✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙


目录
论文概述
论文贡献
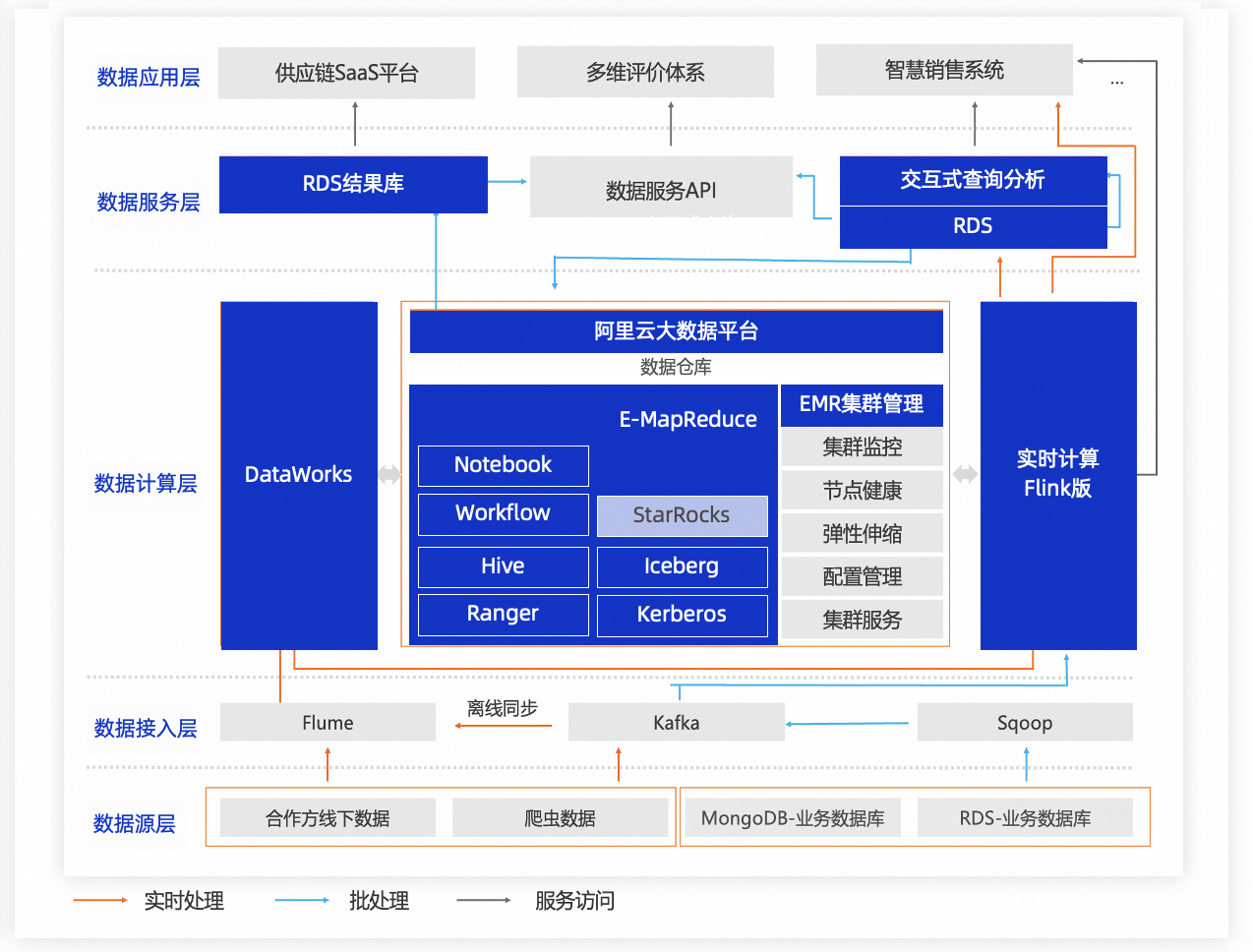
算法流程
实验结果
核心代码复现
main.py文件
multi_label_learn.py文件
使用方法
导入本地数据集
构建多标签学习分类模型
运行模型输出测试指标
测试结果
未来可能的改进方向
环境配置
本文所有资源均可在该地址处获取。
论文概述

-
帕金森病是一种使人虚弱的慢性神经系统疾病。传统中医(TCM)是一种诊断帕金森病的新方法,而用于诊断帕金森病的中医数据集是一个多标签数据集。考虑到帕金森病数据集中的症状(标签)之间总是存在相关性,可以通过利用标签相关性来促进多标签学习过程。目前的多标签分类方法主要尝试从标签对或标签链中挖掘相关性。该文章提出了一种简单且高效的多标签分类框架,称为潜在狄利克雷分布多标签(LDAML),该框架旨在通过使用类别标签的主题模型来学习全局相关性。简而言之,研究人员试图通过主题模型在标签集上获得抽象的“主题”,从而能够挖掘标签之间的全局相关性。大量实验清楚地验证了所提出的方法是一个通用且有效的框架,能够提高大多数多标签算法的性能。基于该框架,研究人员在中医帕金森病数据集上取得了令人满意的实验结果,这可以为该领域的发展提供参考和帮助。
什么是多标签学习

论文贡献
-
提出了一种通用且高效的多标签分类框架——Latent Dirichlet Allocation Multi-Label (LDAML)。该框架通过利用标签间的关联性进行多标签分类。 该框架可以应用于大多数当前的多标签分类方法,使其性能得到提升。通过使用LDAML框架,可以显著提升简单方法(如Binary Relevance, BR)的性能,甚至超过某些最新的方法,同时保持较低的时间成本。 提出的改进LDAML在某些特殊数据集(如帕金森数据集)上取得了最佳性能。特别是在帕金森数据集上,改进的LDAML框架实现了最优性能,达到了本文的最终目标。该方法能够在未来为医生提供指导和帮助。
算法流程
-
挖掘“主题“——提取标签相关性
-
与通过查找标签子集或标签链来利用相关性的传统方法不同,LDAML通过发现标签的抽象“主题”来利用相关性。假设为d维特征向量的输入空间,表示q类标号的输出空间。给定多标签训练集,其中为d维特征向量,为对应的标签集。我们可以将每个实例看作一个文档,每个标签看作文档中的一个单词。直观地说,一定有一些抽象的“主题”,期望特定的标签或多或少地出现在实例中,特别是在包含大量相关标签的多标签数据集中。LDAML算法的主要流程分为两步:(1)从训练集中挖掘标签主题;(2)计算主题的离散分布。
-
从训练集中挖掘标签主题: 首先,我们将LDA引入到训练集d中,每个实例xi表示文档,每个标签表示第i个实例中的第j个标签。然后利用LDA模型生成过程计算实例-主题 θ 的概率分布矩阵,其中 表示第i个实例注入第j主题的概率。
-
主题的离散分布: 计算实例-主题分布矩阵后,得到每个实例属于每个主题的概率值。为了确定实例确切属于哪个主题,我们需要用离散值0/1来代替概率值。在这里我们使用的离散化方法如下所示:


-
再次训练拟合M模型——对真实帕金森病例进行筛查 最后,可以再次使用一种多标签学习模型M对扩增后的训练集D’进行拟合,进一步建立输入数据和输出空间的数据联系。然后对扩增后的测试集t’进行多标签分类,获得输入样本是否患有病症以及其他情况的预测结果。上述过程的整体框架流程图如算法2所示。

实验结果
-
文章在四份数据集上用多种多标签学习分类模型分别加上LDAML算法与其原始模型的分类效果进行对比,实验结果如图所示:




-
以上实验结果表明,LDAML能够在性能和时间成本之间取得良好的平衡。目前的大多数方法都可以应用于LDAML。我们可以采用目前最先进的方法作为LDAML在原始基础上取得突破的基本方法(base model)。另一方面,唯一额外的时间代价是计算主题概率分布矩阵的小词空间。因此,LDAML的时间成本接近于其基础方法的时间成本。通过采用BR或CC等较弱的方法作为基本方法,可以在较低的时间成本下提高接近实际状态的性能。这些结果表明,LDAML是一个通用的框架,可以为具有标签相关性的多标签问题提供鲁棒且更优的解决方案。
核心代码复现
-
