Fine-tuning
微调(Fine-tuning)是一种迁移学习的方法,用于在一个预训练模型的基础上,通过在特定任务的数据上进行有监督训练,来适应该任务的要求并提高模型性能。微调利用了预训练模型在大规模通用数据上学习到的语言知识和表示能力,将其迁移到特定任务上。
微调可以在整个神经网络上执行,也可以仅在其部分层上执行,此时未进行微调的层会被“冻结”(在反向传播步骤中不更新)。微调通常通过监督学习完成,但也有使用弱监督进行模型微调的技术。微调可以与基于人类反馈的强化学习目标相结合,以生成像ChatGPT(GPT-3的微调版本)和Sparrow等模型。
对于在大型和通用语料库上进行预训练的模型,通常通过重用模型的参数作为起点。对整个模型进行微调也很常见,通常会产生更好的结果,但计算成本更高。
指令微调
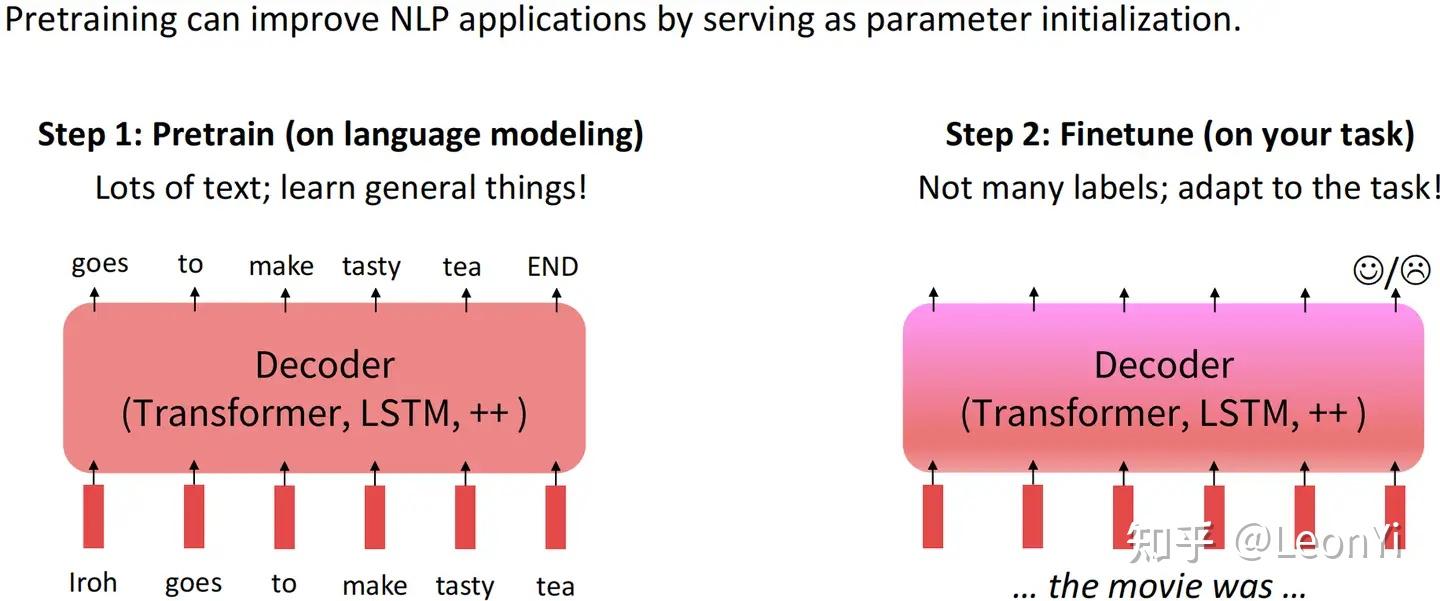
在大量通用数据上进行预训练语言模型训练,然后再针对特定下游任务进行微调,达到领域适应(迁移学习)的目的,是NLP目前的主流范式。

指令微调在预训练语言模型微调的基础进行优化,其目的是尽量让下游任务的形式尽量接近预训练任务。
指令微调的效果要优于基于Zero/Few-shot的提示词工程的上下文学习。,但随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。
- 全参微调Qwen2-7B预估要2张80GB的A800,160GB显存
- 全参微调Qwen2-72B预估要20张80GB的A800,至少1600GB显存
为了寻求一个不更新LLM全部参数的廉价微调方案,大家开始探索预训练语言模型的高效微调(Parameter Efficient Fine-Tuning, PEFT)
PEFT
微调和参数高效微调 (PEFT)是机器学习中用于提高预训练模型在特定任务上的性能的两种方法。
微调就是把一个预先训练好的模型用新的数据在一个新的任务上进一步训练它。整个预训练模型通常在微调中进行训练,包括它的所有层和参数。这个过程在计算上非常昂贵且耗时,特别是对于大型模型。
参数高效微调 (PEFT)是一种专注于只训练预训练模型参数的子集的微调方法。这种方法包括为新任务识别最重要的参数,并且只在训练期间更新这些参数。这样,PEFT可以显著减少微调所需的计算量。
Parameter-Efficient Fine-Tuning(PEFT)是一种微调策略,旨在仅训练少量参数使模型适应到下游任务。对大规模PLM(pre-trained language models )进行微调的成本往往高得令人望而却步。在这方面,PEFT方法只微调了少量(额外的)模型参数,从而大大降低了计算和存储成本。最近最先进的PEFT技术实现了与完全微调相当的性能。
PEFT通过冻结预训练模型的某些层,并仅微调特定于下游任务的最后几层来实现这种效率。这样,模型就可以适应新的任务,计算开销更少,标记的例子也更少。
PEFT旨在提高预训练模型(如BERT和RoBERTa)在各种下游任务上的性能,包括情感分析、命名实体识别和问答。它在数据和计算资源有限的低资源设置中实现了这一点。它只修改模型参数的一小部分,并且不容易过度拟合。在计算资源有限或涉及大型预训练模型的情况下特别有用。在这种情况下,PEFT可以在不牺牲性能的情况下提供一种更有效的方法来微调模型。
