🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
🌈历史文章🌈:
SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
- DiT(Diffusion Transformer)详解
- Stable Diffusion 3详解
微调方法原理:
- DreamBooth
- LoRA
- LORA及其变种介绍
- ControlNet
- ControlNet文章解读
- Textual Inversion 和 Embedding fine-tuning

目录
核心基础内容
Stable Diffusion 3整体架构初识
VAE模型
Latent特征Patch化
提高通道数
MM-DiT(Multimodal Diffusion Backbone)模型
中期融合
两套独立的权重参数
Text Encoder模型(包含详细图解)
新增T5-XXL Encoder
一、提取输入文本的全局语义特征“y”(上图中“1”)
二、提取输入文本的细粒度特征“c”(上图中“2”)
Dropout
改进的RF(Rectified Flow)采样方法
训练技巧&细节解析
训练数据预处理
图像Caption标签精细化
图像特征和文本特征在训练前缓存
使用Classifier-Free Guidance技术
使用DPO(Direct Preference Optimization, 人类偏好)技术微调
使用QK-Normalization
设计多尺度位置编码(插值+扩展)
TimeStep Schedule中shift参数作用
基于DiT架构AI绘画大模型的Scaling能力
SD 3.5
推荐阅读:文生图中从扩散模型到流匹配的演变:从SDXL到Stable Diffusion3(含Flow Matching和Rectified Flow的详解)
摘录于:https://zhuanlan.zhihu.com/p/684068402
核心基础内容
Stable Diffusion 3比起Stable Diffusion之前的系列,在多主题提示词的控制编辑一致性能力(multi-subject prompts)、文字渲染控制能力(spelling abilities)以及图像生成的整体质量(image quality)三个维度都有大幅的提升。
论文:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Stable Diffusion 3整体架构初识
