点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【Transformer】微信交流群
转载自:新智元
【导读】「注意力公式」存在8年的bug首现,瞬间引爆舆论。爆料者称,基于Transformer架构打造的模型或将面临重大考验。
「注意力公式」中存在了8年的bug,竟被国外小哥发现了?
瞬间,这个话题就在网上炸开了锅。

现在基于Transformer打造的主流模型,GPT-4、Lalma 2、PaLM等都将受到影响。
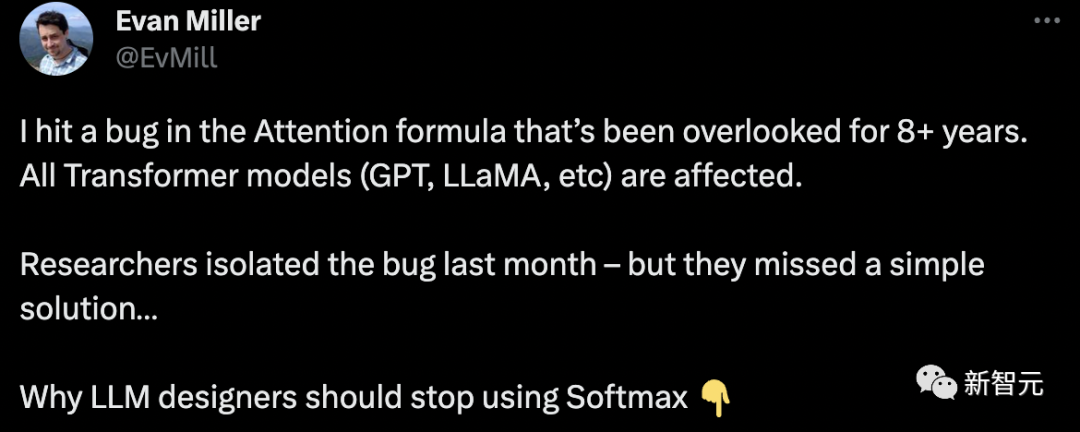
Eppo初创公司的工程师Evan Miller今天在博客中介绍了这一重大发现,并表示:
研究人员上个月分离了bug——但是他们误失了一个简单的解决方案,「为什么LLM设计人员应该停止使用Softmax?」
那么,究竟是什么bug,能够暗藏8年?
作者在博文中,引用了维特根斯坦别有蕴意的一句话,「对于无法言说之事,必须保持沉默」。

注意力是Off By One
这篇博文标题为「注意力是Off By One」。

你能看到这个公式的差一错误吗?
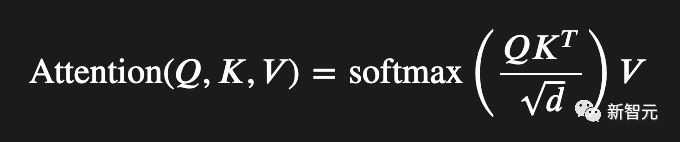
要知道,注意力公式是现代人工智能的核心等式,但其中有一个bug在上周让作者Evan Miller抓狂。
由此,Miller决定就这个漏洞和修复建议写篇博文。
文章中,他解释了当前一代AI模型是如何在一个关键的地方出现差一错误,这使得每个人的Transformer模型都难以压缩和部署。
不过,作者强调这只是一篇观点文章,但如果网上有人想做一些实验来证明这是对的,可以一起合作验证。
全与「离群值」有关
首先,先谈谈为什么差一错误很重要。ChatGPT工作得很好,有什么问题吗?
作者第一次发现了不对劲的地方,是在忙自己的事情和阅读量化研究论文时发现,这是一种通过LLM Edgers将大型模型压缩到Mac Minis、Rasberry Pis,以及破解家用恒温器的技术。
在AI领域,每个人都会受到RAM限制。
所以你使用的RAM越少,你就可以做的更多酷炫的事情,无论是在云端还是在边缘设备上。
LLM有数十亿的权重,如果我们可以让这些权重缩小,我们可以写出更好的十四行诗,或者剽窃更优秀的文章,又或者加速世界末日,这都取决于你使用语言的个人动机。
RAM存储信息,这听起来像是一种同义反复。信息是负对数概率,即我们需要多少位来存储事物。
如果一串数字流可预测,例如始终限制在一个有限的范围内,我们需要的比特数就会少一些。
如果一个数字流不可预测,比如偶尔出现一个超大数字,我们需要更多的二进制数字来编码这个庞然大物。
这就是在LLM中正在发生的事情(出于目前仅能部分理解的原因)。
Transformer模型包含这些离群权重(outlier weights),并且产生了相差一个数量级的巨大激活。
但是没有人能够消除它们。这些megalodons(研究命令行工具)看起来对这些模型的运行至关重要。
但是它们的存在与我们在构建优秀模型之前,所了解的关于神经网络的一切知识相矛盾。
已经有很多论文讨论这些离群值(outlier),人们已经想出了各种各样的位燃烧方案,以更少的1和0来进行编码。
因为现在,我们使用普通的比例和偏差整数量化得到的性能退化非常严重。
关于所有这些的最佳分析来自高通AI研究院的一篇论文:「Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing」。

