文章目录
- 1、概论
- 2、什么是知识图谱?
- 3、知识图谱能做什么?
- 4、知识图谱的技术路线图
- 5、知识图谱构建
- 5.1、构建知识图谱的生命周期
- 5.2、Schema定义
- 5.3、知识抽取
- 5.4、知识融合
- 5.5、知识存储
- 5.6、知识推理
- 6、知识图谱应用
- 6.1 搜索
- 6.2 问答系统(可整合 ChatGPT 语言模型)
- 6.3 推荐系统
- 7、图谱建设的一些经验
1、概论
知识图谱(KnowledgeGraph)以结构化的形式描述客观世界中的概念实体及其关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织,管理和理解互联网海量信息的能力。
知识图谱关注概念,实体及其关系,其中实体是客观世界中的事物,概念是对具有相同属性的事物的概括和抽象。本体是知识图谱的知识表示基础,可以形式化表示为O={C,H,P,A,I},C为概念集合,如事务性概念和事件类概念,Hshi概念的上下位关系集合,P是属性集合,描述概念所具有的特征,A是规则集合,描述领域规则,I是实例集合,描述实例-属性-值。
2、什么是知识图谱?
知识图谱的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
什么是对关系图?
图(Graph)是由节点(Vertex)和边(Edge)来构成,但这些图通常只包含一种类型的节点和边。多关系图一般包含多种类型的节点和多种类型的边。

- 知识图谱中,我们通用“
实体(Entity)”来表达图中的节点,用“关系(Relation)”来表达图中的边; - 实体指的是显示世界中的事物比如人、地名、概念、药物、公司等,关系则用来表达不同实体之间的某种联系。
李小龙的关系图谱:

从数据角度来看,知识图谱通过对结果化数据、非结构化数据、半结构化数据进行处理、抽取、整合,转化成“实体—关系—实体”的三元组。

3、知识图谱能做什么?
这个问题的答案是非常宽泛的,如果从一个知识库或者数据库的角度来看,知识图谱可以是任何系统的基础工程,涉及到存储、记忆、分析和智能的东西,都可以应用知识图谱。知识图谱首先是一个规模庞大的数据库(或者说知识库),百万级、亿级的数据相互关联,可以从更多维度对事物进行更精确的分析。
