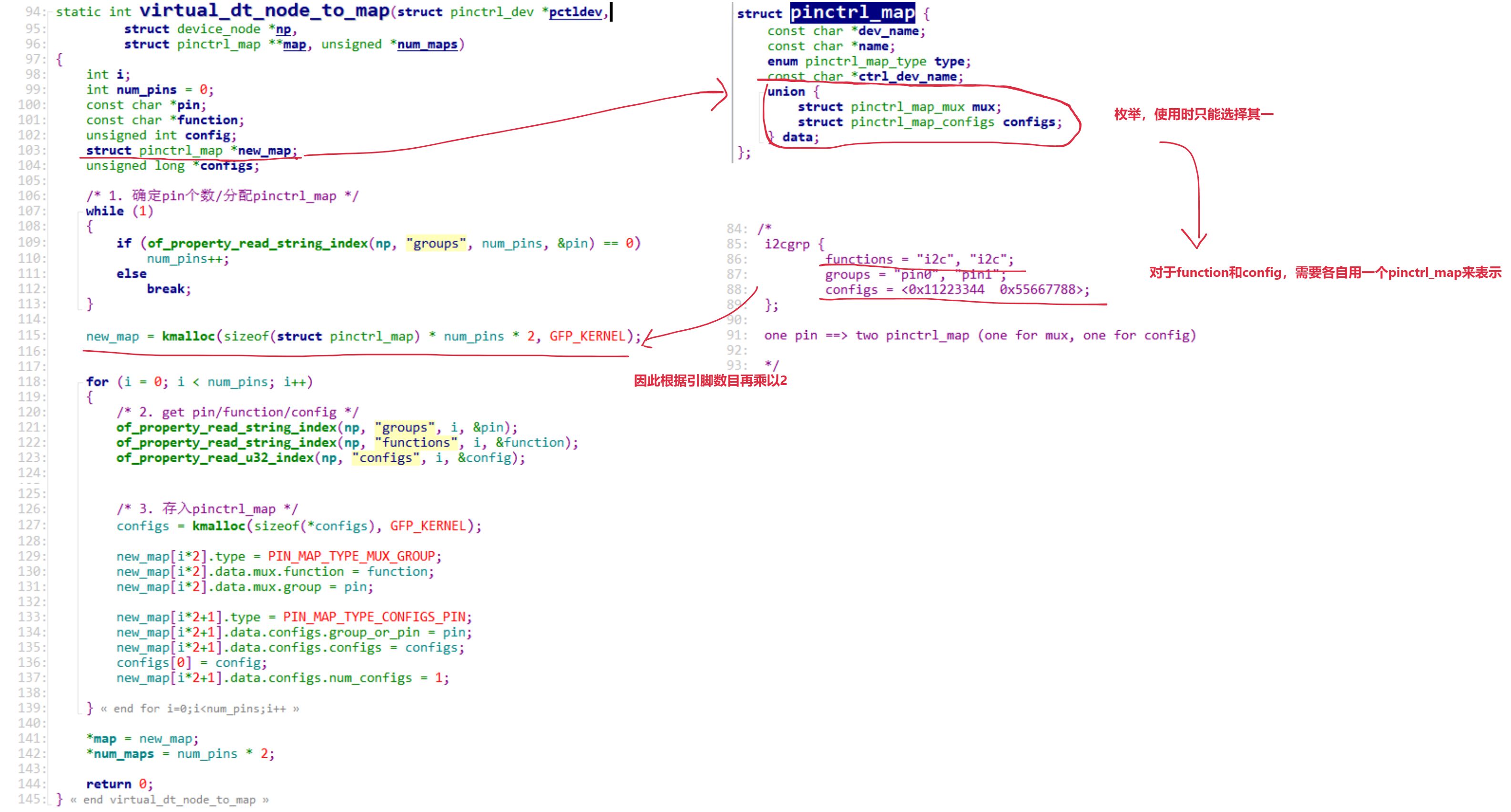
一、什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (𝑥,𝑦) ,表示从原点 (0,0)到点 (𝑥,𝑦)的有向线段。
1.1、文本向量
1、将文本转成一组 𝑁 维浮点数,即文本向量又叫 Embeddings。
2、向量之间可以计算距离,距离远近对应语义相似度大小。

1.2、向量相似度计算

相似度计算过程中:欧式距离越小越好,余弦距离越大越好。
import numpy as np
from numpy import dot
from numpy.linalg import normfrom openai import OpenAI
import os
# 加载环境变量
client = OpenAI(api_key="模型key",base_url='模型的base_url')
def cos_sim(a, b):'''余弦距离 -- 越大越相似'''return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):'''欧氏距离 -- 越小越相似'''x = np.asarray(a)-np.asarray(b)return norm(x)
def get_embeddings(texts, model="text-embedding-3-large", dimensions=None):'''封装 OpenAI 的 Embedding 模型接口'''if model == "text-embedding-ada-002":dimensions = Noneif dimensions:data = client.embeddings.create(input=texts, model=model, dimensions=dimensions).dataelse:data = client.embeddings.create(input=texts, model=model).datareturn [x.embedding for x in data]
test_query = ["测试文本"]
vec = get_embeddings(test_query)[0]# query = "国际争端"
# 且能支持跨语言
query = "global conflicts"documents = ["联合国就苏丹达尔富尔地区大规模暴力事件发出警告","土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判","日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤","国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营","我国首次在空间站开展舱外辐射生物学暴露实验",
]query_vec = get_embeddings([query])[0]doc_vecs = get_embeddings(documents)print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in doc_vecs:print(cos_sim(query_vec, vec))print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:print(l2(query_vec, vec))

