平时做大模型训练的时候总是苦于没有服务器资源来做微调实验,于是这次深度体验了一下SCNet超算平台。
SCNet超算平台是一个超算互联网计算服务平台,有着更大更全更专业的超级算力。显卡从异构加速卡到A800都有。
本次我尝试了大模型的推理和微调。
第一部分:AI算力性能反馈
1、这次我分别运行了以下这几个商品。
Notebook 异构加速卡AI、Nvidia L20、Nvidia A800
2、运行的过程记录
平台直接内置了相应的AI环境,包括pytorch cuda notebook等等,可以启动后直接开始运行代码,这一点确实省了好多时间。



3、运行的结果反馈
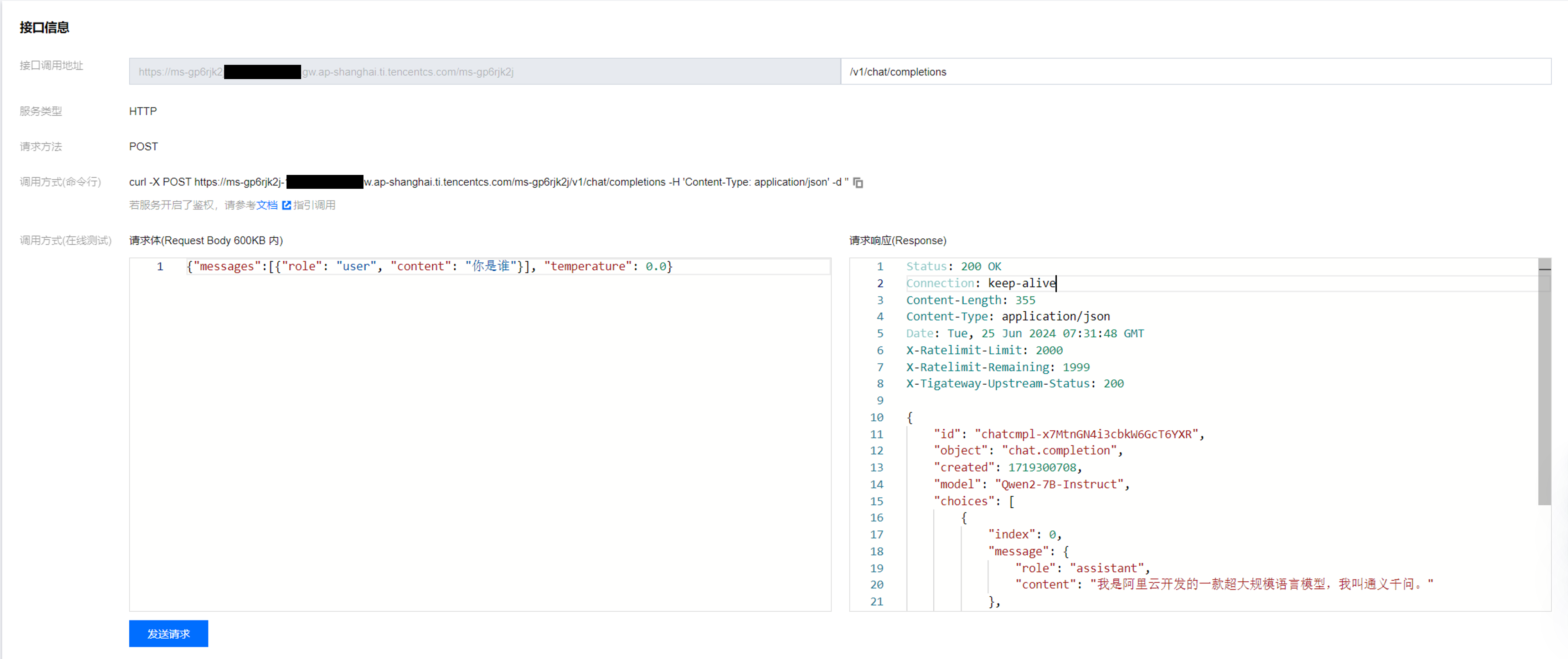
使用Nvidia L20.使用Nvidia L20推理qwen1.5-32B-AWQ量化版本,推理框架使用vllm,单次请求速度每30t/s,介于A6000 25t/s到4090的40t/s之间(我们公司使用的是A6000和4090)。


A800 vllm运行qwen1.5-32B-chat-awq速度相当快,47t/s,也可以感觉到并行处理能力会很强,基本一个问题输入后,1-2s内就能全部输出。A800 vllm运行llamma3.1-8B速度62t/s


运行自定义服务后没有关闭服务的地方
A800训练llama3.1如下图。








![[论文][环境]3DGS+Colmap环境搭建_WSL2_Ubuntu22.04 - 副本](https://img-blog.csdnimg.cn/img_convert/e1a01414e2dac51099fb43a146a938f9.png)



![[mysql]修改表和课后练习](https://i-blog.csdnimg.cn/direct/06d3c48a23c649208f201513a4fb49e9.png)





