声明:工作以来主要从事TTS工作,工程算法都有涉及,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 低调奋进 TTS 开源数据 低调奋进。如转载,请标明出处。欢迎关注微信公众号:低调奋进
目录
1 研究背景
2 研究情况
2.1 数据充足
2.1.1 系统架构设计
2.1.2 高采样率数据
2.2 数据匮乏
2.2.1 低质数据
2.2.2 歌声转换
2.2.3 迁移学习
3 总结
4 引用
1 研究背景
歌唱合成SVS(singing voice synthesis)是根据歌词和乐谱信息合成歌唱。相比于TTS(text to speech)使机器“开口说话”,歌唱合成则是让机器唱歌,因此更具有娱乐性。互联网的时代,人机交互更加频繁和智能,歌唱合成则添加了人机交互的趣味性,因此受到工业界和学术界的关注。相比TTS,歌唱合成需要更多的输入信息,比如乐谱中的音高信息,节拍信息等等。但是歌唱合成的训练语料十分昂贵,为获得较高品质的歌唱干声和乐谱信息,研究者需要付出上百万的开销,这也阻碍大量研究人员的脚步。本文针对2020年歌唱合成的发展状况,总结在是否拥有大量训练数据前提下采用的不同方案,以供同行参考。
各家demo的链接:
Learn2Sing
https://bytesings.github.io/paper1.html
https://xiaoicesing.github.io/
HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis - Speech Research
DurIAN-SC: Duration Informed Attention Network based Singing Voice Conversion System | [“DurIAN_SC”]
DeepSinger: Singing Voice Synthesis with Data Mined From the Web - Speech Research
2 研究情况
其实歌声合成(singing voice synthesis)的文章不算太多,本打算通读以后再做个总结,但思来想去还不如先总结之后,以后再慢慢修改,也算“敏捷”总结。我找的文章都是2020年的文章,这样可以看出去年歌唱合成的发展动态。我们知道,歌唱合成之所以没有像TTS这样受到强烈关注的原因之一就是训练语料的匮乏。相较普通音频的训练语料,歌唱合成的训练语料要贵好几倍,因此很少有企业和研究所能够承担此种开销。歌唱合成训练语料相比普通语料的成本较高的原因:1)需要专业歌手在专业的录音棚录制高音质的干声;2)歌声的标注需要更复杂的信息,标注成本较高。是否拥有充足的训练数据导致不同的研究方向和策略,因此我根据训练数据是否充足进行以下分类:
2.1 数据充足
2.1.1 系统架构设计
(a)ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders
(b)XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
2.1.2 高采样率数据
(a)HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
2.2 数据匮乏
2.2.1 低质数据
(a)Deepsinger: Singing voice synthesis with data mined from the web
2.2.2 歌声转换
(a)Durian-sc: Duration informed attention network based singing voice conversion system
2.2.2 迁移学习
(a)learn2sing target speaker singing voice synthesis by learning from a singing teacher
2.1 数据充足
2.1.1 系统架构设计
2.1.1.1 ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders
图一展示了ByteSing 系统的整体架构,该系统包含时长模型,声学模型和神经网络声码器。时长模型的输入为音素+音素类型+节奏和音符时长,输出为音素对应的时长。声学模型的输入为音素+音符音高+每帧的位置信息,输出为声学信息,具体为图2展示。看到图2结构可能大家跟我有相同的疑惑,既然时长模型已经预测出了每个音素时长,为什么还使用attention?本文在实验部分给出了实验结果:使用attention的效果更好。神经网络声码器是把声学特征转成波形,具体结构图3所示。

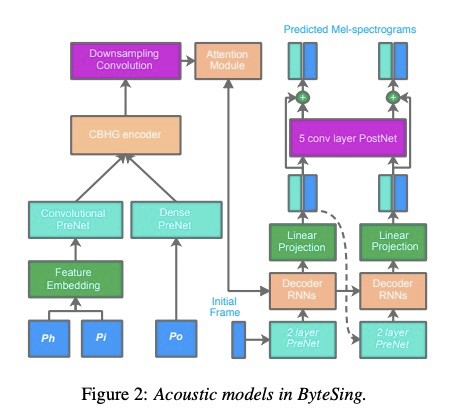

本文实验对比一下几个方面:Natural是原始录音,ByteSing为本文提出方案,BS-w/o-attention为不使用attention方案,BS-w-To为输入特征添加音调信息。

