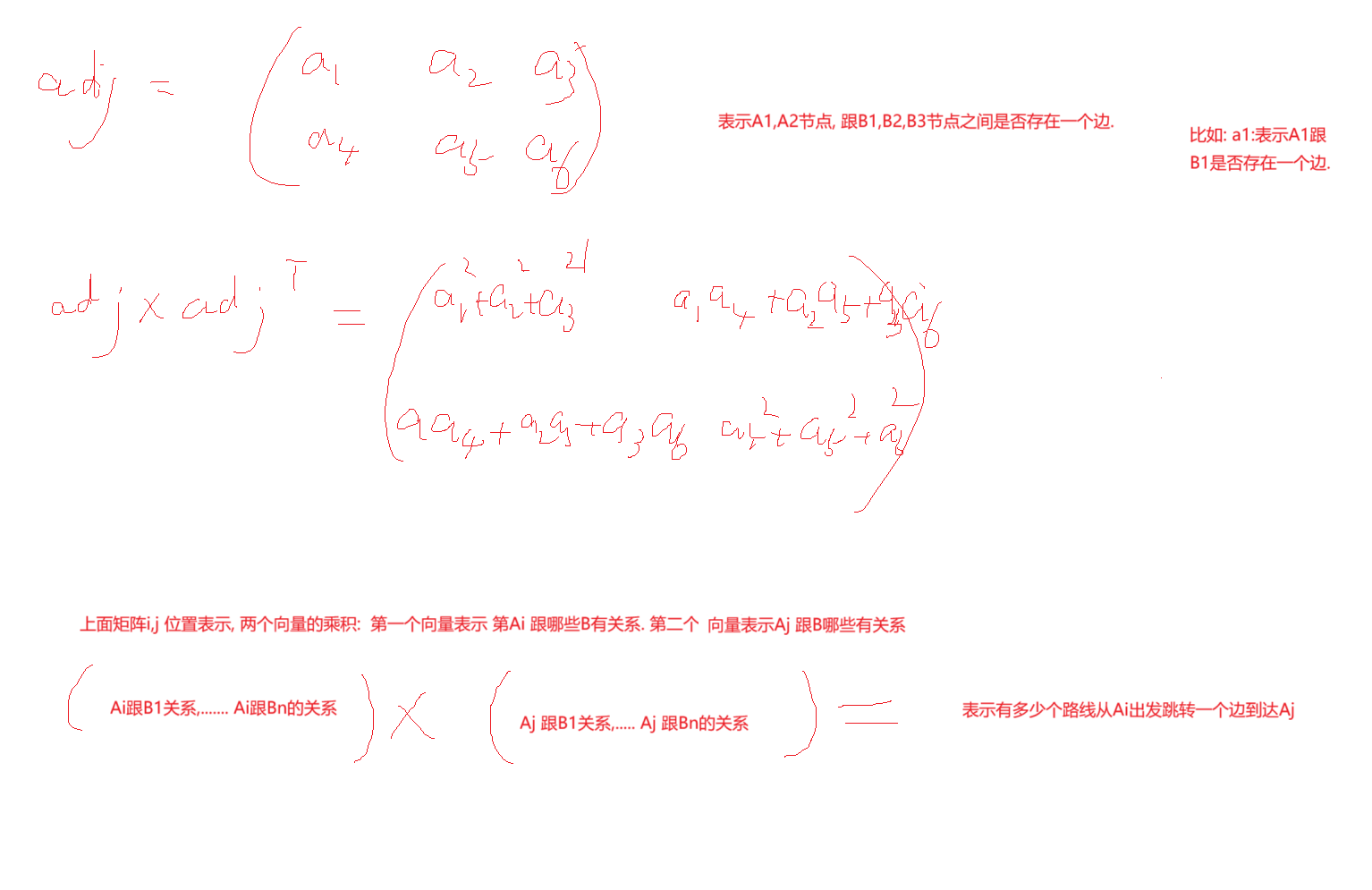在 Django 中,aggregate() 和 annotate() 是两个常用的聚合函数。它们都可以用来对一组查询结果进行聚合操作,但它们的作用是有所不同的。
aggregate() 是用于聚合整个查询集的结果,通常用于返回一个值,例如计算查询集中所有结果的数量、平均值、最大值或最小值等。使用 aggregate() 函数时,需要用到 SQL 中的聚合函数(如 Count、Sum、Min、Max、Avg 等) 返回的是字典
from django.db.models import Count
from myapp.models import MyModel# 统计所有模型对象的数量
obj_count = MyModel.objects.aggregate(obj_count=Count('id'))# 输出结果
print(obj_count)annotate() 的作用是对数据库中每一行进行聚合操作,并返回一个新的查询集,通常用于计算每个分组的聚合值。使用 annotate() 函数时,需要用到 SQL 中的 GROUP BY 语句。返回的是queryset 。filter在annotate()函数前是筛选后分组,在annotate()函数后是分组后过滤类似与group by 后的having
from django.db.models import Count
from myapp.models import MyModel# 统计每个分类下的记录数量
category_count = MyModel.objects.values('category').annotate(cat_count=Count('id'))# 输出结果
print(category_count)使用 values() 函数指定要分组的字段 category,然后使用 Count 函数对 id 字段进行聚合操作,并为结果起一个别名 cat_count。
如何使用aggregate函数
Django还提供了另外两种统计查询方法,首先来看看aggregate:
SELECTCOUNT(id) AS id__count
FROMauth_user;from django.db.models import CountUser.objects.aggregate(Count('id'))为了使用aggregate,我们导入了Count函数,aggregate以另外一个实现统计查询的表达式为参数,在本例中,我们使用主键id来查询数据库表中的行的数量。
aggregate的结果是一个字典对象:
>>> from django.db.models import Count
>>> User.objects.aggregate(Count('id'))
{"id__count": 891}键的名称是从字段的名称和查询函数的名称派生的,在本例中,键名是id__count。我们最好不要使用这样的命名方式,而是要自己设定名称:
SELECTCOUNT(id) as total
FROMauth_user;>>> from django.db.models import Count
>>> User.objects.aggregate(total=Count('id'))
{"total": 891}aggregate参数的名称,就是返回值字典的键。
如何实现Group By
使用aggregate,我们得到数据表进行聚合查询结果,这很有用,但我们还希望对指定的行应用此操作。
让我们根据用户的活动状态来统计用户数:
SELECTis_active,COUNT(id) AS total
FROMauth_user
GROUP BYis_active(User.objects
.values('is_active')
.annotate(total=Count('id')))这次使用了annotate函数。我们使用values和annotate的组合来完成分组查询:
values('is_active'):分组依据annotate(total=Count('id')):要查询的内容
顺序很重要:如果在annotate之前调用values失败,不会产生查询结果。
与aggregate一样,annotate的参数名称是QuerySet返回值的键,示例中就是total。
分组筛选
若要对筛选查询应用聚合功能,可以在查询的任何位置使用filter,例如,仅按员工用户的活动状态对其进行统计:
ELECTis_active,COUNT(id) AS total
FROMauth_user
WHEREis_staff = True
GROUP BYis_active(User.objects
.values('is_active')
.filter(is_staff=True)
.annotate(total=Count('id')))如何进行分组排序
