目录
前言
一、Tokenizer
二、模型结构
dense模型
MoE模型
模型参数设置
三、Pre-Training
Pre-Training DATA
LONG-CONTEXT TRAINING
四、Post-Training
Post-Training DATA
人工数据注释(collaborative data annotation)
自动数据合成(automated data synthesis)
Supervised Fine-Tuning
Reinforvement Learning From Human Feekback
五、Evaluation
Base Language Models
Core Capabilities
Instruction-Tuned Model
Open Benchmark Evaluation
In-house Automatic Evaluation
Long Context Capabilities
总结
前言
今天分享六月份开源的Qwen2模型系列,包括了dense模型的70B、7B、1.5B、0.5B和MoE模型的57-14B,其中最强悍的70B模型在国内属于T1梯队,在大量使用后的体验也确实如此。本文通过分析技术报告从Tokenizer、模型结构、预训练、后训练和评估进行解读,深入分析Qwen2背后的原理。
一、Tokenizer
和Qwen相同,Qwen2采用byte-level byte-pair encoding(BPE)分词器,这个分词器具有很高的编码效率,所有大小的模型都使用由151643个通用token和3个控制token组成的公共词汇表。
具体来说,使用一个开源的 fast BPE tokenizer,tiktoken,并且选择cl100k词汇表作为起点进行分词;为了提高模型在多语言下游任务上的性能,特别是在中文中,进一步增加了常用的中文字符和单词以及其他语言的词汇;此外,将数字分成了个位数。
随机选择每种语言的100万个文档语料库,将Qwen2的tokenizer和其他大模型使用的tokenizer的压缩率进行对比,具有更高的压缩率:

二、模型结构
共包括四个scale的dense模型和一个MoE模型。
dense模型
Qwen2 dense模型的架构包括多个Transformer层,每个层都配备了因果注意机制和前馈神经网络(ffn)。与Qwen的主要区别如下:
- GQA(Grouped Query Attention):使用GQA替换MHA,GQA在推理期间优化KV缓存,显著提高了吞吐量。
- DCA(Dual Chunk Attention with YARN):为了扩展Qwen2的上下文窗口,实现了双块注意,将长序列分割成可控长度的块。如果输入可以在一个块中处理,则DCA与原始注意生成相同的结果。否则,DCA有助于有效捕获块内和块间的token的相对位置信息,从而提高长上下文性能。此外,还使用YARN来重新调整注意力权重,以获得更好的长度外推。
- 除了GQA和DCA之外,follow Qwen使用SwiGLU激活函数、RoPE位置嵌入、QKV bias for attention、RMSNorm归一化函数和前置归一化。
MoE模型
MIXTURE-OF-EXPERTS MODEL,Qwen2 MoE模型的结构和Qwen1.5-MoE-2.7B几乎相同,作为原始FFN的替代品,MoE FFN由n个独立的FFN组成,每个FFN都作为专家,每个token被定向到一个特定的专家Ei,根据门控网络G分配的概率进行计算:

针对MoE模型的设计,提出以下关键部分的设计:
- Expert Granularity:不同于Mistral-8x7B(将每个专家的参数设置为与原始密集模型中的单个FFN的参数相等,每次激活8名专家中的2名),Qwen2使用更细粒度的专家(Dai et al., 2024),创建较小scale的专家同时激活更多的专家,以保证在专家参数和激活参数的总数相同的同时提供更丰富的专家组合。通过细粒度的专家,Qwen2 MoE实现更多样性和动态的专家组合使用。
- Expert Routing:Qwen2采用集成共享专家加特定专家的组合(Rajbhandari et al., 2022; Dai et al., 2024),这有助于在各种任务中应用共享专家,同时保留其他专家在特定路由场景中的选择性使用。
- Expert Initialization:使用类似于upcycling(升级回收)(Komatsuzaki et al.,
2023)的方式利用dense模型的权重。首先设定专家维度为hE,原始FFN的维度为hFFN,专家数量为n;为了兼容制定数量的专家,将FFN复制(n * hE / hFFN 向上取整)次;为了促进每个FFN副本的多样性,将FFN的参数进行shuffle;然后,从FFN副本中提取出所有专家的参数,剩余的参数被丢弃;最后,为了在专家中引入额外的随机性,对于每个细粒度专家,其50%的参数被随机重新初始化。
模型参数设置
Intermediate Size表示专家的大小;激活专家数不包括共享专家。

