作者:燕返
简介
CLUE(中文语言理解测评基准)是中文语言理解领域的权威榜单,包含多项测评任务。近日,达摩院NLP团队在其中的语义匹配榜登顶,并在魔搭社区(ModelScope)上开源了预训练和微调后的模型。本文将介绍该模型及其使用方法。
模型链接:https://modelscope.cn/models/damo/nlp_masts_sentence-similarity_clue_chinese-large/summary
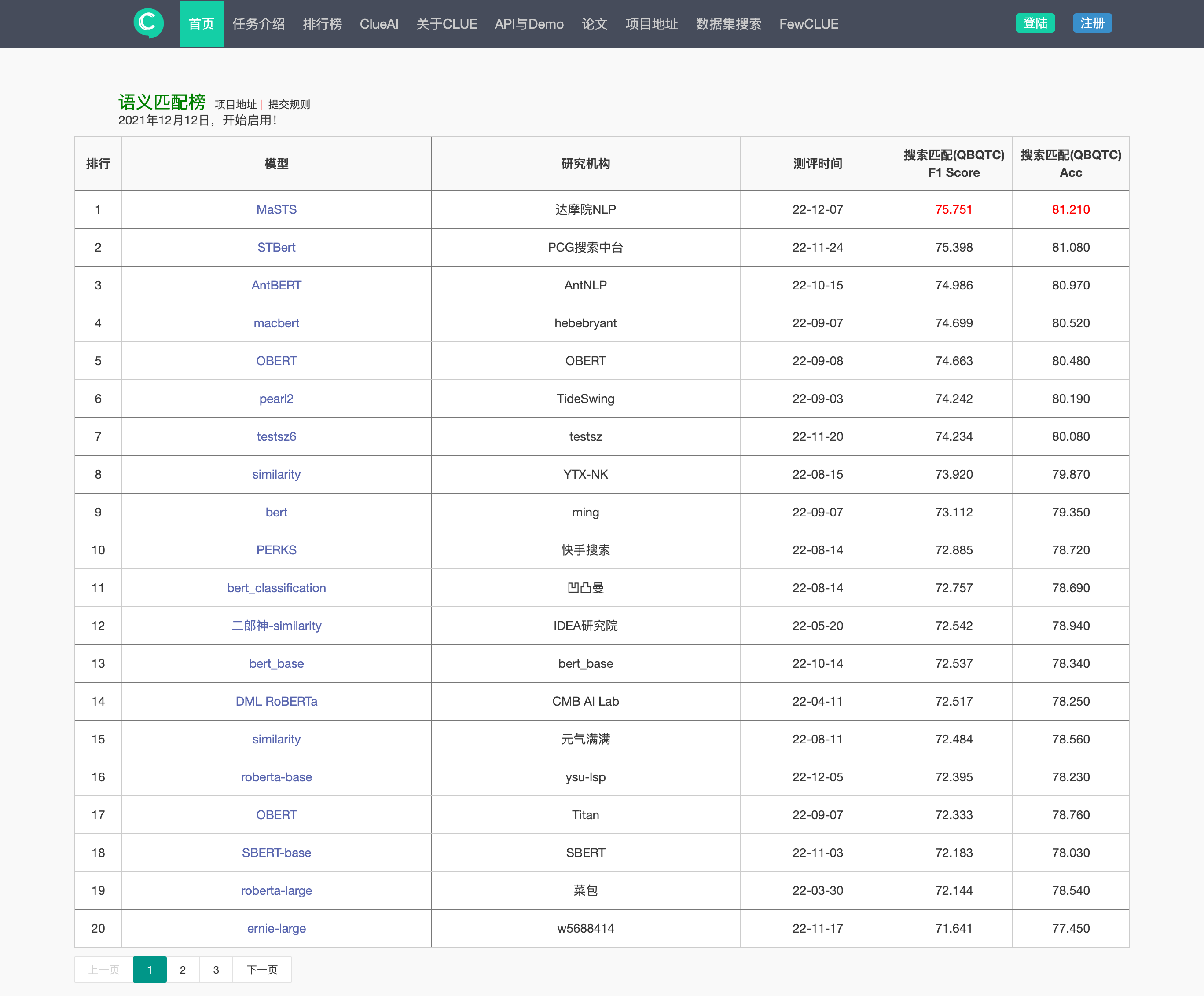
CLUE语义匹配任务
CLUE作为最常用的中文NLP模型的评估基准,其各个榜单的排名已经成为衡量NLP技术水平的重要指标,推动着NLP技术的不断进步和突破。语义匹配是NLP领域中的一个重要的任务,旨在从语义上衡量两段文本的相关性。
语义匹配在产业界有着广泛的应用场景,如社区问答、信息检索和推荐等。在搜索相关性场景下,语义匹配用于衡量Query和Document的相关程度,是搜索引擎中的重要一环。基于针对大搜场景的搜索相关性数据集,CLUE构建了语义匹配榜,吸引了众多国内的NLP团队参与。
通常来讲,语义匹配是一个二分类问题,即两段文本相关或不相关。而CLUE语义匹配榜对文本的相关性进行了进一步的细化,分成了三档,即“0”代表相关程度差,“1”代表有一定相关性,“2”代表非常相关,数字越大表示相关性越高。此外,CLUE语义匹配数据集也融合了相关性、权威性、内容质量、 时效性等维度。
MaSTS模型
此次达摩院NLP团队登顶CLUE语义匹配榜,得益于其在预训练和语义匹配领域的长期的耕耘,以及对相关算法的持续跟进迭代。预训练技术通常能够给多个NLP下游任务带来提升,如文本分类,序列标注和阅读理解。而领域适应预训练同样能够在各业务领域带来显著的帮助[1]。达摩院NLP团队针对搜索相关性领域开发了一套新的预训练方法MaSTS,改进了MLM任务的掩码策略,较通用模型能够获得更好的效果。

在微调阶段,模型采用了基于交互的深度语义匹配方法[2]。基于MaSTS预训练模型,将Query的文本(Text 1)和Document的文本(Text 2)通过特殊字符SEP拼接在一起,通过多个Transformer建立Query和Document文本之间的匹配信号。最终基于特殊字符CLS通过MLP网络计算各个相关性的概率。将多个微调后的模型基于相关性的概率进行集成后,最终输出的结果在CLUE语义匹配榜获得了榜首。相关预训练和微调后的模型已经在魔搭社区(ModelScope)上开源,并可以轻松上手使用。
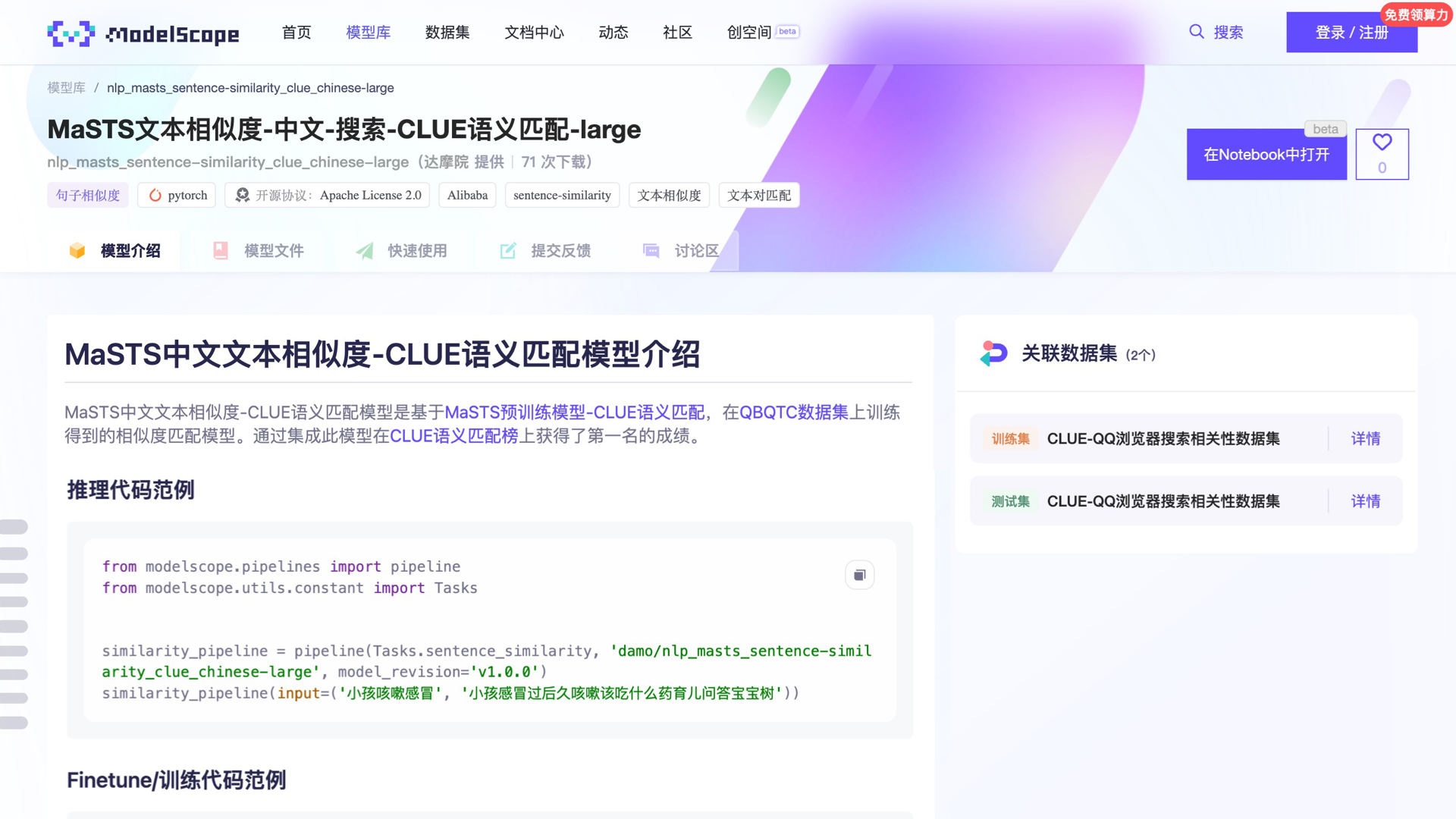
魔搭社区(ModelScope)是由阿里巴巴达摩院,联合CCF开源发展委员会,共同作为项目发起方成立的一个模型开源社区及创新平台。 达摩院的众多业界领先模型都在魔搭社区上开源。打开魔搭社区提供的Notebook,就能够非常简易地调用MaSTS中文文本相似度模型,以及微调MaSTS预训练模型。
使用教程
接下来我们介绍如何轻松使用阿里达摩院开源在魔搭社区上的CLUE语义匹配模型。
模型微调
首先载入QBQTC数据集。与之前的方法类似,我们也将Dev集加入训练[3]。
from modelscope.msdatasets import MsDataset
from datasets import concatenate_datasetsdataset_id = 'QBQTC'# 载入训练集
train_dataset = MsDataset.load(dataset_id, namespace='damo', subset_name='default', split='train', keep_default_na=False)
dev_dataset = MsDataset.load(dataset_id, namespace='damo', subset_name='default', split='validation', keep_default_na=False)
train_dataset._hf_ds = concatenate_datasets([train_dataset._hf_ds, dev_dataset._hf_ds]) # 随版本更新该方法可能失效