与filter类似,要对分组结果排序,可以在查询中使用order_by:
SELECTis_active,COUNT(id) AS total
FROMauth_user
GROUP BYis_active
ORDER BYis_active,total(User.objects
.values('is_active')
.annotate(total=Count('id'))
.order_by('is_staff', 'total'))请注意:你可以按分组的关键词is_active和聚合的关键词total进行排序。
如何联合聚合查询
要生成同分组的多个聚合查询,请添加多个annotation:
SELECTis_active,COUNT(id) AS total,MAX(date_joined) AS last_joined
FROMauth_user
GROUP BYis_activefrom django.db.models import Max(User.objects
.values('is_active')
.annotate(total=Count('id'),last_joined=Max('date_joined'),
))该查询将得到活动用户和非活动用户的数量,以及用户加入每个组的最后日期。
根据多个字段进行分组
就像执行多个聚合一样,我们可能也希望根据多个字段进行分组。例如,按活动状态和人员状态分组:
SELECTis_active,is_staff,COUNT(id) AS total
FROMauth_user
GROUP BYis_active,is_staff(User.objects
.values('is_active', 'is_staff')
.annotate(total=Count('id')))此查询的结果包括is_active、is_staff和每个组中的用户数。
根据表达式分组
分组的另一个常见用例是按表达式分组。例如,统计每年加入的用户数:
SELECTEXTRACT('year' FROM date_joined),COUNT(id) AS total
FROMauth_user
GROUP BYEXTRACT('year' FROM date_joined)(User.objects
.values('date_joined__year')
.annotate(total=Count('id')))注意,为了从日期开始获取年份,我们在第一次调用values()时使用了特殊表达式<field>__year。查询的结果是一个dict,键的名称将是date_joined__year。
有时,内置表达式不够,需要在更复杂的表达式上进行聚合。例如,按注册后登录的用户分组:
SELECTlast_login > date_joined AS logged_since_joined,COUNT(id) AS total
FROMauth_user
GROUP BYlast_login > date_joinedfrom django.db.models import (ExpressionWrapper,Q, F, BooleanField,
)(User.objects
.annotate(logged_since_joined=ExpressionWrapper(Q(last_login__gt=F('date_joined')),output_field=BooleanField(),)
)
.values('logged_since_joined')
.annotate(total=Count('id'))
.values('logged_since_joined', 'total')这里的表达式相当复杂。我们首先使用annotate构建表达式,然后在下面对values()的调用中通过引用表达式将其标记为按该关键词分组。后面的代码就跟前述一样了。
根据条件聚合
根据条件,只能对组的一部分进行聚合。当有多个聚合时,条件就很有用了。例如,按注册年份统计员工用户和非员工用户的数量:
SELECTEXTRACT('year' FROM date_joined),COUNT(id) FILTER (WHERE is_staff = True) AS staff_users,COUNT(id) FILTER (WHERE is_staff = False) AS non_staff_usersFROMauth_user
GROUP BYEXTRACT('year' FROM date_joined)from django.db.models import F, Q(User.objects
.values('date_joined__year')
.annotate(staff_users=(Count('id', filter=Q(is_staff=True))),non_staff_users=(Count('id', filter=Q(is_staff=False))),
