我自己的原文哦~ https://blog.51cto.com/whaosoft/12548542
#DragGAN
在 AIGC 的神奇世界里,我们可以在图像上通过「拖曳」的方式,改变并合成自己想要的图像。比如让一头狮子转头并张嘴:

实现这一效果的研究出自华人一作领衔的「Drag Your GAN」论文,于上个月放出并已被 SIGGRAPH 2023 会议接收。
一个多月过去了,该研究团队于近日放出了官方代码。短短三天时间,Star 量便已突破了 23k,足可见其火爆程度。
GitHub 地址:https://github.com/XingangPan/DragGAN
无独有偶,今日又一项类似的研究 —— DragDiffusion 进入了人们的视线。此前的 DragGAN 实现了基于点的交互式图像编辑,并取得像素级精度的编辑效果。但是也有不足,DragGAN 是基于生成对抗网络(GAN),通用性会受到预训练 GAN 模型容量的限制。
在新研究中,新加坡国立大学和字节跳动的几位研究者将这类编辑框架扩展到了扩散模型,提出了 DragDiffusion。他们利用大规模预训练扩散模型,极大提升了基于点的交互式编辑在现实世界场景中的适用性。
虽然现在大多数基于扩散的图像编辑方法都适用于文本嵌入,但 DragDiffusion 优化了扩散潜在表示,实现了精确的空间控制。
- 论文地址:https://arxiv.org/pdf/2306.14435.pdf
- 项目地址:https://yujun-shi.github.io/projects/dragdiffusion.html
研究者表示,扩散模型以迭代方式生成图像,而「一步」优化扩散潜在表示足以生成连贯结果,使 DragDiffusion 高效完成了高质量编辑。
他们在各种具有挑战性的场景(如多对象、不同对象类别)下进行了广泛实验,验证了 DragDiffusion 的可塑性和通用性。相关代码也将很快放出、
下面我们看看 DragDiffusion 效果如何。
首先,我们想让下图中的小猫咪的头再抬高一点,用户只需将红色的点拖拽至蓝色的点就可以了:

接下来,我们想让山峰变得再高一点,也没有问题,拖拽红色关键点就可以了:

还想让雕塑的头像转个头,拖拽一下就能办到:

让岸边的花,开的范围更广一点:

方法介绍
本文提出的 DRAGDIFFUSION 旨在优化特定的扩散潜变量,以实现可交互的、基于点的图像编辑。
为了实现这一目标,该研究首先在扩散模型的基础上微调 LoRA,以重建用户输入图像。这样做可以保证输入、输出图像的风格保持一致。
接下来,研究者对输入图像采用 DDIM inversion(这是一种探索扩散模型的逆变换和潜在空间操作的方法),以获得特定步骤的扩散潜变量。
在编辑过程中,研究者反复运用动作监督和点跟踪,以优化先前获得的第 t 步扩散潜变量,从而将处理点的内容「拖拽(drag)」到目标位置。编辑过程还应用了正则化项,以确保图像的未掩码区域保持不变。
最后,通过 DDIM 对优化后的第 t 步潜变量进行去噪,得到编辑后的结果。总体概览图如下所示:

实验结果
给定一张输入图像,DRAGDIFFUSION 将关键点(红色)的内容「拖拽」到相应的目标点(蓝色)。例如在图(1)中,将小狗的头转过来,图(7)将老虎的嘴巴合上等等。

下面是更多示例演示。如图(4)将山峰变高,图(7)将笔头变大等等。

#Agent Attention
来自清华大学的研究者提出了一种新的注意力范式——代理注意力 (Agent Attention)。Softmax注意力与线性注意力的优雅融合,推动注意力新升级
近年来,视觉 Transformer 模型得到了极大的发展,相关工作在分类、分割、检测等视觉任务上都取得了很好的效果。然而,将 Transformer 模型应用于视觉领域并不是一件简单的事情。与自然语言不同,视觉图片中的特征数量更多。由于 Softmax 注意力是平方复杂度,直接进行全局自注意力的计算往往会带来过高的计算量。针对这一问题,先前的工作通常通过减少参与自注意力计算的特征数量的方法来降低计算量。例如,设计稀疏注意力机制(如 PVT)或将注意力的计算限制在局部窗口中(如 Swin Transformer)。尽管有效,这样的自注意力方法很容易受到计算模式的影响,同时也不可避免地牺牲了自注意力的全局建模能力。
与 Softmax 注意力不同,线性注意力将 Softmax 解耦为两个独立的函数,从而能够将注意力的计算顺序从 (query・key)・value 调整为 query・(key・value),使得总体的计算复杂度降低为线性。然而,目前的线性注意力方法效果明显逊于 Softmax 注意力,难以实际应用。
注意力模块是 Transformers 的关键组件。全局注意力机制具良好的模型表达能力,但过高的计算成本限制了其在各种场景中的应用。本文提出了一种新的注意力范式,代理注意力 (Agent Attention),同时具有高效性和很强的模型表达能力。
- 论文链接:https://arxiv.org/abs/2312.08874
- 代码链接:https://github.com/LeapLabTHU/Agent-Attention
具体来说,代理注意力在传统的注意力三元组 (Q,K,V) 中引入了一组额外的代理向量 A,定义了一种新的四元注意力机制 (Q, A, K, V)。其中,代理向量 A 首先作为查询向量 Q 的代理,从 K 和 V 中聚合信息,然后将信息广播回 Q。由于代理向量的数量可以设计得比查询向量的数量小得多,代理注意力能够以很低的计算成本实现全局信息的建模。
此外,本文证明代理注意力等价于一种线性注意力范式,实现了高性能 Softmax 注意力和高效线性注意力的自然融合。该方法在 ImageNet 上使 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架构取得了显著的性能提升,能够将模型在 CPU 端加速约 2.0 倍、在 GPU 端加速约 1.6 倍。应用于 Stable Diffusion 时,代理注意力能够将模型生成速度提升约 1.8 倍,并显著提高图像生成质量,且无需任何额外训练。
方法
在本文中,我们创新性地向注意力三元组 (Q,K,V) 引入了一组额外的代理向量 A,定义了一种四元的代理注意力范式 (Q, A, K, V)。如图 1 (c) 所示,在代理注意力中,我们不会直接计算 Q 和 K 之间两两的相似度,而是使用少量的代理向量 A 来收集 K 和 V 中的信息,进而呈递给 Q,以很低的计算成本实现全局信息的建模。从整体结构上看,代理注意力由两个常规 Softmax 注意力操作组成,并且等效为一种广义的线性注意力,实现了高性能 Softmax 注意力和高效线性注意力的自然融合,因而同时具有二者的优点,即:计算复杂度低且模型表达能力强。

图 1:Softmax 注意力、线性注意力与代理注意力机制对比
1. 代理注意力

图 2:代理注意力示意图
上图即为代理注意力的示意图,下面给出具体数学形式。为了书写方便,我们将 Softmax 注意力和线性注意力分别缩写为:

其中 A 为新定义的代理矩阵。

2. 代理注意力模块
为了更好地发挥代理注意力的潜力,本文进一步做出了两方面的改进。一方面,我们定义了 Agent Bias 以促进不同的代理向量聚焦于图片中不同的位置,从而更好地利用位置信息。另一方面,作为一种广义的线性注意力,代理注意力也面临特征多样性不足的问题,因此我们采用一个轻量化的 DWC 作为多样性恢复模块。
在以上设计的基础上,本文提出了一种新的代理注意力模块,其结构如下图:

图 3:代理注意力模块
结合了 Softmax 注意力和线性注意力的优势,代理注意力模块具有以下特点:
(1) 计算复杂度低且模型表达能力强。之前的研究通常将 Softmax 注意力和线性注意力视为两种不同的注意力范式,试图解决各自的问题和局限。代理注意力优雅地融合了这两种注意力形式,从而自然地继承了它们的优点,同时享受低计算复杂性和高模型表达能力。
(2) 能够采用更大的感受野。得益于线性计算复杂度,代理注意力可以自然地采用更大的感受野,而不会增加模型计算量。例如,可以将 Swin Transformer 的 window size 由 7^2 扩大为 56^2,即直接采用全局自注意力,而完全不引入额外计算量。
实验结果
1. 分类任务
代理注意力是一个通用的注意力模块,本文基于 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架构进行了实验。如下图所示,在 ImageNet 分类任务中,基于代理注意力构建的模型能够取得显著的性能提升。例如,Agent-Swin-S 可以取得超越 Swin-B 的性能,而其参数量和计算量不到后者的 60%。

图 4:ImageNet 图片分类结果
在实际推理速度方面,代理注意力也具有显著的优势。如下图所示,在 CPU/GPU 端,代理注意力模型能够取得 2.0 倍 / 1.6 倍左右的加速,同时取得更好的性能。

图 5:实际测速结果
2. 检测和分割
在检测和分割任务中,相较于基础模型,Agent Transformer 也能够取得十分显著的性能提升,这在一定程度上得益于代理注意力的全局感受野。

图 6:COCO 物体检测与分割结果

图 7:ADE20K 语义分割结果
3.Agent Stable Diffusion
特别值得指出的是,代理注意力可以直接应用于 Stable Diffusion 模型,无需训练,即可加速生成并显著提升图片生成质量。如下图所示,将代理注意力应用于 Stable Diffusion 模型,能够将图片生成速度提升约 1.8 倍,同时提升图片的生成质量。

图 8:Stable Diffusion, ToMeSD 和 AgentSD 的定量化结果
下图中给出了生成图片的样例。可以看到,代理注意力能够显著降低 Stable Diffusion 模型生成图片的歧义和错误,同时提升生成速度和生成质量。

图 9:生成图片的样例
4. 高分辨率与大感受野
本文还探究了分辨率和感受野对模型性能的影响。如下图所示,我们基于 Agent-Swin-T 将窗口大小由 7^2 逐步扩大到 56^2。可以看到,随着感受野的扩大,模型性能稳步提升。这说明尽管 Swin 的窗口划分是有效的,但它依然不可避免地损害了模型的全局建模能力。