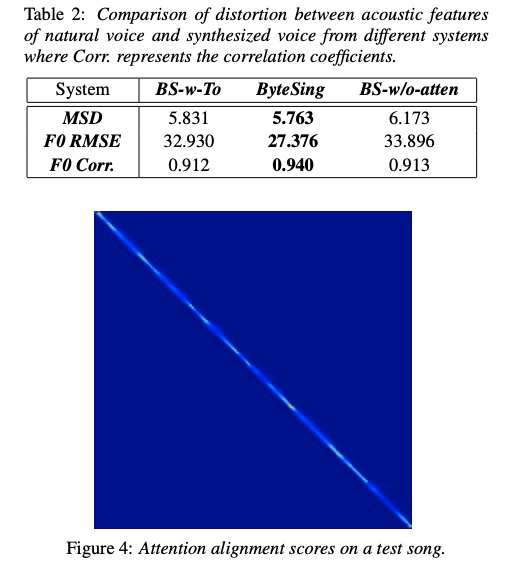
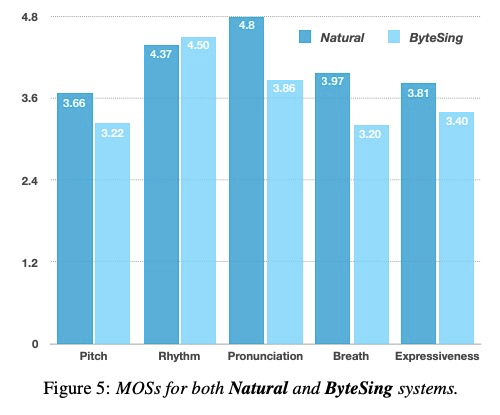
客观指标如table 2显示,本文ByteSing在各项指标最好,说明使用attention效果提升,同时添加音调信息结果反而不好。图4是attention的对齐信息。图5展示了主观MOS评测,该部分说明ByteSing在pitch, rhythm,pron,breath和express等方面跟原始录音差别不大。
2.1.1.2 XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
本文使用的系统架构是FastSpeech,声码器为world vocoder,具体系统架构为图1所示。该系统主要注意以下几点。第一,输入的内容是从乐谱中提取的phoneme, pitch和duration,具体的格式为图二。第二,encoder和decoder之间的durtion训练时候不仅考虑phoneme的loss,也考虑syllable的loss,因此此处的loss为公式1。第三,decoder输出的特征mgc+bap+v/uv+pitch,其中pitch使用残差的方式进行拼接,其loss为公式2和3。


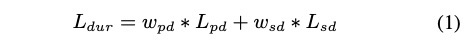


本文在主客观两个方向进行对比。此处baseline系统为CNN的声学模型+LSTM的f0和duration。由table1的mos结果显示,xiaoicesing在pronun acc. sound quality和naturalness都是远远好于baseline。客观指标table2 显示错误率指标RMSE,xiaoicesing低于baseline,相关性corr 指标xiaoicesing高于baseline,其它参数也是好于baseline。

