列,分别有3,648和3,564个有效演示 - 从32个环境对象对中随机选择2m对(m=0,1,2,3,4,5)进行训练,对于每个选定的对,随机抽取2n个有效演示的分数(n= 0,−1,−2,−3,−4,−5)。每个策略在8个未见过的环境中进行评估,每个环境使用两个未见过的对象,每个环境进行5次试验
如下图所示(每条曲线对应使用的不同演示比例,归一化分数显示为训练环境-对象对数的函数),可以看到

- 增加训练环境-对象对的数量可以显著提高策略的泛化性能,这与之前的观察一致
- 有趣的是,尽管在新环境和对象中进行泛化更具挑战性,但在这种情况下,额外演示的收益饱和得更快(如25%和100%演示使用的重叠线所示)
这表明,与仅改变环境或对象相比,同时改变二者可以增加数据多样性,从而提高策略学习效率并减少对演示数量的依赖
这一发现进一步强调,扩展环境和对象的多样性比仅仅增加每个单独环境或对象的演示数量更有效
1.2.2 幂律拟合与定量分析
接下来,探讨实验结果是否遵循如在其他领域中所见的那种幂律缩放规律
- 具体而言,如果两个变量 Y 和 X 满足关系
,它们就表现出幂律关系
对 Y和 X 进行对数变换可揭示出线性关系: - 在高阳团队的本次工作背景中,Y 代表最优性差距,定义为偏离最大分数的程度(即 1 − Normalized Score),而 X 可以表示环境、对象或演示的数量
使用之前实验中 100% 演示比例的数据,对对数变换的数据拟合了一个线性模型,如下图所示(定义为图5)
基于所有结果,他们总结了以下数据缩放规律:
- 该策略对新对象、新环境或两者的泛化能力大致随着训练对象、训练环境或训练环境-对象对的数量呈幂律扩展
这可以通过上图中的相关系数来证明
- 当环境和对象的数量固定时,示范次数与策略的泛化性能之间没有明显的幂律关系。虽然性能在增加示范次数时最初会迅速提高,但最终会趋于平稳,如下图最左侧的图所示
可以看到
上图左侧所示:在收集最大数量的示范的情况下,检查策略的性能是否与示范总数呈幂律关系。倒水和鼠标排列的相关系数分别为-0.62和-0.79,表明只有较弱的幂律关系
上图右侧所示:对于不同的环境-对象对,策略性能随着示范总数的增加而增加,然后达到饱和
关于环境和对象的这些幂律可以作为大规模数据的预测工具。例如,根据上上图:图5中的公式,他们预测,对于鼠标排列,要在新环境和对象上实现归一化得分0.99,需要1,191个训练环境-对象对,对此,july个人认为:这个结论便是这个工作比较有价值的点之一了
1.2.3 高效数据收集策略:涉及环境和对象数量的选择、演示数量的选择
基于以上的实验,他们继续提出了一种由数据缩放法则指导的高效数据收集策略
他们的数据是在M个环境和N个操作对象中收集的,每个环境中的每个对象都有K个示例
试图回答的主要问题是:对于给定的操作任务,如何优化选择M、N和K,以确保策略的强泛化性,同时不导致过于繁重的数据收集过程,为此,继续使用任务倒水和鼠标排列作为示例
首先确认第一个问题,如何选择环境和对象的数量?
- 之前,我们只考虑了每个环境包含一个独特操作对象的设置。然而,在实际的数据收集中,每个环境收集多个对象可能会提高性能,从而成为更有效的方法
- 为了探索这种可能性,假设N是M的倍数,每个环境包含N/M个独特对象
具体来说,使用16个环境,每个环境包含4个独特对象,并为每个对象收集120个示范(M=16, N=64, N/M=4, K=120)
对于倒水和鼠标排列,这分别导致了6,896和6,505个有效示范 - 然后,从16个可用环境中随机选择2m个环境(m=0,1,2,3,4)
对于每个选定的环境,使用n个对象(n=1,2,3,4)的所有示范作为训练数据
总共训练了20个策略,每个策略在8个未见过的环境中进行评估,每个环境使用两个新对象,每个环境进行5次试验
如下图的热图显示,当环境数量较少时,在每个环境中收集多个对象可以提升性能。然而,随着环境数量的增加(例如,达到16个),每个环境中收集多个对象与仅收集一个对象之间的性能差距变得微不足道
即,对于大规模数据收集来说,环境数量通常超过16个,在同一环境中添加多个对象不会进一步提高策略性能,这表明这种方法可能是不必要的
- 故,基于他们的实验结果,他们建议如下:在尽可能多的多样化环境中收集数据,每个环境中仅有一个独特的对象。当环境-对象对的总数达到32时,通常足以训练出能够在新环境中操作并与之前未见过的对象交互的策略
其次,确认第二个问题,即如何选择演示次数?