然而,需要注意的是,PEFT有时可能会达到与完全微调不同的性能水平,特别是在预训练模型需要进行重大修改才能在新任务上表现良好的情况下。
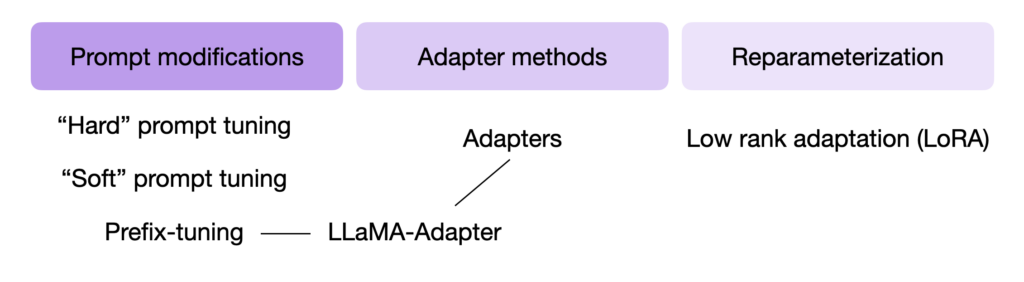
PEFT可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。

- Additive methods: 使用额外的参数或层来增强现有的预训练模型,并且仅训练新添加的参数
- 选择性层调整(Selective Layer Tuning):可以只微调层的一个子集,而不是微调模型的所有层。这减少了需要更新的参数数量。
- 适配器(Adapters):适配器层是插入预训练模型层之间的小型神经网络。在微调过程中,只训练这些适配器层,保持预先训练的参数冻结。通过这种方式,适配器学习将预先训练的模型提取的特征适应新任务。
- 低秩近似(Low-Rank Approximations):用一个参数较少但在任务中表现相似的模型来近似微调后的模型。
- Soft Prompts:通过在模型输入嵌入中添加可训练的张量(软提示)来优化模型行为,将离散空间中的提示寻找问题转化为连续优化问题。
- Prefix-Tuning:与软提示类似,但在所有层的隐藏状态中添加可训练参数。
尽管提出了这么多方法,复杂的方法很少用,实际使用最多就是LoRA,因为架构简单、效果不错,便于实现和推理。
但接下来还是会大致介绍如下几个具体的PEFT方法
- BitFit
- Adatper Tuning
- Prompt Tuning
- LoRA
BitFit
一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数
对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
在Bert-Base/Bert-Large这种模型里,bias参数仅占模型全部参数量的0.08%~0.09%。但是通过在Bert-Large模型上基于GLUE数据集进行了 BitFit、Adapter和Diff-Pruning的效果对比发现,BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning想当,甚至在某些任务上略优于Adapter、Diff-Pruning。
BitFit微调结果相对全量参数微调而言, 只更新极少量参数的情况下,在多个数据集上都达到了不错的效果,虽不及全量参数微调,但是远超固定全部模型参数的Frozen方式。对微调机制的一种积极探索,仅通过调整bias效果就能有不错的效果,但没有具体阐述原理,就是通过猜测加实验得到的结果。同时,作者提出一个观点:微调的过程不是让模型适应另外的数据分布,而是让模型更好的应用出本身的表征能力。
Adapter Tuning
Parameter-Efficient Transfer Learning for NLP
该论文设计了Adapter结构,并将其嵌入Transformer的结构里面,针对每一个Transformer层,增加了两个Adapter结构(分别是多头注意力的投影之后和第二个feed-forward层之后),在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构和 Layer Norm 层进行微调,从而保证了训练的高效性。