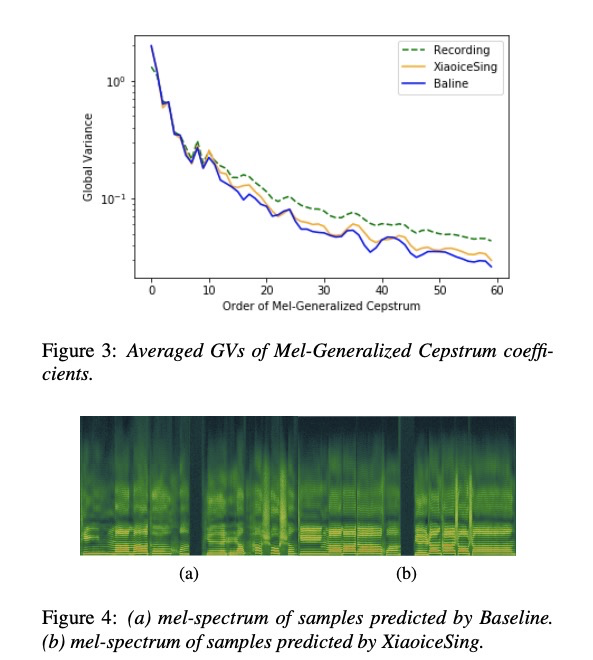
接下来图3显示ave gv实验,xiaoicesing更贴近原始音频,图4展示xiaoice的语谱图刻画的频率更好。
ab test结果如图5 显示,基频f0和durtion远远好于baseline系统。图6和图7也显示f0和durtion的测试中,xiaoicesing更贴切原始音频。

2.1.2 高采样率数据
2.1.2.1 HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
高仿真的音频合成需要处理高采样率的音频数据,尤其是歌唱合成。相对于使用16kHz和24kHz的音频,使用48kHz的音频将会覆盖更宽的频带和更长的音频序列,这将给音频合成造成极大的挑战。本文针对使用48kHz音频带来的问题,提出了HiFiSinger。
该系统由FastSpeech和Parallel wavegan组成,具体的如图1所示。音乐合成的输入是从歌词和乐谱提取的特征(如图一(a)的phoneme从歌词中转换,duration embedding 和pitch embedding从乐谱中提取),整个流程跟fastspeech差不多。不过因为使用48kHz的音频,因此80维的mel特征刻画的频带更广,因此本文提出了SF-GAN进行子带划分和辨别,具体如图一的(b)所示,把80维分为低中高三个频带(0~40,20~60,40~80),其目标函数为公式1和2。另外,为解决生成的音频序列增长的问题,本文对声码器添加ML-GAN,具体如图1的(c)所示,使用不同长度的音频进行辨别,其目标函数为公式3和4。另外本文也测试了使用特征pitch和v/uv,window/hop size 和larger receptive field对结果的影响。



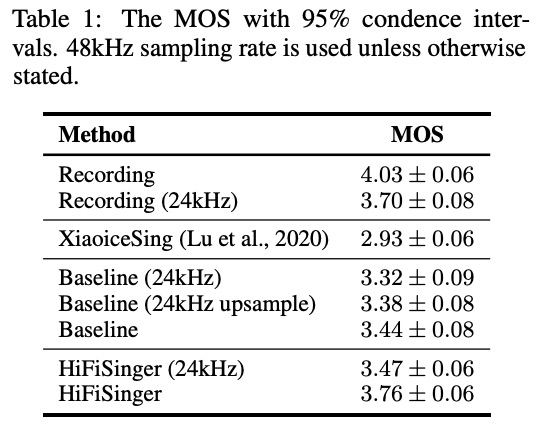
首先对比合成音质的MOS值,table1中的recording为原始音频,xiaoicesing是上一篇文章小冰的效果,baseline为FastSpeech和parallel wavegan,但没有使用SF-GAN和ML-GAN。HifiSinger为本文提出的各种优化策略,由结果显示,本文的方案得出的MOS值在相同的采样率情况下均是最高。
然后,分别对比每个模块的效果。首先验证SF-GAN的效果,由table2 可知对频带划分不是越多越好,当分5个时候,音质反而下降,本文使用3的效果最好。由图2的语谱图可以看出使用SF-GAN的语谱图跟ground truth最接近。


