7月14日,以“释放数智生产力”为主题的 Kyligence 用户大会在上海成功举行。大会现场发布了 Kyligence 最新产品家族:AI 数智助理——Kyligence Copilot 的预览版、一站式指标平台 Kyligence Zen 的 Cloud 和 Enterprise 版本,以及企业级 OLAP 平台 Kyligence Enterprise 的最新版本。
跬智信息(Kyligence)联合创始人兼 CTO 李扬在现场带来了“指标平台 + AI 的技术落地和未来展望”的主题演讲,收获了与会观众的热烈反响,这里特别整理了李扬当天的演讲实录以供参考。目前 Kyligence Copilot 也已经开放申请测试,可在文末访问申请通道。
以下为 李扬 当天演讲实录
刚刚 Luke 演示的 Live Demo 非常精彩,接下来我来分享一下 Kyligence 是如何把指标平台+ AI 技术落地的,以及我们对未来一些关键技术的观点。
人人用数=AI Copilot + 指标体系 + 合理成本
我们先从问题开始,一个最高远“人人用数”的理想。首先,我会先来分享为什么说 Copilot + 指标体系 + 合理成本是一个相对完美的组合,能够达成“人人用数”的目标;然后我将分享几个典型的落地场景,包括 SaaS 模式、本地化部署和嵌入式部署;最后会分享对这些关键技术的未来展望。

指标体系给到我们的是一个通用的数据语言,当我们每一个人都用数据来沟通时,我们遇到的第一个障碍一定是缺乏通用的语言。就像普通话让 13 亿中国人能够自由沟通,数据的解释权有一个标准一致的口径也是非常重要的,是企业数据共享和协作的前提。
AI 助理虽然是最晚来到的,但是却像瓶盖一样、是“人人用数”这个拼图中最关键的一个部分。Kyligence Copilot 提供了一个零门槛的数据工具,比应用最广泛的 Excel 更简单,用户打一行字就能把数据工具连通性的最后一公里解决。
最后是合理的成本,我们看到 AI 非常好,但是大家都在寻找它的落地场景。为什么还在寻找?其实是一个成本的问题,我们可以预见投入 AI 的成本,因此更要让 AI 赋能业务场景,带来更大的价值和回报。
AI 助理、指标体系、合理成本这三个关键部分组合在一起,我们就能看到一个完整的拼图。一个零门槛的数据工具,有统一的数据语言能够高效沟通,最后成本是经济可控的,为企业业务创造了实实在在的价值。Kyligence Copilot、Metrics Store 加上高性能的 OLAP 的引擎,这三者组合在一起,我们就能看到一个完整的拼图,一个人人用数的新时代已经开启。

那这些技术是怎么落地的?大家都知道 Kyligence 是一家技术型公司,我们产品的核心定位就是“指标平台和引擎”。在这个核心以外,我们会拓展一些指标能力,如归因分析、自然语言对接的 Copilot 能力、目标看板等。
中间的两个圈是 Kyligence 的产品路线,也是我们立足的根本。外圈则是支撑到更垂直的行业,比如金融、零售、制造、医药等,我们也希望与更多行业的合作伙伴一起共创,让 Kyligence 产品在更多行业场景落地。
右侧是大语言模型,Kyligence 不会做通用大语言模型,但是我们会在通用大模型的基础上,做领域的语言模型。就像学生会先接受通识教育,再去深入研究某一个专业领域一样,Kyligence Copilot 就是在大语言模型基础之上,成为指标分析、数据分析的专业数智助理,就好像在 Live Demo 中看到的,能够客观地帮助企业做数据分析,助力企业的业务决策和经营管理。
落地方案
SaaS|本地化部署|嵌入式部署
在分享了 Kyligence 的定位后,我们再来看看 Kyligence 指标平台 + AI 的落地方案。
- SaaS
刚刚 Live Demo 展示的其实就是 SaaS 版本,这个产品的核心是 Kyligence 指标平台和引擎,Kyligence Enterprise 是我们的 OLAP 引擎,Kyligence Zen 就是我们今天推出的指标平台产品,周围我们可以看到一些围绕着平台的能力像归因分析、目标看板、仪表盘和今天大家比较关注的 Copilot。