通过上文1.2.1节的实验结果表明,超过某个点增加演示次数带来的好处很小。本节旨在识别该阈值
- 首先检查设置为M=16和N=64的情况(如前面的实验中),代表收集到最大数量演示的场景——总共有超过6400个演示
他们改变用于训练的演示总数,范围从64到6400,并训练8个策略
结果如下图最左边的图所示
显示当演示数量达到800时,两个任务的性能都趋于平稳 - 接下来,考虑推荐的收集环境-对象对(即M=N)的设置
结果如上图最右边的两个图所示,表明当环境-对象对的数量较少时,需要更少的总演示来达到饱和
具体来说,对于8、16和32对,性能分别在400、800和1600个演示时达到平稳
基于这些发现,他们建议为与他们的任务难度相似的任务收集每个环境-对象对50个演示(即K=50)
1.2.4 数据收集策略的验证:32个环境-对象对、50次示范
为了验证上节所述的「数据收集策略」的普遍适用性,作者团队将其应用于新任务,并评估是否可以训练出足够具备泛化能力的策略
具体而言,他们尝试了两个新任务:折叠毛巾和拔掉充电器
- 在折叠毛巾任务中,机器人首先抓住毛巾的左边缘并向右折叠
在拔掉充电器任务中,机器人抓住插在电源插座上的充电器并迅速拔出
对于每个任务,从32个环境-对象对中收集数据,每个环境进行50次示范
- 与之前的实验一致,他们在8个未见过的环境中评估策略,每个环境包含2个未见过的对象,并在每个环境中进行5次试验
结果下表所示
报告了策略的标准化得分和相应的成功率(成功标准的定义见附录D)
如上表所示,他们的策略在所有四个任务中都达到了约90%的成功率——包括之前实验中的两个任务和两个新任务
值得注意的是,在两个新任务中实现这种强泛化性能仅需4名数据收集者一个下午的数据收集。这突显了我们数据收集策略的高效性,并表明训练能够在新环境和对象中零样本部署的单任务策略所需的时间和成本是适中的
1.3 模型规模和训练策略:超越数据扩展
最后,作者将探索范围从数据扩展延伸到模型方面
扩散策略由两个部分组成:一个视觉编码器和一个动作扩散模型。他们的研究重点是视觉编码器训练策略的重要性以及视觉编码器和动作扩散模型参数扩展的影响
具体而言,他们在Pour Water上进行实验,使用从32个环境-对象对收集的数据,并选择所有有效演示的50%作为训练集
结果如下表所示

得出几个关键观察:
- 对于视觉编码器,预训练和全面微调都是必不可少的
具体如上表a部分所示,从头学习(LfS)的ViT-L/14和使用冻结的DINOv2预训练特征的得分接近于零
此外,参数高效微调方法如LoRA(rank=8)(Hu等,2021)无法匹配全面微调的性能 - 增加视觉编码器的规模显著提高了性能
如上表b部分显示,将视觉编码器从ViT-Small扩展到ViT-Large,策略的泛化性能稳步提升 - 与预期相反,扩展动作扩散U-Net并未带来性能提升
如上表c部分所示,尽管随着网络从小到大扩展,最大特征维度从512增加到2048,但得分并未相应提高
事实上,最大的U-Net性能略有下降。他们推测,小型U-Net的容量可能已经足以建模当前的动作分布,或者他们尚未找到可扩展的动作扩散架构或算法
最后,再谈一下他们目前这个工作的局限性
- 首先,他们专注于单任务策略的数据扩展,而没有探索任务级别的泛化,因为这需要收集来自数千个任务的数据
未来的研究可以结合语言条件策略,探索如何扩展数据以获得能够遵循任何新任务指令的策略(Kim等,2024) - 其次,仅在模仿学习中研究数据扩展,而强化学习(RL)可能进一步增强策略能力;未来的研究可以调查RL的数据扩展规律
- 第三,使用UMI进行数据收集,这在演示中引入了固有的小错误,并且我们仅使用扩散策略算法对数据进行建模。未来的研究可以调查数据质量和策略学习算法如何影响数据扩展规律
- 最后,由于资源限制,仅在四个任务上探索和验证了数据扩展规律;他们希望未来的工作能在更大且更复杂的任务集上验证他们的结论
第二部分 清华高阳团队复现UMI的一些关键细节
2.1 使用UMI收集数据的经验
他们还在论文中分享了使用UMI收集大量示范数据所获得的关键见解:
- 随机初始姿势至关重要:对于每次演示,随机化手持夹具的初始姿势,包括其高度和方向,这一点至关重要
