文章目录
- @[toc]
- 顶部
- 1. 使用`[TOC]`自动生成
- 2. VSCode中的插件
- 3. 手搓目录
- 目录
- 相关资料
- 本文相关代码
- 一、概述
- 1.1 基本概念
- 1.2 两种处理模型
- (1)微批处理
- (2)持续处理
- 1.3 Structured Streaming和Spark SQL、Spark Streaming关系
- 二、编写Structured Streaming程序的基本步骤
- 三、输入源
- 3.1 File源
- (1)创建程序生成JSON格式的File源测试数据
- (2)创建程序对数据进行统计
- (3)测试运行程序
- (4)处理警告
- (5)总结分析
- 3.2 Kafka源
- (1)启动Kafka
- (2)编写生产者(Producer)程序
- (3)安装Python3的Kafka支持
- (4)运行生产者程序
- (5)编写并运行消费者(Consumer)程序
- 方式一
- 方式二
- 总结
- 3.3 Socket源
- 3.4 Rate源
- surprise
文章目录
- @[toc]
- 顶部
- 1. 使用`[TOC]`自动生成
- 2. VSCode中的插件
- 3. 手搓目录
- 目录
- 相关资料
- 本文相关代码
- 一、概述
- 1.1 基本概念
- 1.2 两种处理模型
- (1)微批处理
- (2)持续处理
- 1.3 Structured Streaming和Spark SQL、Spark Streaming关系
- 二、编写Structured Streaming程序的基本步骤
- 三、输入源
- 3.1 File源
- (1)创建程序生成JSON格式的File源测试数据
- (2)创建程序对数据进行统计
- (3)测试运行程序