聊到 SaaS 不得不说到数据安全,Kyligence 怎么保证让用户放心地把数据交给我们?
- 首先整个 Kyligence Zen 的生产域是与 Kyligence 办公域是完全隔离的,包括我自己也没有权限访问生产环境。
- 数据存储和计算资源都是按照组织来隔离的,比如说有不同的公司来申请注册,每一位申请到的组织的资源都是与其他的组织完全隔离的。
- 数据全程加密,不管是数据存储还是传输,全程都有加密管控,只有客户和 Zen 的应用程序能够接触到数据、处理数据。
- 所有对生产环境的访问都有流程来保证审计和留痕的审查,我们有SOC 2 Type 2 和 ISO 认证来保证合规和安全可靠。
SaaS 版本是最容易体验到 Kyligence Zen 新一代数据分析能力的途径,欢迎大家在文末申请 Kyligence Zen 的试用。
- 本地化部署方案
对于企业而言,数据安全是无价的,以金融行业为代表,很多企业也希望有本地部署的方案。我们先来聊聊数据怎么能够不离开企业的本地环境?在真实场景中,最简单的思路就是把大语言模型移到企业的私有域来,但事实上在现阶段落地的时候可能会遇到一个问题:ChatGPT 代表了行业的最高水平,如果我们在落地时用了一个替代的模型,它的能力会不会比 ChatGPT 弱一些?
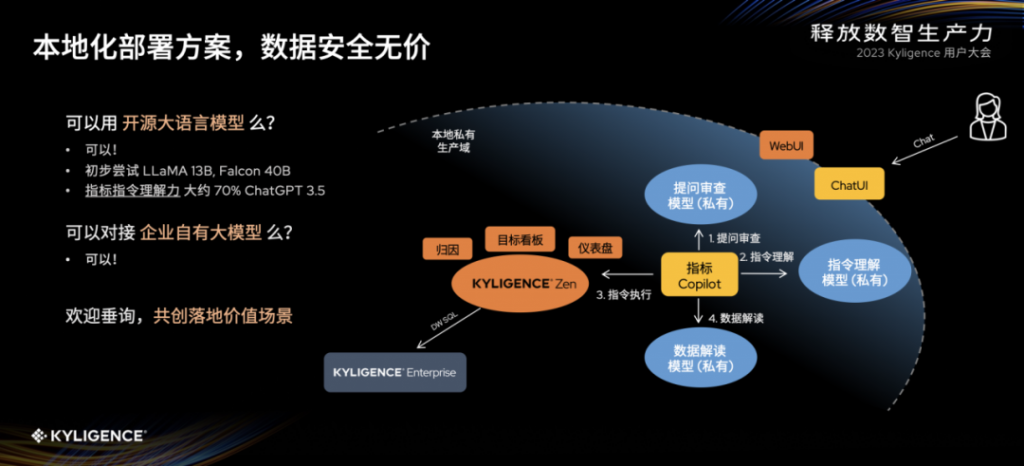
这种情况确实可能发生,那么在弱一些的前提下,我们怎么能够保证语言理解能力、可靠的性能呢?我们可以把 Copilot 的这个行动拆解成为几个语言行为,其实每一个局部的语言行为上我们可能不需要那么强大和完善的通用语言能力。
那也就是说,当我们把范围缩小,就可以适当降低对通用模型的要求。举个具体的例子,Kyligence Copilot 执行一个指令的时候,其实分三步:
- 第一步是提问审查,去看提问的问题是否合法合规、符合逻辑等,这是第一次和语言模型的对话。
- 第二步是指令理解,把用户请求去映射成一个指标平台的具体动作,这步通常比较难,用户对业务需求的表达是多种多样的。
- 第三步是指标平台进行指令的执行,可能是归因分析、目标看板等等,这一步得到的只是数据。
- 第四步是用一个语言模型把这个数据、图表进行自然语言的解读,将重点鲜明的洞察反馈给用户。
在实际落地中,企业既可以用三个局部的小模型来代替一个通用的大模型,这使得现阶段落地成为一个比较可靠、可行的方案;当然如果企业有一个大模型能够完成这三个任务的话也是可以的。以上就是指标平台 + AI 在本地部署比较可行的方案。
大家看到 ChatGPT 的能力是相当不错的,那其他大模型在理解力、性能这方面的表现如何?我们也帮大家做了一些测试和调研,我们用开源的大语言模型代替 ChatGPT 进行了一些初步的尝试,比如 LLaMA 13B 和 Falcon 40B 在测试指令理解能力这个方面大概可以达到 ChatGPT 3.5 的 70% 左右的能力,这可以理解为目前企业希望在本地落地大语言模型指标 Copilot 的最低能力范围。
国内有很多大语言模型的供应商,经过我们的初步调研,目前大语言模型的接口还是比较统一和通用的。如果企业自有或者采购了大模型,Kyligence 也是快速进行合作和对接的。如果您希望在您的企业落地刚刚看到的能力,我们欢迎大家来与我们的前线人员进行交流,Kyligence 可以和大家一起共创。
- 嵌入式方案
Luke 刚刚提到了 Copilot as a Service,这是第三种可落地的方案。我们可以把 Copilot 的自然语言能力,快速嵌入到企业自己开发的系统中。Kyligence 是以指标平台为核心,周围布局了一些指标能力,这些能力都以开放 API 组件化的方式来设计和提供,可以变成企业应用的一部分直接服务客户,同时也可以嵌入到我们合作伙伴的行业解决方案、大企业内部的企业数据平台里面等。