这种做法有助于覆盖更广泛的起始条件。如果没有这种变化,训练出的策略将对特定的初始姿势过于敏感,从而限制其在某些位置的有效性。同样,物体的初始位置范围也应尽可能广泛,同时保持在机器人的运动学和动力学限制范围内 - 选择一个具有丰富视觉特征的环境:由于 UMI 依赖于 SLAM 进行相机位姿跟踪,缺乏足够视觉特征的环境——例如黑暗区域或空白墙壁——可能导致跟踪失败
为了解决这个问题,他们使用可视化工具 Pangolin (Lovegrove) 来验证环境是否具有足够的特征。引入更多干扰物体或向表面(如桌面)添加纹理,可以增加视觉特征,同时也可以作为一种数据增强形式,帮助策略学习忽略环境中不相关的变化
此外,进行多次地图构建和使用批量 SLAM 处理可以增加有效示范的数量 - 使用适当大小的操作物体:大型物体可能会阻碍相机的视野(例如门或抽屉),这可能导致SLAM算法误认为相机是静止的,从而导致跟踪失败。这一限制影响了他们避免执行诸如打开抽屉等任务的决定,突显了当前UMI的一个关键缺陷
整合现成的姿态跟踪硬件(例如iPhone Pro或VIVE Ultimate Tracker)可能会提高UMI的准确性和稳健性 - 其次,还建议
i) 在不同的数据采集者之间标准化行为模式和任务完成时间,以最小化数据集中多模态行为
ii) 在收集数据时,避免移动非操作对象(干扰物),并确保其他移动实体不进入相机的视野
iii) 关闭夹持器时施加轻微的力以引入轻微的变形
2.2 策略训练
在最小数据集上训练的策略经历了800个周期,总计个训练步骤。而在最大数据集上训练的策略经历了75个周期,总计
个训练步骤,使用8个A800GPU需要75小时完成
且他们使用每个策略的最终检查点进行评估。鉴于模型中大量的参数——视觉编码器和噪声预测网络加起来超过3.96亿——我们使用BFloat16精度来加速训练,同时保持数值稳定性
此外,策略实现主要遵循Diffusion Policy (Chi et al.,2023)和UMI (Chi et al.,2024)中的方法,但进行了一个小的修改:增加了某些任务的观察视野
- 例如,在PourWater任务中,当瓶子接近杯口时,策略最初难以区分是即将开始倒水还是倒水已经完成
为了解决这个问题,在原有的2步观察视野(对应于0.05秒的实时持续时间)中加入了一个更远的历史步骤(0.25秒之前) - 对于Unplug Charger任务,我们加入了一个0.5秒的历史步骤
此调整显著提高了Pour Water和Unplug Charger的性能,同时没有增加太多的训练或推断成本
有关超参数的更多信息,详见下表

2.3 各个任务的关键描述和评分标准
2.3.1 倒水
- 对于倒水,机器人执行三个连续的动作:首先,它抓住一个饮料瓶;随后,它将水倒入一个杯子中;最后,它将瓶子放置在指定的红色杯垫上
- 瓶子随机放置在桌子上,但必须在机器人的运动范围内。瓶子和杯子的初始相对位置也是随机的,确保它们间距可变,同时在抓住瓶子后杯子仍能被摄像头看到。红色杯垫是一个直径9厘米的圆形,始终放置在杯子右侧约10厘米处,并在所有环境中使用
- 由于瓶子的颜色、大小和高度的变化,这项任务挑战了机器人的泛化能力,并要求瓶口与杯子精确对齐以成功完成任务。该任务还需要显著的旋转运动,超出了基本的拾取和放置操作。倒水和放置动作的成功执行关键在于初始准确地抓住瓶子。在测试中,瓶盖被紧紧拧上,不会实际倒出水
以下是评分标准
步骤 1:抓住饮料瓶
- – 0 分:夹持器没有接近饮料瓶
- – 1 分:夹持器接触到饮料瓶但由于小错误未能抓住,或最初抓住瓶子,但在提升过程中瓶子滑出
- – 2 分:抓手在抓住饮料瓶之前将其推了一段显著的距离
- – 3 分:抓手成功抓住饮料瓶,没有任何滑动
步骤 2:将水倒入杯子中
- – 0 分:抓手没有接近杯子
- – 1 分:旋转饮料瓶后,其瓶口仍在杯子外,无法倒水
- - 2 分:旋转饮料瓶后,瓶口位于杯子边缘的正上方,只能部分倾倒
- - 3 分:旋转饮料瓶后,瓶口完全在杯子内,便于完全倾倒
步骤 3:将瓶子放在红色杯垫上