每个 Adapter 模块主要由两个前馈(Feedforward)子层组成,第一个前馈子层(down-project)将Transformer块的输出作为输入,将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d。然后,中间通过一个非线形层。在输出阶段,通过第二个前馈子层(up-project)还原输入维度,将m(低维特征)重新映射回d(原来的高维特征),作为Adapter模块的输出。同时,通过一个skip connection来将Adapter的输入重新加到最终的输出中去,这样可以保证,即便 Adapter 一开始的参数初始化接近0,Adapter也由于skip connection的设置而接近于一个恒等映射,从而确保训练的有效性。
h ← h + f ( h W d o w n ) W u p h←h+f(hW_{down} )W_{up} h←h+f(hWdown)Wup
通过实验发现,只训练少量参数的Adapter方法的效果可以媲美全量微调,这也验证了Adapter是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。
Adapter通过引入0.5%~5%的模型参数可以达到不落后全量微调模型1%的性能。
这个方法的不足在于:需要修改原有模型结构,同时还会增加模型参数量。
在这个的基础上有一些后续工作:
- AdapterFusion:https://arxiv.org/abs/2005.00247
- AdapterDrop:https://arxiv.org/abs/2010.11918
Prompt Tuning
Prompt Tuning设计了一种prefix prompt方法,即在模型输入的token序列前添加前缀prompt token,而这个前缀prompt token的embedding是由网络学到。它相当于仅用prompt token的embedding去适应下游任务,相比手工设计或挑选prompt,它是一种Soft的prompt(软提示)
在针对下游任务微调时,Prompt Tuning将冻结原始LLM的参数,只学习独立的prompt token参数(参数化的prompt token加上输入的token送入模型进行前向传播,反向传播只更新prompt token embedding的参数)。
在针对不同的下游任务微调时,就可以分别学习不同的Task Specifical的Prompt Token参数,Soft Prompt Tuning在模型增大时可以接近Model Tuning(fine-tuning)的效果。
Promot Tuning在输入序列前缀添加连续可微的软提示作为可训练参数,其缺点在于:由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。
LoRA
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的intrinsic rank,因此,论文的作者认为权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。