))上面的SQL来自PostgreSQL,它和SQLite是目前唯一支持FILTER语法快捷方式(正式名称为“选择性聚合”)的数据库。对于其他数据库,ORM将使用CASE ... WHEN来代替。
如何使用Having
HAVING子句用于筛选聚合函数的结果。例如,查找超过100多个用户加入的年份:
SELECTis_active,COUNT(id) AS total
FROMauth_user
GROUP BYis_active
HAVINGCOUNT(id) > 100(User.objects
.annotate(year_joined=F('date_joined__year'))
.values('is_active')
.annotate(total=Count('id'))
.filter(total__gt=100))对annotate中的total查询结果进行过滤,即后面的filter,它与SQL中的HAVING子句等效。
根据Distinct分组
对于某些聚合函数(如“COUNT”),有时只需要计算不同的出现次数。例如,每一种活动状态中的用户有多少不同的姓氏:
SELECTis_active,COUNT(id) AS total,COUNT(DISTINCT last_name) AS unique_names
FROMauth_user
GROUP BYis_active(User.objects
.values('is_active')
.annotate(total=Count('id'),unique_names=Count('last_name', distinct=True),
))注意在Count的参数中使用了distinct=True。
使用聚合字段创建表达式
聚合字段通常只是解决较大问题的第一步。例如,按用户活动状态列出的唯一姓氏的百分比是多少:
SELECTis_active,COUNT(id) AS total,COUNT(DISTINCT last_name) AS unique_names,(COUNT(DISTINCT last_name)::float/ COUNT(id)::float) AS pct_unique_names
FROMauth_user
GROUP BYis_activefrom django.db.models import FloatField
from django.db.models.functions import Cast(User.objects
.values('is_active')
.annotate(total=Count('id'),unique_names=Count('last_name', distinct=True),
)
.annotate(pct_unique_names=(Cast('unique_names', FloatField())/ Cast('total', FloatField())
))第一个annotate()定义聚合字段。第二个annotate()使用聚合函数构造表达式。
跨表分组
到目前为止,我们只是在一个模型中进行各种数据查询操作,但聚合也能在不同模型(即不同数据库表)之间实现,比较简单的情况是一对一或外键关系。例如,假设我们有一个与用户一一对应的User profile模型,并且我们希望按配置文件的类型统计用户:
SELECTp.type,COUNT(u.id) AS total
FROMauth_user uJOIN user_profile p ON u.id = p.user_id
GROUP BYp.type(User.objects
.values('user_profile__type')
.annotate(total=Count('id')))')))就像分组表达式一样,在values中使用关联表,并按该该字段分组。请注意:表示关联数据库包的名称将是user_profile__type。
根据多对多关系分组
更复杂的还是多对多的关系。例如,计算每个用户参与了多少个小组:
SELECTu.id,COUNT(ug.group_id) AS memberships
FROMauth_userLEFT OUTER JOIN auth_user_groups ug ON (u.id = ug.user_id)
GROUP BYu.id(User.objects
.annotate(memberships=Count('groups'))
.values('id', 'memberships'))用户可以是多个组的成员,要统计用户所属的组数,我们在User模型中使用了相关名称groups。如果未显式设置相关名称(且未显式禁用),Django将自动生成格式为{related model model}_set的名称。例如group_set。