图 10:感受野大小的影响
下图中,我们将图片分辨率由 256^2 逐步扩大到 384^2。可以看到,在高分辨率的场景下,代理注意力模型持续展现出显著的优势。

图 11:高分辨率场景
总结
本文的贡献主要在三个方面:
(1) 提出了一种新颖、自然、有效且高效的注意力范式 —— 代理注意力,它自然地融合了高性能的 Softmax 注意力和高效的线性注意力,以线性计算量实现有效的全局信息建模。
(2) 在分类、检测、分割等诸多任务中充分验证了代理注意力的优越性,特别是在高分辨率、长序列的场景下,这或为开发大尺度、细粒度、面向实际应用场景的视觉、语言大模型提供了新的方法。
(3) 创新性地以一种无需训练的方式将代理注意力应用于 Stable Diffusion 模型,显著提升生成速度并提高图片质量,为扩散模型的加速和优化提供了有效的新研究思路。
#Skip-Attention
本文提出了SKIPAT方法,该方法利用前面层的自注意力计算来近似在一个或多个后续层的注意力。该工作在ImageNet、Pascal-VOC2012、SIDD、DAVIS和ADE20K数据集上实现了在吞吐量指标上的最SOTA性能,并获得了同等或更高的准确度。一种显著降低Transformer计算量的轻量化方法
Skip-Attention: Improving Vision Transformers by Paying Less Attention
论文:https://arxiv.org/abs/2301.02240
这项工作旨在提高视觉Transformer(ViT)的效率。虽然ViT在每一层中使用计算代价高昂的自注意力操作,但我们发现这些操作在层之间高度相关——这会导致产生很多不必要计算的冗余信息。 基于这一观察,我们提出了SKIPAT方法,该方法利用前面层的自注意力计算来近似在一个或多个后续层的注意力。 为了确保在层之间重用自注意力块而不降低性能,我们引入了一个简单的参数函数,该函数在计算速度更快的情况下能表现出优于基准Transformer的性能。我们在图像分类和ImageNet-1K上的自我监督学习、ADE20K上的语义分割、SIDD上的图像去噪以及DAVIS上的视频去噪中展示了我们方法的有效性。我们在所有这些任务中都在相同或更高的准确度水平下实现了提高模型吞吐量。

Performance of SKIPAT across 5 different tasks.
Transformer架构已经成为一个重要且影响深远的模型系列,因为它简单、可扩展,并且应用广泛。虽然最初来自自然语言处理(NLP)领域,但随着视觉transformer(ViT)的出现,这已成为计算机视觉领域的标准架构,在从表示学习、语义分割、目标检测到视频理解等任务中获得了各种最先进(SoTA)性能。
然而,transformer的原始公式在输入令牌(token)数量方面具有二次计算复杂度。鉴于这个数字通常从图像分类的14^2到图像去噪的128^2 = 16K不等,内存和计算的这一限制严重限制了它的适用性。目前有三组方法来解决这个问题:第一组利用输入令牌之间的冗余,并通过高效的抽样简单地减少计算,例如丢弃或合并冗余令牌。然而,这意味着ViT的最终输出不是空间连续的,因此不能超出图像级别(image-level)的应用,如语义分割或目标检测。第二组方法旨在以低成本计算近似注意力,但通常以性能降低为代价。最后,另一组工作旨在将卷积架构与transformer合并,产生混合架构。虽然这些方法提高了速度,但它们并没有解决二次复杂度的基本问题,并且通常会引入过多的设计选择(基本上是transformer和CNN的联合)。
在这项工作中,我们提出了一种新颖的、迄今为止未经探索的方法:利用计算速度快且简单的参数函数来逼近transformer的计算代价高的块。为了得出这个解决方案,我们首先详细地分析了ViT的关键多头自注意力(MSA)块。通过这项分析,我们发现CLS令牌对空间块的注意力在transformer的块之间具有非常高的相关性,从而导致许多不必要的计算。这启发了我们的方法利用模型早期的注意力,并将其简单地重用于更深的块——基本上是“跳过”后续的SA计算,而不是在每一层重新计算它们。
基于此,我们进一步探索是否可以通过重用前面层的表示来跳过整一层的MSA块。受ResneXt的深度卷积的启发,我们发现一个简单的参数函数可以优于基准模型性能——在吞吐量和FLOPs的计算速度方面更快。我们的方法是通用的,可以应用于任何上下文的ViT:上图显示,我们的跳过注意力(SKIPAT)的新型参数函数在各种任务、数据集和模型大小上都能实现与基准transformer相比更优的精度与效率。
综上所述,我们的贡献如下所示:
- 我们提出了一种新型的插件模块,可以放在任何ViT架构中,以减少昂贵的O(n^2)自注意力计算复杂度。
- 我们在ImageNet、Pascal-VOC2012、SIDD、DAVIS和ADE20K数据集上实现了在吞吐量指标上的最SOTA性能,并获得了同等或更高的准确度。
- 我们的方法在没有下游准确度损失的情况下,自监督预训练时间能减少26%,并且在移动设备上展示了优越的延迟,这都证明了我们方法的普适性。
- 我们分析了性能提升的来源,并对我们的方法进行了大量的实验分析,为提供可用于权衡准确度和吞吐量的模型系列提供了支持。
方法

SKIPAT framework.
引言
Vision Transformer
设x ∈ R^(h×w×c) 为一张输入图像,其中h × w是空间分辨率,c是通道数。首先将图像分成n = hw/p^2个不重叠的块,其中p × p是块大小。使用线性层将每个块投影到一个embedding zi ∈ R^d 中,从而得到分块的图像:

Transformer Layer
Transformer的每一层由多头自注意力(MSA)块和多层感知机(MLP)块组成。在MSA块中,Zl−1 ∈ R^(n×d),首先被投影到三个可学习embeddings {Q, K, V } ∈ R^(n×d)中。注意力矩阵A的计算公式如下:

MSA中的“多头”是指考虑h个注意力头,其中每个头是一个n × d/h 矩阵的序列。使用线性层将注意头重新投影回n × d,并与值矩阵结合,公式如下所示:

然后,将MSA块的输出表示输入到MLP块,该块包括两个由GeLU激活分隔的线性层。在给定层l处,表示通过transformer块的计算流程如下:

MSA和MLP块都具有带层正则化(LN)的残差连接。虽然transformer的每一层中的MSA块均是学习互不依赖的表示,但在下一小节中,我们将展示这些跨层间存在高度相关性。
启发: 层相关性分析
Attention-map correlation

Attention correlation.
ViT中的MSA块将每个块与每个其他块的相似性编码为n × n注意力矩阵。这个运算符具有O(n^2)复杂度(公式2)的计算成本。随着ViT的扩展,即随着n的增加,计算复杂度呈二次增长,使得这个操作成为性能瓶颈。最近的NLP工作表明,SoTA语言模型中相邻层之间的自注意力具有非常高的相关性。这引发了一个问题 - 在视觉transformer是否真的需要每一层都计算自注意力?

CKA analysis of A^[CLS] and Z^MSA across different layers of pretrained ViT-T/16.
为了回答这个问题,我们分析了ViT不同层之间自注意力图的相关性。如本节图1所示,来自类别token的自注意力图A^[CLS]在中间层特别具有高度相关性。A^[CLS]l−1和A^[CLS]l 之间的余弦相似度可以高达0.97。其他token embeddings 也表现出类似的行为。我们通过计算每对i,j∈L的A^[CLS]i和A^[CLS]j之间的Centered Kernel Alignment(CKA)来定量分析ImageNet-1K验证集的所有样本之间的相关性。CKA度量网络中间层获得的表示之间的相似性,其中CKA的值越高则表示它们之间的相关性越高。从本节图2中,我们发现ViT-T在A^[CLS]之间具有高度性,特别是第三层到第十层。
Feature correlation
在ViT中,高相关性不仅局限于A^[CLS],MSA块的表示Z^MSA也在整个模型中显示出高度相关性。为了分析这些表示之间的相似性,我们计算每对i,j∈L的Z^MSAi和Z^MSAj之间的CKA。我们从从本节图2中观察到,Z^MSA在模型的相邻层之间也具有很高的相似性,特别是在较早的层,即从第2层到第8层。
利用 Skipping Attention 提升效率
基于我们对transformer中MSA不同块之间具有高度相似性的观察,我们建议利用注意力矩阵和MSA块的表示之间的相关性来提高视觉transformer的效率。与在每层单独计算MSA操作(公式3)相反,我们探索了一种利用不同层之间依赖关系的简单且有效的策略。
我们建议通过重用其相邻层的特征表示来跳过transformer的一个或多个层中的MSA计算。我们将此操作称为Skip Attention(SKIPAT)。由于跳过整个MSA块的计算和内存效益大于仅跳过自注意力操作 O(n^2d+nd^2) vs. O(n^2d),因此在本文中我们主要关注前者。我们引入了一个参数函数,而不是直接重用特征,换句话说,就是将来源MSA块的特征复制到一个或多个相邻MSA块。参数函数确保直接重用特征不会影响这些MSA块中的平移不变性和等价性,并充当强大的正则化器以提高模型泛化性。
SKIPAT parametric function
设 Φ:R^(n×d) → R^(n×d)表示将l−1层的MSA块映射到l层的参数函数,作为Ẑ^MSA l:=Φ(Z^MSA l−1)。在这里,Ẑ^MSA l是Z^MSA l的近似值。参数函数可以是简单的单位函数,其中Z^MSA l−1能被直接重用。我们使用Z^MSA l−1作为l处的MLP块的输入,而不是在l处计算MSA操作。当使用单位函数时,由于l处没有MSA操作,因此在注意力矩阵中的token间关系不再被编码,这会影响表示学习。为了减轻这一点,我们引入了SKIPAT参数函数,用于对token之间的局部关系进行编码。SKIPAT参数函数由两个线性层和中间的深度卷积(DwC)组成,计算公式如下所示:

SKIPAT framework
SKIPAT 是一种可以被纳入任何 transformer 架构的框架,我们通过大量实验对比结果充分地证明了这一点。根据架构的不同,可以在 transformer 的一层或多层中跳过 MSA 操作。在 ViT 中,我们观察到来自 MSA 块(Z^MSA )的表示在第 2 层到第 7 层之间有很高的相关性,所以我们在这些层中使用 SKIPAT 参数函数。这意味着我们将 Z^MSA2 作为输入传递给 SKIPAT 参数函数,并在 3-8 层中跳过 MSA 操作。相反,来自 SKIPAT 参数函数输出的特征被用作 MLP 块的输入。表示的计算流现在被修改为:

由于 MSA 和 MLP 块中存在残留连接,第 3 层到第 8 层的 MLP 块需要独立地学习表示,不能从计算图中删除。值得注意的是,使用 SKIPAT 后 ViT 的总层数不变,但 MSA 块的数量减少了。
Complexity: MSA vs. SKIPAT
自注意力操作包括三个步骤。首先,将token embeddings 投射到query、key和value embeddings,其次,计算注意力矩阵 A,它是 Q 和 K 的点积,最后,计算输出表示作为 A 和 V 的点积。这导致了计算复杂度为 O(4nd^2 + n^2d)。由于 d ≪ n,所以 MSA 块的复杂度可以降低到 O(n^2d)。
SKIPAT 参数函数由两个线性层和一个深度卷积操作组成,计算复杂度为 O(2nd^2 + r^2nd),其中 r × r 是 DwC 操作的内核大小。由于 r^2 ≪ d,所以 SKIPAT 的整体复杂度可以降低到 O(nd^2)。因此,当 n 随着 transformer 的扩大而增加时,SKIPAT 的 FLOPs值 比 MSA 块更少,即 O(nd^2) < O(n^2d)。
实验