- – 0 分:夹持器没有接近红色杯垫
- – 1 分:饮料瓶放置在红色杯垫外,或者放置过程中扰动了杯子,导致其倾倒
- – 2 分:只有部分饮料瓶放在红色杯垫上
- – 3 分:饮料瓶完全且稳定地放在红色杯垫上
成功标准。一个成功的任务需要在步骤1中至少得2分,步骤2中得3分,步骤3中至少得2分
2.3.2 拔掉充电器
机器人需要完成两个步骤:首先,它抓住插入插线板的充电器;其次,它拔出充电器并将其放置在插线板的右侧
充电器和插线板可以放置在桌面的任何地方,只要它们保持在机器人的运动范围内
挑战在于机器人能否准确抓住充电器,施加足够的力,并迅速将其拔出。充电器插头有不同的形状和大小,因此机器人必须调整其握持方式以牢固地握住插头
以下是评分标准
步骤 1:抓取充电器
- – 0 分:夹持器未能抓取充电器
- – 1 分:夹持器抓住了充电器但不够紧,导致无法拔出充电器
- – 2 分:夹持器牢固地抓住了充电器,但在过程中与插线板发生碰撞,最终充电器被拔出
- – 3 分:夹持器牢固地握住充电器,没有与其他物体碰撞,之后成功拔出充电器
步骤 2:拔出充电器
- – 0 分:充电器没有被拔出
- - 2 分:拔出充电器后,它从夹持器滑落
- - 3 分:充电器成功拔出,夹持器将其放置在电源插座的右侧
成功标准。成功的任务要求在步骤 1 中至少获得 2 分,在步骤 2 中获得 3 分
2.4 评估细则
他们使用测试人员分配的分数作为主要评估指标,承认这种方法本质上引入了测试人员的一些主观性
另一种指标是验证集上的均方误差(MSE),它提供了一种不需要人工干预的潜在客观测量
为了计算MSE,我们为每个评估环境或对象收集30个人类演示,形成验证集。然后,我们通过平均每个时间步长上策略预测的动作与人类动作之间的平方差来计算MSE。他们观察到,在某些情况下,MSE(均方误差)与归一化得分之间存在强烈的反向相关性
例如,在下图图17的右图中

实验设置评估了政策在Pour Water任务中跨环境和对象的泛化能力。随着训练环境-对象对的数量增加,归一化得分逐渐上升,而MSE稳步下降,Pearson相关系数r=-0.98,Spearman等级相关系数ρ=-1.00,这表明MSE可能替代人工评分方法
然而,在某些情境中,MSE与真实世界的表现并不相关
- 例如,在上图图17的左图中,实验评估了政策在Pour Water任务中跨对象的泛化能力。当训练对象的数量增加到16时,MSE实际上增加,Pearson相关系数仅为-0.73
- 同样,在探索模型训练策略的实验中,LoRA的MSE显著低于全量微调(0.0049对0.006)
然而,在真实世界测试中,LoRA的政策表现不如全量微调,归一化得分分别为0.72和0.9
总体而言,验证集上的MSE通常与现实世界的表现不相关,许多异常现象不可预测且没有明显的模式。这使我们相信MSE不是一个完全可靠的评估指标。在实践中,我们更多地将MSE用作调试工具,以快速识别存在明显问题的策略
2.5 UMI的硬件设置
如下图图19所示,他们使用了一台Franka Emika Panda机器人(一个7自由度机械臂),配备了Weiss WSG-50夹持器(一个1自由度平行爪夹持器)
- 为了解决机器人末端执行器俯仰角度有限的问题,使用了Chi等人(2024年)设计的安装适配器,将WSG-50夹持器相对于机器人的末端执行器法兰旋转90度

- 夹持器配备了使用紫色95A TPU材料打印的柔软、顺应性手指
- 对于感知,使用了一台安装在腕部的GoProHero 10相机,配备鱼眼镜头。GoPro的实时视频流通过GoPro Media Mod和Elgato HD60X外部采集卡的组合实现

- 策略推理在一台配备NVIDIA 4090 GPU(24 GB VRAM)的工作站上进行
- 所有组件由一台容量为2048 Wh的移动电源(EcoFlow DELTA 2 Max)供电,该电源还作为一个23公斤的配重,以防止倾斜。系统安装在一个定制的可移动升降台上。虽然该台不能自动移动,但其移动性允许在非实验室环境中测试他们的策略
关于UMI复现的更多关键,详见:具身智能机器人复现实战营 [复现实战UMI/DexCap]