技术原理
LoRA(LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。

可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。

在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx。第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。
h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+ΔWx=W_0x+BAx h=W0x+ΔWx=W0x+BAx
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间,关于秩的选择,通常情况下,rank为4,8,16即可。

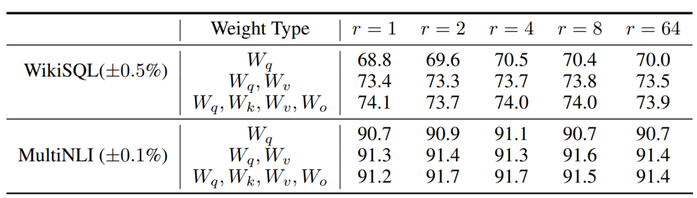
在众多数据集上LoRA在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。
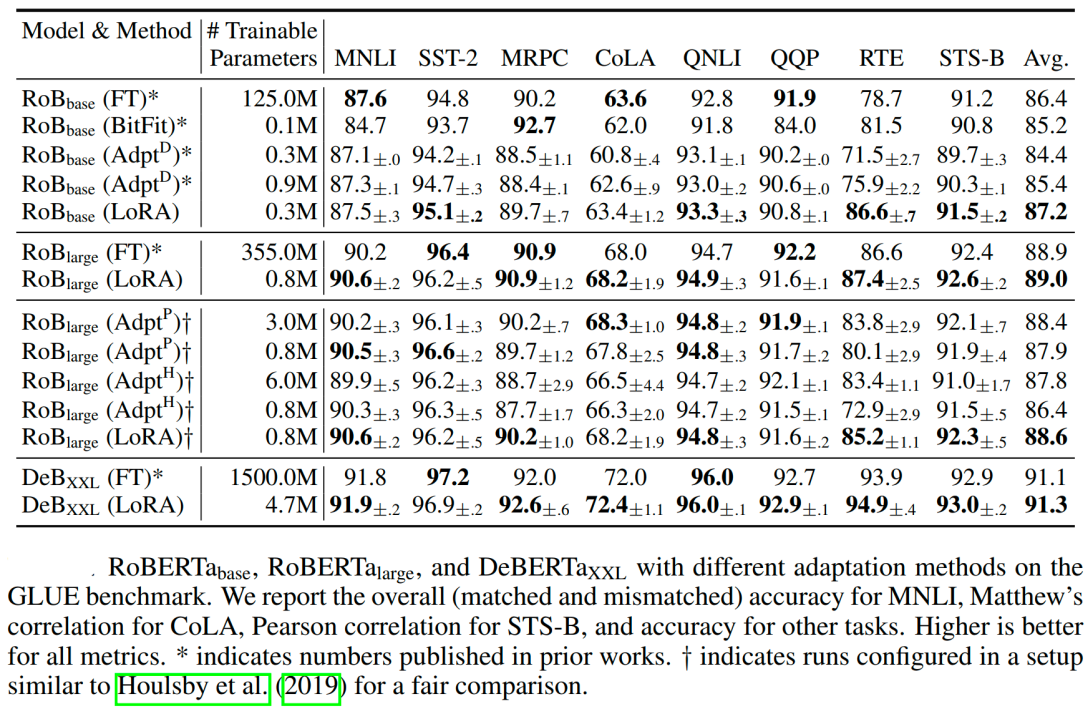
后续还有很多在其基础上的改进,这里不再具体介绍
- AdaLoRA:https://arxiv.org/abs/2303.10512
- QLoRA:https://arxiv.org/abs/2305.14314
MAM Adapter
Towards a Unified View of Parameter-Efficient Transfer Learning 在Adapter、Prefix Tuning和LoRA之间建立联系的统一方法。
为什么看起来Adapter、Prefix Tuning、LoRA(在结构上和公式上)都不太一样,尤其是Prefix Tuning,但是这三种方法有近似的效果?基于此,作者分解了当下最先进的参数高效迁移学习方法(Adapter、Prefix Tuning和LoRA)的设计,并提出了一种新方法MAM Adapter,一个在它们之间建立联系的统一框架。具体来说,将它们重新构建为对预训练模型中特定隐藏状态的修改,并定义一组设计维度,不同的方法沿着这些维度变化。
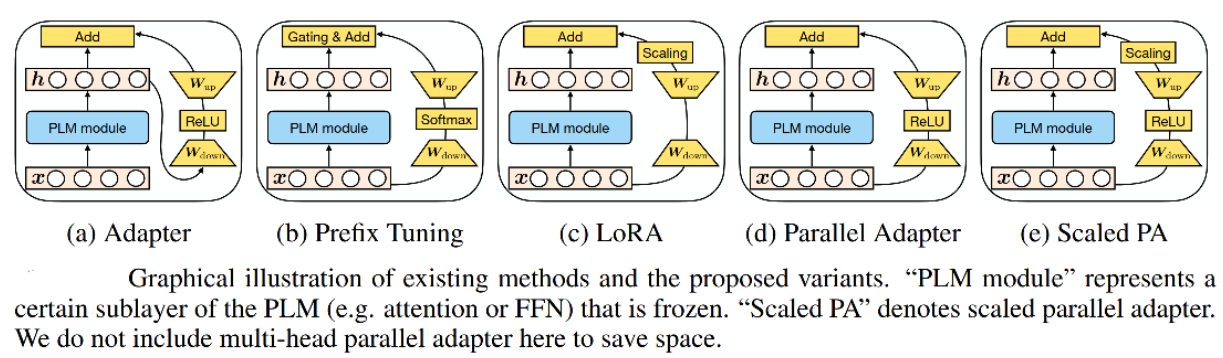
最终的模型 MAM Adapter 是用于 FFN 的并行 Adapter 和 软提示的组合。整体上来说,最终的模型MAM Adapter效果会优于单个高效微调方法。
UniPELT
一种将不同的PELT方法LoRA、Prefix Tuning和Adapter作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。
更具体地说,LoRA 重新参数化用于 WQ 和 WV 注意力矩阵,Prefix Tuning应用于每一Transformer层的key和value,并在Transformer块的feed-forward子层之后添加Adapter。 对于每个模块,门控被实现为线性层,通过GP参数控制Prefix-tuning方法的开关,GL控制LoRA方法的开关,GA控制Adapter方法的开关。可训练参数包括 LoRA 矩阵 WA(Down)和WB(Up),提示调优参数Pk和Pv、Adapter参数和门函数权重。即图中蓝颜色的参数为可学习的参数。