# 载入公开测试集
eval_dataset = MsDataset.load(dataset_id, namespace='damo', subset_name='public', split='test', keep_default_na=False)
print("训练集:")
print(train_dataset._hf_ds)
print("公开测试集:")
print(eval_dataset._hf_ds)训练集:
Dataset({features: ['id', 'query', 'title', 'label'],num_rows: 200000
})
公开测试集:
Dataset({features: ['id', 'query', 'title', 'label'],num_rows: 5000
})基于MaSTS预训练模型-CLUE语义匹配,在载入的训练集上进行微调。
调整训练的超参数。根据GPU的显存调整BATCH_SIZE,推荐使用官方的超参数,即BATCH_SIZE=64。
import os.path as osp
from modelscope.trainers import build_trainer
from modelscope.utils.hub import read_configmodel_id = 'damo/nlp_masts_backbone_clue_chinese-large'WORK_DIR = './workspace'
BATCH_SIZE = 64 # 推荐使用官方的超参数cfg = read_config(model_id, revision='v1.0.0')
cfg.train.work_dir = WORK_DIR
cfg_file = osp.join(WORK_DIR, 'train_config.json')
cfg.train.max_epochs = 7
# train_dataloader的配置
cfg.train.dataloader.batch_size_per_gpu = BATCH_SIZE
cfg.train.optimizer.lr = 2.0e-5
# lr_scheduler的配置
cfg.train.lr_scheduler = {'type': 'LinearLR','start_factor': 1.0,'end_factor': 0.0,'total_iters':int(cfg.train.max_epochs * len(train_dataset) // BATCH_SIZE),'options': {'warmup': {'type': 'LinearWarmup','warmup_iters': int(cfg.train.max_epochs * len(train_dataset) * 0.9 // BATCH_SIZE)},'by_epoch': False}
}
cfg.dump(cfg_file)kwargs = dict(model=model_id,model_revision='v1.0.0',train_dataset=train_dataset,eval_dataset=eval_dataset,cfg_file=cfg_file,
)
trainer = build_trainer(default_args=kwargs)print('===============================================================')
print('pre-trained model loaded, training started:')
print('===============================================================')trainer.train()print('===============================================================')
print('train success.')