由于改论文代码目前尚未开源,因此在本文中我将给出由本人根据论文算法流程一比一复制的复现代码,代码源文件我将放在附件中,其核心逻辑如下:
main.py文件
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500">#########################伪代码###########################</span>
<span style="color:#aa5500"># 导入必要的库</span>
Import libraries
<span style="color:#aa5500"># 定义函数</span>
Function discretize(theta):<span style="color:#aa5500"># 初始化二进制矩阵 YT</span>Initialize YT as a zero matrix with the same shape as thetaFor each row i <span style="color:#770088">in</span> theta:Find the maximum value <span style="color:#770088">in</span> row iFor each column j <span style="color:#770088">in</span> row i:If the difference between the max value and theta[i][j] is less than <span style="color:#116644">1</span>/K:Set YT[i][j] to <span style="color:#116644">1</span>Else:Set YT[i][j] to <span style="color:#116644">0</span>Return YT
Function convert_to_one_hot(data):<span style="color:#aa5500"># 获取唯一值和类别数</span>Find unique values <span style="color:#770088">in</span> dataInitialize one_hot_encoded as a zero matrixFor each value <span style="color:#770088">in</span> data:Find the index of the value <span style="color:#770088">in</span> unique valuesSet the corresponding position <span style="color:#770088">in</span> one_hot_encoded to <span style="color:#116644">1</span>Return one_hot_encoded
Function lda(labels, n):<span style="color:#aa5500"># 进行潜在狄利克雷分配(LDA)</span>Initialize LDA model with n componentsFit and transform labels using LDA modelDiscretize the transformed dataReturn the discretized data
Function metric_cal(test, pred):<span style="color:#aa5500"># 计算并打印评估指标</span>Calculate accuracy, precision, recall, F1 score, and AUCPrint the calculated metrics
<span style="color:#aa5500"># 主程序</span>
