参考来源:In-memory processing - Wikipedia,What is processing in memory (PIM) and how does it work? (techtarget.com),《Processing-in-memory: A workload-driven perspective》
LPDDR Initial → LPDDR Write Leveling and DQ Training → LPDDR Read and Training → LPDDR Write and Training → LPDDR Clock Switch → PIM Technical
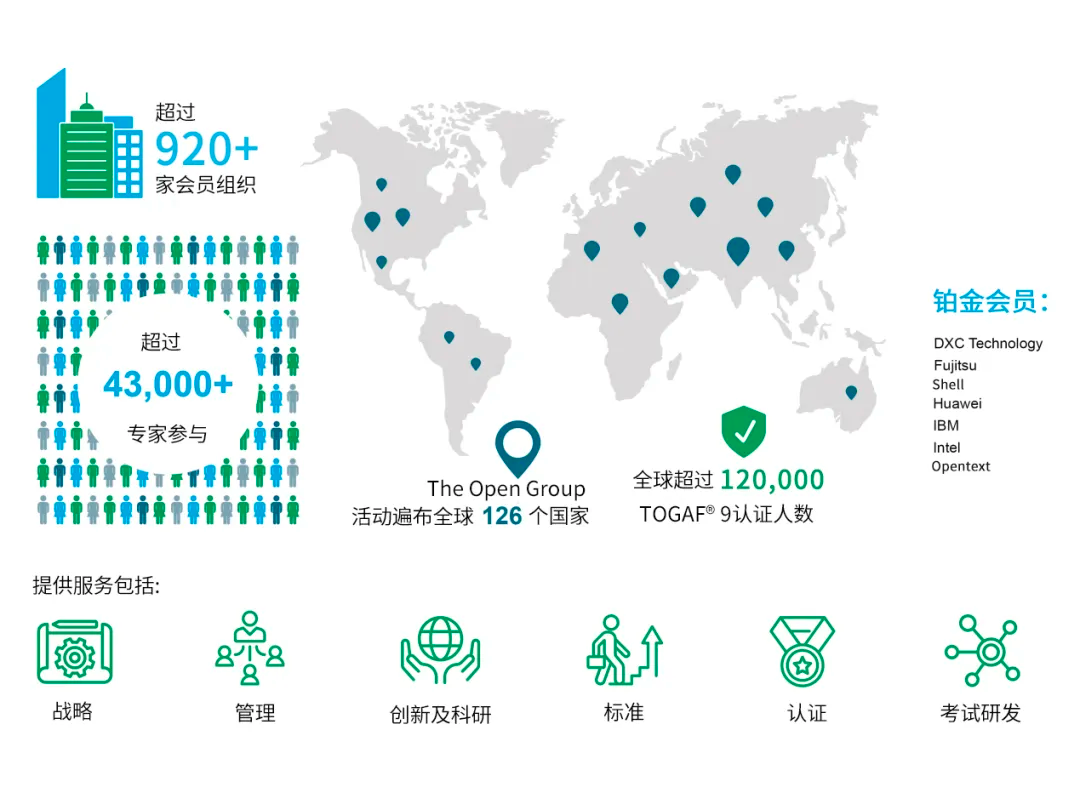
PIM - Processing in Memory Basic
什么是PIM,看下Wiki的定义:
Hardware层面:PIM - Processing in Memory 是一种计算机体系结构,在这种体系结构中,数据操作可直接在DRAM内存中进行,而无需先传输到CPU寄存器中。
Software层面:PIM - Processing in Memory 是一种软件架构,数据库完全保存在随机存取存储器(RAM)或闪存中,因此数据的读取或查询操作,不需要访问磁盘存储。
这里分析的对象是Hardware层面的PIM体系,这种PIM 架构等于是在DRAM附近添加了具备逻辑运算单元的小型通用核心,称之为PIM 内核(PIM Cores)。
这种 PIM 内核往往与 CPU 兼容,可以像CPU一样执行应用程序的任何部分。

但由于面积、能耗和性能等原因,它们无法承受像 CPU 一样复杂的大型多级缓存层次结构或执行逻辑限制。
PIM 内核通常没有缓存或缓存很小,限制了它们可以利用的时间局部性的数量。
并且PIM没有复杂的激进的乱序或超标量执行逻辑,限制了 PIM 内核提取指令级并行性的能力。
因此对于计算密集型或缓存友好型部分的数据处理应该还是保留在更大、更复杂的 CPU 内核上。
在具备PIM架构的处理器任务设计中,需要根据以下几个条件判断是否需要调用PIM执行相关code:
- 这个函数是否为整个workload中最耗费energy的部分
- 这个函数的data movement是否占用了整个workload负载的20%以上
- 这个函数是否为内存密集型而非计算密集型(每一千指令中就有一次last-level cache misses)
- 这个函数的data movement是否占据了此函数主要的负载消耗
可以看到满足上述条件的code基本都是充斥着大量的data movement这样简单操作的任务,而这类简单密集的任务就可以让PIM参与协助执行,减少CPU的负担。
PIM in Tensorflow Case
下面基于Tensorflow Case对PIM的实际应用场景进行分析:

可以看到不同网络之间负载消耗主要在打包Packing,量化Quantization和解包Conv2D。
这几个任务的特点就是矩阵数据需要重新排序为向量数据,从而减少CPU访问数据的缓存未命中Cache Miss,但是会导致大量的data movement。
PIM架构就可以有效优化这类问题。
在神经网络算法设计中,矩阵乘法 (GEMM) 是神经网络的核心构建基础模块,由 2-D 卷积层和全连接层使用,而在不同层级之间都会涉及CPU和Memory数据的搬运。
下面是两种不同架构之间在Data Packing阶段的流程差异:

相比单独CPU流程:
- 获取Matrix Data(Memory -> CPU)
- 找到min/max,矩阵数据量化处理(CPU)
- CNN卷积(CPU -> Memory)
- Loop back to step1
可以看到CPU + PIM流程把除了卷积Conv2D之外的活都交给PIM干了,大幅度减少了CPU工作量:
- 找到min/max,矩阵数据量化处理(Memory)
- CNN卷积(Memory -> CPU -> Memory)
- Loop back to step1
下面是不同架构下的能耗对比图:

图中的PIM-Acc有单独的硬件加速模块。而PIM-Core没有专门的加速设计,只有普通的少量通用逻辑运算单元。
Programming PIM Architectures
在设计程序中,分出单独的Section内容用于给PIM代理执行,这样的行为被称为Offload(卸载)。
那么在设计这部分卸载内容时需要考虑的因素有哪些?
Offloading Granularity
设计卸载内容时的最小粒度单位可以是单个指令、批量操作、整个函数或者整个应用程序,不同的卸载粒度对于PIM的要求都是不同的。
实例可以参考 Tesseract/GRIM-Filter。

如果是单个指令为最小卸载粒度,可以基于现有的ISA单独建立一个PIM执行的CPU指令 PEI(PIM-enabled instruction)
PEI由PCU(PEI Computation Unit)单元执行,每个CPU Core配备一个PCU。
一个PEI指令的执行可能需要多个CPU指令,但实际对于CPU而言只需要执行一个PEI指令。
不同CPU Core之间的PEI指令会被集中送到PMU(central PEI Management Unit),PMU 会在其一个 PCU 上启动适当的 PIM 操作,再获取返回Data/Ins。
这种设计具有以下优点:
- 这使得 PEI 和 PIM 操作之间的映射保持简单,并允许逐步引入新指令
- 避免了在内存中进行虚拟内存地址转换的需要,因为转换是在将 PEI 发送到内存之前在 CPU 中完成的
- PIM 操作仅限于在单个高速缓存行上操作,单个PEI和普通CPU Ins占用的memory fences/Cache Line一样
- PEI 有原子性,并使用Memory Barrier来隔离 PEI 和普通 CPU 指令
但是因为要和CPU指令协调,PIM计算的复杂性很低,只能执行一些简单计算。
作为指令,只能携带少量数据,当需要执行大量 PIM 操作时,这可能会产生很高的开销。
如果是批量操作为最小卸载粒度,在内存中执行批量操作有两个要求:
- 批量按位操作一次不能对少于一行执行
- 由于存储器阵列内可以实现的逻辑功能数量的限制,对批量数据只能进行简单的逻辑运算
如果是整个函数为最小卸载粒度,可以用编译器指令包围Function实现: #PIM_begin 和 #PIM_end 指令包围,编译器可以使用它们来生成在 PIM 上执行的线程。
这种方法需要编译器和/或库支持来将 PIM 内核分派到内存,并且这种方法还需要考虑PIM和CPU之间的缓存一致性和地址转换问题。
如果是整个应用为最小卸载粒度,可以避免与 CPU 进行通信,但是因为PIM资源有限,极大地限制了可以使用 PIM 执行的应用程序类型。
Data Coherency
PIM和CPU之间是共享内存的状态,Cache Coherency是需要考虑的。
而且PIM会占用大量的coherence messages,所以需要设计支持更高带宽的一致性机制CoNDA:

这里简单总结下CoNDA功能:
- 周期地推测性地获取给定时间段内多个内存操作的一致性权限
- 可以理解为对一块memory region的操作行为归为一次性的PIM Kernel thread task,在Cache一致性机制中被视为单次的data modified
- 将来自多个内存操作的一致性请求批处理为一组压缩的一致性签名
- 将签名发送给CPU以确定推测是否违反了任何一致性语义
CPU收到签名后,基于Cache Coherency进行一致性检查,如果有dirty line就刷新。
PIM Kernel收到CPU刷新指令就会Roll Back并且重新执行Command,因为之前执行的command用的是未更新前的数据,而不是Cache中存储的最新数据。
下面是不同架构下的性能对比图:

可以看到CoDNA通过利用各种缓存一致性机制有效优化了数据处理的速度。部分缩写定义如下:
- NC - noncacheable data regions
- CG - coarse-grained locks on shared data regions
- FG - fine-grained coherence per cache line
- Ideal-PIM - 理想PIM
Virtual Memory
在之前的CPU Study专栏中提到过,VA->PA需要基于Memory中的Page Table/Cache中的TLB进行。
例如PIM Kernel需要遍历指针时,指针存储地址信息为VA,如果需要CPU协助进行VA→PA,则会浪费PIM优势。
所以在PIM设计中通常采取如下方法:
独立的PIM页表架构
CPU页表与PIM页表解耦,基于IMPCA 开发。
IMPCA 加速器仅对某些可以映射到VA中连续区域的数据结构进行操作,将其称为 PIM 区域。
因此,可以使用更小的基于区域的页表来映射连续的 PIM 区域,而无需为整个地址空间复制页表映射。
其次如果只需要映射 PIM 区域
可以折叠传统的多层次页表结构,相关的PIM region地址转换module设计就会简单很多。
独立的PIM编译器
在编译阶段解决虚拟地址问题,生成基于PIM物理地址的映射表信息。