- (4)处理警告
- (5)总结分析
- 3.2 Kafka源
- (1)启动Kafka
- (2)编写生产者(Producer)程序
- (3)安装Python3的Kafka支持
- (4)运行生产者程序
- (5)编写并运行消费者(Consumer)程序
- 方式一
- 方式二
- 总结
- 3.3 Socket源
- 3.4 Rate源
- surprise
顶部
1. 使用[TOC]自动生成
在文档开头第一行单独输入[TOC],Markdown编辑器就会根据文档中的标题层级自动生成目录。在博客园和csdn中可以通过此方法来实现自动生成目录(为了演示,本文开头的目录就是使用[TOC]所生成),但是要**注意[TOC] 通常会生成文档中所有标题的目录。如果读者只想生成指定标题的目录(例如,前三个标题),可以手动创建一个自定义的目录,而不是使用自动生成的功能。
==默认在GitHub中并不支持TOC的自动生成目录**==
2. VSCode中的插件
首先得有VSCode,在VSCode中下载Markdown All in One插件(使用Markdown All in One或Markdown Preview Enhanced皆可,此处以Markdown All in One为例)后,将需要编辑的Markdown文档使用VSCode打开进行编辑,按下万能键CTRL+SHIFT+P 或 F1,输入Markdown All in One: Create Table of Contents后回车即可
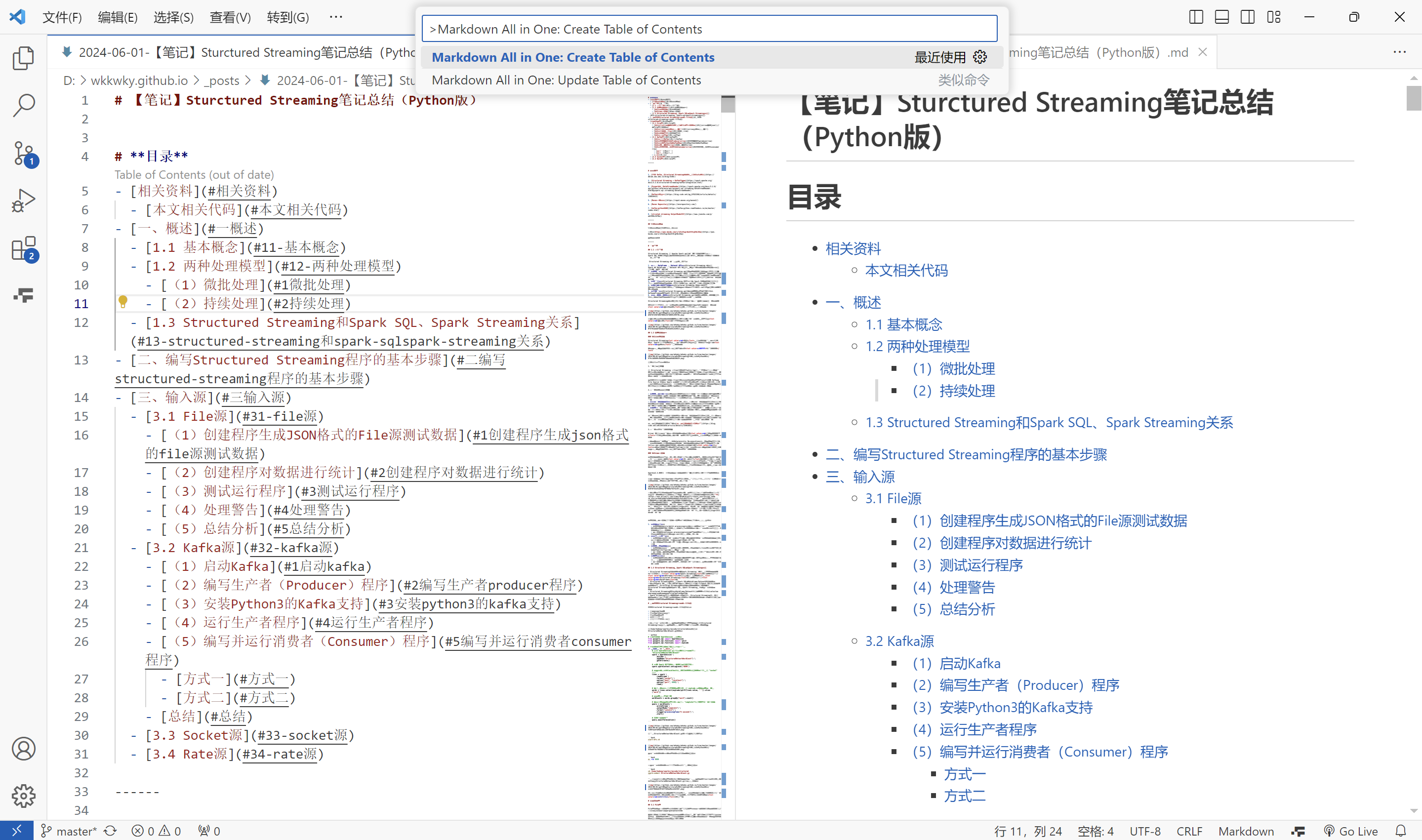
该插件适用于GitHub中的Markdown的语法结构
现附上插件GitHub链接
v3.6.2下载链接
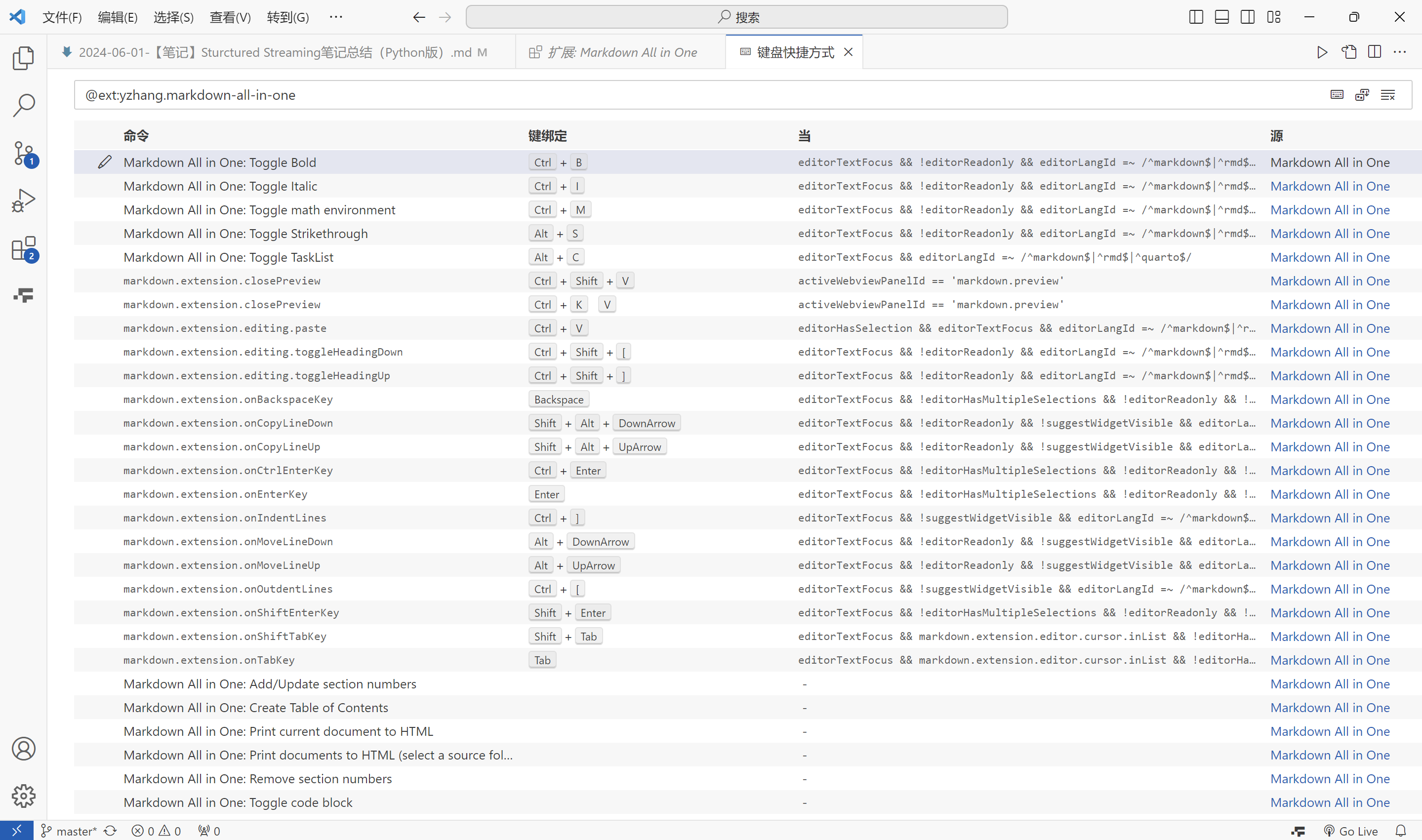
