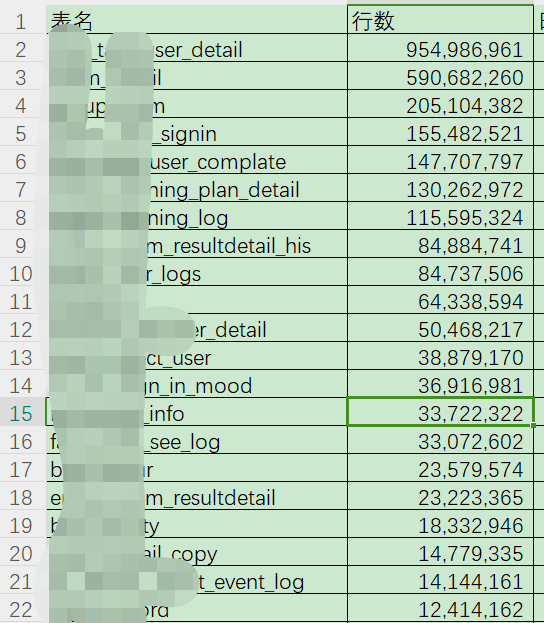
记录一下2年前的MySQL大表的归档,当时刚到公司,发现MySQL的业务核心库,超过亿条的有7张表,最大的表有9亿多条,有37张表超过5百万条,部分表行数如下:
在测试的MySQL环境 :
pt-archiver 工具,测试200的dev实例,5800万条数据,纯删除1000万条数据,花费约9分多钟。
pt-archiver --source h=172.17.0.1,u=dev_op,p='pwd',P=3306,D=test,t=cc --statistics --no-check-charset --where " id<=13000000" --limit 60000 --commit-each
--progress 1000000 --bulk-delete --primary-key-only --purge
和研发,产品讨论如何删除这些大表的没用的数据,确定后,是删除部分没有续约和不合作客户的数据,这些企业的id,由产品部门确认后,给了给列表。
查询后,这些大表都有比较大的数据行数删除,最大的9亿多条表可以删除出2.3亿条数据,如何备份和删除这2.3亿条数据?
1,使用腾讯云的数据迁移工具,把整个表备份后,通过pt-archiver 工具删除。 大表不适用
这样备份可以批量进行,删除可以慢慢删除,小表备份可以,但是对于大表,就多备份了6,7亿条数据。占用空间
2,可以使用mysqldump工具通过查询备份删除的数据,在通过pt-archiver 工具删除。 小表不适用
千万级别以下小表就比较麻烦。对于亿级别以上的大表就比较好,如下:
-- 导出单表
mysqldump -udba_op -p'pwd' -h172.17.16.126 -P3306 --set-gtid-purged=OFF -t --default-character-set=utf8mb4 --skip-lock-tables de_db exam_detail --where=" exam_id in (select exam_id from exam where app_id in (select app_id from bak.t_app_2022)) " >/data1/ex.sql-- 在备份MySQL还原
source /data1/ex.sql
pt-archiver删除数据:
例子: -从库4和5延迟30秒,暂停停止删除
pt-archiver --source h=172.17.16.12,u=dba_op,p='pwd',P=3306,D=de_db,t=user_detail --statistics --no-check-charset --where " exam_id in (select exam_id from exam where app_id in ('gzdsl'))" --limit 100000 --max-lag=30 --check-slave-lag u=dba_op,p='pwd',h=172.17.16.106,P=3306 --check-slave-lag u=dba_op,p='pwd',h=172.17.16.4,P=3306 --commit-each --progress 3000000 --bulk-delete --primary-key-only --purge
--primary-key-only 指定进行DELETE清除时最有效,因为只需读取主键一个字段而无需读取行所有字段
--purge 指定执行的删除操作
--limit 100000 每次删除10万行,可以根据情况调整
--dry-run 打印查询需要清除数据的执行语句,做好确认之后再执行
最后处理:
1,对于9亿条的数据,修改pt脚本,确定执行最长时间--run-time和延迟时间20秒,减少对系统的影响,类似修改如下:
pt-archiver --source h=172.17.16.12,u=dba_op,p='pwd',P=3306,D=de_db,t=gp_mem --statistics --no-check-charset --where " sys_user_id in (select sys_user_id from db_bak.t1) " --limit 200000 --max-lag=20 --check-slave-lag u=dba_op,p='pwd',h=172.17.16.106,P=3306 --commit-each --progress 3000000 --bulk-delete --primary-key-only --run-time=100m --purge
2,每个表写一个shell文件,调度执行
3,删除完成后,重建表释放表的空间
pt-online-schema-change --alter " engine=innodb " h=172.17.16.78,P=3306,p='pwd',u=dev_op,D=sg_bak,t=user_detail --charset=utf8mb4 --no-check-replication-filters --recursion-method=none --execute