目前字符编码有以下几种:
1、UTF-8
UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。
2、UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元, 长度为2 Byte)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。UTF-16是2字节或4字节存储,英文也是2字节。详细请参考文章
UTF-8 与 UTF-16编码详解-CSDN博客
3、GBK,GB2312
何为GBK,何为GB2312,与区位码有何渊源?
区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。就是打四个数字然后就出来汉字了,什么原理呢。请看下面的区位码表,每一个字符都有对应一个编号。其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是:0xA0+区号,0xA0+位号。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE
区位码表节选


可能大家注意到了,区位码里有英文和数字,按道理说是不是也应该是双字节的呢。而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。比如一个数字2,对应的二进制是0x32,而不是 0xA3 0xB2。那么问题来了,0xA3 0xB2 又对应到什么呢?还是2(笑)。注意看了,这里的2跟2是不是有点不太一样?!确实是不一样的。这里的双字节2是全角的二,ASCII的2是半角的二,一般输入法里的切换全角半角就是这里不同。
如果留意过早些年的手机(功能机),会发现人名中常见的“燊”字是打不出来的。为什么呢?因为早期的区位码表里面并没有这些字,也就是说早期的GB2312也是没有这些字的。到后来的GBK(1995)才补充了大量的汉字进去,当然现在的安卓苹果应该都是GBK字库了。再看看这些补充的汉字的字节码 燊 0x9F 0xF6 。和前面说到的GB2312不同,有的字的编码比 0xA0 0xA0 还小,难道新补充的区位号还能是负的??其实不然,这次的补充只补充了计算机编码表,并没有补充区位码表。也就是说区位码表并没有更新,用区位码打字法还是打不出这些字,而网上的反向区位码表查询也只是按照GBK的编码计算,并不代表字与区位号完全对应。时代的发展,区位码表早已经是进入博物馆的东西了。
Big5是与GB2312同时期的一种台湾地区繁体字的编码格式。后来GBK编码的制定,把Big5用的繁体字也包含进来(但编码不兼容),还增加了一些其它的中文字符。细心的朋友可能还会发现,台湾香港用的繁体字(如KTV里的字幕)跟大陆用的繁体字还有点笔画上的不一样,其实这跟编码无关,是字体的不同,大陆一般用的是宋体楷体黑体,港澳台常用的是明体(鸟哥Linux私房菜用的是新細明體)。GBK总体编码范围为0x8140~0xFEFE,首字节在 0x81~0xFE 之间,尾字节在 0x40~0xFE 之间,剔除 xx7F 一条线。详细编码表可以参考这个列表。微软Windows安排给GBK的code page(代码页)是CP936,所以有时候看到编码格式是CP936,其实就是GBK的意思。2000年和2005年,国家又先后两次发布了GB18030编码标准,兼容GBK,新增四字节的编码,但比较少见。
GBK编码字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
4、ANSI
用Notepad++创建一个文本文件text.txt,其默认编码格式为ANSI(乍看之下,还以为是ASCII呢),输入汉字居然不是乱码:
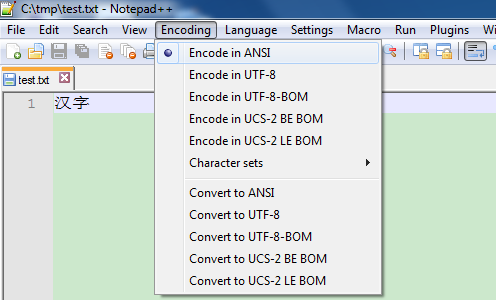
保存为test.txt,发送给你美国的同事Bob。他也用Notepad++,不幸的是,却发现你的文件内容是这样的:
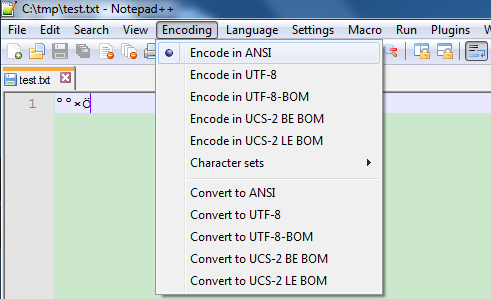
也许你会认为:你用的是中文系统,能正常显示中文;他用的是英文系统,不能显示中文!