插件键盘快捷方式:
3. 手搓目录
接下来介绍如何手搓适用于GitHub的Markdown的结构的目录😎
以下为笔者的拙见,如有错误,请同志不吝指教
首先在编写目录之前请笔者明确目录结构
可以使用无序列表来实现目录的层级结构,之后就是创建链接锚点(每一个标题都是一个锚点),在目录的无序列表结构中使用[回到顶部](#顶部)这样的结构来链接到顶部标题,同理,链接到其他标题也是如此结构,如下:
| 语法 | 效果 |
|---|---|
[回到顶部](#顶部) | 回到顶部 |
简单总结一下在GitHub编写README.md文件的规律总结:
-
标题处理:
- 若标题为纯中文或中英文结合,无标点等特殊字符,直接用
#加上标题名称,例如:# 一概述对应[一、概述](#一概述)。
- 若标题为纯中文或中英文结合,无标点等特殊字符,直接用
-
特殊符号处理:
- 若标题中包含中文符号如
、或()等标点,则在链接中忽略这些标点,例如:# (1)微批处理对应[(1)微批处理](#1微批处理)。
- 若标题中包含中文符号如
-
数字结构处理:
- 对于标题中含有类似
1.1这样的结构,可以在链接中忽略.或者吧.用-代替,例如:# 1.1 基本概念对应[1.1 基本概念](#11-基本概念)或[1.1 基本概念](#1-1-基本概念)。
- 对于标题中含有类似
-
空格处理:
- 标题中的空格在链接中用
-替代,例如:# 3.2 Kafka源对应[3.2 Kafka源](#32-kafka源)。
- 标题中的空格在链接中用
-
保持一致性:
- 所有链接都采用小写字母和连字符风格,确保在Markdown中保持一致的链接格式。
下面结合一个实例来看:
目录
- 相关资料
- 本文相关代码
- 一、概述
- 1.1 基本概念
- 1.2 两种处理模型
- (1)微批处理
