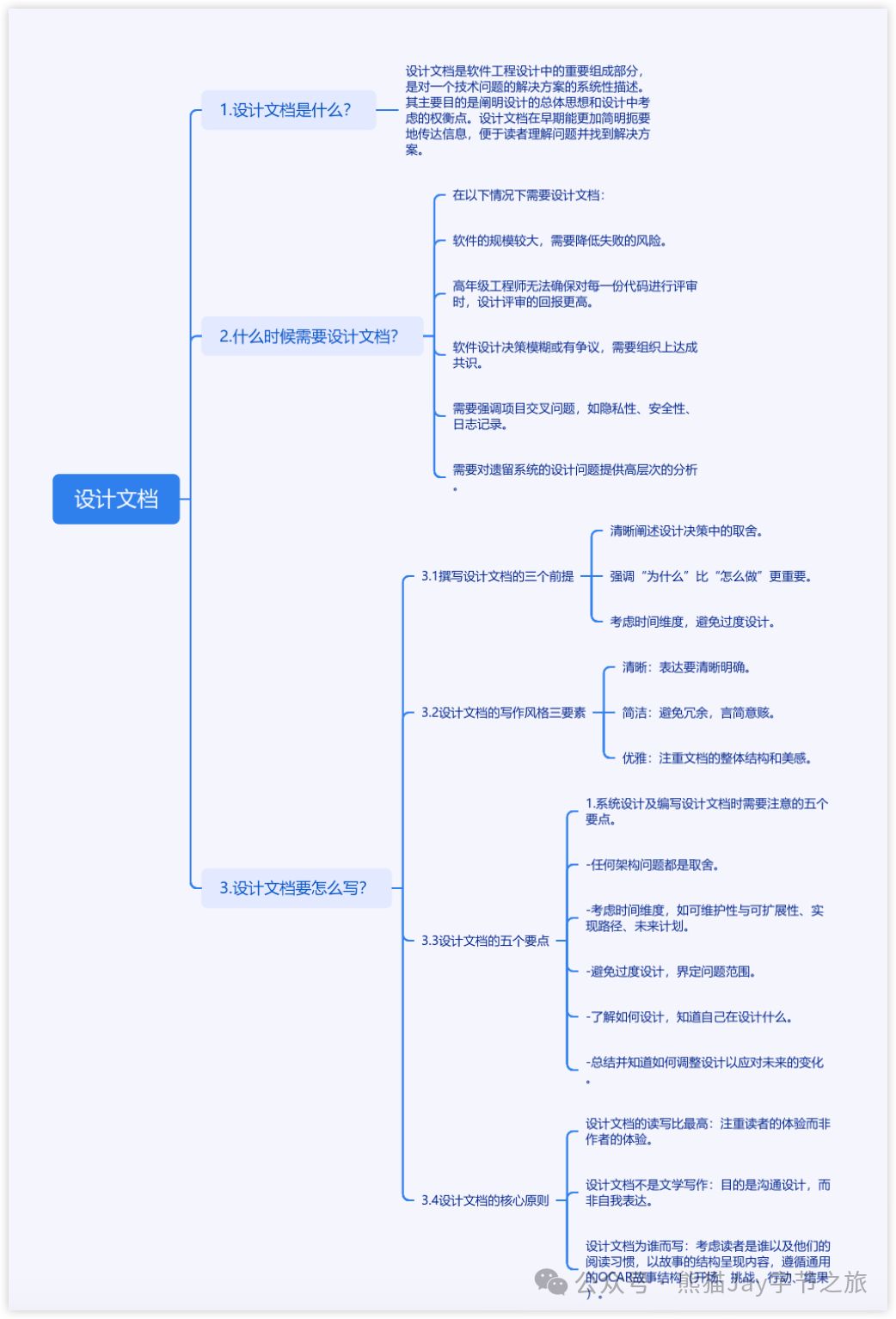
运行模式
单机模式
能够将数据源和规则等元数据信息持久化,但无法将元数据同步至多个Sharding实例,无法在集群环境中相互感知。 通过某一实例更新元数据之后,会导致其他实例由于获取不到最新的元数据而产生不一致的错误。 适用于工程师在本地搭建 Apache ShardingSphere 环境。
支持持久化类型jdbc
集群模式
提供了多个Sharding实例之间的元数据共享和分布式场景下状态协调的能力。 在真实部署上线的生产环境,必须使用集群模式。它能够提供计算能力水平扩展和高可用等分布式系统必备的能力。 集群环境需要通过独立部署的注册中心来存储元数据和协调节点状态。
支持持久化配置ZooKeeper、Etcd
总结一下,这两种模式的主要区别在于,运行多个节点的时候,元数据是否共享。比如,你运行了多个单机模式的proxy,这时候,你登录其中一个proxy节点,去新增一张表,那么这张新增的表,只能够在你操作的proxy节点看到,其他节点是看不到的。其他节点要是想要看到的话,也是有一些办法的,等说过元数据之后,咱们再谈一谈单节点之间如何实现数据的共享。而集群模式则能够实现多个节点的元数据共享,当我们在其中一个节点中新增了一张表,其他节点也能够看到新增的表,因为集群模式下,所有的节点的元数据是同步的。这种同步,是通过ZooKeeper或者Etcd这样的中间件实现的。
元数据
元数据是表示数据的数据。从数据库角度而言,则概括为描述数据库的数据。因此如列名、数据库名、用户名、表名等以及数据自定义库表存储的关于数据库对象的信息都是元数据。而 ShardingSphere 中的核心功能如数据分片、加解密等都是需要基于数据库的元数据生成路由或者加密解密的列实现,由此可见元数据是ShardingSphere 系统运行的核心,同样也是每一个数据存储相关中间件或者组件的核心数据。