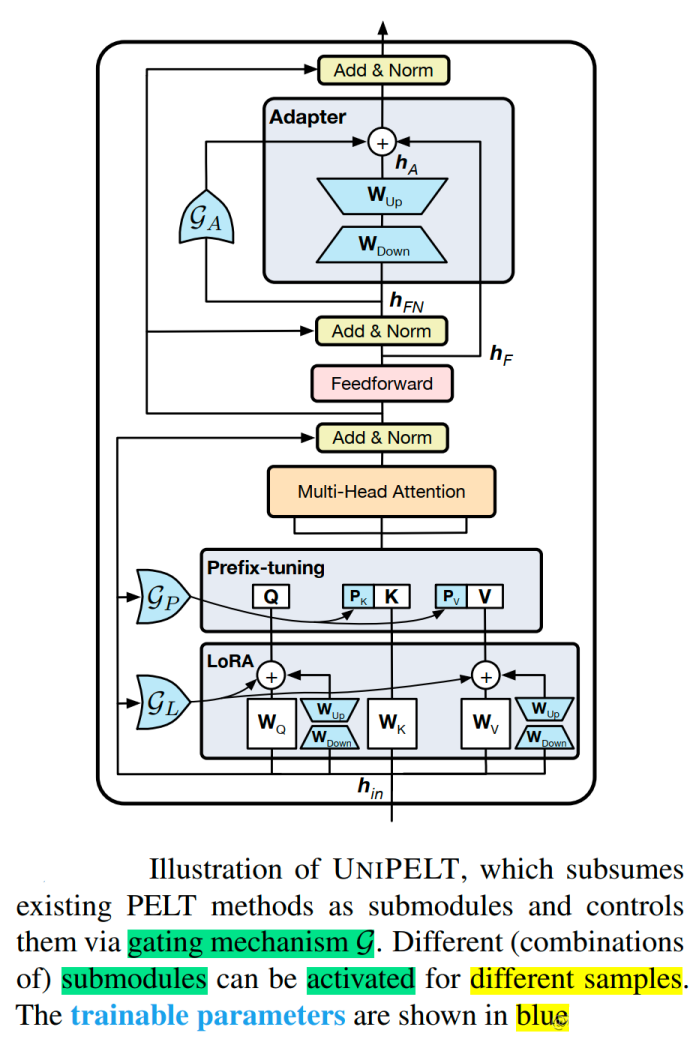
本方法始终优于常规的全量微调以及它在不同设置下包含的子模块,通常超过在每个任务中单独使用每个子模块的最佳性能的上限;并且,通过研究结果表明,多种 PELT 方法的混合涉及到PLM 的不同部分可能对模型有效性和鲁棒性都有好处。
步骤
- 准备数据集:收集和准备与目标任务相关的训练数据集。确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。
- 选择预训练模型/基础模型:根据目标任务的性质和数据集的特点,选择适合的预训练模型。
- 设定微调策略:根据任务需求和可用资源,选择适当的微调策略。
- 设置超参数:确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。
- 初始化模型参数:根据预训练模型的权重,初始化微调模型的参数。
- 进行微调训练:使用准备好的数据集和微调策略,对模型进行训练。在训练过程中,根据设定的超参数和优化算法,逐渐调整模型参数以最小化损失函数。
- 模型评估和调优:在训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。这有助于提高模型的性能和泛化能力。
- 测试模型性能:在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。这有助于评估模型在实际应用中的表现。
- 模型部署和应用:将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。
显存需求
要确定进行全参数微调所需的显存量,需要考虑以下几个因素:
- 模型的大小:模型的大小是影响所需显存量的一个主要因素。较大的模型通常需要更多的显存来存储模型的参数和中间计算结果。
- 批次大小(Batch Size):较大的批次大小通常需要更多的显存,因为模型需要同时存储和处理更多的输入数据。批次大小的选择通常是根据显存容量和性能需求进行平衡的。
- 输入序列长度:如果任务涉及到处理长序列文本,例如长篇文章或整个文档,那么输入序列的长度也会对显存需求产生影响。较长的序列需要更多的显存来存储序列的表示和中间计算结果。
- 计算平台和优化:不同的计算平台和深度学习框架可能在显存使用方面存在差异。一些框架可能会提供显存优化的功能,例如梯度检查点(Gradient Checkpointing)或混合精度训练(Mixed Precision Training),以减少显存的使用。
通常,大型模型和较大的批次大小可能需要较大的显存容量。建议在进行微调之前评估和测试所用计算平台的显存容量,并根据实际情况进行调整。
以Qwen为例:https://github.com/QwenLM/Qwen/blob/main/recipes/finetune/deepspeed/readme.md
| Setting | Full-parameter | LoRA | Q-LoRA |