上图展示的是分割mask的可视化效果:第一行和第二行分别是原始Vit-S模型和Vit-S + SKIPAT模型。显而易见,Vit-S + SKIPAT模型对图像中前景和背景的区分度显著高于原始Vit-S模型。

上图展示的是注意力图的可视化效果:对比原始Vit-S模型(baseline),Vit-S + SKIPAT模型对目标的定位能力有明显提升。

上图展示的是特征图和Z^MSA的相关性:从中可以清晰地观察到在大多数不同层之间Z^MSA仅有较低的相关性。
图象分类

Image classification on ImageNet-1K.
自监督

Unsupervised Segmentation and Object Localization on the validation set of Pascal VOC2012.
推理性能

On-device latency (in msec) of vanilla ViT vs. SKIPAT.
语义分割
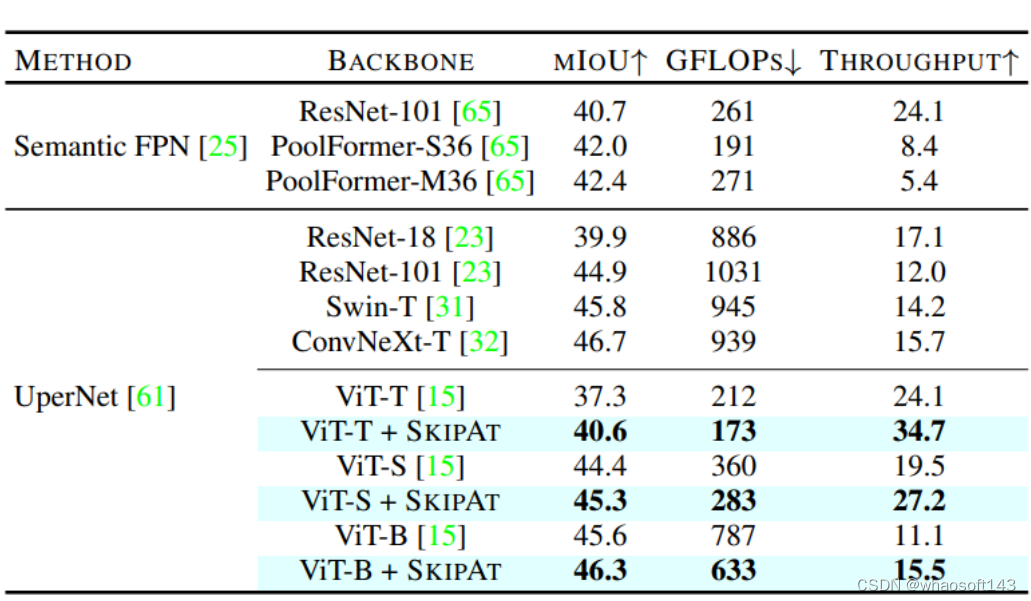
Semantic Segmentation results on ADE20K.
图像去噪

Image denoising on SIDD dataset using PSNR and SSIM as the evaluation metrics in the RGB space.
总结
我们提出了一种可以在任何 ViT 架构中即插即用的模块 SKIPAT,用于减少昂贵的自注意力计算。SKIPAT 利用 MSA 块之间的依赖性,并通过重用以前 MSA 块的注意力表示来绕过注意力计算。此外,我们引入了一个简单且轻量的参数函数,它不会影响 MSA 中编码的归纳偏见。 SKIPAT 函数能够捕获跨token之间的关系,在吞吐量和 FLOPs 指标上优于基线模型,同时我们在7 种不同的任务中充分地表现出SKIPAT的有效性。
#Rethinking-attention
这里介绍了一种简单直接的Transformer架构优化方法,以Transformer模型中的核心操作自注意力(SA)和交叉注意力层(CA)为优化目标,直接使用简单高效的MLP层进行替换。ETH轻量化Transformer最新研究,浅层MLP完全替换注意力模块提升性能
目前,在大型语言模型(LLMs)和AIGC的双重浪潮席卷之下,AI迎来了前所未有的发展机遇。一时间,深度模型训练框架、AI算力等等已经成为社区的热点话题。作为LLMs和AIGC的基础算法backbone,Transformer模型已经成为目前最为关键的基础研究方向,对Transformer现有的注意力机制原理进行探索,并提出优化简化的方案,是目前研究的热点。
一篇来自苏黎世联邦理工学院(ETH Zurich)的最新Transformer优化工作,目前该文已被人工智能顶级会议AAAI 2024录用。本文的核心出发点是,能否使用更加轻量经济的前馈神经网络(MLP)来替代Transformer中笨重的自注意力层,并通过知识蒸馏的方式使用原始模块进行迁移训练,作者将优化后的模型称为“attentionless Transformers”。作者在IWSLT2017等数据集上的实验验证了attentionless Transformer可以达到与原始架构相当的性能,同时进行了一系列消融实验表明,如果正确的配置参数,浅层MLP完全具有模拟注意力机制的潜力。
论文题目:Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers
论文链接:https://arxiv.org/abs/2311.10642
代码仓库:https://github.com/vulus98/Rethinking-attention
一、引言
Vaswani等人在2017年发表的Transformer结构[1]从根本上改变了sequence-to-sequence建模任务的格局,从那时起,Attention Is All You Need。此外,原始Transformer论文还为机器翻译这一基础NLP任务设定了全新的基准(使用BLEU分数作为评价指标)。后续有很多工作对Transformer结构的原理进行探索,人们认为,Transformer的注意力机制能够在时序数据中建立长期依赖关系,使其能够关注序列中的每个元素,这是之前的网络架构在没有大量计算开销的情况下难以实现的效果。为了进一步缩小注意力机制的资源消耗,本文作者提出了一个大胆的设想,能否直接用更轻量的浅层MLP来模拟注意力机制的计算,虽然缺乏在理论上的推理证明,但本文通过实验表明,这种替代方式是完全有效的。
二、本文方法
原始的Transformer架构由一系列的编码器和解码器块堆叠而成。其中编码器层有一个自注意力块,而解码器层包含自注意力块和交叉注意力块。本文针对注意力块提出了四种不同程度的MLP替换模式,这四种替换模式如下图所示。
(1)注意力层替换(Attention Layer Replacement,ALR):仅用MLP替换多头注意力(MHA)块,保留残差连接和归一化层。
(2)残差连接替换的注意力层(Attention Layer with Residual Connection Replacement,ALRR):MHA模块以及残差连接被MLP替换,这种方式可以直接消除 Transformer 中的残差连接。
(3)注意力头分离替换(Attention Separate heads Layer Replacement,ASLR):ALR的变体,该方法用单独的MLP替换MHA模块的每个单独头。
(4)编码器层替换(Encoder Layer Replacement,ELR):完全使用MLP替换编码器层。
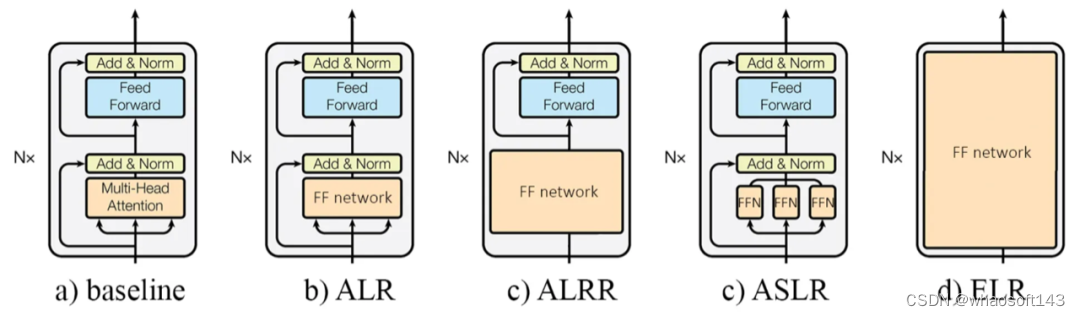
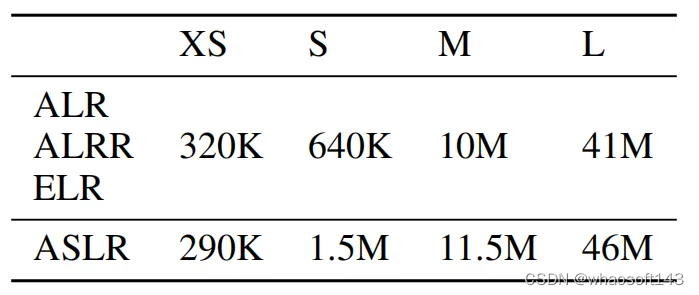
其中 ALR 和 ALRR 的设计灵感是将注意力层的性能提升与残差连接的性能提升分离开来,而ASLR则是用来模拟多头注意力层中每个单独头的操作,即直接使用MLP来代替多头注意力(MHA)。而ELR作为最高的抽象级别,直接将整个编码器块替换为MLP网络,这本质上颠覆了原始编码器架构,将Transformer转换为纯MLP结构。这种替换方式对模型整体参数规模的影响非常显著,下表展示了以上四种方式在XS、S、M和L四种尺寸下的参数大小。
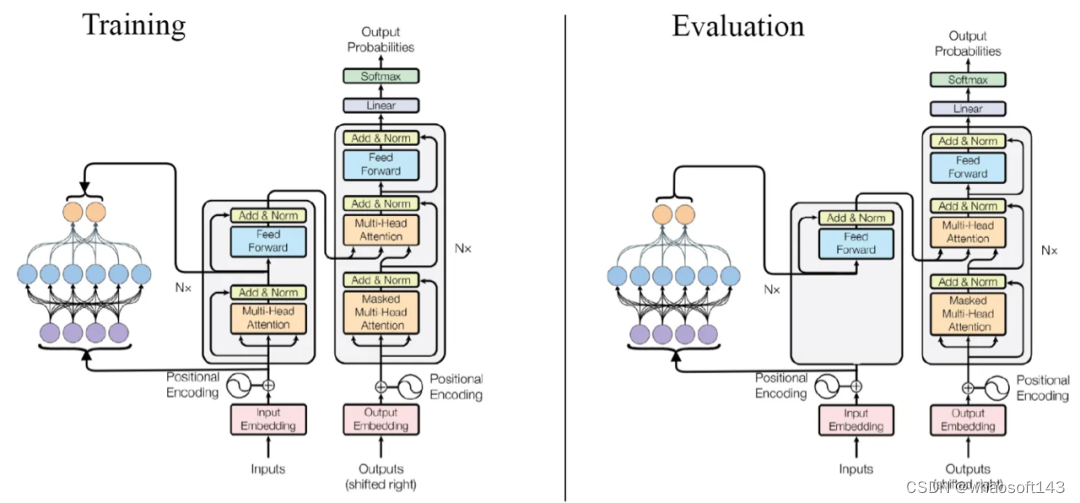
作者以ALRR模式作为样例,首先训练了原始6层编码器和6层解码器的Transformer模型作为MLP网络的教师模型,为了提高训练速度,作者将原始嵌入长度从512减少到128,这样做对模型BLEU分数的影响并不大,但其需要的计算需求会显著降低,此时模型的训练和推理流程如下图所示,使用其他三种模式的训练流程与此类似。
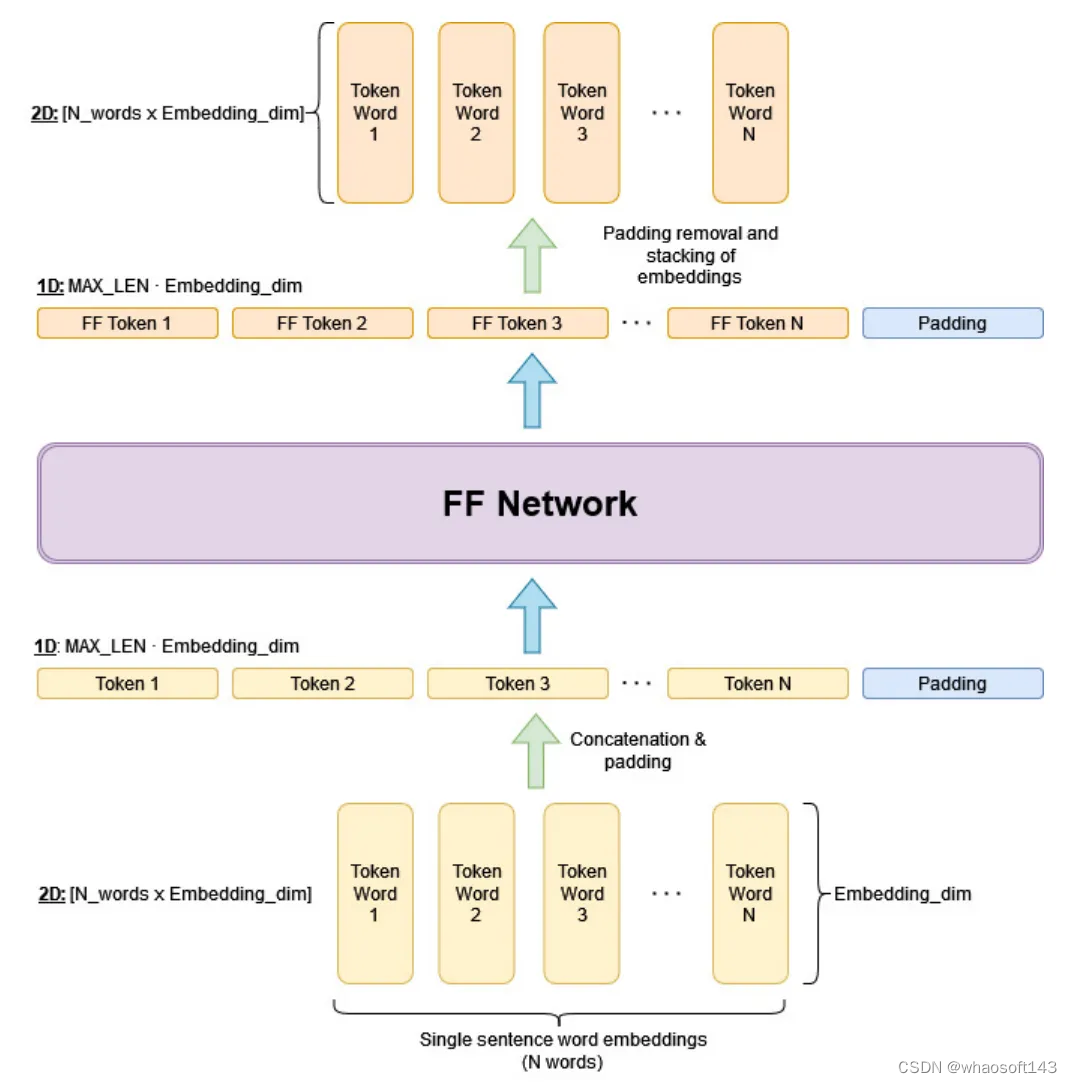
在进行知识蒸馏之前,需要从原始Transformer模型中提取中间激活值,并且对其进行额外的调整,如下图所示,首先需要在每个注意力层中将句子的输入单词表示转换为由输入表示提取的值的线性组合,随后,MLP网络需要将句子的串联单词表示作为输入,并在一次前向传播中生成更新的单词表示作为输出。为了处理不同长度的输入句子,作者直接将所有句子填充到最大固定长度,并用零屏蔽填进行占位。
三、实验效果
本文的实验主要在 IWSLT2017 数据集上进行,该数据集提供了多个语言翻译子集,包括法语-英语(F2E)、英语-法语(E2F)、德语-英语(G2E)和英语-德语(E2G)子集,这些子集平均含有 200000 个训练句子和 1000 个测试句子。翻译后的评价指标选取BLEU分数,BLEU可以衡量模型输出结果与人类专家翻译的直观比较,下表展示了基线Transformer模型(原始模型)在四个翻译子集上的平均效果。