我们将大家看到 Kyligence Zen 的归因分析、Copilot、目标看板等能力称之为开放的数据产品。从技术角度看,我们有类 YAML 的开放式指标定义语言 ZenML;同时我们有开放式 API,Web 小组件、Copilot as a Service (ChatUI) 都是可嵌入式的控件。
只需要十行代码,就能够把 Copilot 这样的能力嵌入到企业现有的应用中。这些操作指南大家可以在 Kyligence Zen 的使用手册上看到,这也适用于各种 SaaS 应用、行业私有化的解决方案和企业内部的数据系统。
关键技术的未来展望
分享了主要的部署方案,我沿着刚刚的指标体系、Copilot 和成本合理的 OLAP 引擎来进一步展望下我们对这几个关键技术和方向的看法。
- 指标体系
先说指标体系,我觉得很有意思的一点是在我们的实践当中我们慢慢发现,当每一个人都可以使用这个数据的时候,数据的治理变成一个更难的问题。我们说有序和创新其实是一对矛盾。最严格的数据治理就是严格管控的,整个企业范围里面都标准化的指标体系,它有好处就是管理严格,但是也会扼杀创新。

很多企业都希望能够找到一些可参考、可复制的指标体系,快速复制一个已经被验证过的成功,这是有序的部分。有了基础,紧接着第二步就是创新,企业有自己业务的特色,基于行业的通用指标体系以外还希望有所创新。如何在有序和创新中找到平衡点,我们发现指标体系是一个很不错的工具。Kyligence Zen 是一个低代码的指标平台,能够帮助大家在通用的指标体系之上,快速沉淀基于业务创新的指标体系,实现快速的复制与推广,抬升行业数智管理的基线。
- AI Copilot

