前言
实现 myWebpack 主要是为了更好的理解,webpack 中的工作流程,一切都是最简单的实现,不包含细节内容和边界处理,涉及到 ast 抽象语法树和编译代码部分,最好可以打印出来观察一下,方便后续的理解。
react 项目中的 webapck
为了更好的了解 Webpack 的执行流程,我们可以先通过观察 react 项目结构中,有关 webpack 的一些内容。当然我们得先拥有一个新的项目,可以通过下面的步骤得到:
- 使用 【
create-react-app 项目名称】命令创建项目 - 进入对应的项目目录,运行
npm run eject命令拉取,react项目中和webapck相关的配置
相比于正常的react项目,会多出来两个文件目录分别是config和scripts
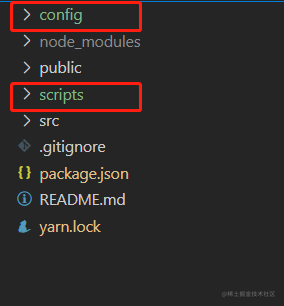
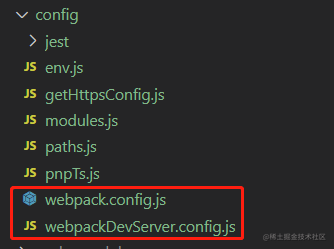
config 目录下主要存放的是 webpack 相关的配置内容:
scripts 目录下主要存放的是在 pakage.json 中存放的 3 个默认 script 脚本相关的内容:
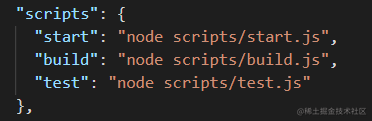

主要看 scripts 目录下的 build.js 文件,这里面引入了 webpack 并且调用 webpack(config) 得到了 compiler 对象,最后使用了 compiler.run(callback) 的方式开始进行打包,代码中具体位置如下:

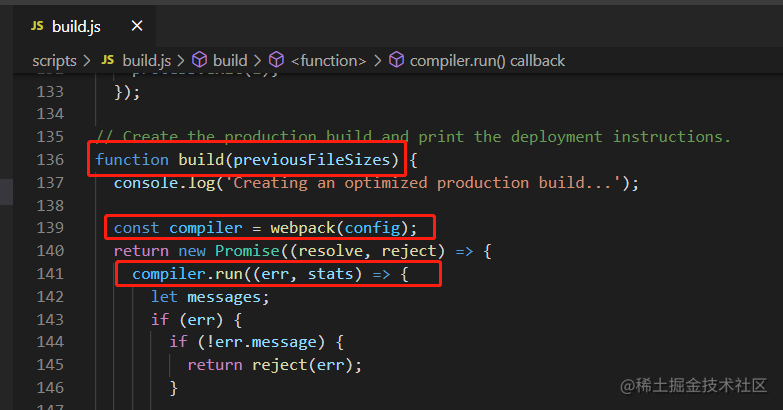
Webpack 执行流程
通过 react 项目中的目录结构结合以及 webpack 中的 Node 接口相关内容,可得到以下几个阶段:
- 解析配置参数 —— 合并
shell传入和webpack.config.js文件配置参数 - 初始化 Compiler —— 通过
webpack(config)得到Compiler对象,并注册所有配置插件,插件监听webpack构建生命周期的事件节点,做出相应处理 - 开始编译 —— 调用
Compiler对象run()方法开始执行编译 - 确定入口 —— 根据配置的
entry找出所有入口文件,开始解析文件,并构建AST语法树,找出依赖模块,进行递归处理 - 编译模块 —— 递归中根据文件类型和
loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤,直到所有入口依赖的文件都经过了本步骤的处理 - 完成模块编译 —— 模块编译结束后,得到每个文件结果,包含每个模块以及他们之间的依赖关系
- 输出资源 —— 根据
entry或分包配置生成代码块chunk,再把每个chunk转换成一个单独的文件加入到输出列表PS:输出资源 这一步是修改输出内容的最后机会
- 输出完成 —— 根据配置确定输出路径和命名,输出所有
chunk到文件系统
核心流程图示:
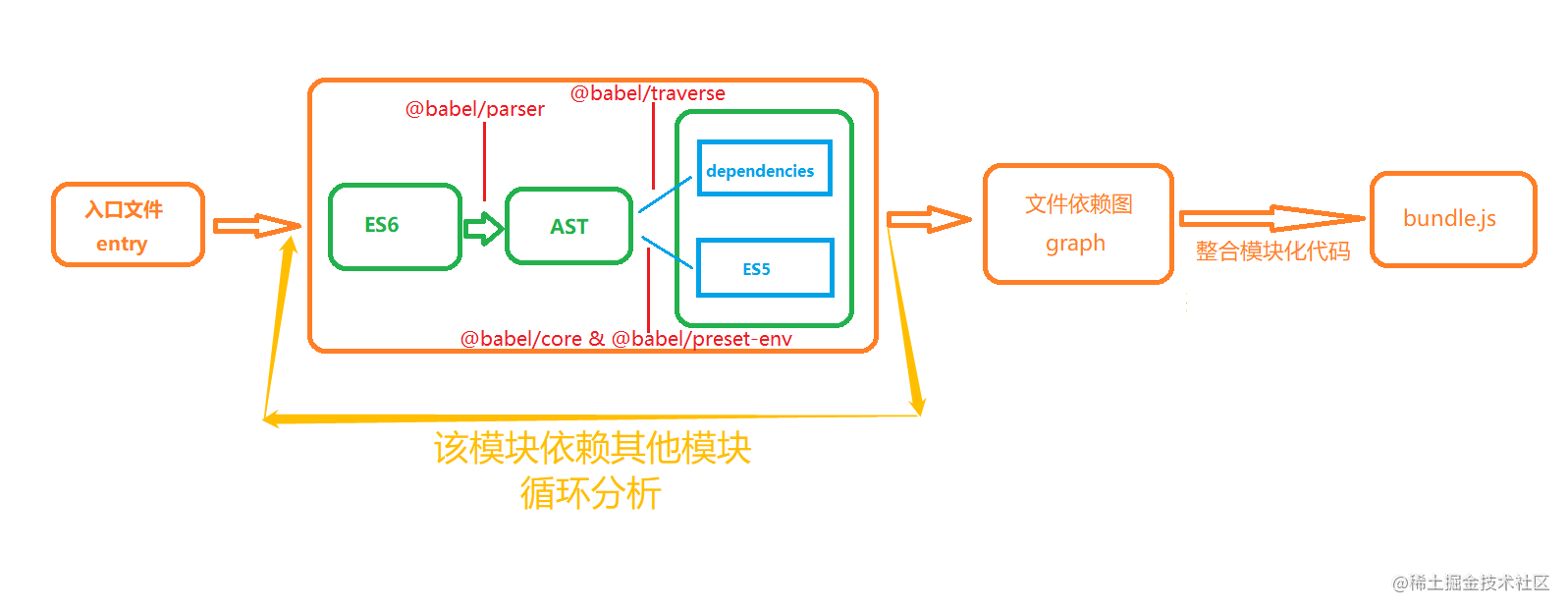
实现 myWebpack
准备工作
根据 react 项目中的目录结构,可以得到一个简单 my-webpac 的项目结构:
- config 目录 —— 存放的是
webpack.config.js相关配置 - script 目录 —— 存放的是
script脚本需要执行的js文件 - lib 目录 —— 存放的就是
myWebpack库(需要自己实现) - src 目录 —— 就是
webpack.config.js中默认的入口文件目录,其中的index.js为入口文件,其他的js文件均属于要测试打包的js模块
在后面的内容中为了更好的实现模块化,目录结构可能会稍微进行修改,最初的文件结构如下:
my-webpack
├─ config
│ └─ webpack.config.js
├─ lib
│ └─ myWebpack
│ └─ index.js
├─ package-lock.json
├─ package.json
├─ script
│ └─ build.js
└─ src├─ add.js├─ desc.js└─ index.js
开始实现
简单配置 config 目录下的 webpack.config.js
// config/webpack.config.jsmodule.exports = {entry: "./src/index.js",output: {path: 'dist',filename: 'index.js'}