- (2)持续处理
- 1.3 Structured Streaming和Spark SQL、Spark Streaming关系
- 二、编写Structured Streaming程序的基本步骤
- 三、输入源
- 3.1 File源
- (1)创建程序生成JSON格式的File源测试数据
- (2)创建程序对数据进行统计
- (3)测试运行程序
- (4)处理警告
- (5)总结分析
- 3.2 Kafka源
- (1)启动Kafka
- (2)编写生产者(Producer)程序
- (3)安装Python3的Kafka支持
- (4)运行生产者程序
- (5)编写并运行消费者(Consumer)程序
- 方式一
- 方式二
- 总结
- 3.3 Socket源
- 3.4 Rate源
- 3.1 File源
相关资料
相关资料内容
本文相关代码
本文相关代码内容
一、概述
概述内容
1.1 基本概念
基本概念内容
1.2 两种处理模型
两种处理模型内容
(1)微批处理
微批处理内容
(2)持续处理
持续处理内容
1.3 Structured Streaming和Spark SQL、Spark Streaming关系
Structured Streaming和Spark SQL、Spark Streaming关系内容
二、编写Structured Streaming程序的基本步骤
编写Structured Streaming程序的基本步骤内容
三、输入源
输入源内容
3.1 File源
File源内容
(1)创建程序生成JSON格式的File源测试数据
创建程序生成JSON格式的File源测试数据内容
(2)创建程序对数据进行统计
创建程序对数据进行统计内容
(3)测试运行程序
测试运行程序内容
(4)处理警告
处理警告内容
(5)总结分析
总结分析内容