Stable Diffusion 3依旧是一个End-to-End模型,最大的亮点是扩散模型部分使用了全新的MM-DiT(Multimodal Diffusion Transformer)架构,这与OpenAI发布的文生视频大模型Sora一致(Transformer is all you need!)。
同时采用优化改进的Flow Matching(FM)技术【RF采样方法】训练SD 3模型,Flow Matching技术由Meta于2022年提出(https://arxiv.org/pdf/2210.02747),可以让扩散模型的训练过程更高效稳定,而且还可以支持更快的采样生成,同时生成质量进一步提高。
为了让用户能够在不同应用场景和硬件环境使用SD 3模型,SD 3一共发布了参数从8亿到80亿(800M-8B)的多个版本,也再次证明了Transformer架构的强大scaling能力。
SD 3 medium版本在FP16精度下组成结构:
- MM-DiT大小为4.17G
- VAE模型大小为168M
- CLIP模型
- CLIP ViT-L大小为246M(参数量约124M)
- OpenCLIP ViT-bigG大小为1.39G(参数量约695M)
- T5-XXL Encoder在FP6精度下大小为9.79G(参数量约4.7B,FP8精度下大小为4.89G)
Stable Diffusion 3的整体网络结构图如下所示:

红框中的详细MM-DiT网络结构图如下:

VAE模型
VAE(变分自编码器,Variational Auto-Encoder)模型在Stable Diffusion 3(SD 3)中依旧是不可或缺的组成部分,VAE在AI绘画领域的主要作用,不再是生成能力【传统时代VAE用于生成】,而是辅助SD 3等AI绘画大模型的压缩和重建能力。
Latent特征Patch化
在SD 3中,VAE模型作用和之前的系列一样,依旧是将像素级图像编码成Latent特征,不过由于SD 3的扩散模型部分全部由Transformer架构【MM-DiT】组成,所以还需要将Latent特征转换成Patches特征加入位置编码后,再送入扩散模型部分进行处理。

【Transformer架构处理图像(ViT,DiT)时的必要手段,Patch化后(2x2的patch,latten 2 × 2 patches),加上位置编码。可以参考DiT的过程:DiT(Diffusion Transformer)详解——AIGC时代的新宠儿-CSDN博客】
提高通道数
之前SD系列中使用的VAE模型是将一个H×W×3的图像编码为H/8×W/8×d的Latent特征,在8倍下采样的同时设置d=4(通道数),这种情况存在一定的压缩损失,产生的直接影响是对Latent特征重建时容易产生小物体畸变(比如人眼崩溃、文字畸变等)。