知识图谱可以用于以下几个领域:
- 语义网和智能问答:知识图谱可以作为语义网的基础,提供一种描述现实世界中实体、概念以及它们之间关系的方法,使得计算机能够理解并处理这些信息,从而为智能问答提供支持。
- 自然语言处理:知识图谱可以用于自然语言处理中的语义分析和理解,通过对文本中的实体、概念以及它们之间关系的识别和抽取,提高自然语言处理的准确性和效率。
- 人工智能和机器学习:知识图谱可以用于提高机器学习算法的准确性和效率,通过对知识的抽取和表示,帮助机器更好地理解和处理数据。
- 生物信息学和社交网络分析:知识图谱可以用于描述和分析生物信息学中的基因、蛋白质和疾病等实体之间的关系,以及社交网络中的用户、信息和关系等。
- 推荐系统:知识图谱可以用于构建推荐系统,通过对用户兴趣和行为的建模,提供个性化的推荐服务。
- 搜索和信息检索:知识图谱可以用于提高搜索和信息检索的准确性和效率,通过对用户查询的理解和分析,提供更相关的结果。
4、知识图谱的技术路线图
知识图谱有广泛的应用和巨大的应用价值,越来越多的企业也在着手进行知识图谱的构建。
按流程来说,知识图谱具有知识表示与建模、知识抽取、知识融合、知识图谱推理、知识统计与图挖掘、知识检索与知识分析等主要的几步。
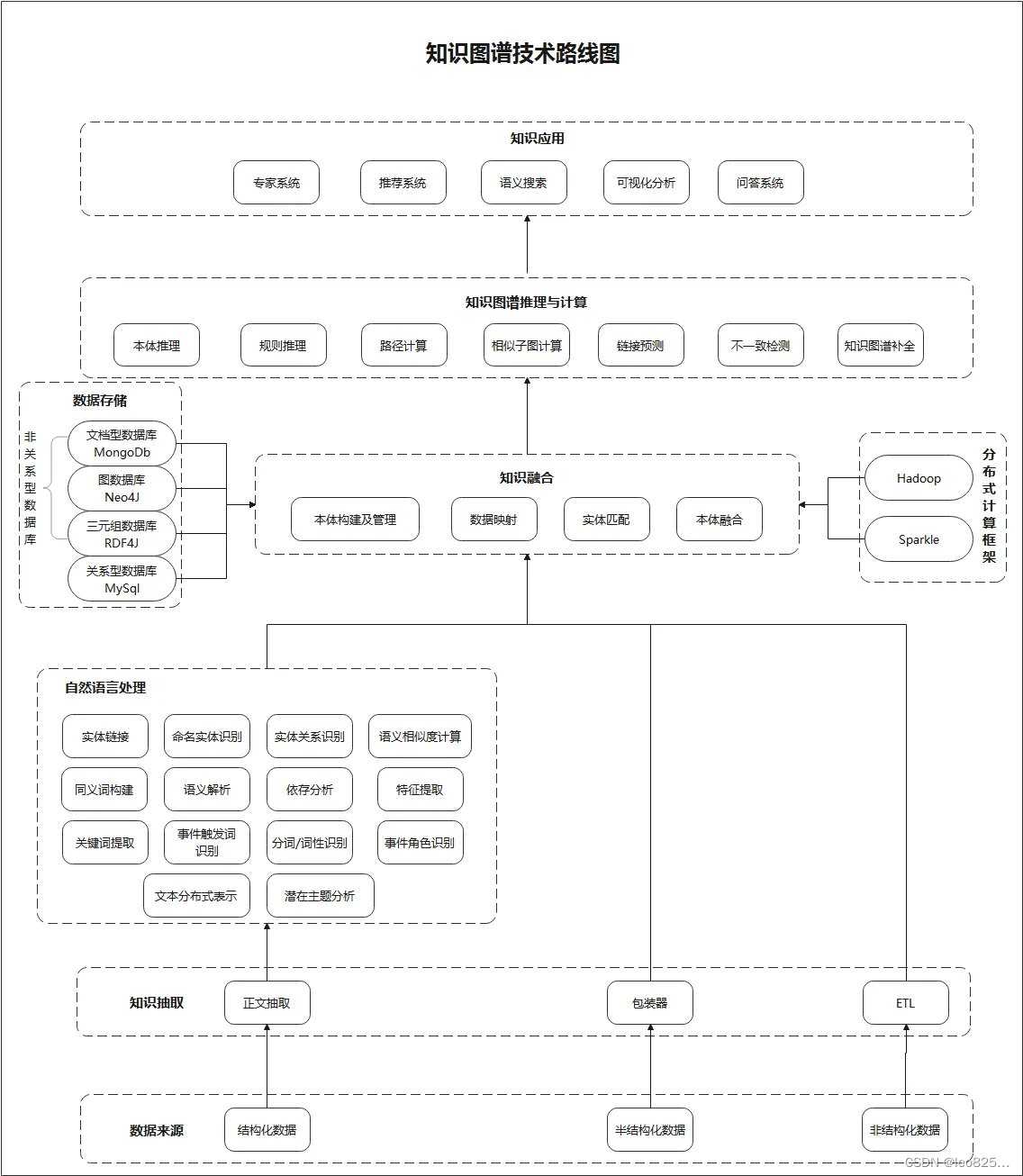
5、知识图谱构建
5.1、构建知识图谱的生命周期
构建知识图谱的生命周期:Schema 定义、知识抽取、知识融合、知识存储、知识推理这样的循环迭代的过程。

- 什么是本体?
Ontology:通常翻译为“本体”。本体本身是个哲学名词。在上个世纪80年代,人工智能研究人员将这一概念引入了计算机领域。Tom Gruber 把本体定义为“概念和关系的形式化描述”。通俗点讲,本体相似于数据库中的 Schema ,比如足球领域,主要用来定义类和关系,以及类层次和关系层次等。OWL 是最常用的本体描述语言。本体通常被用来为知识图谱定义 Schema 。
举个例子:
张三是一个实体,其具有年龄、性别、职业等属性;
同时,张三是一个人,“人类”就是一个概念、类似的还有“国家”,“民族”等抽象概念;
本体是概念的集合,知识图谱本体层的东西就是各种概念及其属性和关系。
5.2、Schema定义
- Schema 是什么?