Qwen2-57B-A14B是由Qwen2-7B升级而来。
三、Pre-Training
在Qwen2的预训练中,主要集中在 改进数据集的构建 和 研究如何有效扩展上下文长度。
Pre-Training DATA
Qwen2模型的预训练涉及到一个新的、大规模的、高质量的多语言数据集,该数据集相比以前Qwen和Qwen1.5模型使用的语料库有所改进,在几个关键领域提高预训练数据的规模、质量和多样性:
- 质量提升(Quality Enhancement):通过附加的启发式和基于模型的方法改进数据过滤算法,包括使用Qwen模型来过滤掉低质量的数据,并且利用模型合成高质量的预训练数据。
- 数量扩充(Data Expansion):与Qwen1.5相比收集了大量高质量的代码、数学和多语言数据,以增强模型在各自领域的能力。这个新数据集支持大约30种语言,如英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语和越南语。
- 数据分布(Distribution Improvement):为了确保模型学习类似于人类学习的分布,事先在按比例缩小的模型上进行实验,以优化来自不同来源和领域的数据混合。
基于这些数据增强措施,Qwen1.5中的预训练数据从3T token扩展到7T token。进一步放宽质量阈值尝试构建了12万亿个token数据集,然而,在这个数据集上训练的模型并没有比 7T token模型有显著的性能改进。有人质疑,增加数据量不一定有利于模型预训练,考虑到训练成本,Qwen2选择使用更高质量的7T token数据集来训练更大的模型,为未来的模型迭代留下进一步的探索。
除Qwen2-0.5 b外,所有Qwen2 dense模型都在这个超过7T token的大规模数据集上进行了预训练。Qwen2-0.5B使用12T token数据集进行预训练。根据upcycling(升级回收)的原则,MoE模型接受了额外的4.5T token的预训练。
与之前的Qwen模型类似,Qwen2将高质量的多任务指令数据整合到预训练过程中,以增强情境学习和指令跟随能力。
LONG-CONTEXT TRAINING
为了增强Qwen2的长上下文能力,在预训练的最后阶段将上下文长度从4,096个token增加到32,768个token,这一操作还引入了大量高质量、长数据的补充训练。同时将RoPE的基频从10,000修改为1,000,000,以优化长上下文场景中的推理性能(Xiong et al., 2023)。
为了充分利用模型的长度外推潜力,采用了 YARN 机制(Peng et al., 2023)和 Dual Chunk Attention 机制(An et al., 2024)。这些策略使模型能够处理多达131,072个token的序列,同时保持模型的高性能。
四、Post-Training
在进行了大规模的预训练之后,接下来开始Qwen2的后训练阶段。这个过程对于提高其在通用领域的能力至关重要,包括编码、数学、逻辑推理、指令遵循和多语言理解。此外,确保了模型的生成与人类价值观相一致。与传统方法严重依赖于大量的人类监督数据不同,Qwen2侧重于用最少的人类注释进行可扩展的对齐。
具体而言,主要研究了获取监督微调(SFT)和人类反馈强化学习(RLHF)的高质量数据的方法,旨在最大限度地减少对人工标记的需求(Cao et al., 2024),同时最大限度地提高数据的质量和可靠性。
Post-Training DATA
后训练数据主要包括两部分:监督数据(x, y)和偏好数据(x, y+, y-),在SFT时使用监督数据,在RLHF时使用偏好数据。
训练数据的构建包括两个步骤:人工数据注释(collaborative data annotation)和自动数据合成(automated data synthesis)。首先,从大规模的指令语料库中提取数据本体,从而得到广泛多样的高质量指令集,然后,通过人工标注,得到了目标响应 y 及其正负对应项(y+, y-)。最后,使用一个多样的自动对齐策略来合成大量人工标注的数据。
人工数据注释(collaborative data annotation)
- 自动本体提取(Automatic Ontology Extraction):首先使用InsTagg (Lu et al., 2024c),一种开放集的细粒度的标注器,从大规模指令数据集中提取底层本体。随后通过手工改善确保提取的准确性。