SD 3模型通过提升d来增强VAE的重建能力,提高重建后的图像质量。论文中的实验,当设置d=16时,VAE模型的整体性能(FID指标降低、Perceptual Similarity指标降低、SSIM指标提升、PSNR指标提升)比d=4时有较大的提升,所以SD 3确定使用了 d=16 (16通道)的VAE模型。
【补充】
之前SD系列下采样倍都是8倍,但是
- SD1.5 默认配置d=4
- SDXL 默认配置d=8
与此同时,随着VAE的通道数增加到16,扩散模型部分(U-Net或者DiT)的通道数也需要跟着修改(修改扩散模型与VAE Encoder衔接的第一层和与VAE Decoder衔接的最后一层的通道数),虽然不会对整体参数量带来大的影响,但是会增加任务整体的训练难度。因为当通道数从4增加到16,SD 3要学习拟合的内容也增加了4倍,我们需要增加整体参数量级来提升模型容量(model capacity)。
当模型参数量小时,16通道VAE的重建效果并没有比4通道VAE的要更好,当模型参数量逐步增加后,16通道VAE的重建性能优势开始展现出来,当模型的深度(depth)增加到22时,16通道的VAE的性能明显优于4通道的VAE。
VAE完整结构图如下:
【结构上与SD和SDXL并未有差别,更详细信息参考:Stable Diffusion核心网络结构——VAE_stable diffusion网络架构-CSDN博客】
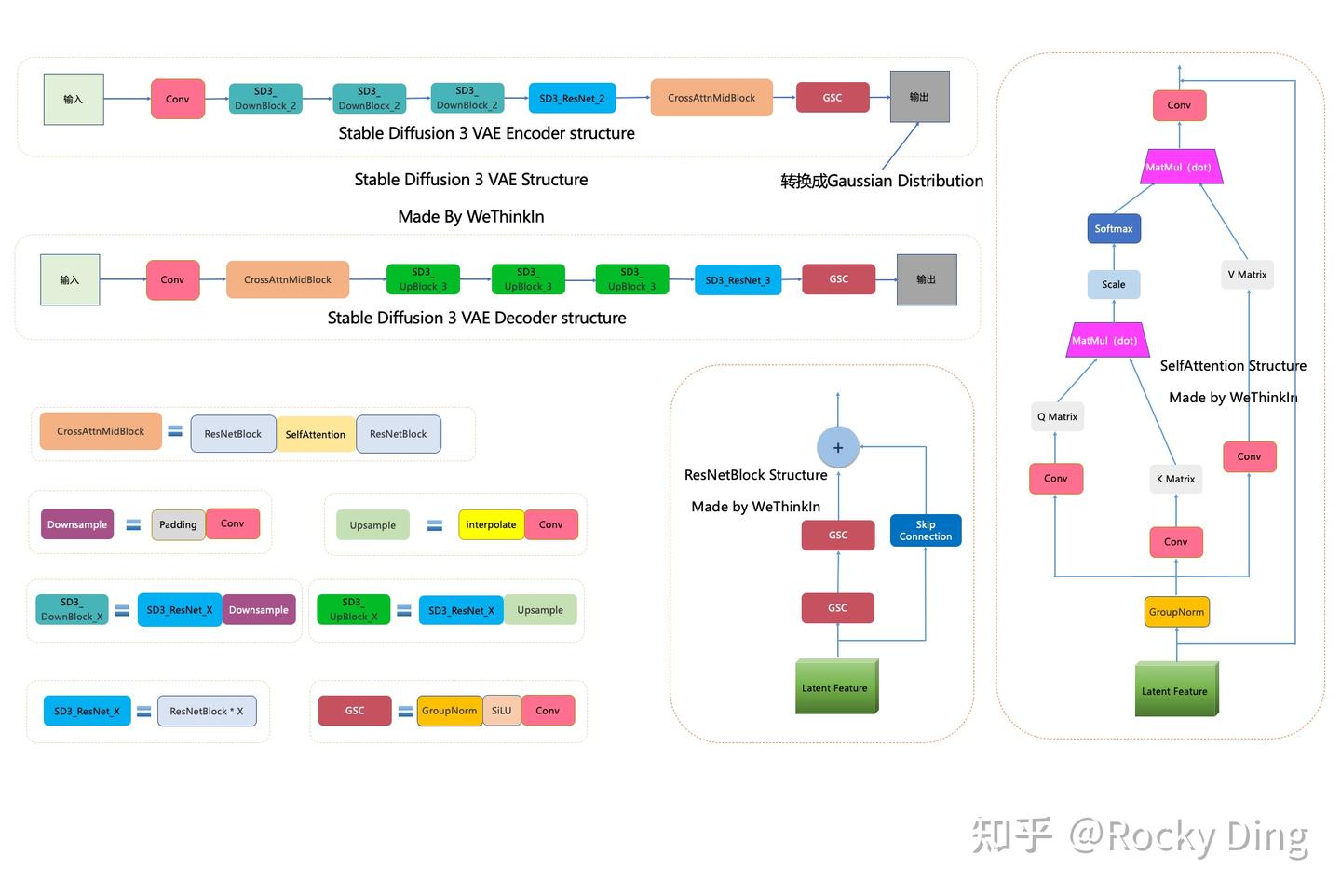
可以看到,SD 3 VAE模型中有三个基础组件:
- GSC组件:GroupNorm+SiLU+Conv
- Downsample组件:Padding+Conv
- Upsample组件:Interpolate+Conv
同时SD 3 VAE模型还有两个核心组件:ResNetBlock模块和SelfAttention模块,两个模块的结构都已在上图中展示。
SD 3 VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
而VAE Decoder部分正好相反,其输入Latent特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
在2048x2048高分辨率上,SDXL VAE出现了较明显的内容和文字的信息损失。与此同时,SD 3 VAE能够较好的对高分辨率图像进行压缩与重建。
MM-DiT(Multimodal Diffusion Backbone)模型
在SD之前的系列中,对于文本的Text Embeddings与图像信息是在U-Net中使用Cross-Attention机制来结合,其中Text Embeddings作为Attention中的keys和values,图像信息作为Attention的Query。