If __name__ <span style="color:#981a1a">==</span> <span style="color:#aa1111">"__main__"</span>:<span style="color:#aa5500"># 加载数据</span>Load data from Excel file<span style="color:#aa5500"># 定义标签列和特征</span>Define label_cols and featuresConvert features and labels to NumPy arrays<span style="color:#aa5500"># 设置主题数</span>Set n to <span style="color:#116644">6</span><span style="color:#aa5500"># 对标签进行LDA</span>Call lda <span style="color:#770088">function</span> to <span style="color:#3300aa">get</span> Y_T<span style="color:#aa5500"># 将特征与离散化的标签组合</span>Concatenate features and Y_T to <span style="color:#3300aa">get</span> XYT<span style="color:#aa5500"># 划分训练集和测试集</span>Split XYT and labels into X_train, X_test, y_train, y_test<span style="color:#aa5500"># 初始化多标签分类器</span>Initialize MT_classifier as RankSVM<span style="color:#aa5500"># 从训练集和测试集中提取主题</span>Extract yt_train and yt_test from X_train and X_testRemove last n columns from X_train and X_test<span style="color:#aa5500"># 训练多标签分类器</span>Fit MT_classifier using X_train and yt_train<span style="color:#aa5500"># 预测测试集的主题</span>Predict yt_proba and yt_pred using MT_classifier on X_testConvert yt_pred to integer<span style="color:#aa5500"># 使用预测的主题扩展训练集和测试集</span>Concatenate X_train with yt_train to <span style="color:#3300aa">get</span> X_train_augConcatenate X_test with yt_pred to <span style="color:#3300aa">get</span> X_test_aug<span style="color:#aa5500"># 初始化并训练二进制相关性分类器</span>Initialize base_classifier as MLPClassifierInitialize clf as BinaryRelevance with base_classifierFit clf using X_train_aug and y_train<span style="color:#aa5500"># 预测测试集的标签</span>Predict y_pred and y_score using clf on X_test_aug<span style="color:#aa5500"># 计算评估指标</span>Calculate hamming loss, ranking loss, coverage error, and average precisionPrint calculated metrics<span style="color:#aa5500"># 对每个标签计算并打印评估指标</span>For each label i:Extract test and pred <span style="color:#770088">for</span> label iCall metric_cal <span style="color:#770088">function</span> to calculate and print metricsPrint separatorPrint final separator</span></span>-