接下来,对比ML-GAN的效果。由table 3结果可知,单独使用一个长度都没有使用多个长度效果好,图3也展示使用ML-GAN的语谱图更好。

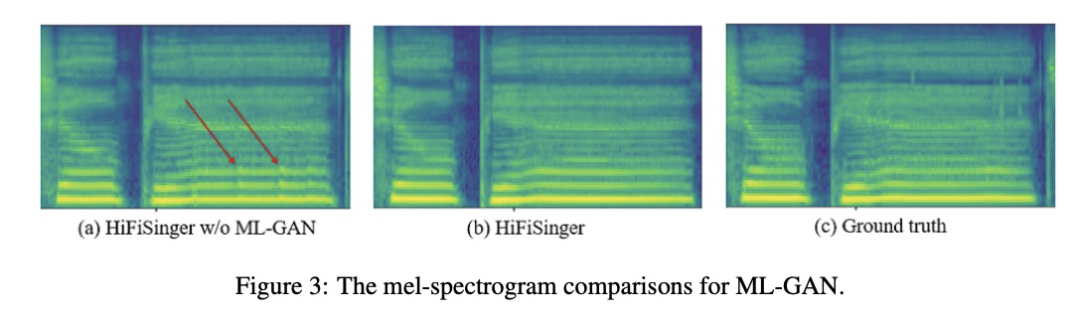
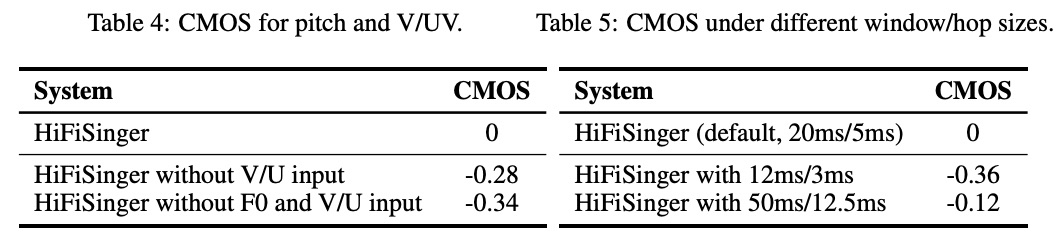
其次,由图4和table4显示使用pitch和v/uv输入特征,都能够提高合成效果。最后,table5和table 6显示不同window/hop size和声码器receptive fields对合成质量的影响。


2.2 数据匮乏
2.2.1 低质数据
2.2.1.1 DeepSinger: Singing Voice Synthesis with Data Mined From the Web
歌唱合成是一项非常有趣的研究,但歌唱合成的训练语料十分昂贵,往往获得较好的训练语料需要花费上百万的成本,因此很少有企业和研究所能够承担此种开销。为了解决数据的问题,本文是首次使用网络爬取的数据进行模型训练,总体效果还算不错,也为很多研究者提供思路。
先来看一下DeepSinger整体的流程(图1所示):1)网上爬取歌曲和相应的歌词;2)使用Spleeter进行歌曲的歌声和伴奏的分离,获取干声;3)歌词和歌声之间的对齐,获取时长信息;4)进行数据筛选,获取较好的训练语料;5)歌唱合成系统的训练;

其中以上的五个步骤,本文主要讲解对齐设计和歌唱合成模型。对齐模型是使用encoder-attention-decoder的ASR模型,具体如图2所示,另外本部分的attention使用guided attention,具体如图3所示。本文通过attention的对齐情况来抽取时长。


本文的歌唱合成模型是在fastspeech系统上进行的修改,为了支持多人多语言的歌唱合成,具体的系统结构如图4所示:该部分的输入为phoneme + pitch + singer infomation (reference encoder)。推理阶段如图5所示,这里不再详细阐述。


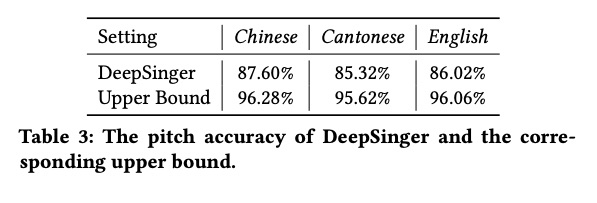
本文的实验数据是在中文,粤语和英文歌曲进行的实验,具体的数据信息见table 1所示。接下来将在客观和主观两个方面进行评估。table 2的客观指标显示合成三种语言歌曲在句子级别正确率都差不多大于80%,ASE都小于100ms。table3展示了基频准确率都大于85%,这种效果还是不错的。table 4 是MOS测试,由此可知,合成的音质相比于GT较低,但也可接受。table 5分别展示每个模块的影响,其中添加TTS数据可以很好帮助提高合成效果。table 6显示使用参考音频是否干净的影响效果。table7显示reference encoder的重要性。table8显示出本文提出的DeepSinger使用歌唱语料的效果。





