✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。
🍎个人主页:Java Fans的博客
🍊个人信条:不迁怒,不贰过。小知识,大智慧。
💞当前专栏:Java案例分享专栏
✨特色专栏:国学周更-心性养成之路
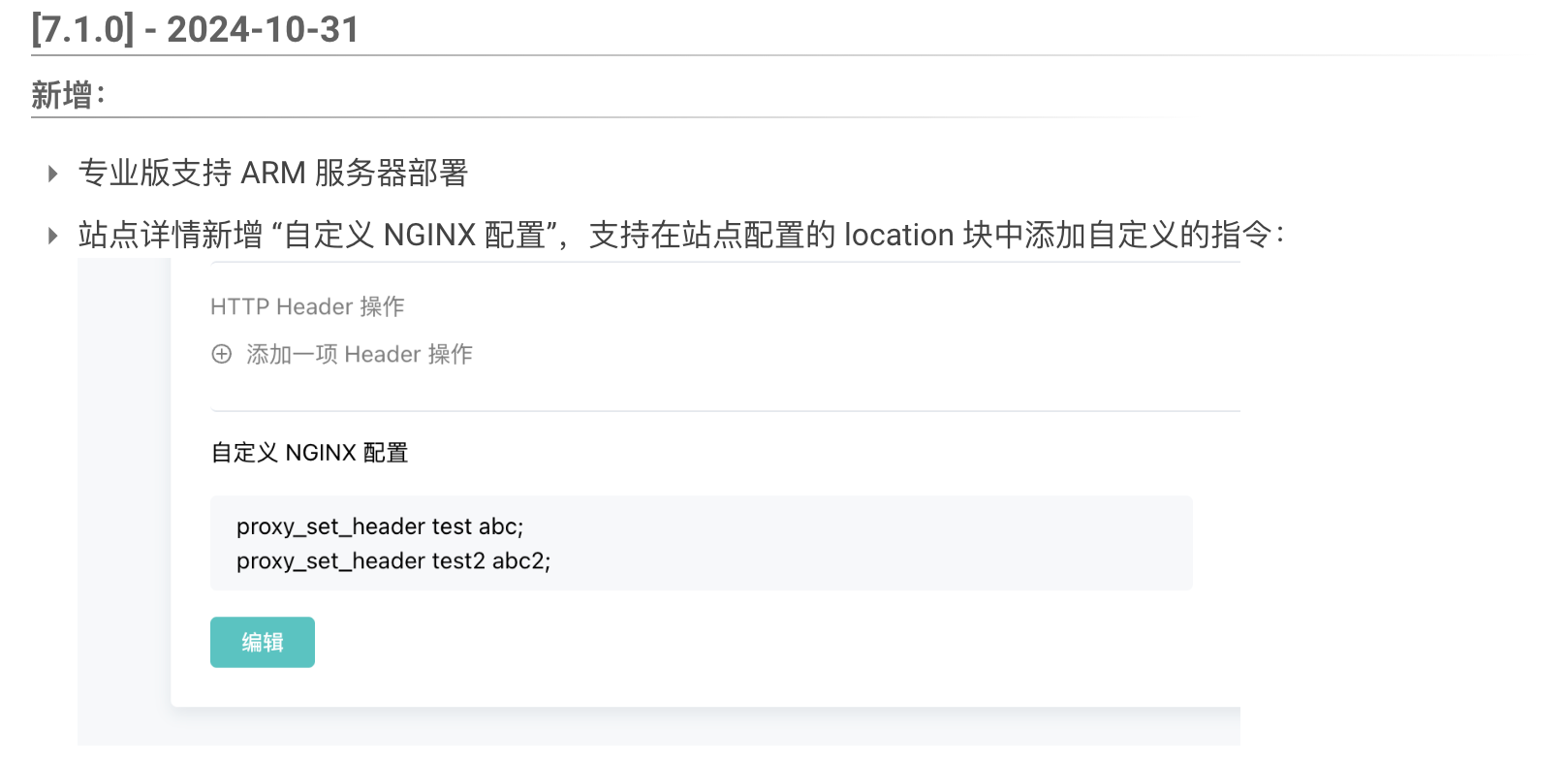
🥭本文内容:用 Vue.js 打造炫酷的动态数字画廊:展示学生作品的创意之旅
文章目录
- 引言
- 1. 项目概述
- 1.1 项目目标
- 1.2 技术架构
- 1.3 项目流程
- 1.4 预期成果
- 1.5 适用场景
- 2. 环境准备
- 2.1 安装Python
- 2.2 安装开发工具
- 2.3 创建虚拟环境
- 2.4 安装所需库
- 2.5 验证库安装
- 2.6 项目结构
- 2.7 创建`requirements.txt`
- 3. 网络请求
- 3.1 HTTP请求概述
- 3.2 使用`requests`库发送GET请求
- 3.3 设置请求头
- 3.4 处理响应
- 3.5 处理重定向
- 3.6 处理Cookies
- 3.7 处理超时
- 3.8 示例代码
- 4. 数据解析
- 5. 用户界面
- 6. 定时任务
- 6.1 安装 `schedule` 库
- 6.2 `schedule` 库基本用法
- 6.3 定时任务示例
- 6.4 将定时任务与自助抢单插件结合
- 6.5 代码详解
- 6.6 运行定时任务
- 7. 完整代码示例
- 总结
引言
在数字化时代,电子商务的迅猛发展使得消费者能够轻松地在线购买商品和服务。然而,随着竞争的加剧,许多热门商品和限量版商品在发布后瞬间被抢购一空,给消费者带来了极大的挑战。为了在这种竞争中脱颖而出,许多用户开始寻求自动化工具,以提高抢购的成功率。自助抢单插件应运而生,成为了消费者在激烈市场中获取心仪商品的重要助手。
自助抢单插件是一种自动化工具,旨在帮助用户监控特定网站上的商品或服务,并在满足特定条件时自动下单。这种工具不仅可以节省用户的时间,还能提高抢购的成功率,尤其是在面对高需求商品时。通过编写自助抢单插件,用户可以实现实时监控、数据解析和自动下单等功能,从而在瞬息万变的市场中把握机会。
本文将详细介绍如何使用Python编写一个基本的自助抢单插件。我们将从项目的整体架构入手,逐步深入到各个技术层面,包括网络请求、数据解析、用户界面设计和定时任务调度等。通过这一过程,读者将能够掌握创建自助抢单插件的基本技能,并能够根据自己的需求进行扩展和优化。
无论你是编程新手还是有经验的开发者,这篇博文都将为你提供一个清晰的思路和实用的示例,帮助你快速上手自助抢单插件的开发。让我们一起探索这个充满挑战和机遇的领域,提升我们的抢购能力,确保在竞争激烈的市场中占得先机。
1. 项目概述
在当今的电子商务环境中,消费者面临着越来越多的竞争,尤其是在抢购限量商品、热门商品或特定服务时。为了提高抢购的成功率,许多用户开始寻求自动化解决方案,以便在瞬息万变的市场中迅速反应。自助抢单插件正是为满足这一需求而设计的工具,它能够帮助用户自动监控特定网站的商品信息,并在条件满足时自动下单,从而提升用户的购物体验。
1.1 项目目标
本项目的主要目标是开发一个功能齐全的自助抢单插件,具备以下核心功能:
- 实时监控:能够定期检查指定网站的商品状态,获取最新的商品信息。
- 数据解析:从网页中提取关键信息,如商品名称、价格、库存状态等,以便用户做出决策。
- 自动下单:在满足特定条件(如价格低于某个阈值或库存状态为“有货”)时,自动提交订单。
- 用户友好的界面:提供一个简单易用的图形用户界面,让用户能够方便地输入目标网址和设置参数。
1.2 技术架构
为了实现上述目标,本项目将采用以下技术架构:
- 编程语言:使用Python作为主要开发语言,因其丰富的库和框架使得网络请求、数据解析和用户界面的实现变得更加高效。
- 网络请求:使用
requests库发送HTTP请求,以获取目标网站的HTML内容。 - 数据解析:利用
BeautifulSoup库解析HTML,提取所需的商品信息。 - 用户界面:使用
tkinter库创建图形用户界面,提供友好的用户交互体验。 - 定时任务:使用
schedule库实现定时任务,定期检查商品状态并执行相应操作。
1.3 项目流程
项目的开发流程将分为以下几个步骤:
- 需求分析:明确用户需求,确定插件的功能和特性。
- 环境搭建:安装所需的Python库和开发环境,确保开发过程顺利进行。
- 网络请求模块开发:实现从目标网站获取HTML内容的功能。
- 数据解析模块开发:编写代码解析HTML,提取商品信息。
- 用户界面设计:创建图形用户界面,允许用户输入目标网址和设置参数。
- 定时任务实现:设置定时任务,定期检查商品状态并执行下单操作。