3.2 Kafka源
Kafka源内容
(1)启动Kafka
启动Kafka内容
(2)编写生产者(Producer)程序
编写生产者(Producer)程序内容
(3)安装Python3的Kafka支持
安装Python3的Kafka支持内容
(4)运行生产者程序
运行生产者程序内容
(5)编写并运行消费者(Consumer)程序
编写并运行消费者(Consumer)程序内容
方式一
方式一内容
方式二
方式二内容
总结
总结内容
3.3 Socket源
Socket源内容
3.4 Rate源
Rate源内容
上述内容的markdown代码为:
# **目录**
- [相关资料](#相关资料)- [本文相关代码](#本文相关代码)
- [一、概述](#一概述)- [1.1 基本概念](#11-基本概念)- [1.2 两种处理模型](#12-两种处理模型)- [(1)微批处理](#1微批处理)- [(2)持续处理](#2持续处理)- [1.3 Structured Streaming和Spark SQL、Spark Streaming关系](#13-structured-streaming和spark-sqlspark-streaming关系)
- [二、编写Structured Streaming程序的基本步骤](#二编写structured-streaming程序的基本步骤)
- [三、输入源](#三输入源)- [3.1 File源](#31-file源)- [(1)创建程序生成JSON格式的File源测试数据](#1创建程序生成json格式的file源测试数据)- [(2)创建程序对数据进行统计](#2创建程序对数据进行统计)- [(3)测试运行程序](#3测试运行程序)- [(4)处理警告](#4处理警告)- [(5)总结分析](#5总结分析)- [3.2 