利用citespace对近十年来的相关中英文文献关键词进行突现分析,结果分别如下图所示:


关键词突现是指在短时间内发表文章中出现频次极高的关键词,从关键词突现开始至突现结束形成的红色线条,表明关键词在该研究领域的重要程度和被关注度。突现长度越长,说明该关键词热度持续时间越久;突现强度(Strength)越高,说明关键词在其突现期间内的热度越高。而淡蓝色的线条则表示该关键词在此期间还未出现[1]。
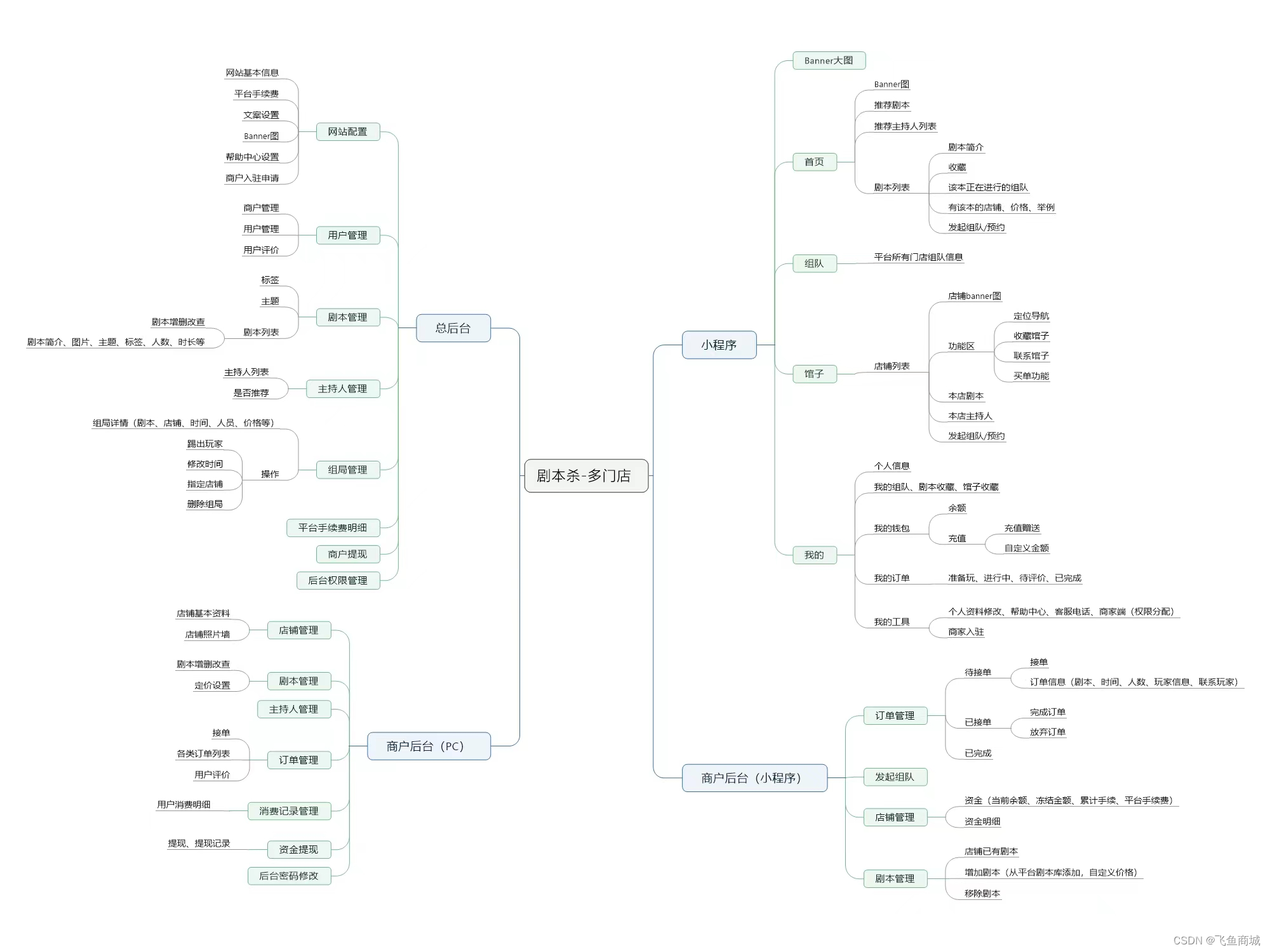
由图可见,近十年来,国内相关研究的热点集中于关联规则、数据挖掘、大数据、科研情景、用户画像、精准推荐等。其中,用户画像和科研情景在近五年来首次出现,并“持续走红”,可以预见在短期内也将成为图书馆智能推荐领域的热点之一。
在英文文献中,机器学习和人工智能在推荐系统的应用虽早有涉及,但由于近年来AI领域的快速发展,从去年开始首次呈现了突现现象。
下面来逐条分析一下:
一、背景的更新:大数据时代
大数据时代为个性化推荐服务提供了海量、多元、异构的数据来源,为传统的推荐服务带来了模式、方法上的更新,使得机器学习、用户画像等基于对海量数据挖掘的方法成为了可能。
二、模式的更新:数据挖掘
数据分析模式不再局限于传统的从“假设”到“验证”,而是出现了从“探索”到“解释”。数据挖掘就是从大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的过程。 在推荐算法中,数据挖掘被广泛地运用于发现用户的喜好模式,确定用户兴趣的各项指标及其内在联系,从而完成兴趣建模。
三、方法的更新
1、用户画像
用户画像的核心旨在分析每个用户的个性化需要,从而实现“一对一”的精准推荐服务。
用户画像最早于1999年由交互设计师cooper提出,在数字图书馆智能推荐服务中的应用最早出现于2017年,尚处于初级阶段。该领域的研究集中于模型的建立和算法的选择上,尚未形成跨学科、大规模的应用。[2]
2、科研情景感知