中期融合
SD 3一改之前的范式,在架构上最重要的改进就是设计了以多模态DiT(MM-DiT)作为核心扩散模型。直接将Text Embeddings和图像的patch Embeddings拼接(Concat)在一起进行处理,将文本特征的重要性和图像特征对齐,这样就不需要再引入Cross-Attention机制。
【这里“直接将Text Embeddings和图像的patch Embeddings拼接(Concat)在一起进行处理”,意思是早期融合,其实描述并不准确。从MM-DiT的架构中可以看出,文本和图像进行融合是在计算Q、K、V时候,属于中期融合。】
- 早期融合是指在模型的输入阶段或特征提取的初期(如输入或嵌入层),将不同模态的数据直接合并,统一表示,然后通过一个共享的网络进行处理,如ViLT、Single-DiT(FLUX中用到)。
- 中期融合是指模态数据在初期被分别编码为独立的特征后,在模型的中间层通过跨模态交互模块(如注意力机制)进行融合,如MM-DiT(使用Self-Attention机制来实现特征的交互融合),BLIP(通常通过跨模态/交叉注意力机制实现)。
- 后期融合是指模态数据由独立的网络完全编码为独立的特征,最后在输出阶段或决策层进行融合,如CLIP。
使用跨模态注意力机制通常是 中期融合 的特征,但如果跨模态注意力用于输入阶段或决策阶段,则可能属于早期融合或后期融合。
两套独立的权重参数
SD 3中MM-DiT架构的一个核心关键是对图像的Latent Tokens和文本的Tokens设置了两套独立的权重参数,并在Attention机制前拼接在一起,再送入Attention机制进行注意力的计算【中期融合】。MM-DiT架构图如下所示:

由于图像和文本属于两个不同的模态,所以SD 3中采用两套独立的权重参数来处理学习这两个不同模态的特征,两种模态特征在所有Transformer层的权重参数并不是共享的,只通过Self-Attention机制来实现特征的交互融合。这相当于使用了两个独立的Transformer模型来处理文本和图像信息,这也是SD 3技术报告中称这个结构为MM-DiT的本质原因,这是一个多模态扩散模型。
Stable Diffusion 3 MM-DiT的完整结构图如下:
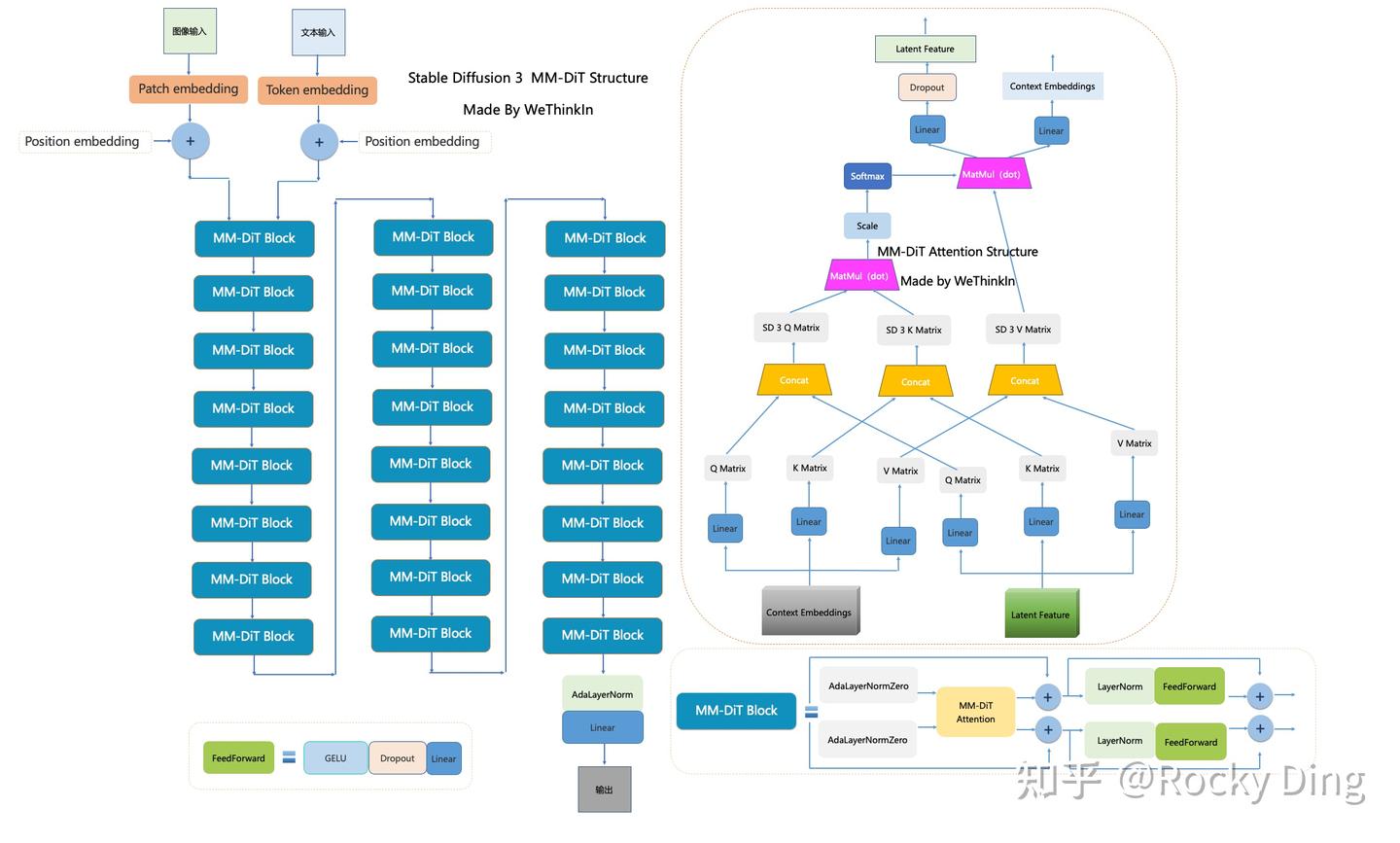
SD 3论文中还将3套不同参数的MM-DiT(CLIP text tokens、T5-XXL text tokens和Patches分别各一套参数)与CrossDiT(引入Cross-Attention机制的DiT架构)、UViT(U-Net和Transformer混合架构)基于CC12M数据集训练后进行性能对比,验证MM-DiT架构的有效性,