};
实现 script 目录下的 build.js
这里只需要引入 myWebpack.js 和 webapck.config.js 文件,通过把配置内容 config 传入 myWebpack() 方法,并执行得到 compiler 对象,最终通过 compiler.run() 开始执行打包的处理程序
// script/build.jsconst myWebpack = require('../lib/myWebpack'); // 这里相当于 require('../lib/myWebpack/index.js')
const config = require('../config/webpack.config.js');// 获得 compiler 对象
const compiler = myWebpack(config);// 开始打包
compiler.run();
实现 lib 目录下的 myWebpack 的具体内容(即其目录下的 index.js)
根据 build.js 中对 myWebpack 使用方式,可以知道在 myWebpack 必然是一个 function 且,其返回值必须是 Compiler 类的实例对象,毕竟被称为 compiler 对象。在这就出现了一个 Compiler 类的相关内容,为了更好的模块化,我们在 lib/myWebpack 目录下新建 compiler.js 文件,里面专门实现 Compiler 类的相关逻辑。
所以,在 lib/myWebpack/index.js 中的处理就是实现 myWebpack 函数,引入 Compiler 类并把 new Compiler(config) 的结果进行返回即可:
// lib/myWebpack/index.jsconst Compiler = require('./Compiler.js')function myWebpack(config) {return new Compiler(config)
}module.exports = myWebpack
实现 lib 目录下 myWebpack 中的 compiler.js 内容
根据 build.js 中对 compiler 对象的使用方式,compiler.js 中必然会存在 Compiler 类 ,并且肯定存在 run() 方法,而且 run() 方法中需要处理的几件事可以归纳为:
- 根据
entry配置中的路径,将文件解析成ast抽象语法树 - 根据
ast收集依赖存放自定义deps对象上 - 根据
ast编译成可以在浏览器上正常运行的code内容 - 以及把编译好的
code通过output配置中的path和filename写入到文件系统
其中,前三步属于编译解析的内容,因此,具体逻辑我们可以抽离到lib/myWebpack/parser.js中实现并向外暴露对应内容即可,并且放在Compiler 类里面的build()方法统一处理,最后一步输出资源可以抽离到Compiler 类里面的generate()方法中。
// lib/myWebpack/compiler.jsconst { getAst, getDeps, getCode } = require('./parser.js')
const fs = require('fs')
const path = require('path')class Compiler {constructor(options = {}) {// webpack 配置对象this.options = options// 所有依赖的容器this.modules = []}// 启动打包run() {// 获取 options 中的路径const filePath = this.options.entry// 首次构建,获取入口文件信息const fileInfo = this.build(filePath)// 保存文件信息this.modules.push(fileInfo)// 遍历所有依赖this.modules.forEach((fileInfo) => {// 获取当前文件所有依赖: { relativePath: absolutePath }const deps = fileInfo.depsfor (const relativePath in deps) {// 获取对应绝对路径const absolutePath = deps[relativePath]// 对依赖文件进行打包处理const fileInfo = this.build(absolutePath)// 