论文地址:https://arxiv.org/pdf/2306.12929.pdf
作者们将这些离群值的存在,追溯到注意力机制的softmax函数。这个看似无辜的指数函数,没有人发现其能够产生如此严重的峰度异常。
而研究人员也就差点发现这个边界错误。
对此,作者表示,高通研究人员暂时还未回复自己电子邮件,但必须通过这种方式呼吁国际学者社区。如果你读了这篇链接的论文,就忽略他们的建议吧。
修剪后的softmax带有一个旋转式的零梯度,他们的门控注意力提议虽然可行,但是为了解决这只是一个增量的失败而引入了数百万个新的参数。
在作者看来,这里有一个简单而明显的解决方案,就自己阅读的所有内容中,还没有人想过去尝试。
接下来,一起谈谈softmax函数,以及为什么在处理注意力时,它并非最适合的工具。
Softmax出现的问题
为了解释这个错误,你真的需要理解注意力机制的目标。
这么做个类比吧,大多数数值错误都是程序员错误地实现方程。
然而,当你处理的不是错误的代码,而是错误的数学时,你需要理解这个等式来自哪里,以及你应该怎么做,才有可能修复它。
对此,作者不得不阅读了大约50篇arXiV论文来理解所有这些。
首先,从输入嵌入开始理解,这是一个浮点向量,它表示输入字符串中的一个单词。
这个向量似乎每年都在变高,比如,最近的LLaMA 2模型从Meta使用了一个长度为3,204嵌入向量。
半精度浮点数计算为6KB+,仅仅是为了表示词汇表中的一个单词,而词汇表通常包含30,000——50,000个条目。
现在,如果你是节省内存的C程序员,你可能会想,为什么这些AI goober要使用6KB,来表示应该只需要2字节就能搞定的事情?
如果他们的词汇表小于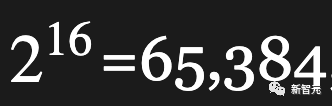 ,我们只需要16位就能表示一个条目,对吧?
,我们只需要16位就能表示一个条目,对吧?
这正是Transformer实际在做的事情:它将输入向量转换为相同大小的输出向量,这个最终的6KB输出向量需要编码绝对一切,以预测当前词语之后的词语。
每一层Transformer的工作就是,实实在在地向原始的单词向量添加信息。
这就是残差(née skip)连接的作用:所有的注意力机制只是向原始的两个字节信息添加补充材料,分析更大的上下文以指示。
例如,单词「pupil」指的是学生,而不是你的瞳孔。重复几十次注意力机制,你就掌握了英语和所有丰富的内容。
现在,Transformer 的最后一步是将这个输出向量与一个矩形矩阵相乘,并将结果的词汇长度向量塞入softmax,将那些指数输出视为下一个词的概率。
这是合理的,但每个人都知道它并非是完全正确的。
因为没有模型将那些输出概率视为正确,与之相反,每个实现和其他模型都使用采样机制来掩盖softmax过度表示低概率的事实。
这一切都很好,也可行。
在输出步骤中的softmax为词汇表中的每个词提供了梯度,这是一个合理的选择,直到有更好的词出现。
但作者想要辩论的是,Transformer的输出softmax与注意力机制的内部softmax有着不同的目的,我们都应该去除后者,或者至少用一些方便的东西支撑起它的分母。
那么什么是softmax?
softmax最初起源于统计力学中,用于基于能级预测状态分布:
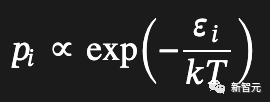
然后经济学家意识到,如果人们的线性效用函数中的噪声项恰好遵循Gumbel分布,那么某人选择某个项目的概率将与效用输入的指数成比例:
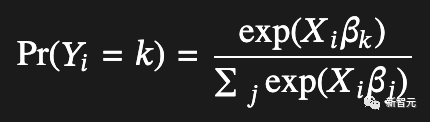
而这也使得softmax在多项式逻辑函数中有了用武之地。
可以说,softmax是一种将实数映射为总和为1的概率的「作弊代码」。
在物理学中,它效果很好;在经济学中,它有点虚假,但是一旦它进入机器学习领域,每当涉及到离散选择时,它似乎就成为一种行之有效的东西。
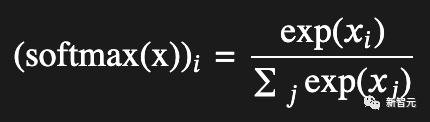
这就是softmax的核心机制:它强制在竞争的替代方案中进行选择,无论是粒子选择能级状态,还是消费者选择汽车。
也就是说,如果softmax机制根本不想做出任何选择,softmax将需要进行修改,否则我们预期softmax在遇到实际数据时会产生扭曲。
就LLM而言,其中一个扭曲是对非语义token(逗号等)进行重点加权,而那些权重也就变成了难以压缩的异常值。
对此,高通AI研究人员发现,LLM中97%以上的异常激活发生在空白和标点位置。
哪里会出错?
接下来,让我们深入研究softmax在注意力中的使用,并看看它在哪里出错了:
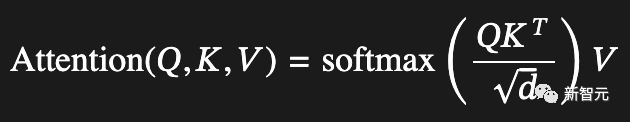
分解一下:在仅解码器模型中(即ChatGPT之后的所有模型),、和都来自同一输入序列。
虽然它们并不相同,因为它们在途中被以不同的方式投影,但在每一层中,它们都始于相同的已注释(已添加到)嵌入向量。
现在:^正在寻找不同位置的token(嵌入)向量之间的相关性,实际上正在构建一个相关性(点积按1/√缩放)值的方阵,其中每列和行对应一个token位置。
然后,这个方阵的每一行都经过softmax处理,得到的概率用作矩阵中的值向量的混合函数。概率混合后的矩阵被加到输入向量中,并将其传递到神经网络中进行进一步处理。
多头注意力在每个层中同时经过这个过程,进行多次处理。它基本上将嵌入向量划分成多个部分,每个头使用整个向量中的信息来注释输出向量的一个(不重叠的)段。
如果你对原始Transformer论文中的Concatenation操作感到困惑,那就是在发生的事情:头1向段1添加信息,头2向段2添加信息,依此类推。
使用softmax的问题在于,它迫使每个注意力头都要进行注释,即使它没有任何信息可以添加到输出向量中。
在离散选择之间使用softmax是很好的;但作为可选注释(即输入到加法中)使用它,就有点不太好。其中,多头注意力则会加剧这个问题,因为专门的头比通用的头更有可能想要「通过」。
现在,可能应该全面替换softmax,但它在大部分情况下效果还不错,除了一个小问题,它阻止了注意力头发出空白注释。
因此,我提出了一个非常小的调整,我愿意将所有未来的互联网声明都寄托在这个正确性上。
这个调整是如此小,又是如此明显,自从注意力被发明(2014年)以来一直在大家的眼皮底下。
Softmax1和Quiet Attention
现在,经过改造的Softmax Super-Mod公式来了!
不过,实际上只是在分母上加了一个「1」。
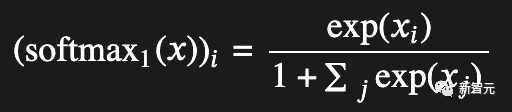
作者表示,如果愿意的话,这可以让整个向量趋向于零,但除此之外,就只是将数值缩小了一些,而这将会在归一化过程中得到补偿。其中,归一化过程会在注意力之后进行。
关键的区别在于负极限,当中的条目明显小于零且模型试图完全避免一个注释时。
比较原始softmax的极限行为:

与新的改进softmax1的极限行为:

可以看到,原始的softmax总是会产生相同的总权重;softmax1虽然看起来大部分相同,但在负半轴中有一个逃生通道。
此外,softmax1还有其他一些特点。比如,它的导数是正数,因此我们始终有非零梯度;它的和在0和1之间,因此输出不会失控。
同时,softmax1还会保持如下函数性质,即输出向量中的相对值保持不变。
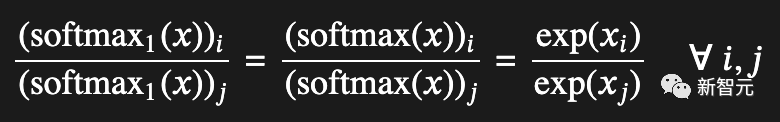
而原始的softmax即便采用更高的精度,也无法解决这些问题。也就是说,所有的Transformers都受到影响。
尽管softmax1表面上看起来相当普通,但作者有99.44%的把握,它可以解决量化的离群反馈循环问题。
对于改进后的机制,作者称之为——QuietAttention,因为它允许注意力头保持安静:
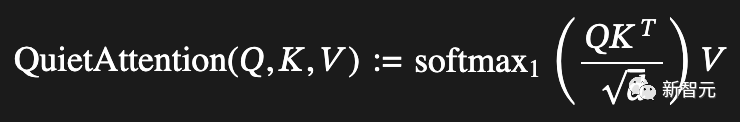
基于此,作者认为可以很快地编写一个测试:
「如果在每个输入上下文前加上一个零向量,并确保选择的神经网络种不会增加任何偏差(包括位置编码),那么零向量应该会原封不动地通过,并且在每个后续的softmax分母中都添加一个单位。这样,也就不必纠结于梯度代码了。」
此外,作者还认为可以使用一个使用固定嵌入和特殊前缀token的LLaMA模型来完成这项工作。
不过,由于仍然需要重新训练模型,所以暂时不要在Raspberry Pi上进行尝试。
顺便,如果你真的进行测试了的话,记得把结果发给这位作者——他想在即将发表的arXiV论文中制作一张漂亮的表格。
作者介绍
本文作者Evan Miller其实说起来并不是那么有名。
他的履历和出身和一些科学大牛相比,确实是比不过。但并不影响他能做出本文所讲的重大发现。

Miller本科、硕士和博士三个阶段其实都没有主修计算机科学。
本科阶段,他在威廉姆斯学院学的是物理。后来又在芝加哥大学攻读了经济学的博士。

而除了学业生涯,Miller写过很有名的排名算法,目前在很多网站上都有应用。
他设计的统计软件还曾被顶级医学期刊引用。
目前,Miller在一家名为 Eppo 的初创公司担任统计工程师。

而Miller在他自己的网站上所展示的内容,可以看出这哥们快是个全才了。
开源项目,做过7个。

各个专业的博客、文章、论文啥的,多的数不过来。
有编程类的,应用数学类的,甚至还有生意经。

参考资料:
https://news.ycombinator.com/item?id=36851494
https://twitter.com/EvMill/status/1683508861762695168
https://www.evanmiller.org/attention-is-off-by-one.html
点击进入—>【Transformer】微信交流群
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()