- 测试与优化:对插件进行全面测试,确保其稳定性和可靠性,并根据用户反馈进行优化。
1.4 预期成果
通过本项目的实施,预期能够开发出一个功能完整、用户友好的自助抢单插件。用户将能够通过该插件轻松监控目标商品,并在合适的时机自动下单,从而提高抢购的成功率。此外,项目的代码和设计将为后续的扩展和优化提供良好的基础,用户可以根据自己的需求添加更多功能,如登录验证、价格提醒等。
1.5 适用场景
自助抢单插件适用于多种场景,包括但不限于:
- 限量商品抢购:如限量版鞋子、电子产品等。
- 特价商品监控:如打折促销商品,用户希望在价格下降时及时购买。
- 抢购热门活动:如门票、演唱会票等,用户希望在开售的瞬间抢购。
2. 环境准备
在开始开发自助抢单插件之前,确保你的开发环境已经正确配置是至关重要的。良好的环境准备不仅可以提高开发效率,还能减少后续调试和运行时出现的问题。以下是详细的环境准备步骤,包括软件安装、库依赖和开发工具的选择。
2.1 安装Python
首先,确保你的计算机上安装了Python。Python是一种广泛使用的编程语言,适合于网络爬虫和自动化脚本的开发。
-
下载Python:
- 访问Python官方网站。
- 根据你的操作系统(Windows、macOS或Linux)下载适合的Python版本。建议使用最新的稳定版本。
-
安装Python:
- 在Windows上,运行下载的安装程序,确保勾选“Add Python to PATH”选项,以便在命令行中直接使用Python。
- 在macOS和Linux上,可以使用包管理工具(如Homebrew或apt)进行安装。例如,在macOS上可以使用以下命令:
brew install python
-
验证安装:
- 打开命令行或终端,输入以下命令以验证Python是否安装成功:
python --version - 如果安装成功,你将看到Python的版本号。
- 打开命令行或终端,输入以下命令以验证Python是否安装成功:
2.2 安装开发工具
为了提高开发效率,建议使用集成开发环境(IDE)或文本编辑器。以下是一些推荐的工具:
- PyCharm:功能强大的Python IDE,适合大型项目开发。
- Visual Studio Code:轻量级的文本编辑器,支持多种插件,适合快速开发。
- Jupyter Notebook:适合数据分析和实验性代码开发,支持交互式编程。
选择适合自己的开发工具,并进行安装。
2.3 创建虚拟环境
使用虚拟环境可以隔离项目依赖,避免不同项目之间的库冲突。以下是创建和激活虚拟环境的步骤:
-
安装
virtualenv(如果尚未安装):pip install virtualenv -
创建虚拟环境:
在项目目录下运行以下命令,创建一个名为venv的虚拟环境:virtualenv venv -
激活虚拟环境:
- 在Windows上:
venv\Scripts\activate - 在macOS和Linux上:
source venv/bin/activate
- 在Windows上:
激活后,你的命令行提示符会显示虚拟环境的名称,表示你已进入该环境。
2.4 安装所需库
在虚拟环境中安装项目所需的库。以下是本项目需要的主要库及其安装命令:
-
requests:用于发送HTTP请求。pip install requests -
BeautifulSoup:用于解析HTML文档。pip install beautifulsoup4 -
tkinter:用于创建图形用户界面(通常Python自带,无需单独安装,但在某些Linux发行版上可能需要安装):sudo apt-get install python3-tk -
schedule:用于定时任务调度。pip install schedule -
(可选)
lxml:如果需要更快的HTML解析,可以安装lxml库:pip install lxml
2.5 验证库安装
安装完所需库后,可以通过以下命令验证库是否安装成功:
pip list
这将列出当前虚拟环境中安装的所有库及其版本。
2.6 项目结构
在开始编码之前,建议创建一个清晰的项目结构,以便于管理和维护。以下是一个简单的项目结构示例:
self-service-order-plugin/
│
├── venv/ # 虚拟环境目录
│
├── main.py # 主程序文件
│
├── requirements.txt # 项目依赖文件
│
└── README.md # 项目说明文件
2.7 创建requirements.txt
为了方便其他开发者或用户安装项目依赖,可以创建一个requirements.txt文件,记录所有依赖库及其版本。在虚拟环境中运行以下命令生成该文件:
pip freeze > requirements.txt