将打包后的结果保存到 modules 中,方便后面进行处理this.modules.push(fileInfo)}})// 将 modules 数组整理成更好的依赖关系图/*{'index.js': {'code': 'xxx','deps': {[relativePath]: [absolutePath]} }}*/const depsGraph = this.modules.reduce(function (graph, module) {return {...graph,[module.filePath]: {code: module.code,deps: module.deps,},}}, {})// 根据依赖关系图构建输出内容this.generate(depsGraph)}// 开始构建build(filePath) {// 将文件解析成 ast 抽象语法树const ast = getAst(filePath)// 根据 ast 收集依赖:{ relativePath: absolutePath }const deps = getDeps(ast, filePath)// 根据 ast 编译成 codeconst code = getCode(ast)return {filePath, // 当前文件路径deps, // 当前文件的所有依赖code, // 当前文件解析过的代码}}// 生成输出资源generate(depsGraph) {const bundle = `(function(depsGraph){// require 加载入口文件function require(module){// 定义暴露对象var exports = {};// require 内部在定义 localRequire 是为了让 require 递归function localRequire(relativePath){// 找到引入模块的绝对路径,通过 require 进行加载return require(depsGraph[module].deps[relativePath]);}(function(require, exports, code){eval(code);})(localRequire, exports, depsGraph[module].code);// 作为 require 的返回值 —— 让后面的 require 函数能得到被暴露的内容return exports;}require('${this.options.entry}');})(${JSON.stringify(depsGraph)});`const { output } = this.optionsconst dirPath = path.resolve(output.path)const filePath = path.join(dirPath, output.filename)// 如果指定目录不存在就创建目录if (!fs.existsSync(dirPath)) {fs.mkdirSync(dirPath)}// 写入文件fs.writeFileSync(filePath, bundle.trim(), 'utf-8')}
}module.exports = Compiler
generate() 方法中 bundle 变量内容的解释
- 外部包裹一个立即执行的匿名函数,主要就是为了生成独立作用域,实现
js的模块化 - 其中的
require()方法,就是通过eval函数去执行,被编译后的code,因为被编译后的code是字符串形式的js代码 require()方法中的localRequire ()方法实际上执行的还是require()方法本身,但对当前模块路径做了一定处理,这里其实就是递归require()方法中还有一个立即执行的匿名函数,接收三个参数:require, exports, code,其中code参数容易理解,但是为什么我们需要传递require, exports参数呢?- 这一点我们可以通过看被编译之后的
code的内容就知道了,例如入口文件index.js和它里面引入add.js的编译结果code如下:
- 这一点我们可以通过看被编译之后的
// index.js 内容编译结果 => 这里需要使用到 require 方法,因此外部必须传入
"'use strict';
var _add = _interopRequireDefault(require('./add.js'));
var _desc = _interopRequireDefault(require('./desc.js'));