这么想,好像很有道理呢!
但是再细想一下:一个系统显示乱码,说明它不支持这种编码格式(或者解码方式不对)。难道英文系统不支持ANSI?难道ANSI是一种中文编码?
如果你身边有一个韩文系统,也装一个Notepad++,默认还是ANSI编码,你可以输入“한국어”,发现也能正常显示:
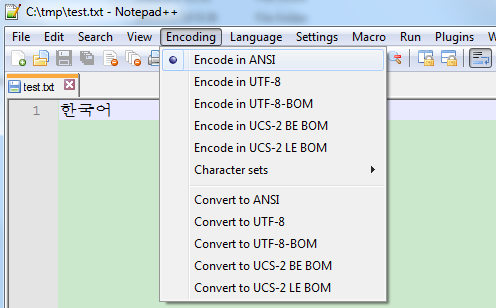
但是你要输入“汉字”可能就会发现是乱码了...
通过这个反例,就可以说明ANSI不是一种中文编码。那么,ANSI到底是什么编码?
用十六进制编辑器打开内容为“汉字”的test.txt文件:

你会发现:其中baba和d7d6正好是“汉”和“字”两个字的GBK编码值。
同样,用十六进制编辑器打开内容为“한국어”的test.txt文件:

你会发现:其中c7d1、b1b9和beee正好是“한”、“국”和“어”三个字符的EUC-KR编码值。
由此可以看出:其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
5、QString中的编码
QString中只存放unicode的utf16编码的字符串,内部用QChar(short)类型的指针进行保存。如果非要使用utf-8或ansi编码的字符串操作类,可以使用QLatin1String类。也可以考虑使用QByteArray类甚至std::string。
char*变量在内存中存放的字符串默认编码,与编译器参数 execution-charset有关,而vs2015及以下编译器默认为 "/execution-charset=GB2312",也就是char*变量内存中保存时使用ansi(具体为GB2312)编码,vs2022默认为 "/execution-charset=UTF-8",gcc或类gcc编译器默认为 "-fexec-charset=UTF-8",特就是char*使用unicode的utf8编码。可以通过在字符串前加u8强制编译器对某个char*变量在内存中保存时采用unicode的utf8编码。
char*转换成QString,一定会做一次字符编码的转码!!!通过QString(const char*)构造的QString对象,char*字符串会被QString强制当成unicode的 utf8编码,这是QString代码不可更改的,并隐式的将这个强制当做unicode 的utf8编码的字符串转换成unicode的utf16编码的字符串。vs编译器 的 execution-charset 默认 为ansi编码,存放的编码为ansi编码,如果你qt工程采用vs2015编译器或以下编译器,这时候强制当做unicode的utf8转换成QString,就一定会乱码,(所以这个时候最好设置"/execution-charset=UTF-8"的编译器参数)。QString 官方不建议使用从char*转QString的构造函数。所以在这个构造函数前加了QT_ASCII_CAST_WARN 宏开关和宏提示。QString中所有的从char*转换到QString的构造函数 或者 由char*隐式转换到QString的函数 或者 参数中含有char*的非static函数 都是隐式调用QString::fromUtf8(char*) 这个静态函数 进行字符编码的转换的。从QByteArray转QString 与 char*转QString 是一样,也会出现同样的问题。
从char*转到QString ,QString有提供很多的static类型的转码函数,qt建议通过调用这些函数进行显示的编码转换。
D:\Qt\Qt5.12.0\5.12.0\mingw73_64\include\QtCore\qstring.h
static inline QString fromLatin1(const QByteArray &str)//从ascii编码转unicode的utf16编码
{ return str.isNull() ? QString() : fromLatin1(str.data(), qstrnlen(str.constData(), str.size())); }
static inline QString fromUtf8(const QByteArray &str) //从unicode8的编码转换成unicode的utf16编码
{ return str.isNull() ? QString() : fromUtf8(str.data(), qstrnlen(str.constData(), str.size())); }
static inline QString fromLocal8Bit(const QByteArray &str) //从local编码转换虫unicode的utf16编码
{ return str.isNull() ? QString() : fromLocal8Bit(str.data(), qstrnlen(str.constData(), str.size())); }
static QString fromUtf16(const ushort *, int size = -1); //从unicode的utf16编码转unicode的utf16编码,可以在字符串前存放BOM来指定输入的字符串字节序,否则采用系统默认字节序
static QString fromUcs4(const uint *, int size = -1); //从unicode的utf32编码转unicode的utf16编码,可以在字符串前存放BOM来指定输入的字符串字节序,否则采用系统默认字节序