Kafka源](#32-kafka源)- [(1)启动Kafka](#1启动kafka)- [(2)编写生产者(Producer)程序](#2编写生产者producer程序)- [(3)安装Python3的Kafka支持](#3安装python3的kafka支持)- [(4)运行生产者程序](#4运行生产者程序)- [(5)编写并运行消费者(Consumer)程序](#5编写并运行消费者consumer程序)- [方式一](#方式一)- [方式二](#方式二)- [总结](#总结)- [3.3 Socket源](#33-socket源)- [3.4 Rate源](#34-rate源)# 相关资料
相关资料内容# 本文相关代码
本文相关代码内容# 一、概述
概述内容## 1.1 基本概念
基本概念内容## 1.2 两种处理模型
两种处理模型内容### (1)微批处理
微批处理内容### (2)持续处理
持续处理内容## 1.3 Structured Streaming和Spark SQL、Spark Streaming关系
Structured Streaming和Spark SQL、Spark Streaming关系内容# 二、编写Structured Streaming程序的基本步骤
编写Structured Streaming程序的基本步骤内容# 三、输入源
输入源内容## 3.1 File源
File源内容### (1)创建程序生成JSON格式的File源测试数据
创建程序生成JSON格式的File源测试数据内容### (2)创建程序对数据进行统计
创建程序对数据进行统计内容### (3)测试运行程序
测试运行程序内容### (4)处理警告
处理警告内容### (5)总结分析
总结分析内容## 3.2 Kafka源
Kafka源内容### (1)启动Kafka