3. 网络请求
在自助抢单插件中,网络请求是获取目标网站数据的关键步骤。通过发送HTTP请求,我们可以获取网页的HTML内容,并进一步解析出所需的信息。以下将详细阐述如何使用Python的requests库进行网络请求,包括请求的基本概念、常用方法、处理响应以及错误处理等。
3.1 HTTP请求概述
HTTP(超文本传输协议)是Web上数据传输的基础。网络请求通常包括以下几个重要概念:
-
请求方法:常用的请求方法包括GET和POST。
- GET:用于请求数据,通常用于获取网页内容。
- POST:用于提交数据,通常用于表单提交或数据上传。
-
请求头:请求头包含了请求的元信息,如用户代理(User-Agent)、接受的内容类型(Accept)等。
-
响应:服务器返回的结果,包括状态码、响应头和响应体。状态码指示请求的处理结果,如200表示成功,404表示未找到。
3.2 使用requests库发送GET请求
requests库是Python中最常用的HTTP库,使用简单且功能强大。以下是如何使用requests库发送GET请求的步骤:
-
安装
requests库(如果尚未安装):pip install requests -
发送GET请求:
使用requests.get()方法发送GET请求,并获取响应内容。import requestsdef fetch_page(url):try:response = requests.get(url)response.raise_for_status() # 检查请求是否成功return response.text # 返回响应的HTML内容except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None
3.3 设置请求头
有些网站可能会根据请求头来判断请求的来源,特别是需要模拟浏览器行为时。可以通过headers参数设置请求头。
def fetch_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept-Language': 'en-US,en;q=0.9',}try:response = requests.get(url, headers=headers)response.raise_for_status()return response.textexcept requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None
3.4 处理响应
在成功获取响应后,通常需要检查响应的状态码和内容。以下是一些常见的状态码及其含义:
- 200 OK:请求成功,服务器返回所请求的内容。
- 404 Not Found:请求的资源未找到。
- 500 Internal Server Error:服务器内部错误。
可以通过response.status_code获取状态码,并根据需要进行处理。
def fetch_page(url):headers = {'User-Agent': 'Mozilla/5.0 ...', # 示例User-Agent}try:response = requests.get(url, headers=headers)response.raise_for_status() # 检查请求是否成功print(f"请求成功,状态码: {response.status_code}")return response.textexcept requests.exceptions.HTTPError as http_err:print(f"HTTP错误: {http_err}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None
3.5 处理重定向
有些请求可能会被重定向到其他URL。requests库会自动处理重定向,但你也可以通过allow_redirects参数控制这一行为。
response = requests.get(url, headers=headers, allow_redirects=True) # 默认允许重定向
3.6 处理Cookies
有些网站需要使用Cookies进行身份验证或会话管理。可以通过requests库轻松处理Cookies。
session = requests.Session() # 创建一个会话对象
session.get('http://example.com') # 第一次请求,可能会设置Cookies
response = session.get('http://example.com/another-page') # 使用相同的会话请求
3.7 处理超时
