本文为您介绍如何配置不同MaxCompute项目并实现数据迁移。
背景信息
本文使用的被迁移的原始项目为教程《简单用户画像分析(MaxCompute版)》中的WorkShop2023项目,您需要再创建一个迁移目标项目,用于存放原始项目的表、资源、配置和数据。
注意事项
仅华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华南1(深圳)和西南1(成都)地域支持跨地域迁移。
操作步骤
-
创建迁移目标项目
登录DataWorks控制台,创建工作空间并绑定MaxCompute引擎。具体操作请参见创建工作空间和绑定MaxCompute引擎。
说明
由于原始项目WorkShop2023为标准模式,因此本文中DataWorks工作空间模式也选择标准模式,本文中目标项目名称以clone_test_doc为例。
-
跨项目克隆
您可以通过跨项目克隆功能将原始项目WorkShop2023的节点配置和资源复制到当前项目,详情请参见跨项目克隆实践。
说明
-
跨项目克隆无法复制表结构与数据。
-
跨项目克隆无法复制组合节点,需要您手动创建。
-
单击原始项目WorkShop2023右上角的跨项目克隆,跳转至相应的克隆页面。

-
选择克隆目标工作空间为clone_test_doc,业务流程为您需要克隆的业务流程Workshop,勾选所有节点,单击添加到待克隆后单击右侧的待克隆列表。
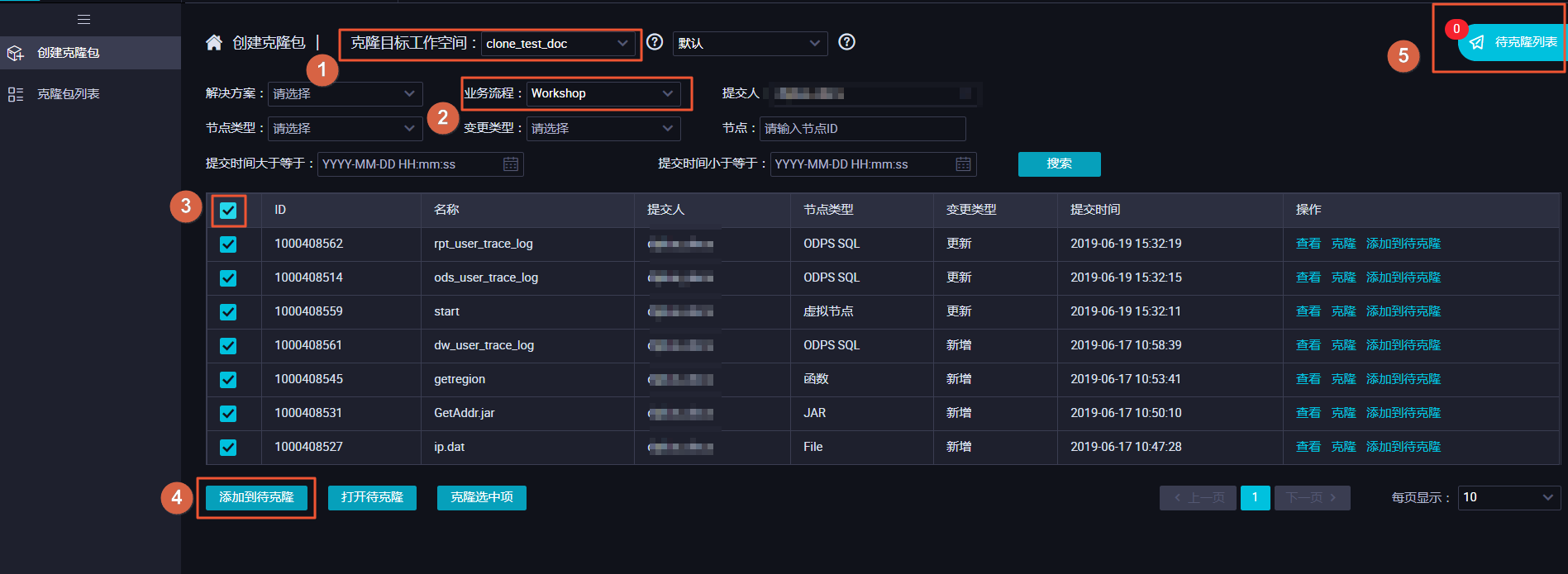
-
单击全部克隆,将选中的节点克隆至工作空间clone_test_doc。
