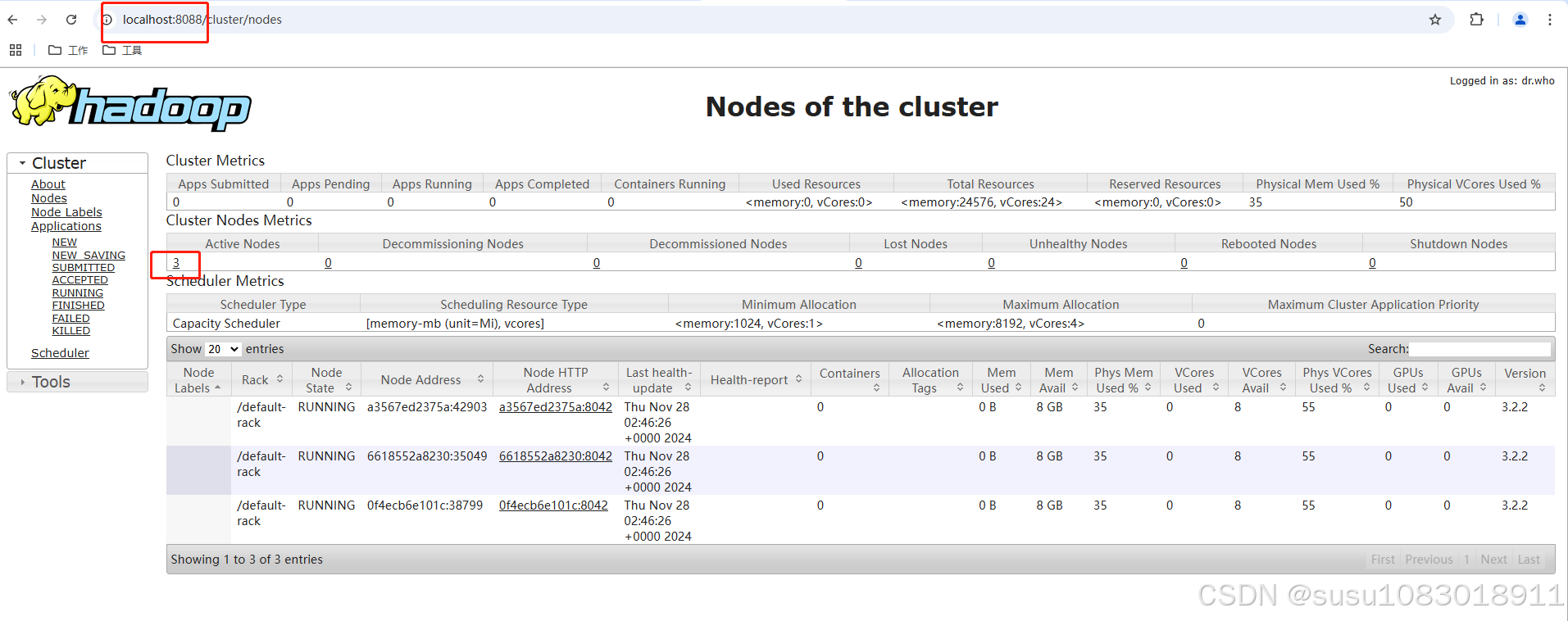
一、使用docker搭建基础镜像
1、拉取centos系统镜像
# 我这里使用centos7为例子
docker pull centos:7
2、创建一个dockerfiler文件,用来构建自定义一个有ssh功能的centos镜像
# 基础镜像
FROM centos:7
# 作者
#MAINTAINER hadoop
ADD Centos-7.repo /etc/yum.repos.d/CentOS-Base.repo
# 将工作目录切换到`/etc/yum.repos.d/`
RUN cd /etc/yum.repos.d/
# 使用sed命令注释掉mirrorlist行。
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
# 使用sed命令将baseurl修改为`http://vault.centos.org`。
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
# 更新yum缓存。
RUN yum makecache
# 使用yum更新系统软件。
RUN yum update -y
# 使用yum安装openssh-server和sudo。
RUN yum install -y openssh-server sudo
# 使用sed命令将UsePAM设置为no,禁用PAM认证。
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
# 使用yum安装openssh-clients。
RUN yum install -y openssh-clients
# 使用echo和chpasswd命令将root用户的密码设置为123456。
RUN echo "root:123456" | chpasswd
# 将root用户添加到sudoers文件中,允许其执行任何命令。
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
# 生成DSA类型的SSH密钥。
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
# 生成RSA类型的SSH密钥。
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 创建`/var/run/sshd`目录。
RUN mkdir /var/run/sshd
# 暴露容器的22端口,用于SSH连接。
EXPOSE 22
# 设置容器启动时默认运行的命令为`/usr/sbin/sshd -D`,即启动SSH服务。
CMD ["/usr/sbin/sshd", "-D"]
3、因为默认的centos镜像是没有任何功能的,根据上面的dockerfile文件,生成我们的centos-ssh镜像
# 生成centos7-ssh镜像
docker build -t="centos7-ssh" .# 生成之后,我们的docker中就有了这个镜像
docker images
4、将jdk、hadoop安装包和Dockerfile目录平级,我是windows系统

5、之前的Dockerfile备份为dockerfile_centos7-ssh,我们重新再创建一个Dockerfile文件,用来构建hadoop镜像
# 基础镜像为centos7-ssh
FROM centos7-ssh# 将当前目录下的jdk复制到镜像中
ADD jdk-8u11-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_11 /usr/local/jdk
# 设置java环境变量
ENV JAVA_HOME /usr/local/jdk
ENV JRE_HOME=${JAVA_HOME}/jre
ENV CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
ENV PATH=${JAVA_HOME}/bin:$PATH# 将hadoop目录复制到镜像中
ADD hadoop-3.2.2.tar.gz /usr/local/
