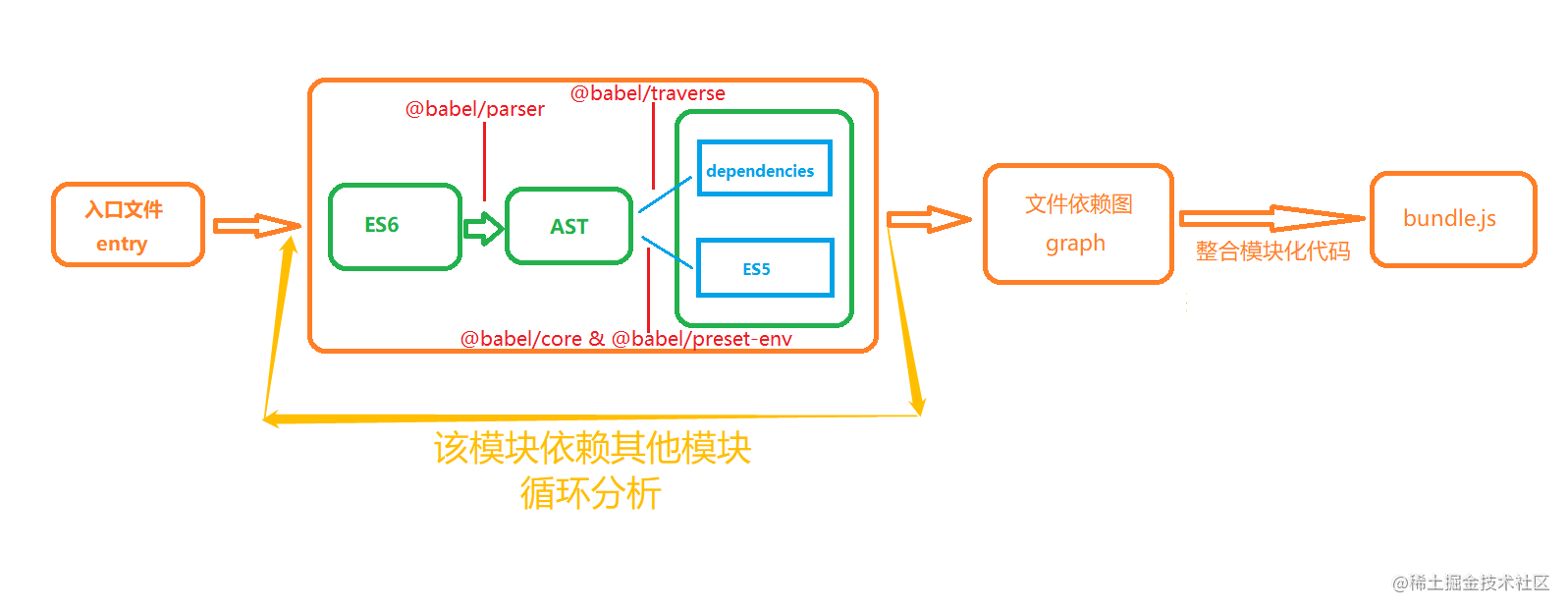
以下是代码中关于词表(vocabulary)部分的代码片段,以及对应的设计思路和优势解释:
def gen_one_voc():# ... [省略部分代码] ...count = Counter()for ii in tqdm(range(0, len(data), len(data) // 8)):jj = ii + len(data) // 8for k, v in Counter(data[ii:jj]).items():count[k] = count.get(k, 0) + v# ... [省略部分代码] ...count = pd.DataFrame({"voc": count.keys(), "count": count.values()})voc = count.loc[count["count"] > 100, "voc"].values.tolist()voc0 = [[[["<|pos_{}_{}|>".format(jj, ii) for jj, ii in enumerate(list(str(i)))], j] for i, j inenumerate(count.loc[count["count"] <= 100, "voc"].values.tolist())]]pd.to_pickle(voc, "voc.pkl")pd.to_pickle(voc0, "voc0.pkl")
def gen_voc():voc = pd.read_pickle("voc.pkl")voc0 = pd.read_pickle("voc0.pkl")voc0 = {j: i for i, j in voc0[0]}for i in range(6):for j in range(10):voc.append("<|pos_{}_{}|>".format(i, j))voc = ["<|sos|>", "<|agent|>", "<|pad|>", "<|history|>"] + sorted(voc)pd.to_pickle({"voc": voc, "voc0": voc0}, "total_voc.pkl")
设计思路:
- 词频统计:
gen_one_voc函数首先对文本数据进行词频统计。这是通过遍历数据,并对每个分段的文本进行计数来完成的。使用Counter类来记录每个词出现的次数。 - 筛选高频词:统计完成后,将结果转换为 DataFrame,并根据词频筛选出高频词。在这个例子中,只保留了出现次数超过100次的词。
- 低频词特殊处理:对于出现次数不超过100次的词,将其转换为特殊的标记格式
<|pos_{}_{}|>,其中{}是位置索引。这种格式有助于在模型中区分低频词和高频词。 - 构建总词表:
gen_voc函数将高频词和特殊标记的低频词合并成一个总的词表total_voc。此外,还添加了一些特殊的标记,如<|sos|>(序列开始)、<|agent|>(代理标记)、<|pad|>(填充标记)和<|history|>(历史标记)。
优势:
- 减少词汇量:通过筛选高频词,减少了模型需要处理的总词汇量,这有助于减少模型的复杂性和训练时间。
- 处理稀有词:将低频词转换为特殊格式,可以有效地处理稀有词问题,而不需要为每个稀有词分配一个唯一的词向量。
- 增强泛化能力:通过将低频词映射到一组有限的特殊标记,模型可以在没有直接见过这些词的情况下,对这些词进行泛化处理。
- 灵活性:通过添加特殊标记,模型可以更容易地处理特定的序列任务,如序列的开始、代理的响应等。
- 易于管理:使用 DataFrame 和 pickle 来管理和存储词表,使得数据的加载和处理变得更加方便和高效。
- 扩展性:这种设计允许模型容易地扩展到新的数据集和任务,只需重新生成或更新词表即可。
总的来说,这种词表设计方式在处理大规模文本数据时非常有效,特别是在需要处理大量词汇和稀有词的 NLP 任务中。