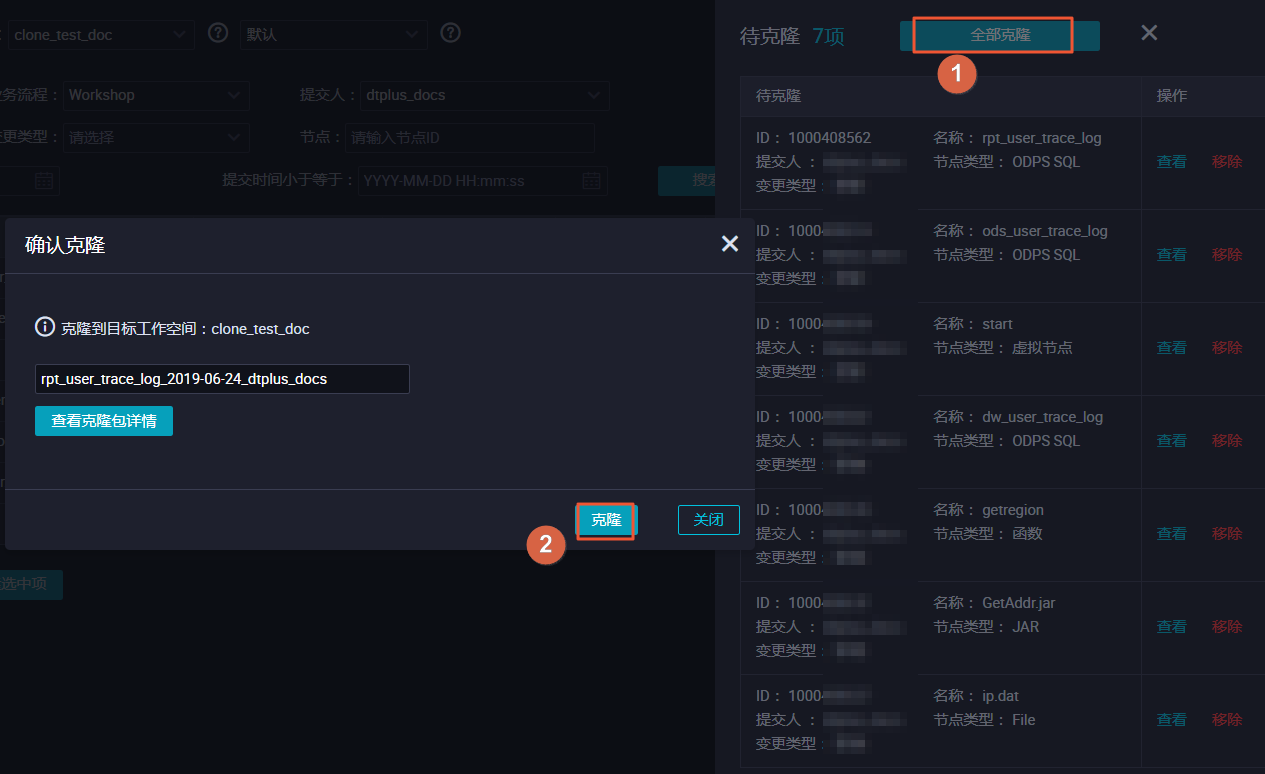
-
切换至您新建的项目,检查节点是否已完成克隆。
-
-
新建数据表
跨项目克隆功能无法克隆您的表结构,因此您需要手动新建表。
-
对于非分区表,建议使用如下语句迁移表结构。
create table table_name as select * from 源库MaxCompute项目.表名 ; -
对于分区表,建议使用如下语句迁移表结构。
create table table_name partitioned by (分区列 string);
新建表后请将表提交到生产环境。更多建表信息,请参见创建并使用MaxCompute表。
-
-
数据同步
跨项目克隆功能无法复制原始项目的数据到新项目,因此您需要手动同步数据,本文中仅同步表ods_user_info_d的数据。
-
新建数据源。
-
在数据集成页面,单击左侧导航栏上的数据源。
-
在数据源管理页面,单击右上角新增数据源,并选择MaxCompute(ODPS)。
-
填写您的数据源名称、ODPS项目名称、AccessKey ID、AccessKey Secret等信息,单击完成,详情请参见配置MaxCompute数据源。
-
-
创建数据同步任务。
创建数据同步任务操作详情,请参见通过向导模式配置离线同步任务。
-
在数据开发页面右键单击您克隆的业务流程Workshop下的数据集成,选择新建 > 离线同步。
-