在主文件main.py中我复现了LDAML算法的整个流程,并实现了从输入数据到输出评价指标的全过程,在这里默认采用的多标签学习分类起M是RankSVM和二元回归+深度学习。
multi_label_learn.py文件
<span style="background-color:#f8f8f8"><span style="color:#333333"># 定义LIFTClassifier类,继承自BaseEstimator和ClassifierMixin
class LIFTClassifier(BaseEstimator, ClassifierMixin):# 初始化函数,接受一个基本分类器作为参数def __init__(self, base_classifier=DecisionTreeClassifier()):设置base_classifier为传入的参数初始化classifiers字典
# 训练模型函数def fit(self, X, y):获取标签数量遍历每个标签对每个标签训练一个分类器将训练好的分类器存入classifiers字典返回self
# 预测函数def predict(self, X):获取标签数量初始化预测结果矩阵遍历每个标签使用对应的分类器进行预测将预测结果存入预测结果矩阵返回预测结果矩阵
# 预测概率函数def predict_proba(self, X):获取标签数量初始化概率预测结果矩阵遍历每个标签使用对应的分类器进行概率预测将预测概率结果存入概率预测结果矩阵返回概率预测结果矩阵
# 定义MLkNN类
class MLkNN:# 初始化函数,接受一个k值作为参数def __init__(self, k=3):设置k值初始化k近邻模型
# 训练模型函数def fit(self, X, y):保存训练数据X和y使用X训练k近邻模型
# 预测函数def predict(self, X):获取样本数量初始化预测结果矩阵
遍历每个样本获取样本的k+1个最近邻排除样本自身计算邻居标签的和根据标签和判断最终预测结果返回预测结果矩阵
# 预测概率函数def predict_proba(self, X):获取样本数量初始化概率预测结果矩阵
遍历每个样本获取样本的k+1个最近邻排除样本自身计算每个标签的概率返回概率预测结果矩阵
# 定义RankSVM类,继承自BaseEstimator和ClassifierMixin
class RankSVM(BaseEstimator, ClassifierMixin):# 初始化函数,接受参数C, kernel, gammadef __init__(self, C=1.0, kernel='rbf', gamma='scale'):设置C, kernel, gamma值初始化模型列表初始化多标签二值化器
# 训练模型函数def fit(self, X, y):使用多标签二值化器转换y获取标签数量
遍历每个标签将当前标签转换为二值格式使用SVM训练二值化后的标签将训练好的SVM模型加入模型列表
# 预测函数def predict(self, X):初始化预测结果矩阵
遍历每个SVM模型使用模型进行预测将预测结果存入预测结果矩阵返回预测结果矩阵
# 预测概率函数def predict_proba(self, X):初始化概率预测结果矩阵
遍历每个SVM模型使用模型进行概率预测将预测概率结果存入概率预测结果矩阵返回概率预测结果矩阵
# 定义MultiLabelDecisionTree类
class MultiLabelDecisionTree:# 初始化函数,接受参数max_depth, random_statedef __init__(self, max_depth=None, random_state=None):设置max_depth, random_state值初始化标签幂集转换器初始化决策树分类器