限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性。 - Schema 有什么作用?
规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中。
5.3、知识抽取
从各种数据源中进行实体识别、关系识别,从而抽取实体、关系、属性以及实体间的关系,属性的值,完成本体的知识表达,具体可以参照前文关于知识库的表达部分。对于知识图谱来说,数据源我们知道有结构化数据,非结构化数据和半结构化数据。
数据来源一般有:
- 业务的关系数据,这些数据通常包含在公司内数据库中;一般是结构化数据,或者是系统交互中Jison数据,虽然没有结构化,但是仍然可以通过功能进行存储,这种数据一般定义好本体库可以直接使用;
- 网上公开发布的可以抓取的数据,通常以网页形式存在,这种一般要通过爬虫技术,通过本体库相关关键词进行数据的爬取并结构化;
- 相关合同、文件等,比如一些保险合同、电子发票信息等;这种一般需要自然语言处理技术,进行数据信息的结构化提取。
信息的抽取是知识图谱构建的第一步,关键的点是:如何从数据源中自动抽取到实体、关系、以及属性等机构化技术。
实体抽取又称为实体识别,就是从文本中自动识别出来命名的实体,它是信息抽取中最基础的部分。
关系抽取就是进行语义的识别,抽取到实体间的关系,这个是信息抽取中最关键的部分,也是形成网状知识结构的基础。
关系的识别运用到各种算法模型以及机器学习的方法,属性抽取实现的是实体属性的完整勾勒。
5.4、知识融合
主要是新知识的融合、整合、判别同义、近义、消除歧义、矛盾。
比如,某些实体数据在显示世界中有多种表达方式,公司的注册名称、公司的简称等,要对这些知识进行同义融合,再比如某些特定的称谓也许对应着多个不同的实体。
知识融合包括两部分:实体链接和知识合并。
- 实体链接:是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。一般是从知识库中选中一些候选的对象,然后通过相似度将指定对象链接到正确的实体。流程如下:通过实体抽取获取实体指称项——通过实体消歧(解决同名实体歧义)和共指消解(多个指称指向同一实体进行相应的合并)——将实体指称链接到知识库对应实体。
- 知识合并:从第三方知识库产品或是已有的结构化数据中进行知识的获取,一般是合并外部知识库和和合并关系数据库,合并中要避免实体与关系的冲突问题,防止不必要的冗余。
5.5、知识存储
知识图谱主要有两种存储方式:一种是基于 RDF 的存储;另一种是基于图数据库的存储。它们之间的区别如下图所示。RDF 一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF 以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

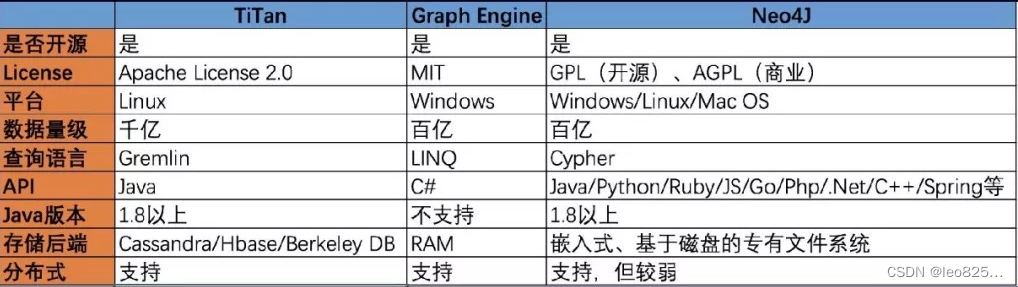
知识存储,就是如何选择数据库,从选择层面,我们有图数据库,有NoSQL的数据库,也有关系型数据库,数据库有很多选择。具体什么样的情况下选择什么样的数据库?通常是如果说知识图谱的关系结构非常的复杂、关系非常的多,这时候建议使用这个图数据库,比如Neo4J这样的数据库。顺便了解一下目前主流的几款图数据库,Titan、Graph Engine、Neo4J这个三个分别都是开源的,然后Titan是Apache旗下的,Graph Engine是MIT的License,Neo4J是GPL开源的,既有商业版,也有也有开源免费版。然后它们的平台,像Titan是Linux,Graph是windows。而数据的支撑量级,像Titan是后端存储,基于Cassandra/Hbase/BDB这样的分布式存储引擎,可以支持更大的数据量,千亿级的数据量级;Neo4J商业版也可以支持到百亿级的,但是它的非商业版在数据量级比较大的时候,一般是在几千万级的时候就可能会出现一些问题。