1.3、 Embedding 模型
2024 年 1 月 25 日,OpenAI 新发布了两个 Embedding 模型:text-embedding-3-large和text-embedding-3-small。其最大特点是,支持自定义的缩短向量维度,从而在几乎不影响最终效果的情况下降低向量检索与相似度计算的复杂度。通俗的说:越大越准、越小越快。

model = "text-embedding-3-large"
dimensions = 128query = "国际争端"# 且能支持跨语言
# query = "global conflicts"documents = ["联合国就苏丹达尔富尔地区大规模暴力事件发出警告","土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判","日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤","国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营","我国首次在空间站开展舱外辐射生物学暴露实验",
]query_vec = get_embeddings([query], model=model, dimensions=dimensions)[0]
doc_vecs = get_embeddings(documents, model=model, dimensions=dimensions)print("向量维度: {}".format(len(query_vec)))print()print("Query与Documents的余弦距离:")
for vec in doc_vecs:print(cos_sim(query_vec, vec))print()print("Query与Documents的欧氏距离:")
for vec in doc_vecs:print(l2(query_vec, vec))

二、向量数据库
向量数据库是专门问向量检索设计的中间件。
# !pip install chromadb
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
import chromadb
from chromadb.config import Settingsdef extract_text_from_pdf(filename, page_numbers=None, min_line_length=5):'''从 PDF 文件中(按指定页码)提取文字'''paragraphs = []buffer = ''full_text = ''# 提取全部文本for i, page_layout in enumerate(extract_pages(filename)):# 如果指定了页码范围,跳过范围外的页if page_numbers is not None and i not in page_numbers:continuefor element in page_layout:if isinstance(element, LTTextContainer):full_text += element.get_text() + '\n'# 按空行分隔,将文本重新组织成段落lines = full_text.split('\n')for text in lines:if len(text) >= min_line_length:buffer += (' '+text) if not text.endswith('-') else text.strip('-')elif buffer:paragraphs.append(buffer)buffer = ''if buffer:paragraphs.append(buffer)return paragraphsclass MyVectorDBConnector:def __init__(self, collection_name, embedding_fn):chroma_client = chromadb.Client(Settings(allow_reset=True))
# chroma_client = chromadb.HttpClient(host='localhost', port=8000)# 为了演示,实际不需要每次 reset()
# chroma_client.reset()# 创建一个 collectionself.collection = chroma_client.get_or_create_collection(name=collection_name)self.embedding_fn = embedding_fndef add_documents(self, documents):'''向 collection 中添加文档与向量'''self.collection.add(embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)def search(self, query, top_n):'''检索向量数据库'''results = self.collection.query(query_embeddings=self.embedding_fn([query]),n_results=top_n)return results# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(paragraphs)user_query = "Llama 2有多少参数"
results = vector_db.search(user_query, 2)for para in results['documents'][0]:print(para+"\n")

澄清几个概念:
1、向量数据库的意义是快速的检索
2、向量数据库本身不生成向量,向量是由Embedding 模型产生的
3、向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
2.1、主流向量数据库
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
2.2、基于向量检索的RAG
class RAG_Bot:def __init__(self, vector_db, llm_api, n_results=2):self.vector_db = vector_dbself.llm_api = llm_apiself.n_results = n_resultsdef chat(self, user_query):# 1. 检索search_results = self.vector_db.search(user_query, self.n_results)# 2. 构建 Promptprompt = build_prompt(prompt_template, context=search_results['documents'][0], query=user_query)# 3. 调用 LLMresponse = self.llm_api(prompt)return response# 创建一个RAG机器人
bot = RAG_Bot(vector_db,llm_api=get_completion
)user_query = "llama 2有多少参数?"response = bot.chat(user_query)print(response)

2.3、国产大模型
import json
import requests
import os# 通过鉴权接口获取 access tokendef get_access_token():"""使用 AK,SK 生成鉴权签名(Access Token):return: access_token,或是None(如果错误)"""url = "https://aip.baidubce.com/oauth/2.0/token"params = {"grant_type": "client_credentials","client_id": os.getenv('ERNIE_CLIENT_ID'),"client_secret": os.getenv('ERNIE_CLIENT_SECRET')}return str(requests.post(url, params=params).json().get("access_token"))# 调用文心千帆 调用 BGE Embedding 接口def get_embeddings_bge(prompts):url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/embeddings/bge_large_en?access_token=" + get_access_token()payload = json.dumps({"input": prompts})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload).json()data = response["data"]return [x["embedding"] for x in data]# 调用文心4.0对话接口
def get_completion_ernie(prompt):url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token=" + get_access_token()payload = json.dumps({"messages": [{"role": "user","content": prompt}]})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload).json()return response["result"]# 创建一个向量数据库对象
new_vector_db = MyVectorDBConnector("demo_ernie",embedding_fn=get_embeddings_bge
)
# 向向量数据库中添加文档
new_vector_db.add_documents(paragraphs)# 创建一个RAG机器人
new_bot = RAG_Bot(new_vector_db,llm_api=get_completion_ernie
)user_query = "how many parameters does llama 2 have?"
response = new_bot.chat(user_query)
print(response)