借鉴了某博主@Yunheeee,发现写的很不错,帮助我完成了此次作业,感谢!
紧接着,我跟着它的代码尝试了一下,大体如下:
首先引入库
import requests
import numpy as np
import pandas as pd接着设置url的网站
url='https://datachart.500.com/ssq/history/newinc/history.php?start=03001' #获取历史所有双色球数据
response = requests.get(url)
response.encoding = 'utf-8'
re_text = response.text#网页数据解析
re=re_text.split('<tbody id="tdata">')[1].split('</tbody>')[0]
result=re.split('<tr class="t_tr1">')[1:]all_numbers=[]
for i in result:each_numbers=[]i=i.replace('<!--<td>2</td>-->','')each=i.split('</td>')[:-1]for j in each:each_numbers.append(j.split('>')[1].replace(' ',''))all_numbers.append(each_numbers)#定义列名称
col=['期号','红球1','红球2','红球3','红球4','红球5','红球6','蓝球','快乐星期天','奖池奖金(元)','一等奖注数','一等奖奖金(元)','二等奖注数','二等奖奖金(元)','总投注额(元)','开奖日期']#解析完网页数据,生成双色球数据框
df_all=pd.DataFrame(all_numbers,columns=col)
df_all.head()在网页解析那段代码有些不懂,于是我查看了网页的源代码:

主要是最后一行出现了解析那段的字符,查阅了资料发现split()函数可以通过指定字符串进行切片,我的理解是以tbody id=tdata及tbody为切片,定义为re,然后取re中[1:]的数。
得到:
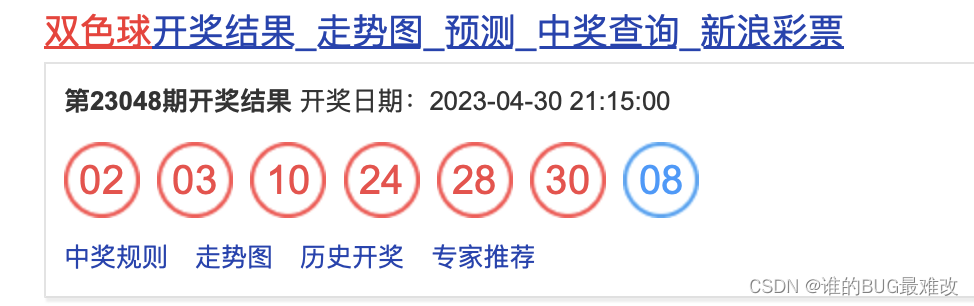
df_all['蓝球']
将开奖日期一项放在前面。
from sklearn.svm import SVR
df_blue = df_all.iloc[::-1]
df_blue = df_blue.set_index('开奖日期')
df_blue 
for i in range(1, 21, 1):df_blue.loc[:,'Close Minus ' + str(i)] = df_blue['蓝球'].shift(i)
df_blue提取20个开奖周期的蓝球数据到数据中,shift(i)会将球号向下移动一格。
筛选有效数据

#从sp20取500作为训练集
x_train = sp20[:-500]
x_train#目标值
y_train = sp20['蓝球'].shift(-1)[:-500]
y_train
预测集和对比集
导入模型,拟合
clf = SVR(kernel='linear')
model = clf.fit(x_train, y_train)
preds = model.predict(x_test)
#将字符串转为整型
y_test = sp20['蓝球'][-500:]
arr = y_test.values
arr = arr.astype(int)#结果也转为整型,再比较
preds = preds.astype(int)
correct = np.mean(preds == arr)
correct
![]()
发现成功率仅为0.046,得出结论:极为不可信!!!!