print('===============================================================')for i in range(cfg.train.max_epochs):eval_results = trainer.evaluate(f'{WORK_DIR}/epoch_{i+1}.pth')print(f'epoch {i} evaluation result:')print(eval_results)print('===============================================================')
print('evaluate success')
print('===============================================================')模型预测
使用多个模型集成,并提交最终的结果。这里以基于MaSTS,RoBERTa和StructBERT三个预训练底座训练得到的模型为例。首先载入这三个训练好的模型。
from modelscope.models import Model
from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
masts_model = Model.from_pretrained('damo/nlp_masts_sentence-similarity_clue_chinese-large', revision='v1.0.0')
roberta_model = Model.from_pretrained('damo/nlp_roberta_sentence-similarity_clue_chinese-large', revision='v1.0.0')
structbert_model = Model.from_pretrained('damo/nlp_structbert_sentence-similarity_clue_chinese-large', revision='v1.0.0')测试这三个模型在公开测试集上的效果。
基于MaSTS的模型在公开测试集上的效果要优于另外两个模型。
def tokenize_and_align_labels(examples):# tokenize the textstokenized_inputs = tokenizer(examples["query"],examples["title"],padding="max_length",truncation=True,max_length=512,)if "label" in examples:tokenized_inputs["labels"] = [int(l) for l in examples["label"]]return tokenized_inputstokenized_eval_dataset = eval_dataset._hf_ds.map(tokenize_and_align_labels,batched=True,remove_columns=eval_dataset._hf_ds.column_names,desc="Running tokenizer on datasets",
)import torch
from torch.utils.data.dataloader import DataLoader
from transformers import DataCollatorWithPadding
from sklearn import metrics@torch.no_grad()
def evaluate(model,tokenizer,eval_dataset,batch_size: int = 512,
):model = model.cuda().eval()data_collator = DataCollatorWithPadding(tokenizer=tokenizer)eval_dataloader = DataLoader(eval_dataset,batch_size=batch_size,shuffle=False,collate_fn=data_collator,pin_memory=True,num_workers=4,)predictions = []for batch in eval_dataloader:batch = {k: v.to(model.device) for k, v in batch.items()}outputs = model(input_ids=batch["input_ids"],attention_mask=batch["attention_mask"],token_type_ids=batch["token_type_ids"],)y_pred = outputs.logits.argmax(-1)predictions += y_pred.tolist()references = eval_dataset["labels"]accuracy = metrics.accuracy_score(references, predictions)f1 = metrics.f1_score(references, predictions, average="macro")return accuracy, f1accuracy, f1 = evaluate(masts_model, tokenizer, tokenized_eval_dataset)
print(f"MaSTS accuracy: {accuracy}, marco f1: {f1}")
accuracy, f1 = evaluate(roberta_model, tokenizer, tokenized_eval_dataset)
print(f"RoBERTa accuracy: {accuracy}, marco f1: {f1}")
accuracy, f1 = evaluate(structbert_model, tokenizer, tokenized_eval_dataset)
print(f"StructBERT accuracy: {accuracy}, marco f1: {f1}")MaSTS accuracy: 0.797, marco f1: 0.7408626647960889
RoBERTa accuracy: 0.785, marco f1: 0.7333059055826837
StructBERT accuracy: 0.7896, marco f1: 0.7358745897202524载入榜单测试集。
leaderboard_eval_dataset = MsDataset.load(dataset_id, namespace='damo', subset_name='default', split='test', keep_default_na=False)
tokenized_leaderboard_eval_dataset = leaderboard_eval_dataset._hf_ds.map(tokenize_and_align_labels,batched=True,remove_columns=leaderboard_eval_dataset._hf_ds.column_names,desc="Running tokenizer on datasets",
)
print("榜单测试集:")
print(leaderboard_eval_dataset._hf_ds)榜单测试集:
Dataset({features: ['id', 'query', 'title', 'label'],num_rows: 10000
})集成三个模型输出的logits,并产生最终的结果。
import torch
from torch.utils.data.dataloader import DataLoader
from transformers import DataCollatorWithPadding
from sklearn import metrics@torch.no_grad()
def inference(model,tokenizer,eval_dataset,batch_size: int = 512,