也就是说,ShardingSphere-Proxy所提供的一切功能,比如:数据分片、读写分离等,都是对元数据组合利用的结果。功能的背后是需要有数据的支撑的。元数据是非常重要的,所以,需要进行持久化存储,我们不能够因为我们的Sharding重启了,元数据发生了丢失。
元数据持久化
不管是单机模式还是集群模式,都需要将元数据保存下来,需要配置对应的仓库。当元数据仓库和配置文件同时存在的情况下,proxy会优先从元数据仓库中读取信息,之后才从配置文件中读取。
-
单机模式,持久化仓库类型:JDBC
-
集群模式,持久化仓库类型:ZooKeeper、Etcd
-
当然元数据也可以不持久,即单机模式的jdbc,默认采用H2数据库内存形式存储。以这种方式启动的proxy,每次从配置文件中读取信息,创建对应资源和规则的元数据,以内存的形式保存下来。proxy结束运行的时候,内存中对应的元数据也会被销毁。
下方图片是使用MySQL作为元数据持久化仓库的方案,我们可以看到其存储的元数据,使用四列信息来描述:id、key、value、parent

单机模式下如何实现元数据的同步
有好好的集群模式不使用,为什么要在单机模式下,实现元数据的同步?
不是不使用,是因为在一些特殊的场景下,不能够使用官方提供的集群模式。
先来说一说,我所面临的场景:
1. 公司的技术栈是Golang,不想要引入过多的Java生态的中间件。
2. 目前Sharding的集群模式支持ZooKeeper、Etcd。Go的技术栈,自然而让就倾向于使用Etcd,但是Proxy组件,集群模式目前不支持使用Etcd,具体可以看这个issue。
3. 公司目前有K8S集群,能够支持自动伸缩和滚动更新,即使,频繁重启proxy不会造成太大的影响。
所以,公司就想要在K8S上部署多个Proxy副本,并且多个副本的元数据持久化仓库指向同一个,这样就可以通过重启Proxy副本的方式,来使用元数据的同步了(当我们配置了持久化仓库了,重启的proxy会优先从仓库中加载元数据,如果仓库为空,才会从配置文件中加载元数据)。

参考资料:
元数据持久化仓库
元数据在 ShardingSphere 中加载的过程