随后作者将本文提出的四种MLP替换模式一一进行了实验,下表首先展示了ALR(仅替换多头注意力层)模式的实验结果,其中“Enc”代表编码器,“Dec”代表解码器,“SA”代表自注意力,“CA”代表交叉注意力,E-D代表同时对编码器和解码器进行替换。从表中可以分析得出,在ALR模式下,“Dec CA”(解码器中的交叉注意力)的BLEU分数较低。
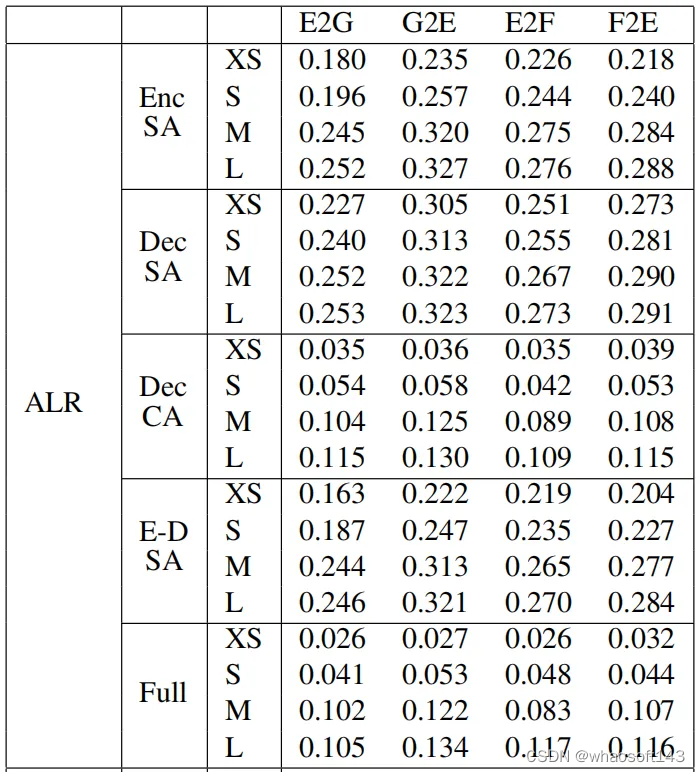
下表展示了其他三种模式:ALRR、ASLR和ELR替换后的实验效果,由于这三种模式不涉及对解码器注意力层的替换,因此模型的整体表现较好。
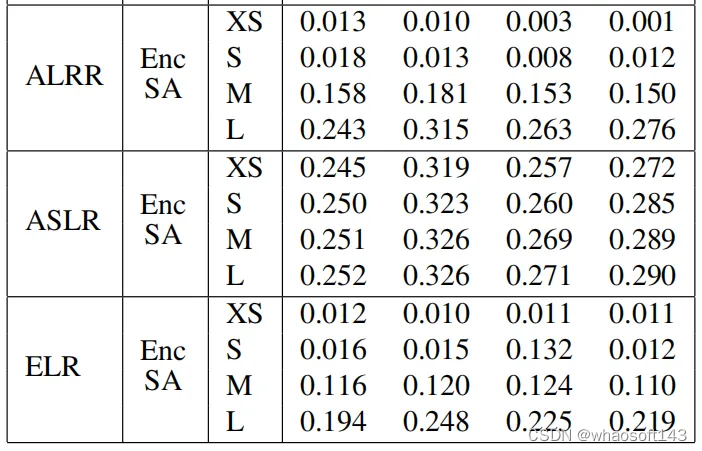
下图展示了四种替换模式与原始基线Transformer模型的BLEU分数差距,与基线相比,所有提出的替换模式都取得了有竞争力的结果,在四种替换模式中,ELR 表现最差,这是由于ELR的构建过于简单。
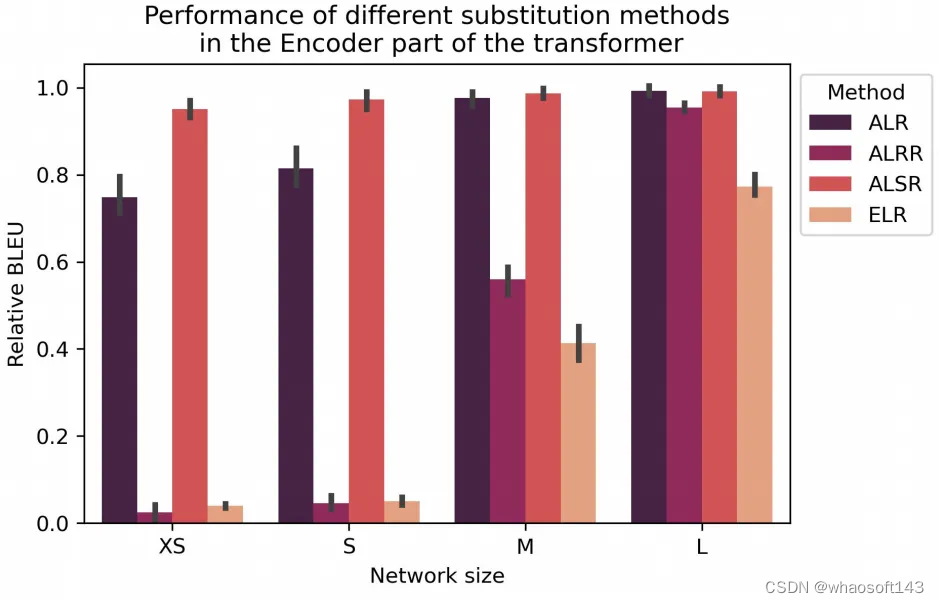
此外,作者还对ALR替换模式在Transformer中的各种替换位置进行了消融实验,如下图所示。ALR在解码器自注意力层中的替换展现出了较好的性能,而在交叉注意力块的表现较差,作者分析造成这种现象的原因是ALR简单的前向传播结构缺乏描述交叉注意力中复杂的映射交互能力,因此,目前想直接使用MLP完全替换交叉注意力层仍然无法实现,同时还有一个缺陷,当使用ALR替换时,模型将只能接受固定长度的序列作为输入,而失去原本的灵活性。
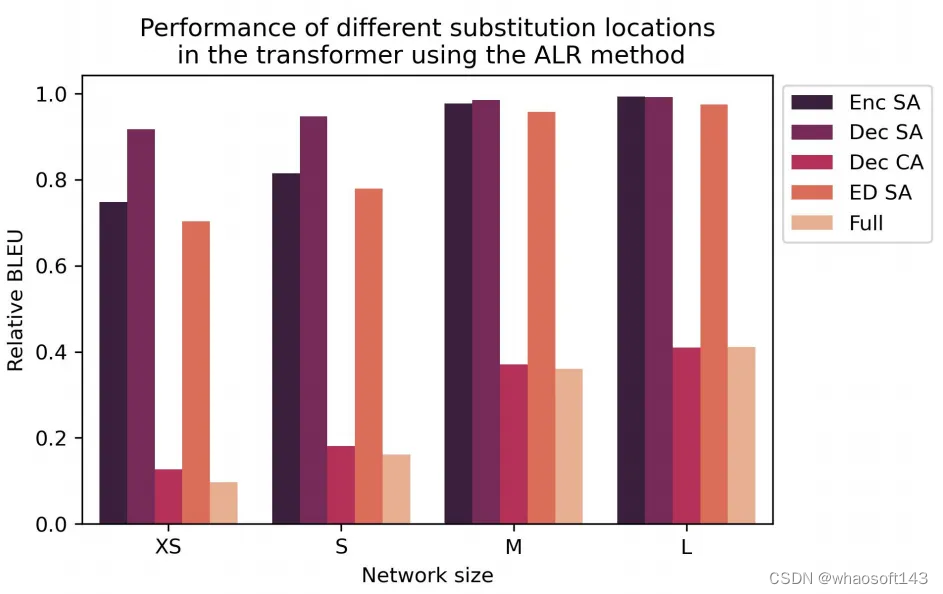
作者还提到,如果能够在对MLP替换层进行知识蒸馏的基础上,引入更加高级的参数搜索策略(例如使用贝叶斯优化)进一步优化MLP层的超参数,有可能会提升模型整体的性能,同时可以进一步缩减MLP替换层的参数量。此外,另一个潜在的研究方向就是对MLP层进行针对性设计,使其模拟交叉注意力模块中的复杂建模能力。
四、总结
本文介绍了一种简单直接的Transformer架构优化方法,以Transformer模型中的核心操作自注意力(SA)和交叉注意力层(CA)为优化目标,直接使用简单高效的MLP层进行替换。根据替换抽象程度和模型参数缩减规模,作者提出了四种替换模式:ALR、ALRR、ASLR和ELR,然后通过知识蒸馏技术将原始Transformer模型的拟合能力迁移到这些轻量化的MLP层中。作者通过在基础NLP翻译基准上的实验表明,Transformer模型完全可以在Attention Free的情况下正常运作,但是需要保留原始的交叉注意力层。
#Flatten Attention
本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。
在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系,给视觉任务的应用带来了挑战。各种各样的线性注意力机制 (Linear Attention) 的计算复杂度随序列长度的大小呈线性关系,可以提供一种更有效的替代方案。线性注意力机制通过精心设计的映射函数来替代 Self-Attention 中的 Softmax 操作,但是这种技术路线要么会面临比较严重的性能下降,要么从映射函数中引入额外的计算开销。
本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。作者首先分析了是什么导致了线性注意力机制性能的下降?然后归结为了两个方面:聚焦能力 (Focus Ability) 和特征丰富度 (Feature Diversity),然后提出一个简单而有效的映射函数和一个高效的秩恢复模块来增强自我注意的表达能力,同时保持较低的计算复杂度。
Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer
论文名称:FLatten Transformer: Vision Transformer using Focused Linear Attention (ICCV 2023)
论文地址:
http://arxiv.org/pdf/2308.00442.pdf
现有线性注意力机制的不足之处
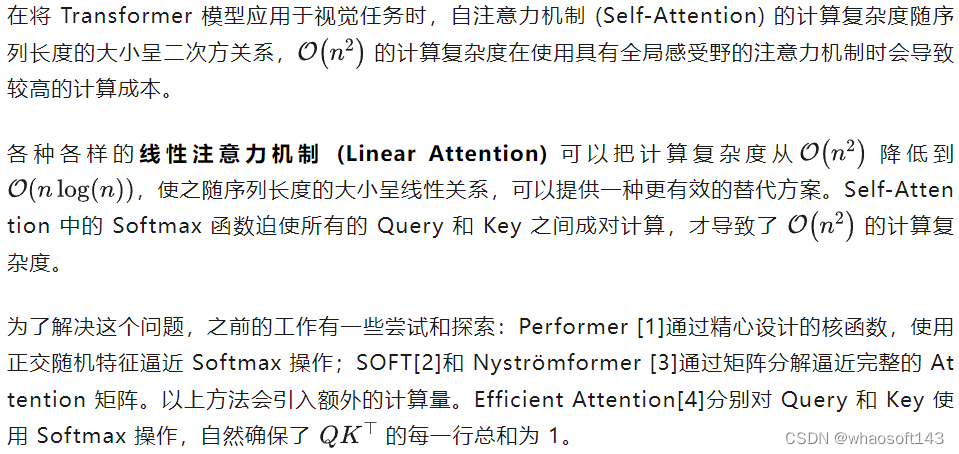
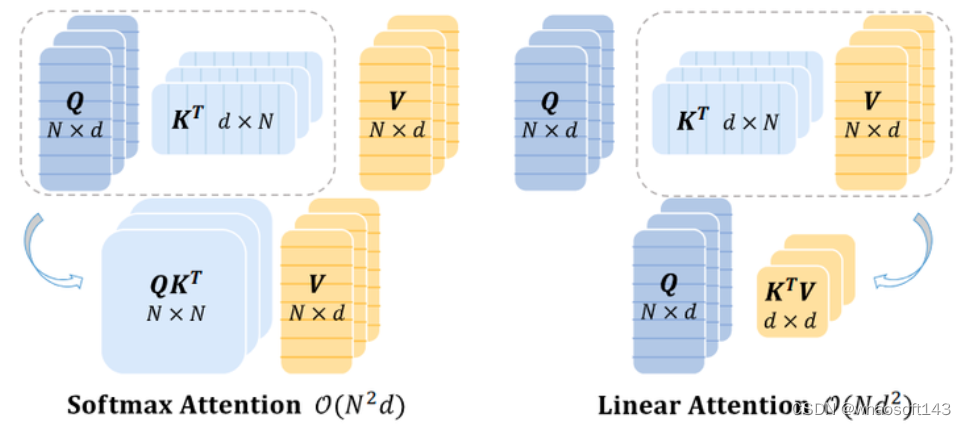
图1:标准的带 Softmax 的 Self-Attention 和 Linear Attention 的区别