RUN mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
# 设置hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH6、根据这个Dockerfile生成centos-hadoop镜像
docker build -t="centos7-hadoop" .
7、由于hadoop集群的机器需要网络通讯,我们单独给这些服务创建一个网桥
docker network create hadoop
8、启动容器并连接到刚刚创建的网桥
docker run -itd --network hadoop --name hadoop1 -p 50070:50070 -p 8088:8088 -p 9870:9870 centos7-hadoopdocker run -itd --network hadoop --name hadoop2 centos7-hadoopdocker run -itd --network hadoop --name hadoop3 centos7-hadoop# 查看网桥使用情况
docker network inspect hadoop# 记录每台服务器ip,后面可能会用
172.18.0.2 hadoop1
172.18.0.3 hadoop2
172.18.0.4 hadoop3
二、进入每台容器,配置ip地址映射和ssh免密登录
1、配置ip地址,配置完成后,容器之间互相ping一下,看看是否可以ping通
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash# 在每台hadoop服务器的终端输入:
vi /etc/hosts
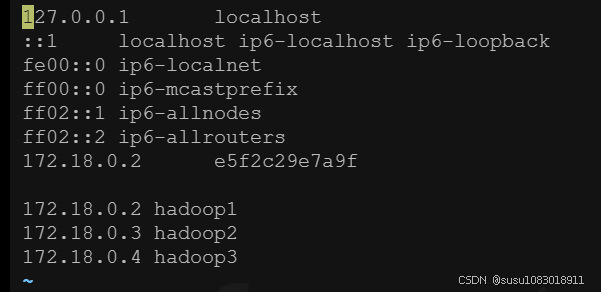
我本地发现,我修改完hosts文件后,我的环境变量配置失效了,重新又配置了一下
echo $PATHvi /etc/profileexport JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native# 保存文件并退出编辑器# 重新加载环境变量配置
source /etc/profile记得配置hadoop2和hadoop3,可以scp拷贝过去
2、配置免密登录
# 在每台hadoop服务器终端输入:
# 谁要去免密登录,谁就生成密钥对,使用ssh-keygen生成密钥对,密钥对包含id_rsa和id_rsa.pub,pub就是公钥,id_rsa是私钥,我们要把id_rsa发送到要免密登录的服务器上去
ssh-keygen# 然后一直回车即可,再在每台hadoop服务器终端中输入:
# 将公钥发送到需要免密登录的服务器上
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop1
# 填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop2
# 填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop3
# 填yes后,输入第二(3)步时设置的密码,123456# 测试是否成功配置ssh免密登录,ssh + hadoop服务器名:
ssh hadoop1
三、进入hadoop1中测试hadoop本地模式
1、修改配置文件
# 进入下面的目录
cd /usr/local/hadoop/etc/hadoop
# 修改hadoop-env.sh
vi ./hadoop-env.sh
# 显示行号
:set number
# 修改java目录为/usr/local/jdk
export JAVA_HOME=/usr/local/jdk
# 注意看下hadoop_home的路径是否正确2、新建一个测试数据集
# 在root目录下创建一个temp目录
mkdir /temp
# 创建测试数据集
vi /temp/data.txt
# 测试数据集内容
I Love Bejing
I Love LiuChang
I Love My Home
I Love you
I Love China
Do you miss me?