编辑您新建的数据同步任务节点,其中数据源WorkShop2023是您的原始项目,数据源odps_first代表您当前的新建项目,表名是您需要同步数据的表ods_user_info_d。完成后单击调度配置。
-
单击使用工作空间根节点后,提交数据同步任务。
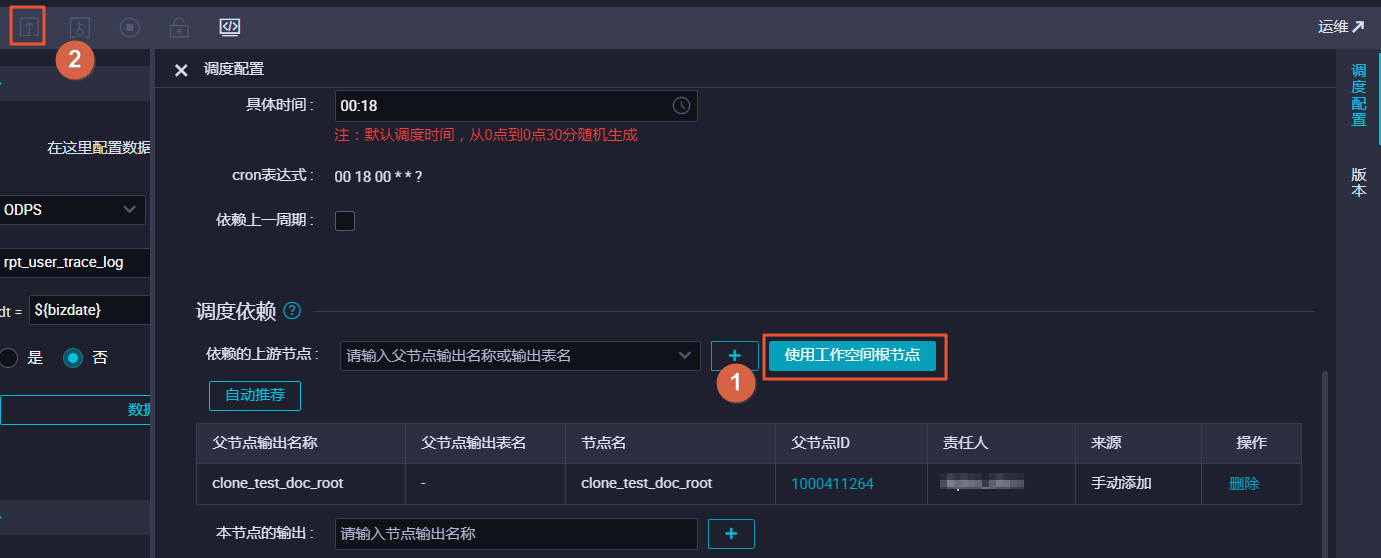
-
-
补数据
-
单击左上角的图标,选择全部产品 > 运维中心。
-
单击左侧导航栏中的周期任务运维 > 周期任务。
-
右键单击您的数据同步任务,选择补数据 > 当前节点。
-
本例中,需要补数据的日期分区为2019年6月11日到17日,您可以直接选择业务日期,进行多个分区的数据同步。完成设置后,单击确定。
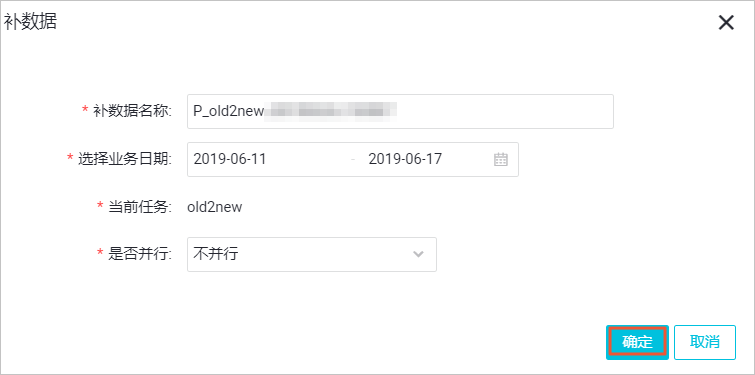
说明
您可以根据自己的业务需求,设置业务日期。
-
在周期任务运维 > 补数据实例页面,您可以查看补数据实例任务运行状态,显示运行成功则说明完成数据同步。
-
-
验证结果
您可以在业务流程 > 数据开发中新建ODPS SQL类型节点,执行如下语句查看数据是否完成同步。
select * from ods_user_info_d where dt BETWEEN '20190611' and '20190617';
-











![YOLOv11融合[NeurlS2022]递归门控卷积gnconv模块及相关改进思路](https://i-blog.csdnimg.cn/direct/bb97315c0482458cb76d86b45eb455d6.png)