):model = model.cuda().eval()data_collator = DataCollatorWithPadding(tokenizer=tokenizer)eval_dataloader = DataLoader(eval_dataset,batch_size=batch_size,shuffle=False,collate_fn=data_collator,pin_memory=True,num_workers=4,)logits = []for batch in eval_dataloader:batch = {k: v.to(model.device) for k, v in batch.items()}outputs = model(input_ids=batch["input_ids"],attention_mask=batch["attention_mask"],token_type_ids=batch["token_type_ids"],)logits.append(outputs.logits.cpu())logits = torch.cat(logits)return logitsmasts_logits = inference(masts_model, tokenizer, tokenized_leaderboard_eval_dataset)
roberta_logits = inference(roberta_model, tokenizer, tokenized_leaderboard_eval_dataset)
structbert_logits = inference(structbert_model, tokenizer, tokenized_leaderboard_eval_dataset)import json# 集成三个模型的logits输出
ensemble_logits = torch.stack([masts_logits, roberta_logits, structbert_logits]).mean(0)
predictions = logits.argmax(-1).tolist()# 输出预测文件提交评测系统
with open("qbqtc_predict.json", "w") as f:for idx, p in enumerate(predictions):json.dump({"id": idx, "label": str(p)}, f)f.write("\n")集成这3个模型的榜单评测结果为 `marco f1: 75.464, accuracy: 80.940`。
marco f1: 75.464, accuracy: 80.940总结
本文介绍了阿里达摩院开源在魔搭社区上的CLUE语义匹配模型及其使用教程,通过简单的模型融合策略,可以获得不错的结果。从BERT的开源到T5,再到最近的ChatGPT,语言模型以极快的速度发展。达摩院NLP团队希望通过开源开放进一步推动NLP技术在国内的发展和应用,帮助开发者轻松上手前沿的模型算法,并构建自己的语言模型和AI应用。
参考文献
[1] Suchin Gururangan, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, Noah A. Smith. Don't Stop Pretraining: Adapt Language Models to Domains and Tasks. ACL 2020: 8342-8360
[2] Rodrigo Frassetto Nogueira, Wei Yang, Kyunghyun Cho, Jimmy Lin. Multi-Stage Document Ranking with BERT. CoRR abs/1910.14424 (2019)
[3] Junjie Wang, Yuxiang Zhang, Ping Yang, Ruyi Gan. Towards No.1 in CLUE Semantic Matching Challenge: Pre-trained Language Model Erlangshen with Propensity-Corrected Loss. CoRR abs/2208.02959 (2022)
![[chatgpt+Azure]unity AI二次元小女友之使用微软Azure服务实现RestfulApi->语音识别+语音合成](https://img-blog.csdnimg.cn/img_convert/cf59bffe4cdf304c6a0534b651431e46.png)