在网络请求中,设置超时是一个良好的实践,以避免请求长时间挂起。可以通过timeout参数设置超时时间(单位为秒)。
response = requests.get(url, headers=headers, timeout=5) # 设置超时为5秒
3.8 示例代码
以下是一个完整的示例,展示如何使用requests库发送GET请求并处理响应:
import requestsdef fetch_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}try:response = requests.get(url, headers=headers, timeout=5)response.raise_for_status() # 检查请求是否成功print(f"请求成功,状态码: {response.status_code}")return response.text # 返回HTML内容except requests.exceptions.HTTPError as http_err:print(f"HTTP错误: {http_err}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None# 示例用法
url = 'http://example.com'
html_content = fetch_page(url)
if html_content:print("获取到的HTML内容:", html_content[:100]) # 打印前100个字符
4. 数据解析
使用BeautifulSoup解析获取的HTML内容,提取我们需要的信息。以下是一个示例,展示如何解析商品信息:
from bs4 import BeautifulSoupdef parse_page(html):soup = BeautifulSoup(html, 'html.parser')items = []for item in soup.select('.item-class'): # 根据实际情况修改选择器title = item.select_one('.title-class').textprice = item.select_one('.price-class').textitems.append({'title': title, 'price': price})return items
5. 用户界面
使用tkinter创建一个简单的用户界面,让用户输入目标URL和其他参数:
import tkinter as tkdef start_monitoring():url = url_entry.get()# 启动监控逻辑print(f"Monitoring {url}")app = tk.Tk()
app.title("自助抢单插件")tk.Label(app, text="输入目标URL:").pack()
url_entry = tk.Entry(app)
url_entry.pack()start_button = tk.Button(app, text="开始监控", command=start_monitoring)
start_button.pack()app.mainloop()
6. 定时任务
在自助抢单插件中,定时任务是确保插件能够定期检查目标网站的更新并获取最新商品信息的关键部分。使用 schedule 库可以轻松地设置定时任务,使得代码结构清晰且易于管理。以下将详细介绍如何使用 schedule 库设置定时任务,包括安装、基本用法、示例代码以及如何与其他模块结合。
6.1 安装 schedule 库
如果尚未安装 schedule 库,可以通过以下命令进行安装:
pip install schedule
6.2 schedule 库基本用法
schedule 库提供了简单的API来安排任务。以下是一些基本用法:
schedule.every(interval).seconds.do(job):每隔指定的秒数执行任务。schedule.every(interval).minutes.do(job):每隔指定的分钟执行任务。schedule.every().day.at("HH:MM").do(job):每天在指定时间执行任务。
6.3 定时任务示例
以下是一个简单的示例,展示如何使用 schedule 库设置定时任务:
import schedule
import timedef job():print("定时任务执行中...")# 每10秒执行一次任务
schedule.every(10).seconds.do(job)while True:schedule.run_pending() # 运行所有待执行的任务time.sleep(1) # 暂停1秒,避免CPU占用过高