# 训练模型函数def fit(self, X, y):使用标签幂集转换器转换y使用转换后的y训练决策树分类器
# 预测概率函数def predict_proba(self, X):使用决策树分类器进行概率预测将预测概率结果转换为原始标签格式返回概率预测结果
# 预测函数def predict(self, X):使用决策树分类器进行预测将预测结果转换为原始标签格式返回预测结果
# 定义MLP神经网络类,继承自nn.Module
class MLP(nn.Module):# 初始化函数,接受输入大小、隐藏层大小和输出大小作为参数def __init__(self, input_size, hidden_size, output_size):调用父类的初始化函数初始化全连接层1初始化ReLU激活函数初始化全连接层2初始化Sigmoid激活函数
# 前向传播函数def forward(self, x):通过全连接层1通过ReLU激活函数通过全连接层2通过Sigmoid激活函数返回输出
# 定义BPMLL类,继承自BaseEstimator和ClassifierMixin
class BPMLL(BaseEstimator, ClassifierMixin):# 初始化函数,接受参数input_size, hidden_size, output_size, epochs, lrdef __init__(self, input_size, hidden_size, output_size, epochs=10, lr=0.0001):设置输入大小、隐藏层大小、输出大小、训练轮数、学习率初始化MLP模型初始化优化器初始化损失函数
# 训练模型函数def fit(self, X_train, X_val, y_train, y_val):将训练数据和验证数据转换为张量创建训练数据集和数据加载器
遍历每个训练轮次设置模型为训练模式遍历训练数据加载器清零梯度前向传播计算损失反向传播更新参数
设置模型为评估模式计算验证损失并打印
# 预测概率函数def predict_proba(self, X):设置模型为评估模式禁用梯度计算进行前向传播返回预测概率结果
# 预测函数def predict(self, X, threshold=0.5):获取预测概率结果根据阈值判断最终预测结果返回预测结果
# 定义RandomKLabelsetsClassifier类,继承自BaseEstimator和ClassifierMixin
class RandomKLabelsetsClassifier(BaseEstimator, ClassifierMixin):# 初始化函数,接受参数base_classifier, labelset_size, model_countdef __init__(self, base_classifier=None, labelset_size=3, model_count=10):设置基本分类器、标签集大小、模型数量初始化RakelD模型
# 训练模型函数def fit(self, X, y):使用RakelD模型训练数据返回self
# 预测函数def predict(self, X):使用RakelD模型进行预测返回预测结果
# 预测概率函数def predict_proba(self, X):使用RakelD模型进行概率预测返回概率预测结果</span></span>同时我在文件multi_label_learning.py中定义了多种不同的多标签学习分类模型,大家可以自行调用相应的函数来进行实验以验证LDAML算法的有效性,使用方法我会在本文对应的视频中进行讲解。
使用方法
导入本地数据集
调用LDAML算法的方法放在main.py文件中,首先我们需要将文件路径修改成自己所要使用的数据集路径。这里我使用的文件路径为’./测试数据.xlsx’,供大家一键运行熟悉项目。然后大家需要将自己的标签列名称提取变量label_cols中,用于对数据集划分特征集合与标签集合。 
构建多标签学习分类模型
构建想要的多标签学习分类算法,这里我给大家复现了多种经典的多标签分类器,如LIFT、MlkNN和RankSVM等,并帮大家配置好了参数,大家可以将想要使用的算法对应行的注释删掉即可(MTM T 和M都是一样)。 
运行模型输出测试指标
设置好这些外在参数后,我们就可以运行代码,主文件将自动调用第三方库和multi_label_learn.py文件中的函数来进行训练和测试。下面是我选取的几种测试指标,分别会输出模型对整体的多标签分类性能指标(Hamming loss、Ranking loss、Coverage error和Average precision)和对单一标签的分类指标(Accuracy、Precision、Recall、F1 Score和AUC)。 