启动Kafka内容### (2)编写生产者(Producer)程序
编写生产者(Producer)程序内容### (3)安装Python3的Kafka支持
安装Python3的Kafka支持内容### (4)运行生产者程序
运行生产者程序内容### (5)编写并运行消费者(Consumer)程序
编写并运行消费者(Consumer)程序内容#### 方式一
方式一内容#### 方式二
方式二内容### 总结
总结内容## 3.3 Socket源
Socket源内容## 3.4 Rate源
Rate源内容
🤡笔者发布文章后3分钟续写🤡
emm,笔者试了一下,笔者在编辑该文章时(即在编辑页面)是可以实现链接锚点跳转的,但不知为何,发布该文章后进入文章进行读取时无法实现通过手动编写的目录进行跳转,但是通过[TOC]生成的目录可以进行跳转。。。━━( ̄ー ̄*|||━━🤡👈🤣
笔者初步分析是因为笔者在写作时是在Markdown编辑器中进行的,所以使用markdown语法在编辑器中可以实现跳转功能,但是一旦发布后通过网页进行阅读并跳转时,网页是根据地址栏中的链接的参数进行定位的,故在阅读文章时能通过[TOC]生成的目录在浏览器中阅读时可以进行跳转,而不能通过使用手动编写的目录链接进行跳转。
如下:
点击[TOC]生成的目录进行跳转到1.1 基本概念时地址栏链接为https://www.cnblogs.com/wkkwk/p/18523776#tid-Wp58ZW
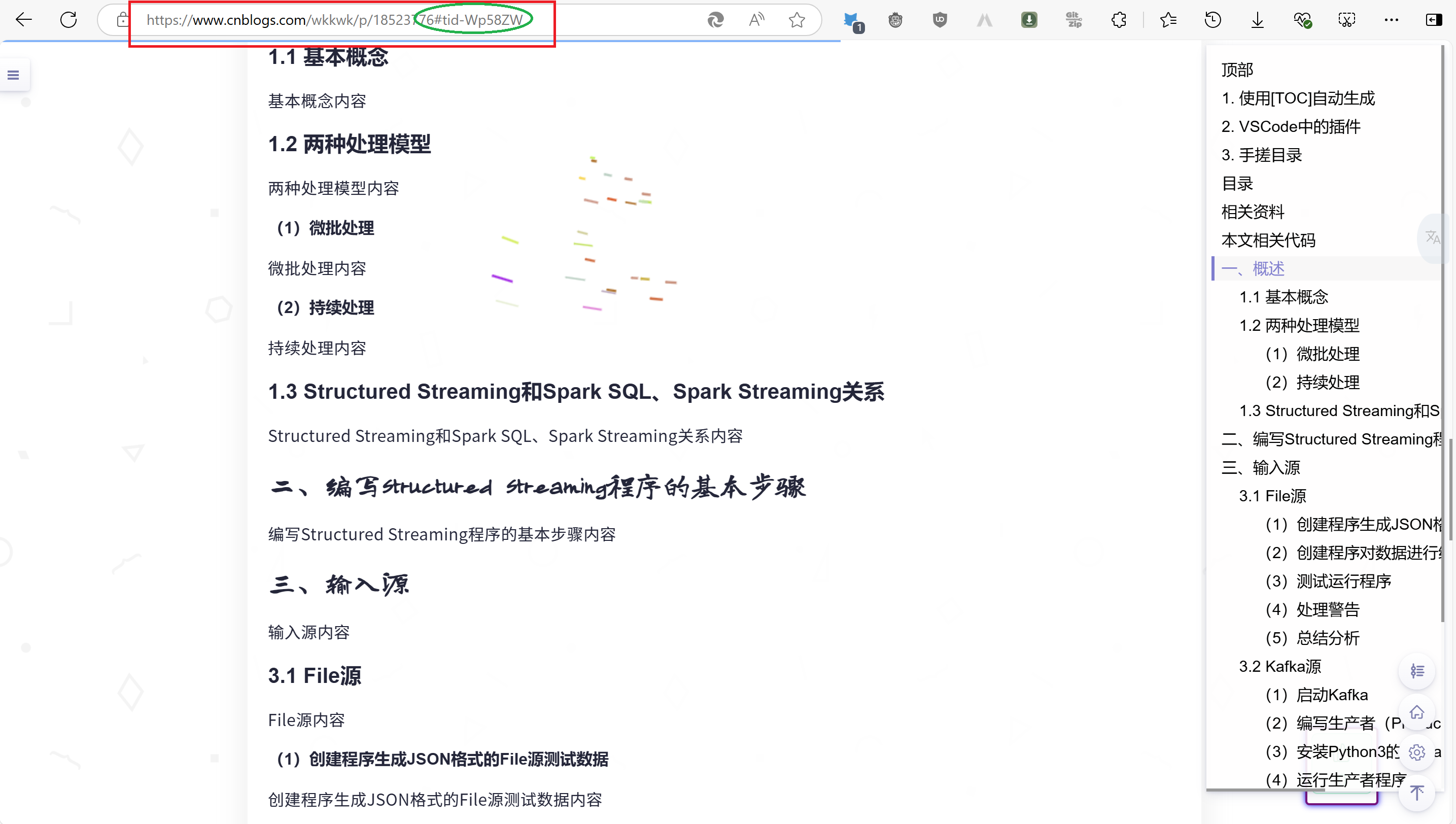
而使用手动编写的目录链接进行跳转到1.1 基本概念时地址栏链接为
https://www.cnblogs.com/wkkwk/p/18523776#11-基本概念
但是复制出来粘贴到记事本为