2.2.2 歌声转换
2.2.2.1 Durian-sc: Duration informed attention network based singing voice conversion system
本文的研究方向是把普通的音频转换成歌唱音频。
本文在DurIAN(duration informed attention network)基础上提出了DurIAN-SC (sing conversion),本系统如图2所示主要包括三个部分:encoder, alignment module 和 decoder。其中encoder主要把音素序列转成隐向量。对齐模块则把音素级别根据时长扩展成帧级别的特征。最后,最回归模式的decoder根据对齐模块的输出进行逐帧推理。
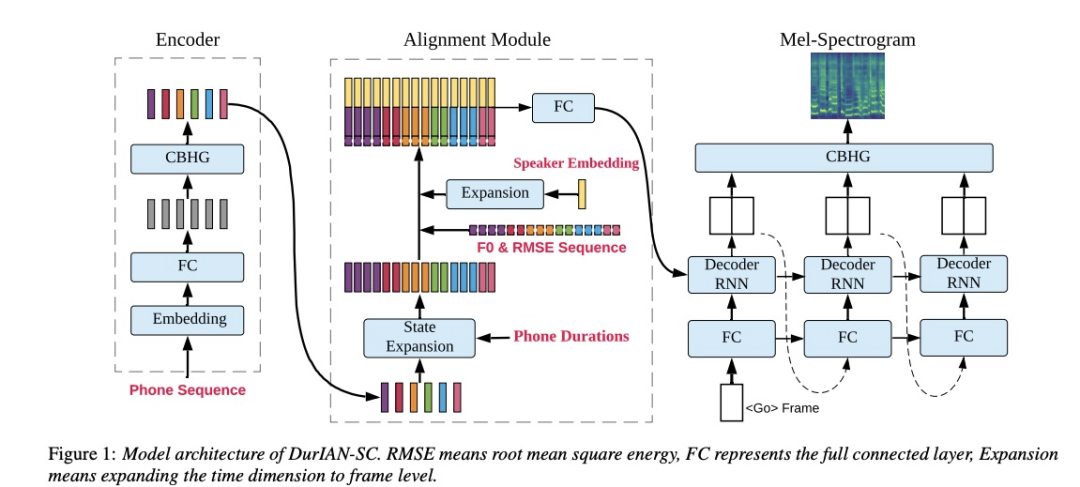
该转换主要分为训练和转换阶段。训练阶段如图2所示,把歌唱和普通音频混在一起,然后提取特征RMSE,F0,Specker embedding(该模块是使用8000多人先训练好)和duration sequence。最后把提取的特征输入到DurIAN-SC进行训练。转换阶段如图3所示,提取歌声的RMSE,F0和duration sequence,提取目标说话人的Specker embedding,然后使用训练好的DurIAN-SC进行合成。

比较有意思的是以下公式,该公式是为了处理不同说话人之间f0范围不同,因此做了一个系数进行缩放,这点可以借鉴一下。

本文主要进行主观评测。先对比使用声纹d-vector和look up table对比,table 1显示使用声纹d-vector效果好(这里我想说一句,训练d-vetcor需要大量数据,而且好坏影响合成效果,还不如LUT联合训练)。