从语言模型训练的稳定性角度来说,指标的语言能力肯定是属于 NLP To SQL 的一个子领域。我们觉得这个限定在指标领域的方向会率先成熟,因为 SQL 作为一个查询语言,自由空间度是无限大的,自然语言的自由度也是无限大的,稳定性势必会存在问题。
但是我们如果把这个问题的目标领域缩小,比如聚焦在企业最关心的那一部分指标,基于这些指标企业会进行一些归因分析、跨时间段、跨维度的分析。所以当我们将其限制到一个目标领域后,整个语言模型到指标平台领域的指令训练的映射就会容易很多。所以 Kyligence 实践下来,也对我们产品的稳定性和准确性有相当大的信心。
最后,我们有一套把大语言模型在这个基础上训练成领域指标模型的一套工具和能力,叫做 Byzer-LLM 工具箱,从基础的模式开始可以做 Prompt-tune,加上用户自己的数据形成指标知识库来做 Fine-tune,最后变成可用的指标领域的语言模型,这套工具链我们也在持续的孵化中,现在已经可以初步使用。
- 合理成本
当人人开始用数,当沟通障碍也被指标标准语言所解除,我们可以预期,分析引擎的负载可能会有百倍乃至千倍的增长。IT 部的负责人可能就开始算钱了,企业当下支持多少并发,如果资源也要成倍的投入,那成本可能就大大超出预期。这也是 Kyligence 一直在持续耕耘的方向,即如何用一个超高并发的 OLAP 引擎技术支撑百倍的负载。

此外,我们还在持续推进计算引擎的性能,我们研发的向量化的 Spark 引擎技术 Kyligence Turbo,已经把标准的 Spark 提速 2 倍以上,可以帮助企业节省 50% 左右的算力和成本。

我们基于 TPC-H 100 测试,Kyligence Turbo 相比 Apache Spark SQL 3.3.1 耗时下降 55.72%,这个测试可以在 AWS EC2 上稳定复现。对技术感兴趣的朋友可以访问 Kyligence Turbo 的主页,上面开源了整个测试过程,可以重现这个实验。我们将持续孵化这项新技术,期望今天所有用到 Spark 的场景,在向量化引擎的加持下,都可以收获立竿见影的 100% 的性能提升,或者 50% 的成本下降。

在 OLAP 引擎这个方面,我们应该面向成本来做优化。南京大学在去年发布的论文中提到,企业来评估 OLAP 引擎时,不应该只考虑性能,因为在云上资源弹性以后,只要钱到位,性能总是能达到的。我们更应该从成本的角度来看,这篇论文中做了一个简单的验证,横轴为查询数量,可以看到用了 Kylin 的 OLAP 引擎成本是比较稳定的。Kyligence 可以承接百倍的负载,我们的引擎会非常有优势。
总之,我们看到在 Copilot + 指标平台 + 高并发的 OLAP 引擎这三个技术点同时到位时,一个人人用数的新时代已经开启,大家可以很快体验到 SaaS 版本,同时也可以本地部署或嵌入式的模式赋能到大家的应用系统。Kyligence Zen 和 Kyligence Copilot 现已开启试用,欢迎大家点击链接申请试用。
关于 Kyligence
跬智信息(Kyligence)由 Apache Kylin 创始团队于 2016 年创办,是领先的大数据分析和指标平台供应商,提供企业级 OLAP(多维分析)产品 Kyligence Enterprise 和一站式指标平台 Kyligence Zen,为用户提供企业级的经营分析能力、决策支持系统及各种基于数据驱动的行业解决方案。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售、医疗等行业客户,包括建设银行、平安银行、浦发银行、北京银行、宁波银行、太平洋保险、中国银联、上汽、长安汽车、星巴克、安踏、李宁、阿斯利康、UBS、MetLife 等全球知名企业,并和微软、亚马逊云科技、华为、安永、德勤等达成全球合作伙伴关系。Kyligence 获得来自红点、宽带资本、顺为资本、斯道资本、Coatue、浦银国际、中金资本、歌斐资产、国方资本等机构多次投资。