但是,与 Softmax 注意力相比,当前的 Linear Attention 方法仍然存在严重的性能下降,并且可能涉及映射函数的额外计算开销,限制了它们的实际应用。
作者从两个角度分析了线性注意力的性能下降的原因,并提出了相应的解决方案。
- Linear Attention 的注意力分布相对平滑,缺乏解决信息量最大的特征的聚焦能力。
- Linear Attention 矩阵的秩相对较低,限制了特征多样性。
线性注意力机制的聚焦能力不够及其解决方案
Softmax Attention 实际上提供了一种非线性重新加权机制,这使得很容易聚焦于重要的特征。如下图1所示,可以看到 Softmax 注意力图的分布在某些区域 (如前景对象) 上比较集中,但是线性注意力图的分布却比较平滑,未能对包含更多信息的区域提供更有效的关注。

图1:线性注意力机制的聚焦能力不够如何为线性注意力机制带来更多的聚焦能力?作者提出了一种聚焦线性注意力机制 (Focused Linear Attention),保留3式的计算方法,同时映射函数写成:

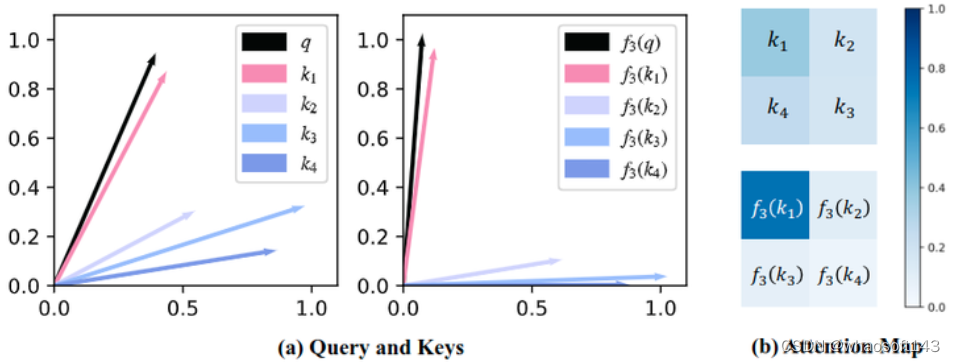
图2:黑色的向量代表 Query,其他几个彩色的向量代表不同的 Key,左图是映射函数作用前的结果,右图是映射函数作用之后的结果
命题结论和可视化结果基本一致。
线性注意力机制的特征丰富度不够及其解决方案
除了焦点能力之外,特征多样性也是对线性注意力表达能力造成限制的因素之一。如下图3所示,以 DeiT-Tiny 中的一个 Transformer 层为例,可以看到 Self-Attention 是满秩矩阵,特征的多样性比较丰富。
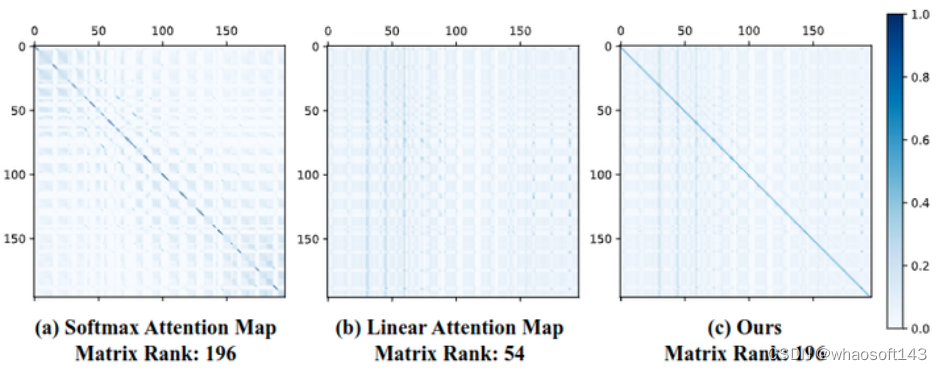
图3:不同 Attention 注意力图可视化和对应的秩,左:Softmax Attention 矩阵,中:Linear Attention 矩阵,带有 DWC 模块的 Linear Attention 矩阵但是,在线性注意的情况下,满秩矩阵很难实现。因为 Linear Attention 的秩受下式的制约:

如上图3所示,使用额外的 DWC 模块,线性注意力中注意力图的排名可以恢复到满秩 196,提升了特征的多样性。
聚焦线性注意力机制
基于上面两节的分析,本文提出一种聚焦线性注意力机制,在保持表达能力的同时降低了计算复杂度,可以表述为:
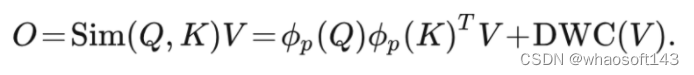
它有2个主要的优点:
- 计算复杂度很低,和线性注意力机制相当。
与前任设计的复杂核函数的线性注意模块相比,本文提出的聚焦函数只采用了简单的算子,以最小的计算开销实现了近似。
- 较高的表达能力,和 Softmax 注意力一致。
前人的基于核函数的线性注意力设计通常不如 Softmax Attention。通过本文所提出的聚焦函数和深度卷积,聚焦线性注意力机制可以实现比 Softmax Attention 更好的性能。
实验结果
ImageNet-1K 图像分类
实验结果如下图4所示,本文方法在差不多的 FLOP 或 Params 下与基线模型实现了一致的改进。比如,FLatten-PVT-T/S 在相似的 FLOP 下分别比 PVT-T/S 高出 2.7% 和 1.9%。基于 Swin,本文模型实现了与 60% FLOPs 相当的性能。这些结果说明 Flatten 方法对不同模型具有泛化能力。
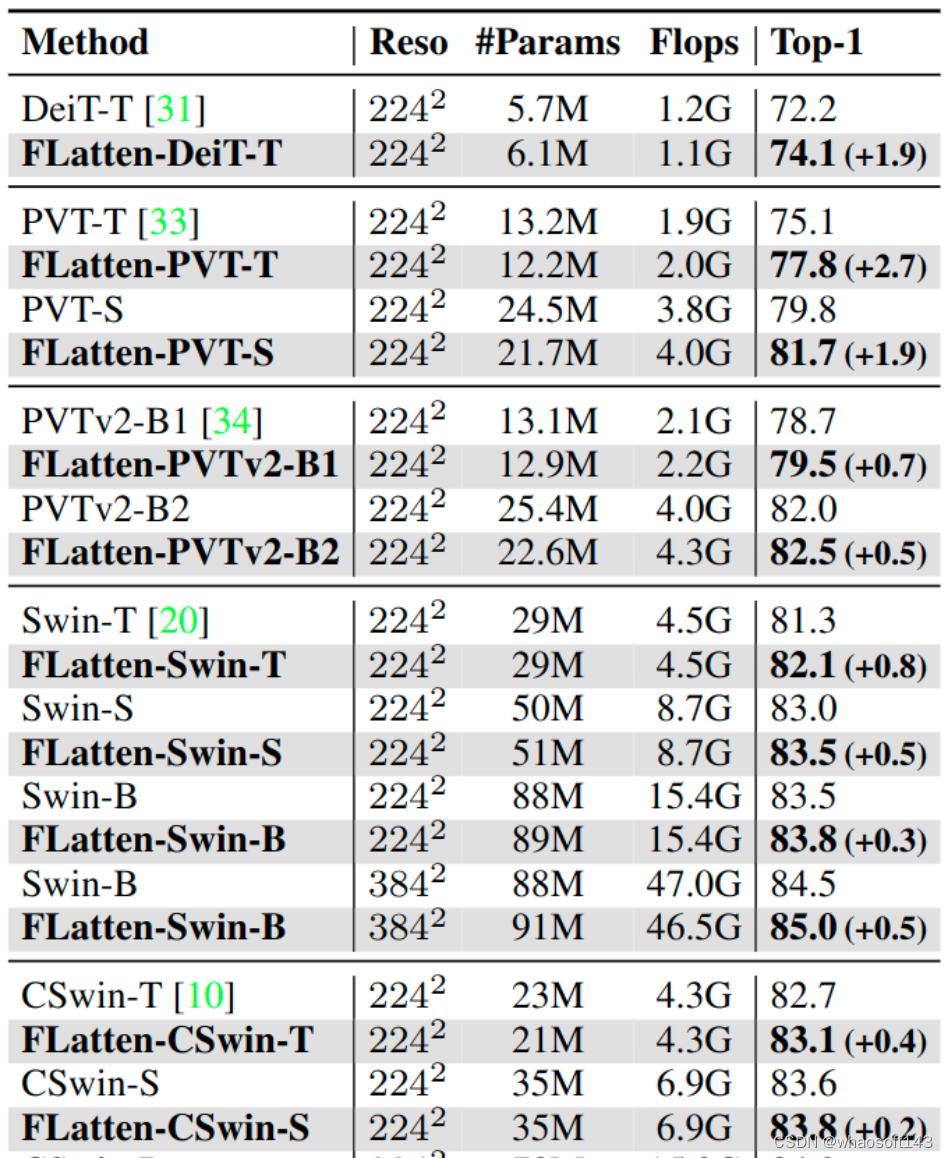

图4:ImageNet 图像分类实验结果
ADE20K 语义分割
实验结果如下图5所示,本文在两个具有代表性的分割模型 SemanticFPN 和 UperNet 上使用 Flatten 方法。如表中所示。如图 1 所示,我们的模型在所有设置下都取得了始终更好的结果。具体来说,我们可以看到 0.5 ∼ 1% mIoU 的改进,计算成本和参数相当。mAcc 的改进更加显著。

图5:ADE20K 语义分割实验结果
COCO 目标检测
实验结果如下图6所示,作者使用 ImageNet 预训练模型和 Mask R-CNN 和 Cascade Mask R-CNN 检测头框来评估有效性,在不同检测头的 1x 和 3x schedule 设置下进行了实验。结果显示,利用更大的感受野,带有 Flattened Attention 的模型在所有设置下都显示出更好的结果。
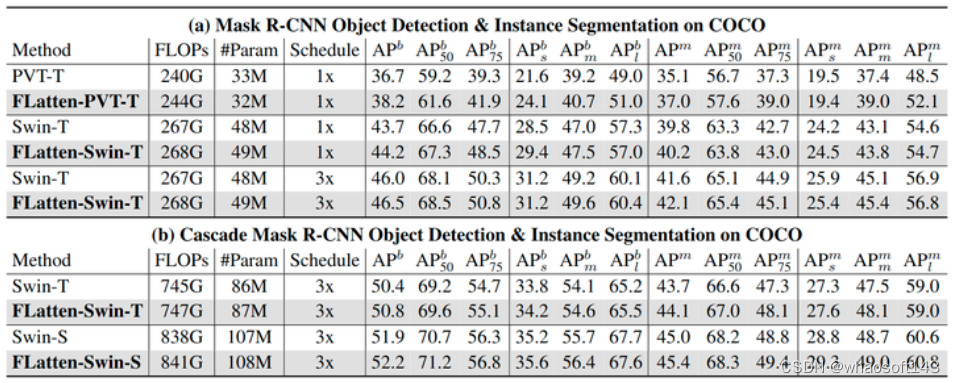
图6:COCO 目标检测实验结果
推理时间
作者进一步评估了模型的实际效率,并将其与两个竞争 Baseline 进行比较,结果如图7所示。作者测试了多个硬件平台上的推理延迟,包括桌面 CPU (Intel i5-8265U) 和两个服务器 GPU (RTX2080Ti 和 RTX3090)。可以看到,带有 Flattened Attention 的模型在 CPU 和 GPU 的运行时和准确性之间实现了更好的权衡,推理速度高达 2.1 倍,性能相当甚至更好。
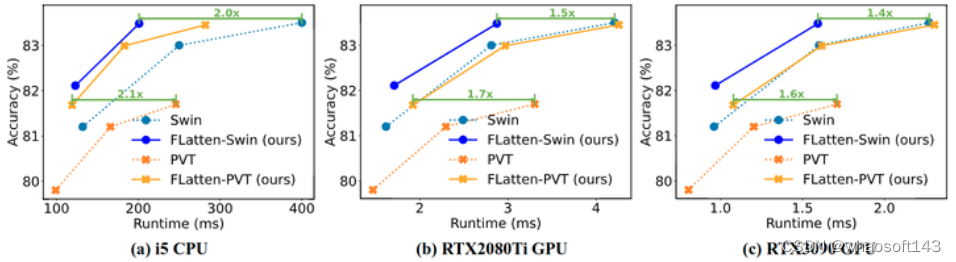
图7:不同硬件设备的推理时间对比
#Flash Attention~2
这是一个大佬手撕Flash Attention的呀~~
本文重心在于介绍 Flash Attention 的算法思想及其实现方式,并对提高 Transformer 运算效率的相关工作做简要介绍。
前言
自 2022 年 11 月 OpenAI 发布 ChatGPT 以来,这一年多来大语言模型 (Large Language Model, LLM) 的发展十分迅速,国内外众多厂商纷纷加入“百模大战”。但是,由于大语言模型的参数量非常巨大(通常为十亿、百亿甚至千亿量级),加之训练语料很庞大,模型的训练成本十分高昂。
当前,Transformer 已经成为了大语言模型的默认网络结构,为了降低大语言模型的训练成本,一些工作尝试对 Transformer 的计算成本进行优化,比如降低注意力运算的时间成本或者显存占用等。
本文介绍 Flash Attention,一种优化的注意力算法。Flash Attention 论文链接如下:
https://arxiv.org/pdf/2205.14135
本文从注意力机制出发,分析原始的注意力机制为什么需要优化,并简要介绍前人在优化注意力机制方面做了哪些工作,再介绍 Flash Attention,并基于 Numpy 手把手实现 Flash Attention 的主体算法。
本文所有代码已开源:
https//gist.github.com/xiabingquan/a4a9a743f97aadd531ed6218be20afd2
如有写得不对或者不清楚的地方还请不吝赐教,在此谢过!
感谢以下用户的指正:@INTuition
由于博主缺少 MLSys 相关背景,因此本文重心在于介绍 Flash Attention 的算法思想及其实现方式,并对提高 Transformer 运算效率的相关工作做简要介绍,而 IO 复杂度分析等内容则略过。本文末尾附了一些其他博主写的个人觉得比较好的讲解Flash Attention的文章链接,读者阅读完本文之后可以作为补充阅读。
本文共约 1.4w 字,阅读约需要 30 分钟。
本文的组织结构如下(PC 端点击左侧目录可直接跳转):
- Transformer 简介:简单介绍 Transformer 的基础知识,以介绍 self-attention 为主;
- Attention 为什么慢:介绍 Transformer 中的 attention 的速度瓶颈;
- 如何提高 Transformer 的计算效率:简单介绍提高 Transformer 计算效率的相关工作;
- Flash Attention:进入正题,详细介绍 Flash Attention 的算法思想和细节;
- 实验效果:简单介绍 Flash Attention 的实际效果;
- 总结:本文总结。
Transformer 简介
本节介绍 Transformer 的基础知识。由于除注意力机制以外的其他内容和本文内容无关,因此本节主要介绍注意力机制。Transformer的详细解释及其代码实现可参考这篇文章(https://zhuanlan.zhihu.com/p/648127076)。
Transformer 是深度学习领域一种非常流行的模型结构,由 Ashish Vaswani 等人于2017年提出[1],主要用于序列到序列 (sequence-to-sequence)[2] 相关任务,如机器翻译、语音识别等。Transformer 主要基于注意力机制搭建,不使用循环神经网络 (RNN) 和卷积神经网络 (CNN) 等结构。
Transformer 包括编码器和解码器两部分,由于当前主流的大语言模型几乎都基于只含解码器而不含编码器的仅解码器 (decoder-only) 模型,因此此处主要介绍仅解码器模型中的 Transformer 解码器,该解码器通过多个解码器层堆叠而成,每层包含自注意力层、前馈神经网络、层归一化、残差连接等组件。
其中,自注意力层接收一个特征序列作为输入,并将该序列输入作为查询 (Query, 下文简称 Q)、键 (Key, 下文简称 K) 和值 (Value, 下文简称 V),使用缩放点积 (Scaled-dot Production) 来计算 Q 和 K 之间的注意力权重矩阵,然后再通过注意力权重和 V 来计算自注意力层的输出。
自注意力层的主体代码如下。简单起见,此处省略自注意力层中的 Q、K、V 各自的线性映射、Dropout、多头注意力、掩码机制等内容。
import unittestimport torch
import torch.nn as nn
from torch.nn import functional as Fclass StandardAttention(object):def __init__(self) -> None:"""Attention module implemented in Numpy.Formula:P = QK^TS = softmax(P / sqrt(d_k))O = SVReference:<<Attention Is All You Need>>URL:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf"""passdef _validity_check(self, q: np.ndarray, k: np.ndarray, v: np.ndarray) -> None:assert q.ndim == 3, "q should be a 3D tensor" # [batch_size, seq_len, hidden_size]assert k.ndim == 3, "k should be a 3D tensor"assert v.ndim == 3, "v should be a 3D tensor"assert q.shape[0] == k.shape[0], "batch_size of q and k should be the same"assert q.shape[2] == k.shape[2], "hidden_size of q and k should be the same"assert q.shape[2] == v.shape[2], "hidden_size of q and v should be the same"def forward(self, q: np.ndarray, k: np.ndarray, v: np.ndarray) -> np.ndarray:self._validity_check(q, k, v)batch_size, q_len, hidden_size = q.shapedenom = np.sqrt(hidden_size)attn = np.matmul(q, k.transpose(0, 2, 1)) # [batch_size, q_len, k_len]attn = np.exp((attn - attn.max(axis=-1, keepdims=True)) / denom)attn = attn / attn.sum(axis=-1, keepdims=True)out = np.matmul(attn, v) # [batch_size, q_len, hidden_size]return outdef __call__(self, *args, **kwargs):return self.forward(*args, **kwargs)def self_attention(x):return StandardAttention()(x, x, x)class TestSelfAttention(unittest.TestCase):def test_forward(self):input_dim = 10batch_size = 32seq_len = 20x = torch.randn(batch_size, seq_len, input_dim)output = self_attention(x)expected = F.scaled_dot_product_attention(x, x, x)self.assertTrue(torch.allclose(output, expected, atol=1e-6, rtol=1e-6))if __name__ == '__main__':unittest.main()我们可以通过 PyTorch 库所给的 F.scaled_dot_production 函数来验证 self_attention 函数的正确性。单元测试的结果此处略过。
Attention 为什么慢?
上一节提到,Transformer 的主要组成部分为 attention,因此优化 Transformer 重点在于优化 attention 的计算。那么,attention 为什么需要优化呢?或者说,注意力机制为什么慢?
此处的“快慢”是相对而言的。严格意义上来说,相比于传统的 RNN,Transformer 中的 attention 可以并行地处理序列所有位置的信息(RNN 只能串行处理),因此计算效率并不低,但是仍然有可以进一步改进的空间。
众所周知,对于科学计算程序而言,按照算数运算和内存读取各自所花的时间比例,科学计算通常分为计算密集型 (compute-bound) 和内存密集型 (memory-bound) 两类。其中,计算密集型运算的时间瓶颈主要在于算数计算,比如大型矩阵的相乘等,而内存密集型运算的时间瓶颈主要在于内存的读写时间,比如批归一化、层归一化等等
我们可以从计算和内存两方面来分析“attention为什么慢”这个问题,分别对应于时间复杂度和空间复杂度两个方面。