|---|---|---|---|
| Base | Yes (up to ZeRO3) | Yes (up to ZeRO2) | No |
| Chat | Yes (up to ZeRO3) | Yes (up to ZeRO3) | No |
| Chat-Int4/8 | No | No | Yes |
Here are some useful suggestions for choosing different fine-tuning settings based on GPU memory, espcially for users with GeForce RTX 3090/4090 (24GB) GPUs (or similar), and A100 (80GB) GPUs (or similar). In the experiments, we uniformly use a batch size of 1, gradient accumulation of 16, and max length of 512. Other parameters are set as the same shown in our notebooks. The results are as follows.
| GPU Memory | Number of GPUs | Qwen-1.8B-Chat | Qwen-7B-Chat | Qwen-14B-Chat | Qwen-72B-Chat |
|---|---|---|---|---|---|
| 24GB | *1 | Full Parameter | LoRA | Q-LoRA | N/A |
| 24GB | *2 | Full Parameter | LoRA | Q-LoRA | N/A |
| 24GB | *4 | Full Parameter | LoRA | LoRA (w/ ZeRO3) | N/A |
| 80GB | *1 | Full Parameter | LoRA | LoRA | Q-LoRA |
| 80GB | *2 | Full Parameter | Full Parameter (w/ ZeRO3) | LoRA (w/ ZeRO2) | TBD |
| 80GB | *4 | Full Parameter | Full Parameter (w/ ZeRO2) | Full Parameter (w/ ZeRO3) | LoRA (w/ ZeRO3) |
Using other configurations of LoRA/Q-LoRA and ZeRO stages will easily result in failures.
参考:
https://github.com/wdndev/llm_interview_note/tree/main
https://zhuanlan.zhihu.com/p/696057719














![[CKS] K8S NetworkPolicy Set Up](https://i-blog.csdnimg.cn/direct/0ce54f17b65a4399a1976f76562862a1.png)