- 指令选择(Instruction Selection):通过多样性、语义丰富度、复杂性和意图完整性四个维度来评估每条被标注的指令。基于这些标准,选择了一组具有代表性的指令 (Dong et al., 2023)。
- 指令进化(Instruction Evolution):为了丰富指令数据集,采用了一种自进化策略(Zhao et al., 2024),促使Qwen模型向现有指令中添加约束或要求,从而增加它们的复杂性,并确保数据集内存在不同的难度级别。
- 人工注释(Human Annotation):使用不同的生成策略和不同规模的Qwen模型,可以获得对一条指令的多个响应。注释者根据他们的偏好对这些回答进行排序,确保最好的回答符合既定标准,从而生成监督数据和偏好数据。
自动数据合成(automated data synthesis)
- 拒绝采样(Rejection Sampling):对于数学任务这类具有明确答案的任务,采用拒绝抽样(Yuan et al., 2023) 来提高解决方案的质量。LLM的任务是为每条指令生成多个响应,即推理路径。保留得出准确结论并被LLM认为合理的路径作为监督数据,偏好数据则通过对比正确和不正确的路径来生成。
- Execution Feedback(执行反馈):对于编码任务,LLM需要生成解决方案和相关的测试用例。这些解决方案的有效性是通过编译和执行测试用例来评估的,从而创建监督数据和偏好数据。这种方法也适用于评估指令遵循 (Dong et al., 2024),例如对于每条有约束的指令,如长度限制,LLM的任务是生成一个Python验证函数,以确保响应符合指令要求。
- Data Repurposing(数据再利用):对于文学写作任务,对于没有经过专门培训的注释者来说具有挑战。为了解决这个问题,收集了来自公共领域的高质量文学作品,并使用LLM来生成具有不同细节水平的指令,这些指令与原始作品相结合,作为监督数据。例如,为了编写具有生动和吸引人的角色扮演数据,从维基百科等知识库中获取详细的角色概况,并指导LLM生成相应的指令和响应(Lu et al, 2024b)。这个过程类似于阅读理解任务,确保了角色的完整性。
- Constitutional Feedback(宪法反馈):宪法人工智能是指指导LLM根据预定义的原则集合生成响应的过程(Bai et al, 2022)。为了确保遵守安全和价值观等指导方针,编写了一个宪法数据集,这个数据集描述了应该遵循的原则和应该避免的原则,用来指导LLM做出与这些指导方针一致或偏离这些指导方针的回应,作为监督数据和偏好数据的参考。
Supervised Fine-Tuning
通过上述操作,组装了一个广泛的指令数据集,其中包含超过500,000个示例,涵盖了诸如指令遵循,编码,数学,逻辑推理,角色扮演,多语言和安全等技能。模型对长度为32,768个token的序列微调了2个epoch。为了优化学习,学习率从7 × 10−6逐渐降低到7 × 10−7,为了解决过拟合问题,将权重衰减设置为0.1,并将梯度裁剪为最大值1.0。
Reinforvement Learning From Human Feekback
RLHF训练包括两个连续的阶段:离线训练和在线训练。在离线训练阶段,使用预编译的偏好数据集P,通过直接偏好优化最大化 y+ 和 y- 之间的似然差(DPO,Rafailov等,2023)。在在线训练阶段,模型迭代地实时改进其性能,利用奖励模型进行即时反馈。具体来说,从当前的决策模型中抽取多个响应,奖励模型选择最受欢迎和最不受欢迎的响应,形成偏好对,用于每一个episode的DPO训练。此外,使用Online Merging Optimizer(Lu等人,2024a)来减轻对齐税。
五、Evaluation
为了全面评估Qwen2模型,包括基础模型和指令调优模型,制定了一个全面的评估方案。该方案考察了一系列能力,包括一般知识理解、语言理解、生成、编码、数学、推理和其他专业领域。具体来说,基本模型是使用大型语言模型(llm)的既定基准数据集进行评估的,除非另有说明,否则通过少量提示得出响应。对于指令调整模型,除了基准评估,优先考虑人类偏好评估。
Base Language Models
Core Capabilities
Benchmarks and Evaluation Protocol(基准和评估协议)
评估基本语言模型核心能力的常见做法是使用少量提示或零提示实现基准数据集评估。
比较 Qwen2-70B 模型:

比较 Qwen2-MoE 模型:

比较 Qwen2-7B 模型:

比较 Qwen2-0.5B 和 Qwen2-1.5B 模型:

Instruction-Tuned Model
Open Benchmark Evaluation
为了全面评估指令调整模型的质量,我们编写了自动和人工评估来评估能力和人类偏好。对于基本能力的评估,我们将类似的数据集应用于预训练模型评估中,其目标是自然语言理解,编码,数学和推理。




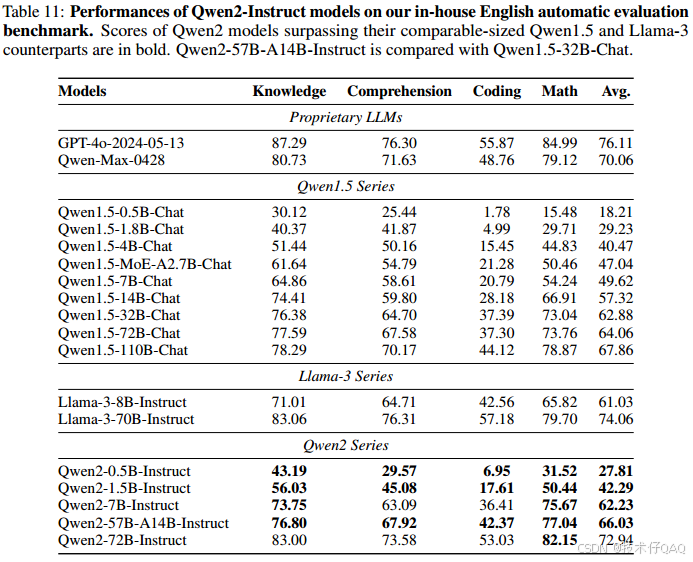
In-house Automatic Evaluation
尽管有许多开放的基准数据集用于评估,但对于完全理解llm的能力是远远不够的。具体来说,通过人工制作了一系列内部数据集来评估模型的不同功能,例如,知识理解、文本生成、编码等,分别使用中文和英文进行评价。
中文评价:

英文评价:

Long Context Capabilities
采用了三种方法来评估长上下文能力: the Needle in a Haystack(NIAH, Kamradt, 2023), NeedleBench (OpenCompass贡献者,2023)和 LV-Eval (Yuan等人,2024)。

六、可能感兴趣的概念
- DCA(Dual Chunk Attention):用于扩展注意力长度以及减少注意力计算复杂度,可以根据任务需求调整块的大小和全局注意力的范围,步骤为分块、局部注意力计算、全局注意力计算、融合局部和全局信息。
- YARN:YARN的出现是为了增强长文本的表示能力,尤其是在处理非常长的上下文时,YARN通过对模型的注意力权重进行动态调整,来重新强调那些对于特定任务和上下文最为重要的部分。具体实现是在注意力层中加入对注意力权重的校准因子,校准因子由Q、K和相对位置信息P计算得到,然后将注意力分数和校准因子相乘得到校准后的注意力分数。
- SwiGLU:SwiGLU(x)=ReLU(x)⊙GLU(x),结合两者的优势:非线性激活+改善训练稳定性
- QKV bias: 通过为Q、K、V引入额外的偏置项来进一步优化模型的性能。具体来说,这些偏置项是额外的可学习参数,它们会加到查询、键和值的计算结果中。这种做法可以帮助模型在处理不同的输入时具有更高的灵活性,因为它能够调整注意力机制的加权方式,改善模型对不同特征的关注程度。
- base frequency of RoPE:具体来说,频率越高,位置间的编码变化就越剧烈。基础频率(base frequency)是用来定义这个变化速率的一个参数,它决定了位置编码在空间中的变化速度。基础频率越大,位置之间的编码差异在较低的位置就变得更为显著;而如果基础频率较小,则编码的变化会变得更加平缓。在长序列中,频率过低可能导致位置信息的编码过于平缓,从而使得长距离的位置关系难以捕捉。而提高基础频率,可以使得位置编码在长序列中更加敏感,从而更好地捕捉长距离依赖。
总结
Qwen2相比较Qwen和Qwen1.5,在模型架构和数据构建上做出了较大的改进,也取得了更好的模型效果,但很多具体的数据构建过程仍然属于黑盒,但好在整个模型结构和数据构建流程属于现在LLM训练的主流过程,我们仍然可以从中借鉴Qwen2的技术思路应用到自己训练或者微调场景。