接下来对sing conversion进行对比,结果由table2显示,本文提出的系统可以把普通音频转成歌唱。

2.2.3 迁移学习
2.2.3.1 learn2sing target speaker singing voice synthesis by learning from a singing teacher
本文设计了一种只输入歌词和乐谱就可以让普通语音合成歌声的系统,实验验证本方法可行。
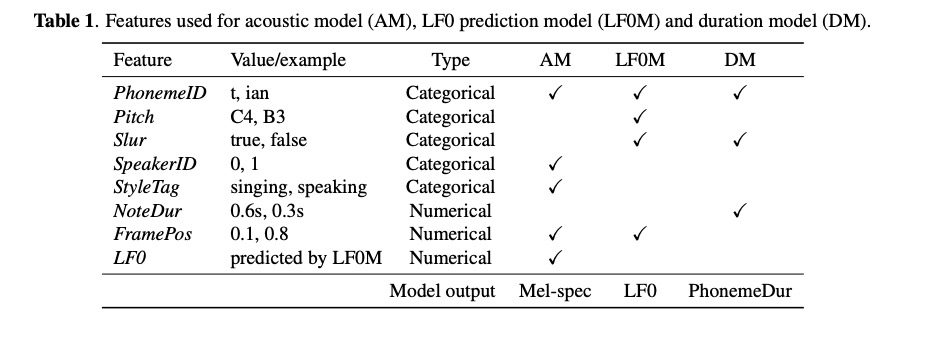
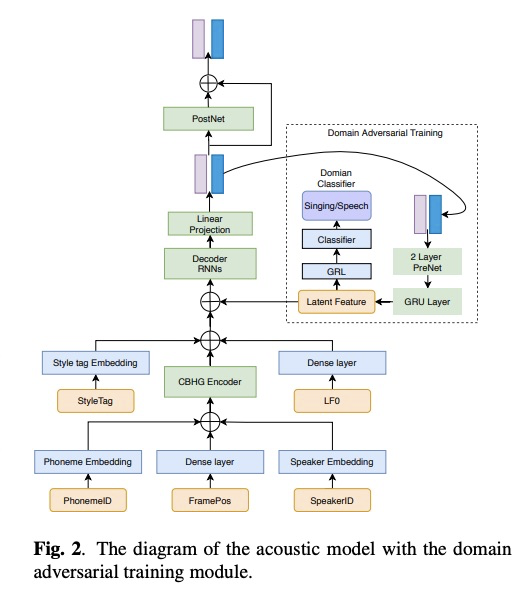
该系统主要包含三个模型(图1所示):Duration model (DM), LF0 prediction model (LF0M)和Acoustic model(AM),其中AM模型使用可domain adversarial training(DAT)进行歌唱类型解耦。另外,训练和推理阶段如图一所示,简单明了,而且每个模型的输入特征如table 1列出。其中声学模型如图2所示的encoder-decoder架构,其decoder为自回归模式(AM就是去掉attention的tacotron,因为已经有duration model了)。当进行推理阶段,先使用乐谱进行音素的duration预测,然后进行LF0的预测,最后设定目标speaker id和sing 的style tag进行声学特征的推理,最后使用声码器合成音频。
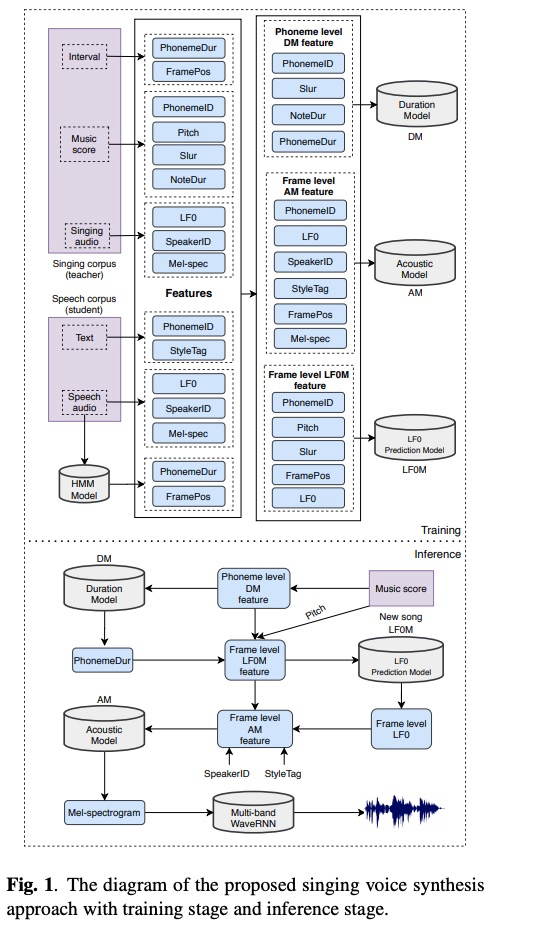
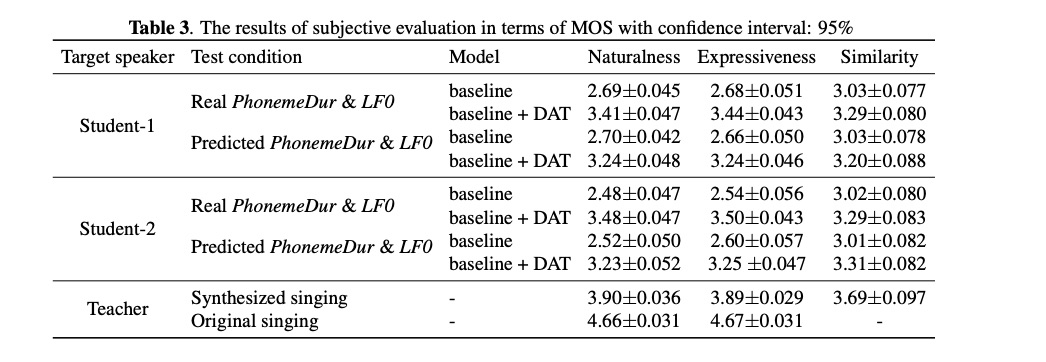
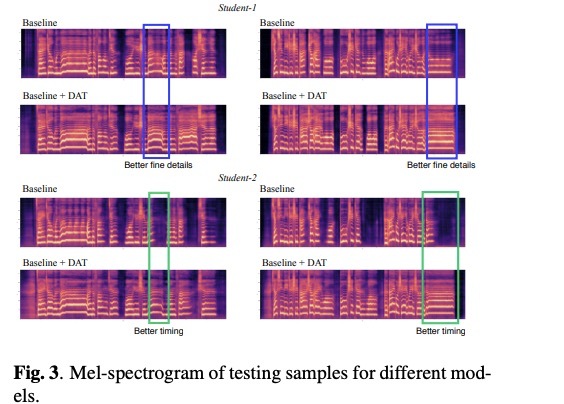
首先对比客观的指标,由table 2显示三个指标结果,其实最主要还是主观的听感。table 3的主观MOS测试显示,普通语句student 1和2 可以合成音乐,而且使用DAT网络效果更好,由图3的语谱图也可以看出使用DAT的频谱刻画更清晰。