6.4 将定时任务与自助抢单插件结合
在自助抢单插件中,我们需要定期检查目标网站的商品信息。以下是如何将定时任务与之前的网络请求和数据解析模块结合的示例:
import requests
from bs4 import BeautifulSoup
import schedule
import time# 网络请求模块
def fetch_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}try:response = requests.get(url, headers=headers, timeout=5)response.raise_for_status()return response.textexcept requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None# 数据解析模块
def parse_page(html):soup = BeautifulSoup(html, 'html.parser')items = []for item in soup.select('.item-class'): # 根据实际情况修改选择器title_element = item.select_one('.title-class')price_element = item.select_one('.price-class')title = title_element.text.strip() if title_element else '未知商品'price = price_element.text.strip() if price_element else '未知价格'items.append({'title': title, 'price': price})return items# 定时任务模块
def job(url):html = fetch_page(url)if html:products = parse_page(html)for product in products:print(f"商品名称: {product['title']}, 价格: {product['price']}")# 启动监控
def start_monitoring(url):schedule.every(10).seconds.do(lambda: job(url)) # 每10秒检查一次while True:schedule.run_pending() # 运行所有待执行的任务time.sleep(1) # 暂停1秒# 示例用法
url = 'http://example.com/products' # 替换为实际的产品页面URL
start_monitoring(url)
6.5 代码详解
- 网络请求模块:使用
fetch_page函数从目标URL获取HTML内容。 - 数据解析模块:使用
parse_page函数解析HTML,提取商品信息。 - 定时任务模块:在
job函数中调用fetch_page和parse_page,并打印商品信息。 - 启动监控:在
start_monitoring函数中设置定时任务,每10秒执行一次job函数。
6.6 运行定时任务
- 确保已安装所有依赖库(
requests、beautifulsoup4、schedule)。 - 在命令行中进入项目目录,激活虚拟环境(如果使用)。
- 运行包含定时任务的主程序文件。
7. 完整代码示例
将上述所有部分整合在一起,形成一个完整的自助抢单插件:
代码资源连接:https://download.csdn.net/download/hh867308122/89962429
总结
在本文中,我们详细探讨了如何构建一个自助抢单插件,涵盖了从环境准备到网络请求、数据解析、定时任务以及用户界面设计的各个方面。通过使用Python的requests和BeautifulSoup库,我们能够高效地获取和解析网页数据,从而提取出用户所需的商品信息。同时,借助schedule库,我们实现了定时任务的功能,使得插件能够定期检查目标网站的更新,确保用户在竞争激烈的市场中把握抢购机会。
整个插件的设计旨在提供一个用户友好的界面,使得即使是编程新手也能轻松上手。通过不断优化和扩展功能,用户可以根据自己的需求定制插件,例如添加自动下单、价格提醒等功能。希望这篇文章能为你在自动化抢购领域提供有价值的指导,帮助你在电子商务的浪潮中获得更多的成功与机会。
码文不易,本篇文章就介绍到这里,如果想要学习更多Java系列知识,点击关注博主,博主带你零基础学习Java知识。与此同时,对于日常生活有困扰的朋友,欢迎阅读我的第四栏目:《国学周更—心性养成之路》,学习技术的同时,我们也注重了心性的养成。