https://www.cnblogs.com/wkkwk/p/18523776#11-%E5%9F%BA%E6%9C%AC%E6%A6%82%E5%BF%B5
上述现象是由于URL编码造成的。在浏览器地址栏中,某些字符(例如中文字符和空格)会以可读的方式显示,而在实际的URL中,这些字符会被编码为特定的格式。(可以认为它俩是等价的)
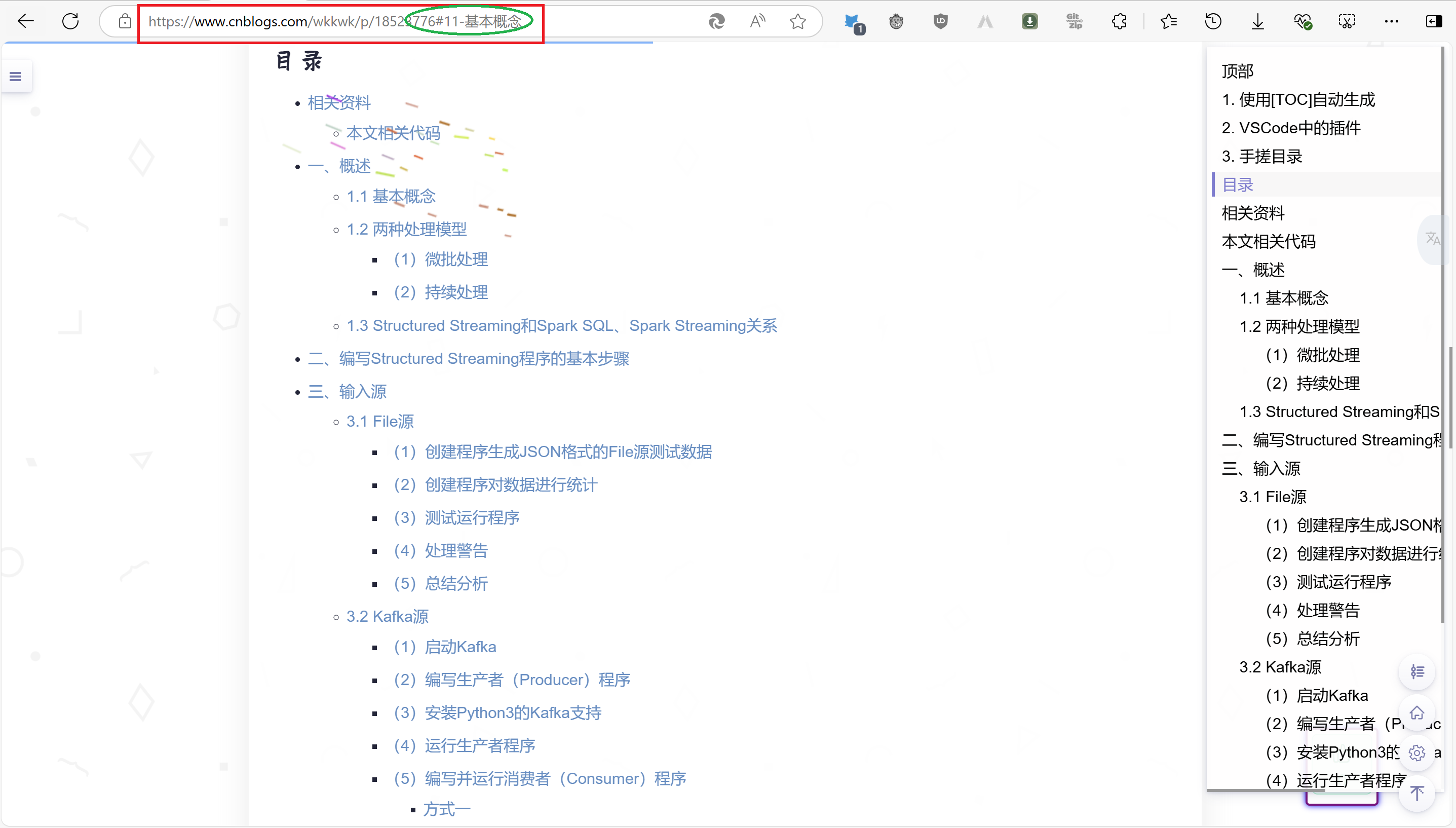
写到这里,我突然有个想法,我将https://www.cnblogs.com/wkkwk/p/18523776#11-基本概念复制到新开的标签页的地址栏中,ai~,您猜怎么着,他跳转了到了对应标题处🤣🤣🤣,如下:
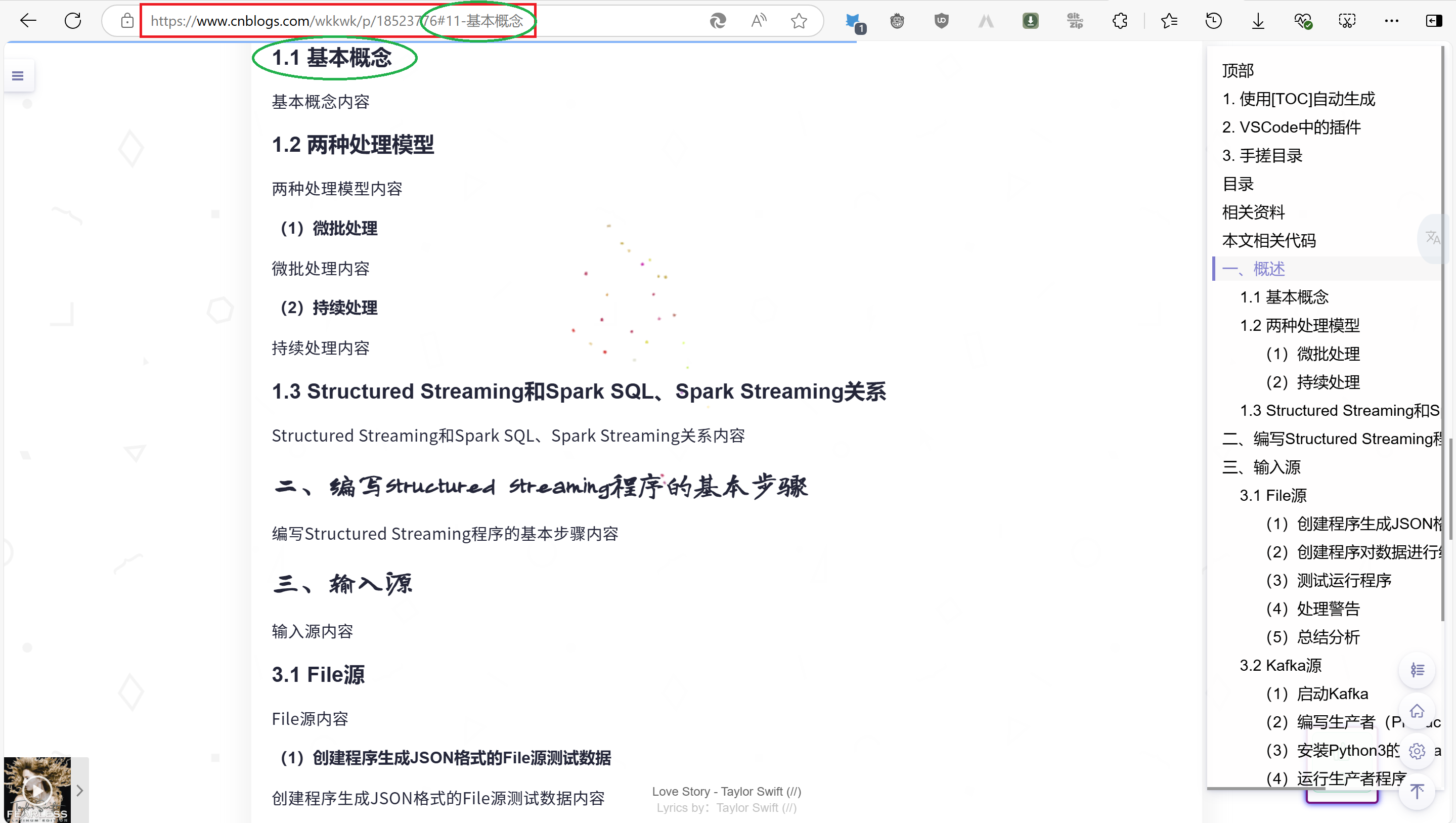
我心里顿时一万个cnm飘过,好在结果是好的,证明笔者写作的思路和内容是没有问题的🙆(❁´◡`❁)🙆
读者可以将文末代码块中的markdown代码复制到VSCode或Typora中进行测试!!!
surprise
笔者在此将家底双手奉上😎(❤️´艸`❤️),下列是一些有助于读者了解并熟练掌握Markdown语法与结构的网站分享:
Markdown教程|菜鸟教程
Markdown 基本语法
Markdown 基本语法 | Markdown 官方教程
README文件语法解读,即Github Flavored Markdown语法介绍
Markdown Emoji表情
同时也分享一个RGB颜色代码表🎨
![[ shell 脚本实战篇 ] 编写恶意程序实现需求(恶意程序A监测特定目录B出现特定文件C执行恶意操作D-windows)](https://i-blog.csdnimg.cn/direct/e246ae794fff4be8847641acf99c07cb.png)