3 总结
歌唱合成则是让机器唱歌,因此更具有娱乐性。互联网的时代,人机交互更加频繁和智能,歌唱合成则添加了人机交互的趣味性。但相比TTS,歌唱合成的训练语料十分昂贵,这也阻碍大量研究人员的脚步。本文根据是否拥有大量训练数据而采用的不同方案进行分类总结,以供同行参考。
4 引用
【1】Xue H, Yang S, Lei Y, et al. Learn2Sing: Target Speaker Singing Voice Synthesis by learning from a Singing Teacher[J]. arXiv preprint arXiv:2011.08467, 2020.
【2】Zhang L, Yu C, Lu H, et al. Durian-sc: Duration informed attention network based singing voice conversion system[J]. arXiv preprint arXiv:2008.03009, 2020.
【3】Chen J, Tan X, Luan J, et al. HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis[J]. arXiv preprint arXiv:2009.01776, 2020.
【4】Lu P, Wu J, Luan J, et al. XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System[J]. arXiv preprint arXiv:2006.06261, 2020.
【5】Gu Y, Yin X, Rao Y, et al. ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders[J]. arXiv preprint arXiv:2004.11012, 2020.
【6】Ren Y, Tan X, Qin T, et al. Deepsinger: Singing voice synthesis with data mined from the web[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1979-1989.