图1. GPU的内存层级。图源:Flash Attention原文
如图 1 所示,GPU 的内存可以分为 HBM 和 SRAM 两部分。例如,A100 GPU 具有 40-80 GB 的高带宽内存 (上图中的 HBM,即我们平时说的“显存”),带宽为 1.5-2.0 TB/s,并且每个流式多处理器都有 192 KB 的片上 SRAM,带宽约为 19 TB/s。片上 SRAM 比 HBM 快一个数量级,但容量要小很多个数量级。在 GPU 运算之前,数据和模型先从 CPU 的内存(上图中的 DRAM)移动到 GPU 的 HBM,然后再从 HBM 移动到 GPU 的 SRAM,CUDA kernel 在 SRAM 中对这些数据进行运算,运算完毕后将运算结果再从 SRAM 移动到 HBM。
将 HBM 和 SRAM 之间的数据交换考虑在内,attention 的计算过程可以用如下图所示的算法表示。

图2. 考虑数据交换的Attention算法。图源:Flash Attention原文
通过前面的空间复杂度分析,attention 运算需要占据的显存空间随着序列长度 nn 的增长呈平方级增长。由于运算需要在 GPU 的 SRAM上 完成,这一过程需要不停地在 HBM 和 SRAM 之间交换数据,因此会导致大量的时间都消耗在 SRAM 和 HBM 之间的数据的换入换出上。
综合上面的关于 attention 的时间和空间复杂度的分析,为了加速 attention 运算,我们可以从降低时间复杂度和降低空间复杂度两个角度入手,接下来逐一进行介绍部分相关工作。
如何提高 attention 的计算效率
本节简单介绍提高 attention 运算效率的一些相关工作。本节内容主要是为了内容的完整性考虑,和 Flash Attention的具体内容无关,不影响后文 Flash Attention 的理解。
路径1:降低 attention 的计算复杂度
计算复杂度方面,一些工作尝试提出近似的 attention 算法,来降低 attention 的理论上的计算复杂度。主要可以分为稀疏 (sparse) 估计、低秩 (low-rank) 估计等。

虽然降低 attention 的计算复杂度在理论上非常具有吸引力,但是在实际应用中仍然存在一些短板,比如以下两点:
- 性能比不上原始 attention。不论是稀疏估计、低秩估计还是其他,这些方法都采用了某种近似算法来估算注意力权重矩阵,难免会丢失信息。目前主流的还是原始的attention;
- 无法减少内存读取的时间消耗。这些方法只能降低 attention 的计算复杂度,但是无法对 attention 运算过程中的空间复杂度等进行控制,无法减少内存读写带来的时间损耗。
路径2:降低attention的空间复杂度
空间复杂度方面,这方面工作的基本思路是降低 attention 对于显存的需求,减少 HBM 和 SRAM 之间的换入换出,进而减少 attention 运算的时间消耗。
值得一提的是,“减少 attention 对于显存的需求”和“减少 HBM 和 SRAM 之间的换入换出”这两者之间并不等价,前者重点在于减少显存消耗,比如 memory-efficient attention(https//arxiv.org/pdf/2112.05682),而后者重在降低数据交换的时间成本,比如 <<DATA MOVEMENT IS ALL YOU NEED: A CASE STUDY ON OPTIMIZING TRANSFORMERS>>(https//proceedings.mlsys.org/paper_files/paper/2021/file/bc86e95606a6392f51f95a8de106728d-Paper.pdf) 这篇文章。
为降低空间复杂度,一种具有代表性的方法是 kernel fusion。kernel fusion 的思想很简单,即将需要通过多个 CUDA kernel 来分步完成的操作融合到一个或者少数几个 CUDA kernel,从而减少数据在HBM和SRAM之间换入换出的次数,进而节省运算时间。