#if defined(Q_COMPILER_UNICODE_STRINGS)
static QString fromUtf16(const char16_t *str, int size = -1)
{ return fromUtf16(reinterpret_cast<const ushort *>(str), size); }
static QString fromUcs4(const char32_t *str, int size = -1)
{ return fromUcs4(reinterpret_cast<const uint *>(str), size); }
#endif
QString::fromUtf8(char*) 转码失败是不会给提示的,但是会将不认识的字节 转成 0xfffd。
如果你将ansi编码的字符串传入, 比如ansi编码的 "你好" 传入,其ansi(GB2312)编码为0xC4E3 0xBAC3 ,会得到由四个0xfffd的QChar组成的QString。
下面的案例中,使用windows下qt5.12+vs2015编译器的场景,采用默认的excution-charset(默认值为GB2312)和source-charset(默认值为GB2312)编译器参数,源文件编码为带BOM的utf8(vs编译器能通过BOM识别到文件为utf8编码,并自动将source-charset设置为utf8编码),QTextCodec为 system编码(在我电脑上也就是ansi(GB2312)),excution-charset为默认的ansi(GB2312)编码。
代码中QString类型的str1和str2都存在隐式地将ansi编码的字符串通过fromutf8() 转变成utf16编码的字符串,utf8并不识别ansi编码的字符串,存在转码错误,且刚好"你好"中的每个字节在utf8中都是非法的,导致char数组变量中的每个字节都变成值为0xfffd的占两个字节的QChar类型数据。 当然,主要问题还是qt中可能存在大量隐式的将char*赋予QString的地方。比如我们常用的qDebug中就有。各种使用char*的地方都可能存在隐式的将chai*转QString而存在字符编码转码的隐患!

测试代码
int main(int argc, char *argv[])
{
char cstr1[]="你好c1";
char cstr2[]=u8"你好c2";
wchar_t cstr3[]=L"你好c3";
QString str1("你好1"); //存在隐式地将gb2312转换成unicode的utf16
QString str2;
str2+="你好2"; //存在隐式地将gb2312转换成unicode的utf16
qDebug()<<"你好"<<endl; //qDebug内部存在隐式的将gb2312转换成unicode的utf16
//显示将gb2312转QString所需的utf16。qt推荐的用法。
QString str3=QString::fromLocal8Bit("你好3");
//显示将Utf8转QString所需的utf16。qt推荐的用法。
QString str4=QString::fromUtf8(u8"你好4");
QString str5=QString::fromLocal8Bit(cstr1);
QString str6=QString::fromUtf8(cstr2);
ushort buffer1[6]={};
ushort buffer2[6]={};
ushort buffer3[6]={};
ushort buffer4[6]={};
memcpy(buffer1,str1.data(),str1.length()*2);
memcpy(buffer2,str2.data(),str2.length()*2);
memcpy(buffer3,str3.data(),str3.length()*2);
memcpy(buffer4,str4.data(),str4.length()*2);
//设置控制台接收ansi(gb2312)编码的字符串。936是windows中GB2312字符编码的代码。
system("chcp 936");
cout<<cstr1<<endl;
qDebug().noquote()<<str1;
qDebug().noquote()<<str2;
qDebug().noquote()<<str3;
qDebug().noquote()<<str4;
qDebug().noquote()<<str5;
qDebug().noquote()<<str6;
return 0;
}
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qiushangren/article/details/136617718
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-NC-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/jackgo73/article/details/130225319
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
笔者之前写过utf-8的博客【点击】
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/hherima/article/details/50801360