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { 'default': obj }; }
console.log('add = ', (0, _add['default'])(1, 2));
console.log('desc = ', (0, _desc['default'])(3, 1));"// add.js 内容编译结果 => 这里需要使用到 exports 对象,因此外部必须传入
"'use strict';
Object.defineProperty(exports, '__esModule', { value: true});
exports['default'] = void 0;
function add(x, y) { return x + y;}
var _default = add;
exports['default'] = _default;"
实现 lib 目录下 myWebpack 中的 parser.js 内容
这里需要做的就是下面的三件事:
- 根据
entry配置中的路径,将文件解析成ast抽象语法树,需要借助@babel/parser中的parse方法 - 根据
ast收集依赖存放自定义deps对象上,借助@babel/traverse遍历ast中的program.body,方便在特定时机收集依赖 - 根据
ast编译成可以在浏览器上正常运行的code内容,需要借助@babel/core中的transformFromAst方法
// lib/myWebpack/parser.jsconst babelParser = require('@babel/parser')
const { transformFromAst } = require('@babel/core')
const babelTraverse = require('@babel/traverse').default
const path = require('path')
const fs = require('fs')const parser = {getAst(filePath) {// 通过 options.entry 读入口文件const file = fs.readFileSync(filePath, 'utf-8')// 将入口文件内容解析成 ast —— 抽象语法树const ast = babelParser.parse(file, {sourceType: 'module', // 处理被解析文件中的 ES module})return ast},getDeps(ast, filePath) {// 获取到文件所在文件夹的路径const dirname = path.dirname(filePath)// 存储依赖的容器const deps = {}// 根据 ast 收集依赖babelTraverse(ast, {// 内部会遍历 ast 中的 program.body,根据对应的语句类型进行执行// ImportDeclaration(code) 方法会在 type === "ImportDeclaration" 时触发ImportDeclaration({ node }) {// 获取当前文件的相对路径const relativePath = node.source.value// 添加依赖:{ relativePath: absolutePath }deps[relativePath] = path.resolve(dirname, relativePath)},})return deps},getCode(ast) {// 编译代码: 将浏览器中不能被识别的语法进行编译const { code } = transformFromAst(ast, null, {presets: ['@babel/preset-env'],})return code},
}module.exports = parser
最终的目录结构
my-webpack
├─ config
│ └─ webpack.config.js
├─ lib
│ └─ myWebpack
│ ├─ compiler.js
│ ├─ index.js
│ └─ parser.js
├─ package-lock.json
├─ package.json
├─ README.md
├─ script
│ └─ build.js
└─ src├─ add.js├─ desc.js└─ index.js