where are you doing?
this is hadoop hello world!# 进入share下面有一个测试的jar
cd /usr/local/hadoop/share/hadoop/mapreduce
# 这里面有很多mapreduce的测试jar包,这里我们测试一下wordcount,/root/temp表示测试数据集的目录,会读取下面所有的文件,/root/output/wc是输出目录
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /temp /output/wc# 执行之后,在/root/output/wc下就有生成的结果
more /output/wc/part-r-00000

四、hadoop全分布模式
以下配置在hadoop1上进行配置,配置完成后,直接把整个目录拷贝到hadoop2和hadoop3从节点
1、修改hadoop-env.sh
# 进入下面的目录
cd /usr/local/hadoop/etc/hadoop
# 修改hadoop-env.sh
vi ./hadoop-env.sh
# 显示行号
:set number
# 修改25行的java目录为/usr/local/jdk
export JAVA_HOME=/usr/local/jdk
2、修改hdfs-site.xml文件
<configuration>
<!-- 数据块的冗余度,默认是3 -->
<!-- 一般来说,数据块冗余度跟数据节点的个数一致,最大不超过3 -->
<property><name>dfs.replication</name><value>2</value>
</property><!-- 禁用了HDFS的权限检查 -->
<property><name>dfs.permissions</name><value>false</value>
</property>
</configuration>
3、配置core-site.xml文件
<configuration><!-- 配置NameNode地址 --><!-- 9000是RPC通信的端口 --><property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value></property><!-- HDFS对应的操作系统目录 --><!--默认是linux的/tmp,一定要进行修改,并且要创建该目录 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property></configuration>
4、配置mapred-site.xml文件
<configuration><!-- 配置MapReduce运行的框架是Yarn --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
5、配置yarn-site.xml文件
<configuration><!-- 配置ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value></property><!-- MapReduce运行的方式是:洗牌 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
注意如果是hadoop2.x版本配置slaves,Hadoop3.x版本中,集群配置的设置文件是workers
6、配置slaves文件
# 编辑从节点信息
vi ./etc/hadoop/slaves
# slaves内容
hadoop2
hadoop3
cd /usr/local/hadoop/etc/hadoop
即默认的情况下,Hadoop在本机启动,不加入分布式集群,因此无法随着集群的启动而启动。所以我们要把机器加入到集群环境中,在workers文件中,将hadoop1、hadoop2、hadoop3追加进去。
7、对NameNode进行格式化
hdfs namenode -format
8、hadoop1配置完成之后,把整个目录拷贝到hadoop2和hadoop3中
# 将hadoop1中的文件夹复制到hadoop2中
scp -r /usr/local/hadoop/ root@hadoop2:/usr/local# hadoop1中复制到hadoop3中
scp -r /usr/local/hadoop/ root@hadoop3:/usr/local
9、启动hadoop
## 启动hadoop
start-all.sh## 判断启动是否成功
# 在hadoop1上执行jps如果执行start-all.sh报错:
ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.

- 进入sbin目录,需要修改start-dfs.sh,stop-dfs.sh,start-yarn.sh,stop-yarn.sh四个文件
- 在start-dfs.sh,stop-dfs.sh两个文件顶部添加如下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 在start-yarn.sh,stop-yarn.sh顶部添加如下参数
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
在master节点上运行start-all.sh后,分别在hadoop2、hadoop3两台机器上进行进程检测。执行命令 jps

查看 Hadoop 的日志文件
cd $HADOOP_HOME/logsls -lt