本文采用MATLAB编程,使用生成对抗网络GAN生成数据集:输出生成数据集EXCEL格式文件,方便大家使用。
实际工程应用中,由于经济成本和人力成本的限制,获取大量典型的有标签的数据变得极具挑战,造成了训练样本数量非常有限。数据增强方法为解决此类问题提供了简单但有效的思路。深度神经网络强大的特征表示能力和非线性拟合能力源自于对高质量数据集的充足学习,基于深度生成对抗网络(Generative Adversarial Network,GAN)模型的数据增强方法,在学习复杂高维数据分布方面表现出了极其优越的性能,为解决数据问题提供了一个新视角。
生成对抗网络(Generative Adversarial Network,GAN),是一种深度学习模型。GAN网络主要由两部分组成,即生成器(Generator)和判别器(Discriminator)。生成器的任务是接收随机噪声向量作为输入,并尽可能生成与真实数据相似的样本,而判别器则是一个二分类器,旨在区分输入的样本是来自生成器生成的,还是来自真实数据。
在训练过程中,生成器和判别器通过对抗学习的方式相互博弈,生成器的目标是生成足以欺骗判别器的样本,而判别器的目标则是尽可能准确地判断样本的真实性。这种对抗过程持续进行,直到达到纳什均衡,此时生成器的生成能力足够强大,使得判别器无法有效区分真假样本。
GAN网络在多个领域展现了强大的能力,能够生成与训练数据分布相似的新数据,包括但不限于图像生成、图像风格转换、超分辨率、数据增强、视频生成、自然语言处理、医学图像处理以及游戏与虚拟现实等。
本文将生成对抗网络GAN应用在数值型数据集生成中,有效地解决数据不充足的问题。
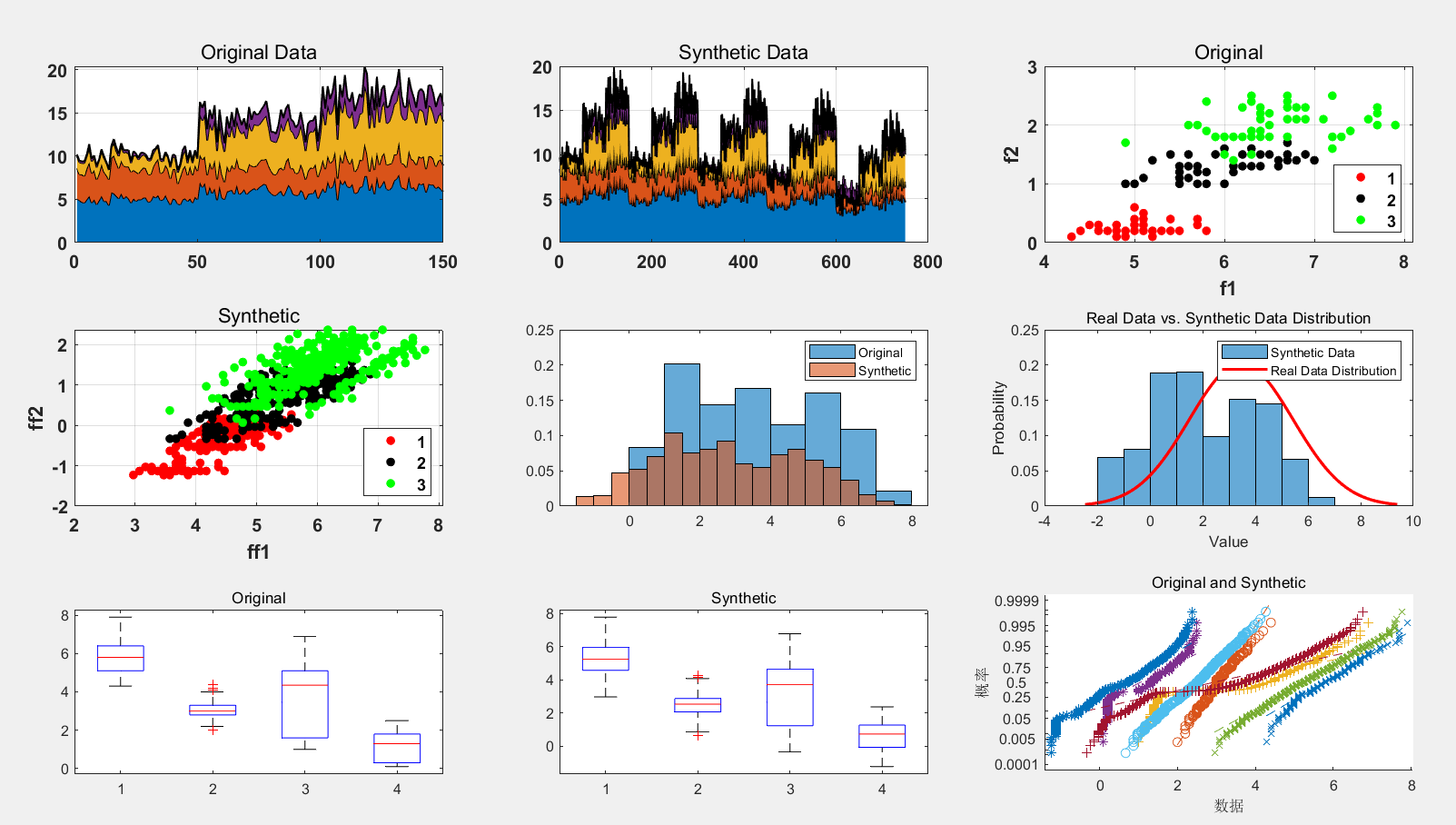
本文利用机器学习中的经典数据集iris数据集:该数据集有3类,每类50个样本,每个样本4个特征,共150个样本*4个特征。利用GAN生成750个样本数据,并选择用SVM作为分类器(也可以使用其他的分类器)进行分类,用以简单地验证GAN数据的生成质量。生成数据作为训练集用以训练分类器SVM,原始数据作为测试集用以测试。最后结果展示包括了原始数据,和生成数据的分布,概率密度函数分布,每个特征的分布boxplot等。最后svm的分类精度:训练精度96.5333,测试精度96.667。
运行效果如下:
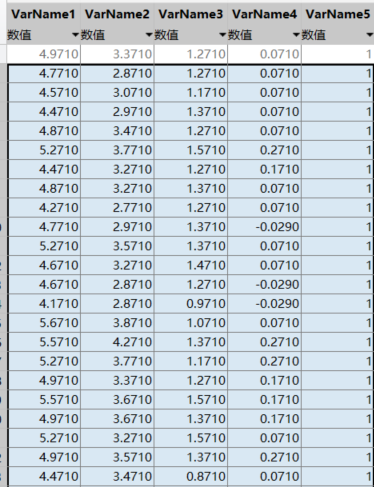
生成的数据集excel样式如下:(含150样本*5=750个样本)



![[C++]:C++11(三)](https://img-blog.csdnimg.cn/img_convert/62dce5d4546ef8b4571dadefce0f2fb0.png)