5.6、知识推理
知识推理这边有几种方法,基于符号的推理、基于 OWL 本体的推理、基于图的方法(PRA算法)、基于分布式知识语义 标识方法(Trans系列模型)、TransR 模型、基于深度学习的推理。
知识图谱不仅仅是根据关系的检索,更大的核心用途是推理,发现图谱中的隐藏关系,而不是发现新知识。
1)通过实体间的关系推理相关关系
通过多实体间的关系,可以推断其他的关系,比如张三和李四之间是夫妻关系,王五是张三的领导,王五居住在A城市,我们可以推论李四也居住在A城市。
2)通过实体间的关系推理相关属性
通过多实体间的关系,实体的属性值,可以推断其实体的属性值。这个与通过实体间的关系推论关系道理类似,也可以通过一个实体间的关系、根据实体的属性推断另一个实体的属性。
在AI中涉及到推理的方法有很多,有基于逻辑的推理,有基于深度学习的推——这个就是基于图谱的推理,也就是通过关系、属性的因素做的推理。
6、知识图谱应用
在知识图谱的应用阶段已经简要说明了通用领域知识图谱和专用领域知识图谱的应用,这里只聚焦其中三项技术:搜素、问答系统、推荐系统。
6.1 搜索
知识图谱依托庞大的数据和关系对,可以对搜索进行增强,不但针对搜索词展示出最接近的信息,还把相关的选项也展示出来,提高了查准率和查全率,另外可以通过图谱化的展现和互动让用户更加方便的了解信息。
一个语义搜索系统的基本框架包括查询构建、查询处理、结果展示、查询优化、语义模型、资源及文档等。
具体的应用中,如搜索“混凝土”,不仅搜索混凝土,还会找到其在知识图谱中的上位词,下位词,同义词等词集合,比如砼(同义词)、轻质混凝土(下位词)等等。
6.2 问答系统(可整合 ChatGPT 语言模型)
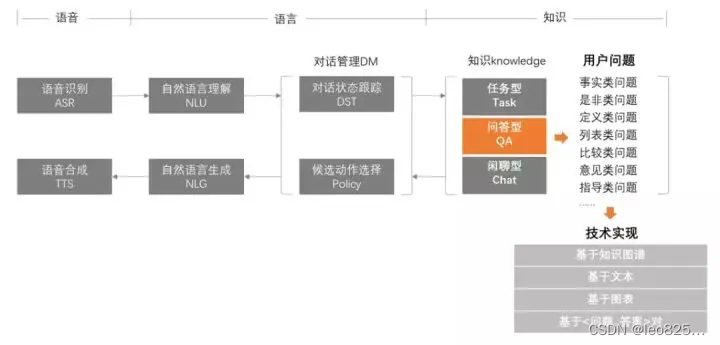
知识问答是用自然语言的方式与机器进行交互并得到答案,是知识图谱的重要应用。问答是一种典型的智能行为,图灵测试就是看机器能否做到人一样的问答效果。问答系统不但要求系统本身能够理解提问者的语义,还要求根据知识图谱进行知识搜索或知识推理以形成答案。可以说问答系统是信息检索系统的一种高级形式,因为问答系统中同样有查询式理解和知识检索这两个重要过程,且与智能搜索中相应过程中的相关细节是一致的。
一个问答系统应具备的四大要素:
(1)问题
是问答系统的输入,通常以问句的形式出现(问答题),也会采用选择题、多选题、列举答案题和填空题等形式。
(2)答案
是问答系统的输出,除了文本表示的答案(问答题或填空题),有时也需要输出一组答案(列举问答题)、候选答案的选择(选择题)、甚至是多媒体信息。
(3)智能体
是问答系统的执行者,需要理解问题的语义,掌握并使用知识库解答问题,并最终生成人可读的答案;
(4)知识库
存储了问答系统的知识,其形态可以是文本、数据库或知识图谱。
问答系统框架:
6.3 推荐系统
推荐系统是我们每天都能接触到的系统,如淘宝的千人千面,网易云音乐的个性化歌单,目前的个性化推荐算法中应用最广的是协同过滤算法。