Flash Attention 的做法其实也是 kernel fusion,只是对应的 kernel 专门针对数据的换入换出进行了优化 (IO-aware),尽可能最小化 HBM 和 SRAM 之间的数据交换次数。
Flash Attention 介绍
本节介绍 Flash ttention 的动机、具体方法和实现细节,并基于 Numpy 实现 Flash Attention 的主体算法(代码已开源,链接(https//gist.github.com/xiabingquan/a4a9a743f97aadd531ed6218be20afd2))。
本文以实现 Flash Attention的前向过程为主,后向传播、masking、Dropout 等略过。
和 Transformer 的原始 attention 相比,Flash Attention 有以下三点特点:
- 运算速度更快 (Fast);
- 更节省显存 (Memory-Efficient);
- 计算结果相同 (Exact)。
这三点刚好和 Flash Attention 论文名《FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness》相对应。得益于 Flash Attention 的这几点特性,自 PyTorch 2.0(https//pytorch.org/blog/accelerated-pytorch-2/) 开始,Flash Attention 已经被集成到 PyTorch 官方库中,使用者可以直接通过 torch.nn.functional.scaled_dot_product_attention(https//pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html) 进行调用。
摘要
Flash Attention 的动机是尽可能避免大尺寸的注意力权重矩阵在 HBM 和 SRAM 之间的换入换出。具体方法包含两个部分:tiling 和 recomputation。
tiling 的基本思路:不直接对整个输入序列计算注意力,而是将其分为多个较小的块,逐个对这些块进行计算,增量式地进行 softmax 的规约。规约过程中只需要更新某些中间变量,不需要计算整个注意力权重矩阵。
recomputation 的基本思路:基于 tiling 技巧,在反向传播过程中不保留整个注意力权重矩阵,而是只保留前向过程中 tiling 的某些中间变量,然后在反向传播过程中重新计算注意力权重矩阵。recomputation 可以看作是一种基于 tiling 的特殊的 gradient checkpointing,因此后文主要介绍 tiling,想进一步了解 recomputation 的读者可以翻阅 Flash Attention 原文。
得益于上述技巧,Flash Attention 可以同时做到又快(运算速度快)又省(节省显存)。
基于Tiling技巧的Softmax
本节主要介绍 Flash Attention 中用到的 tiling 技巧。Tiling 技巧不是 Flash Attention 的首创,该技巧在之前的工作中已有探索[3][4][5]。
Tiling 技巧的核心思想是,尽可能避免对整个序列进行操作,而是通过维护一些中间变量来递推式地完成某些操作,从而减少内存的消耗。
以 softmax 为例,原始的 softmax 可以用如下算法表示:
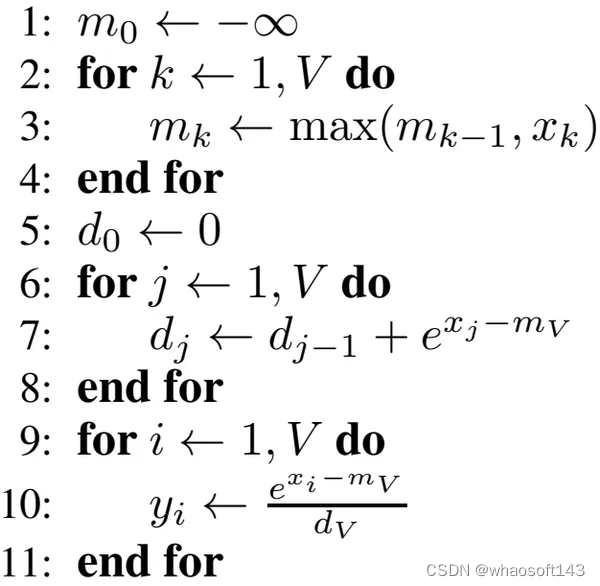
图3. 原始softmax。图源:《Online normalizer calculation for softmax》
该算法的实现如下。为了展示 softmax 运算的详细过程,以下代码没有使用 PyTorch、Numpy 等科学计算库,或者Python原生的 max、min 等归约函数,而仅仅使用 Python 原生的数值运算符对浮点数的列表进行操作。
class SoftMax(object):def forward(self, x: List[float]):# loop 1: get the maximum valuemax_x = -np.inffor t in x:max_x = t if t > max_x else max_x# loop 2: get the accumulative sum of exp(x_i - x_max)accum_exp = 0.for t in x:accum_exp += np.exp(t - max_x)# loop 3: get the softmax output by dividing the exponential of `x-max(x)` with `accum_exp`output = [0. for _ in range(len(x))]for i, t in enumerate(x):output[i] = np.exp(t - max_x) / accum_expreturn outputdef __call__(self, *args, **kwargs):return self.forward(*args, **kwargs)从上面的代码可以看出,softmax 函数需要三个循环,第一个循环计算数组的最大值,第二个循环计算 softmax 的分母,第三个循环计算 softmax 输出。
使用 tiling 技巧的 softmax 的算法如下图所示。
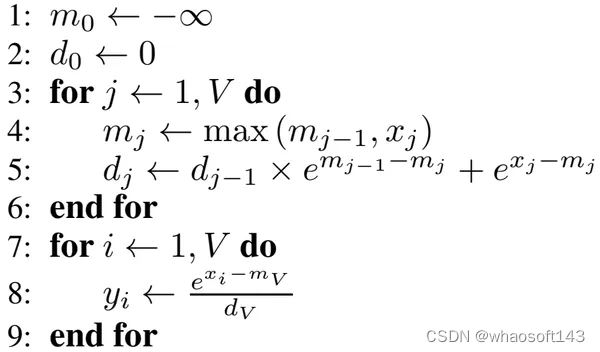
图4. 使用tiling技巧的softmax。图源:《Online normalizer calculation for softmax》
该算法的实现如下:
class SoftMaxWithTiling(object):def forward(self, x: List[float]):# loop 1: get the maximum value of x and the accumulated exponential valuesmax_x = -np.infaccum_exp = 0.for t in x:max_x_new = t if t > max_x else max_xaccum_exp = np.exp(max_x - max_x_new) * accum_exp + np.exp(t - max_x_new)max_x = max_x_new# loop 2: get the softmax output by dividing the exponential of `x-max(x)` with `accum_exp`out = [0. for _ in range(len(x))]for i, t in enumerate(x):out[i] = np.exp(t - max_x) / accum_expreturn out单元测试的代码如下,单元测试的结果此处略过。
class SoftMaxTest(unittest.TestCase):def test_softmax(self):n_test = 10for _ in range(n_test):n_elem = np.random.randint(1, 11)x = np.random.randn(n_elem).tolist()expected = torch.nn.functional.softmax(torch.tensor(x), dim=-1).tolist()out = SoftMax()(x)self.assertTrue(np.allclose(expected, out, atol=1e-4))out_with_tiling = SoftMaxWithTiling()(x)self.assertTrue(np.allclose(expected, out_with_tiling, atol=1e-4))if __name__ == "__main__":unittest.main()

通过 tiling 的方式,softmax 的循环数从三个减到了两个,从而可以降低内存消耗。
Flash Attention的Numpy实现
Flash Attention 同样基于上述的tiling技巧实现,但是和上述的 sofmax 有两点不同:
- attention 的计算过程需要对 QQ 和 KK 进行内积,并且需要维护 attention 的输出矩阵 OO ;
- 在上述 tiling 形式的 softmax 中,我们的每一步只更新一个元素,但是 Flash Attention 将输入分为多个块,每个块包含多个元素。
Flash Attention 的完整算法如图5所示。

图5. Flash Attention完整算法。图源:Flash Attention原文
由于我们无法直接从 Python 层面在 GPU 的 SRAM 和 HBM 之间进行数据交换,因此我们使用 load 和 write 方法来分别模拟 HBM -> SRAM 和 SRAM -> HBM 的数据传输过程:
def load(self, arr, st, ed, step):# Simulate the process that moves data from HBM to SRAMreturn arr[:, st * step: ed * step]def write(self, arr, val, st, ed, step):# Simulate the process that moves data from SRAM to HBMarr[:, st * step: ed * step] = val接下来去我们结合代码来逐步理解该算法:

out = np.zeros((batch_size, q_len, hidden_size))
l = np.zeros((batch_size, q_len))
m = np.zeros((batch_size, q_len))
m.fill(-np.inf)
for i in range(Tr):
m_new = np.maximum.reduce([mi, mij])
l_new = np.exp(mi - m_new) * li + np.exp(mij - m_new) * lij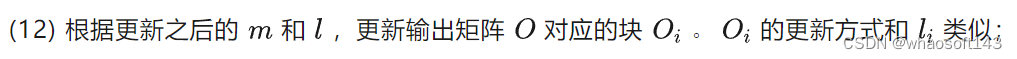
temp = li[..., np.newaxis] * np.exp(mi - m_new)[..., np.newaxis] * oi + np.exp(mij - m_new)[..., np.newaxis] * np.matmul(pij, vj)
temp /= l_new[..., np.newaxis]
self.write(out, temp, i, i + 1, self.row_block_size)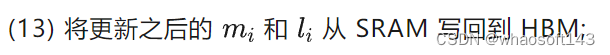
(14) 循环结束;
(15) 循环结束;

return out注:上述代码只是Flash Attention原文算法1的直观实现,可能和底层C++实现在细节上存在一些出入。官方实现请请翻阅Flash Attention的原始仓](https//github.com/Dao-AILab/flash-attention)。
为验证上述 Flash Attention 实现的正确性,我们可以通过对比上述实现的 Flash Attention、“Transformer 简介”一节实现的 self_attention 函数以及 PyTorch 官方库的 nn.functional.scaled_dot_production 函数的运算结果(单元测试的完整代码见github仓库(https//gist.github.com/xiabingquan/a4a9a743f97aadd531ed6218be20afd2))。单元测试通过。

图6. Flash Attention单元测试结果
实验效果
为验证Flash Attention在实际训练场景中的有效性,Flash Attention论文原文对比了分别基于原始attention和Flash Attention的BERT和GPT2模型的训练时间以及模型性能等,还基于Flash Attention做了长上下文语言模型建模相关实验,此处略过,请参考论文原文(https//arxiv.org/abs/2205.14135)。
这里贴一些Flash Attention仓库(https//github.com/Dao-AILab/flash-attention)中的图,让大家对Flash Attention的时间加速比以及空间节省情况有一个更直观的认识。
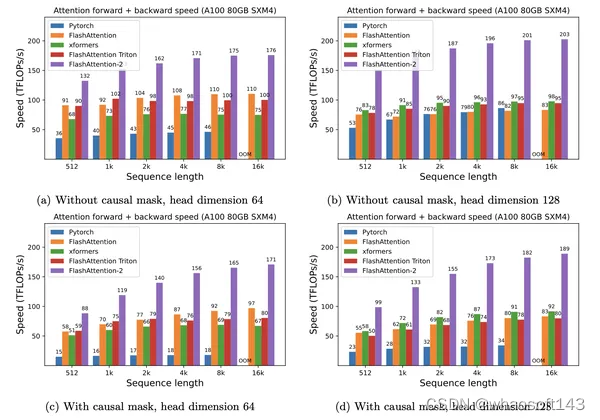
图7. Flash Attention加速情况
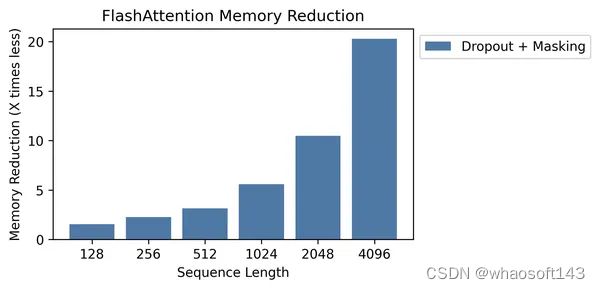
图8. Flash Attention节省显存情况
注:上述为A100的测试结果,不代表其他GPU的情况。
总结
本文介绍了 Flash Attention,一种相比于原始attention运算速度更快、更节省显存的精确注意力算法。
Flash Attention 的特点在于尽量减少 GPU 的 HBM 和片上 SRAM 之间的数据交换,从而达到加速运算以及节省显存的目的。
Flash Attention 的核心方法是 tiling 和 recomputation。其中 tiling 递推式地计算 softmax,避免了计算整个注意力权重矩阵,而 recomputation 则基于前向运算中的 tiling 保存的某些中间变量,在反向传播时重新计算注意力权重矩阵。
自 PyTorch 2.0 起,Flash Attention已经集成到 PyTorch 官方库中。使用者可以通过 torch.nn.functional.scaled_dot_prodoction 进行调用。
当前,Flash Attention还在迭代中,Flash Attention-2(https//tridao.me/publications/flash2/flash2.pdf) 已经推出。
参考
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/1409.3215
- https://arxiv.org/pdf/2112.05682
- https://arxiv.org/pdf/1805.02867
- https://ieeexplore.ieee.org/document/8980322
- https://arxiv.org/abs/1805.02867