情境感知早在2008年开始就被引入到数字图书馆的推荐服务中。而针对科研人员查找文献这一具体情境的研究则最早出现于近五年内。
目前的研究认为,学者的研究领域、目前所处的项目课题等信息均会对其文献偏好产生一定的影响。而具体还有哪些信息、它们又是如何影响文献偏好的,还尚处于探索阶段。[3]
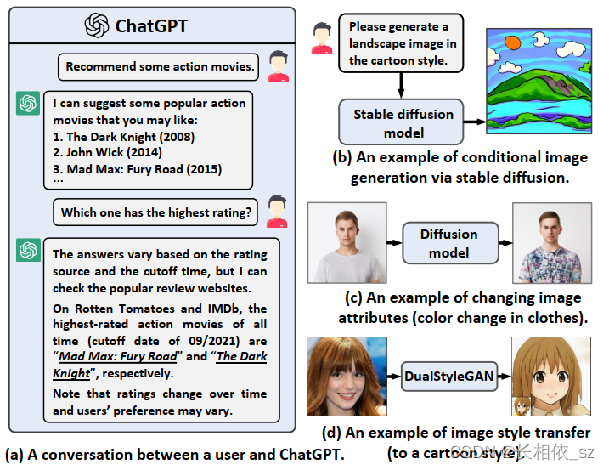
3、AI生成内容(AIGC)[3]
Wenjie Wang等人于今年4月份首次提出了将AIGC技术引入推荐系统中的设想。在该设想中,AI可以通过多模态对话的形式收集用户的自然语言,甚至图片、文档和音乐作为检索式,检索结果会被重组成为可读性更强的自然语言,甚至由AI生成的完全为用户定制化的全新内容。
该研究基于chatgpt的思想,在推荐中加入了交互的流程。比如我对这批推荐结果不满意,可以直接用自然语言或者多模态语言对话AI,告知我的需求,让它给我重新推荐一批。

四、新的问题
1、数据来源的隐私问题
读者数据涉及隐私,难以获取。如借阅记录、课题项目等敏感信息。
2、模型缺乏反馈机制
目前的数字图书馆领域所设计的推荐服务系统中普遍缺乏反馈机制,不利于推荐模型的验证与优化。
参考文献
[1]宋银李,孙瑜.国内数字化学习资源推荐算法研究热点、趋势和启示[J].云南师范大学学报(自然科学版),2022,42(03):60-66.
[2]吴赛楠. 基于用户画像的数字图书馆精准推荐服务研究[D].天津理工大学,2022.DOI:10.27360/d.cnki.gtlgy.2022.000679.
[3] Wang, Wenjie, et al. "Generative Recommendation: Towards Next-generation Recommender Paradigm." arXiv preprint arXiv:2304.03516 (2023).
[4]焦玉英,袁静.基于情景模型的数字图书馆个性化服务研究[J].中国图书馆学报,2008,No.178(06):58-63.