测试结果
下面是在测试数据集上模型的表现:  以上是模型多标签学习分类的性能,Hamming Loss为0.051228070175438595,Ranking Loss为0.016737120579225842,Coverage Error为2.3263157894736843,Average Precision为0.7500066243540565
以上是模型多标签学习分类的性能,Hamming Loss为0.051228070175438595,Ranking Loss为0.016737120579225842,Coverage Error为2.3263157894736843,Average Precision为0.7500066243540565

-
以上是对模型在单一标签下的分类性能测试结果,测试数据集中有十个标签,因此这里会输出十个标签下模型分类的Accuracy、Precision、Recall、F1 Score和AUC,也就是说这样的数据会有十组
 我这里把数据列成表这样大家可以更直观的看到,我换用了不同的多标签学习算法结合LDAML,并比较了它们在Accuracy、AUC和F1-score上的表现。在上面的情况上来看,使用BPMLL在整体对单一标签进行分类时效果相比其他算法更好,但也会在某些标签下弱于其他模型。
我这里把数据列成表这样大家可以更直观的看到,我换用了不同的多标签学习算法结合LDAML,并比较了它们在Accuracy、AUC和F1-score上的表现。在上面的情况上来看,使用BPMLL在整体对单一标签进行分类时效果相比其他算法更好,但也会在某些标签下弱于其他模型。
未来可能的改进方向
-
这一部分是笔者通过思考感觉可以在目前LDAML的基础上进行改进的方面,也就是我想给大家介绍的LSA算法。
潜在语义分析(Latent Semantic Analysis,LSA)是一种用于分析大规模文本数据的统计方法,旨在发现文本中的潜在语义结构并提取其语义信息。LSA假设文本中存在一些潜在的语义结构,即使在词语表达方式不同的情况下,这些结构也会保持一定的稳定性。其基本思想是将文本数据表示为一个矩阵,其中行代表文档,列代表词语,而矩阵中的元素则可以是词频、TF-IDF权重等。接下来,通过奇异值分解(Singular Value Decomposition,SVD)将这个矩阵分解为三个矩阵的乘积: 其中,A是原始文本矩阵,U是文档-概念矩阵,Σ是奇异值矩阵,是词语-概念矩阵的转置。LSA通过保留最重要的奇异值及其对应的左右奇异向量,将文本数据的维度降低到一个更小的空间,从而发现潜在的语义结构,并提取出文本数据的语义信息。
LSA在面对大规模文本数据时,能够有效地提取出其中的潜在语义信息。并且,LSA能发现文本数据中的主题结构并提取出其中的主题信息。受此启发,我们使用LSA对膝骨关节炎标记集合中的十个标记进行相关性计算并提取主题,从而获得标记集合中的高阶信息。相比之下,LSA比LDA更加灵活和简单。LDA对于大规模数据的处理速度较慢,因为它需要对每个词项和主题进行迭代推断,对主题分布和词项分布的先验参数进行设定,而LSA只需进行奇异值分解,不需要对先验参数进行设置,因此更容易实现和调试。LSA在语义上也更为易懂。LDA通过抽样方法从文档中抽取主题,它的主题在语义上可能难以解释,LSA通过奇异值分解从标签数据中提取主题,可以更直观地解释这些主题的含义,更好地反映标签之间的语义关系。
接下来是不是有可能将LSA融入到目前的框架中,或者直接基于LSA开发一种标记相关性提取的算法都是可以尝试的方向,可以留给大家一起去学习探索!
环境配置
-
python3.8或以上版本
-
须事先安装第三方库torch、numpy、sklearn、pandas、skmultilearn
-
可修改变量——主题数n、所用的本地数据集、多标签分类器

-
本文所有资源均可在该地址处获取。

希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!







![[CKS] K8S NetworkPolicy Set Up](https://i-blog.csdnimg.cn/direct/0ce54f17b65a4399a1976f76562862a1.png)