协同过滤分为协同和过滤两个步骤,协同就是利用群体的行为来做推荐决策,而过滤就是从可行的推荐方案中将用户最喜欢的方案找出来。通过群体的协同和每个用户是否喜欢推荐的反馈不断迭代,最终的推荐会越来越准确。当前协同过滤算法主要包括基于用户的协同过滤和基于物品的协同过滤,其核心是怎么计算标的物之间的相似度以及用户之间的相似度。
将与当前用户最相似的用户喜欢的标的物推荐给该用户,这就是基于用户的协同过滤的核心思想;将用户操作过的标的物最相似的标的物推荐给用户,这就是基于标的物的协同过滤的核心思想。
推荐的过程可以简单理解为三个步骤:召回、过滤、排序。
- 首先系统根据获取到的信息,召回适合推荐内容,获取的信息可以是用户的搜索记录、购买记录、评论等。
- 召回的内容中有的是这个用户不关注的,需要根据过滤的条件,将不需要的内容进行过滤。
- 经过过滤产生的推荐集还需要根据内容的相关度进行排序,最后系统根据相关度的排序,将内容分配到对应的模块,这样用户就能看到自己感兴趣的内容了。
基于协同过滤的推荐系统,主要有以下问题:
- 数据稀疏/长尾/噪音问题
用于协同过滤计算的用户行为矩阵(用户和其对应有交互(如购买,点赞,收藏等)的物品矩阵),必然是一个稀疏矩阵,用较小范围的数据推测较大范围的数据,会存在预测不准确的问题。 - 冷启动问题
对于新加入的用户或者物品,系统没有其历史交互信息,很难对其进行准确建模和推荐,相对应的推荐准确率和多样性也会大打折扣。 - 可解释性
协同过滤算法侧重输入和输出,与神经网络模型一样类似于一个黑盒,计算模型提炼出的有效特征是什么很难说明,即决策的依据模糊,缺乏可解释性。
知识图谱可以针对这些问题进行改善,知识图谱可以用来表示实体之间的关系,如推荐系统中物品与物品、用户与物品、用户与用户之间的关系。
7、图谱建设的一些经验
我们在知识图谱建设当中的一些经验:
- 第一,界定好范围,就是要有一个明确的场景和问题的定义,不能说为了知识图谱而知识图谱。如果没有想清楚知识图谱有什么样的应用的场景,或者能解决什么样的问题,这样的知识图谱是比较难以落地的。一些明确的场景,比如解决商品数据的搜索问题,或者从产品说明书里面做相关问题的回答。
- 第二,做好schema的定义,就是上面讲到的对于schema或者本体的定义。第一步确定好场景和问题以后,就基于这样的场景或者问题,再进行相关领域的schema的定义。定义这个领域里概念的层次结构、概念之间的关系的类型,这样做是确保整个知识图谱是比较严谨的,知识的准确性是比较可靠的。知识的模型的定义,或者schema的定义,大部分情况下是通过这个领域的知识专家的参与,自上而下的方式去定义的。
- 第三,数据是知识图谱构建基础。数据的梳理就比较重要,最需要什么样的数据?依赖于我们要解决的问题是什么,或者我们的应用场景是什么?基于问题和场景,梳理出领域相关的问题、相关的数据,包括结构化的数据、半结构化数据、无结构化的数据,结合百科跟这个领域相关的数据,领域的词典,或者领域专家的经验的规则。
- 第四,不要重复去造轮子,很多百科的数据和开放知识图谱的数据,是可以融合到我们的领域知识图谱中。
- 第五,要有验证和反馈机制,需要有管理后台,用户可以不断的和知识图谱系统进行交互,不断的进行确认和验证,确保知识图谱每一步推理和计算都是准确的。
- 第六,知识图谱构建是持续迭代的系统工程,不可能一蹴而就。




![[chatgpt+Azure]unity AI二次元小女友之使用微软Azure服务实现RestfulApi->语音识别+语音合成](https://img-blog.csdnimg.cn/img_convert/cf59bffe4cdf304c6a0534b651431e46.png)