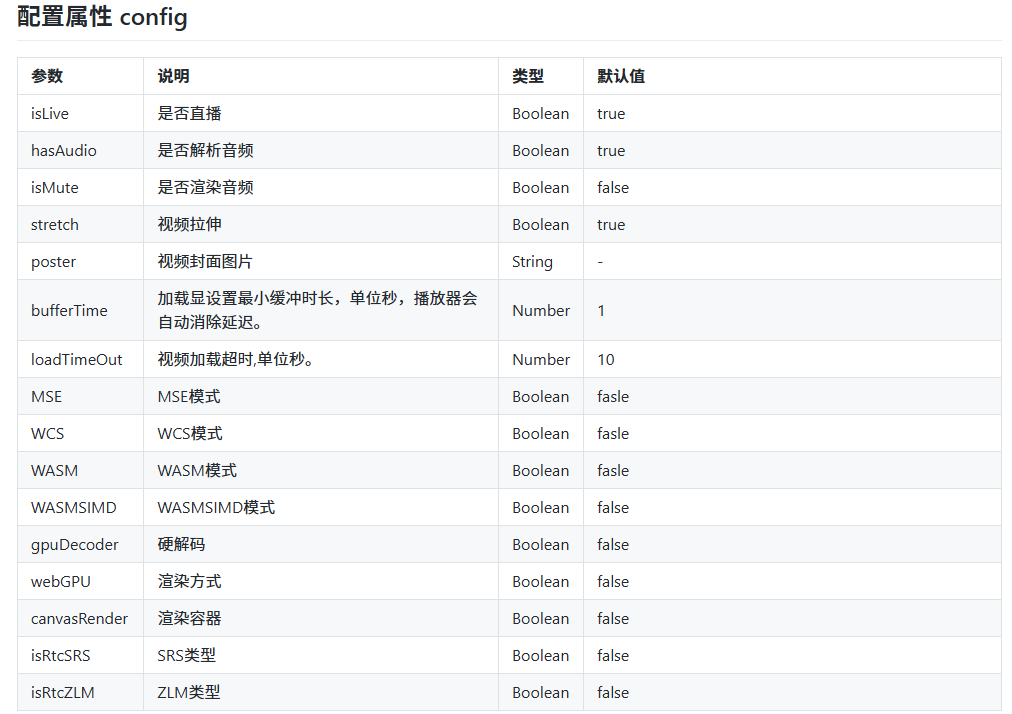
在国内视频大模型领域,生数科技一直以创新和突破而备受瞩目。近日,生数科技再度发力,发布了 Vidu 1.5 新版本,为视频创作带来了全新的变革与机遇。

Vidu 1.5 新版本在多个方面展现出了卓越的性能和创新的特点。首先,它成功突破了 “一致性” 难题,上线了 “多图参考” 功能。这一功能使得用户能够通过上传 1 - 3 张参考图,实现对单主体的精确控制,同时还能实现多主体交互控制以及主体与场景的融合控制。无论是人物、物体还是环境,都能在 Vidu 1.5 的处理下无缝集成。例如,用户可以上传主体、客体和环境的图片,轻松创建出定制角色身穿特定服装、在定制空间内自由动作的场景,甚至可以让多个自定义角色在指定空间内进行交互。
在技术突破方面,Vidu 1.5 具备涵盖人物、物体、环境等融合的多主体一致性能力。对于复杂主体,无论是细节丰富的角色还是复杂的物体,都能保证在多个不同视角下的一致性。即使是造型复杂的 3D 动画风格角色,在各种刁钻视角下,头型、服饰等细节也能保持一致。在人物特写画面中,人物面部特征细节和动态表情自然流畅,不会出现面部僵硬或失真现象。
除了在一致性方面的突破,Vidu 1.5 还具备上下文学习能力,标志着视觉模型进入了 “上下文时代”。与语言模型类似,经过充分训练的 Vidu 1.5 能够深刻理解、记忆上下文,告别了单点微调的局限性。
在生成效率上,Vidu 1.5 延续了其业界领先的优势,不到 30 秒即可生成一段视频。这使得用户能够在短时间内获得高质量的视频内容,大大提高了创作效率。
此外,Vidu 1.5 版本背后的基础模型能力全面提升,采用了不同于业界主流的 LoRA 微调方案。它无需专门的数据采集、数据标注、微调训练环节,一键即可直出高一致性视频,为用户省去了繁琐的 “炼丹” 环节。
总的来说,生数科技发布的 Vidu 1.5 新版本在多主体一致性、上下文学习能力、生成效率等方面都取得了重大突破。这一版本的发布为视频创作和相关应用领域带来了新的可能性,有望引领视频大模型的新潮流。相信在未来,生数科技将继续以创新为动力,为用户带来更多先进、高效的视频大模型解决方案。
Open-sora等热门视频生成大模型一键使用项目链接
https://www.suanjiayun.com/mirrorDetails?id=66c54b11fbec1d941254476e








![[JavaWeb]微头条项目](https://i-blog.csdnimg.cn/direct/0c31d247d38e4f1783db876d54c63591.png)





![[ 网络安全介绍 1 ] 什么是网络安全?](https://i-blog.csdnimg.cn/direct/df118a143f5f40db9f84ca3626ebfed0.png)