看到MM-DiT在性能上是明显优于其它架构的, MM-DiT的模型参数规模主要是模型的深度d,即Transformer Block的数量【一个完整的 MSA + MLP 模块】决定的。
Text Encoder模型(包含详细图解)
【在介绍Text Encoder前,我们需要先明确一下MM-DiT模型的输入,即MM-DiT的结构图中的“y”、“c”和“x”,其中“y”和“c”来自CLIP等Text Encoder模型,“x”则来自VAE模型得到的补丁(Patching)并且位置编码(Positional Embedding)后的 Latent特征】
"x":MM-DiT和原生DiT模型一样在Latent空间中将图像的Latent特征转成patches特征,这里的patch size=2x2【最优】,和原生DiT的默认配置一致。接着和ViT一样,将得到的Patch Embedding再加上Positional Embedding一起输入到Transformer架构中【就是前面VAE中流程】。
【下面讲如何通过Text Encoder得到“y”和“c”】
Stable Diffusion 3的文字渲染能力很强,同时遵循文本Prompts的图像生成效果也非常好,这些能力主要得益于SD 3采用了三个Text Encoder模型,它们分别是:
- CLIP ViT-L(参数量约124M)
- OpenCLIP ViT-bigG(参数量约695M)
- T5-XXL Encoder(参数量约4.762B)
在Stable Diffusion系列的整个版本迭代中,Text Encoder部分一直在优化增强。
- SD 1.x系列模型的Text Encoder部分使用了CLIP ViT-L。
- SD 2.x系列模型中换成了OpenCLIP ViT-H。
- SDXL的Base模型使用CLIP ViT-L + OpenCLIP ViT-bigG的组合作为Text Encoder,Refiner模型只使用了OpenCLIP ViT-bigG的Text Encoder。
- SD 3则更进一步,继续增加Text Encoder的数量,加入了一个参数量更大的T5-XXL Encoder模型。
T5-XXL Encoder证明了预训练好的纯文本模型能够在AI绘画实现更好的文本理解能力。
- 2022年谷歌发布Imagen时,就使用了T5-XXL Encoder作为Imagen模型的Text Encoder
- OpenAI发布的DALL-E 3也采用了T5-XXL Encoder来提取文本prompt信息
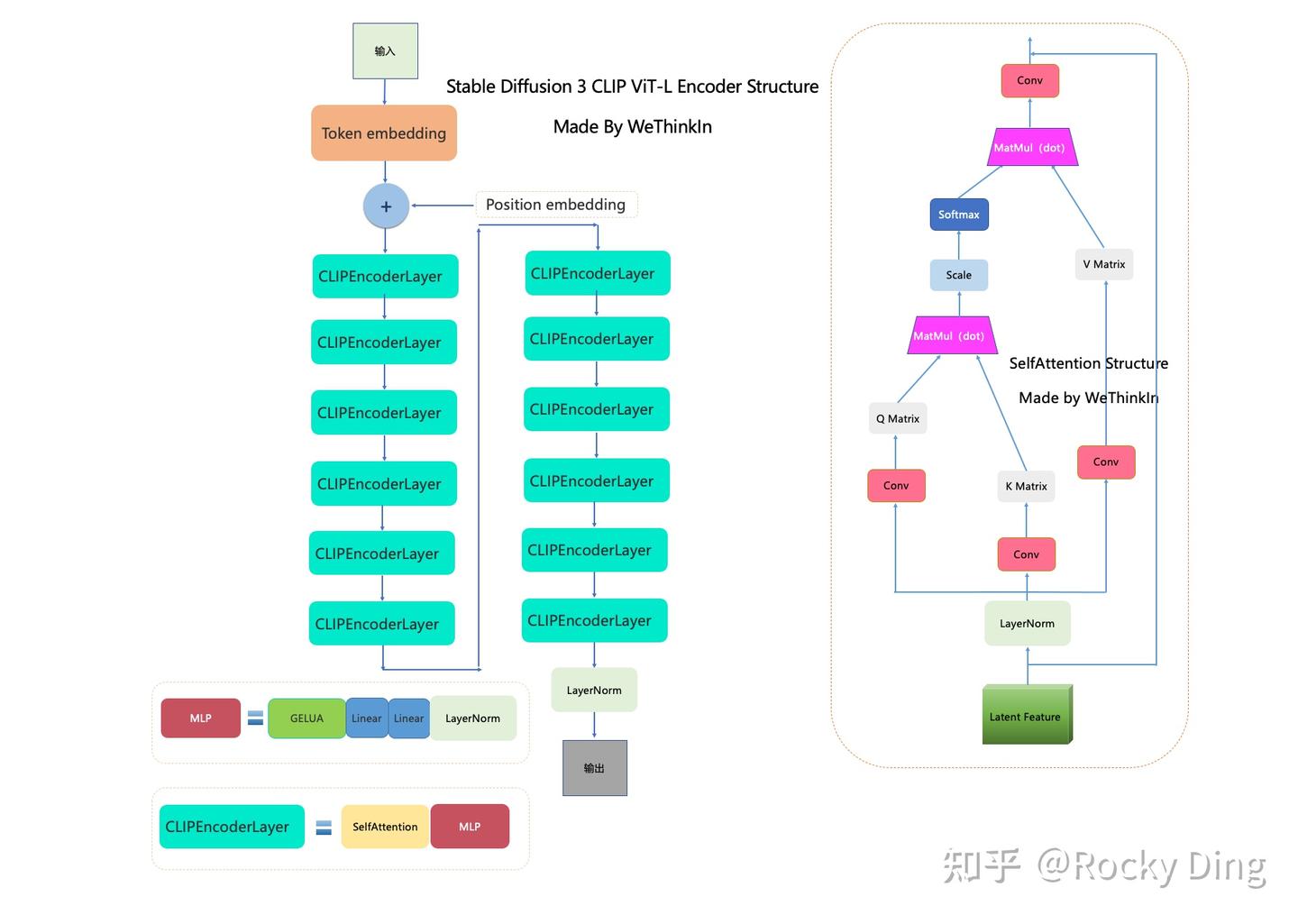
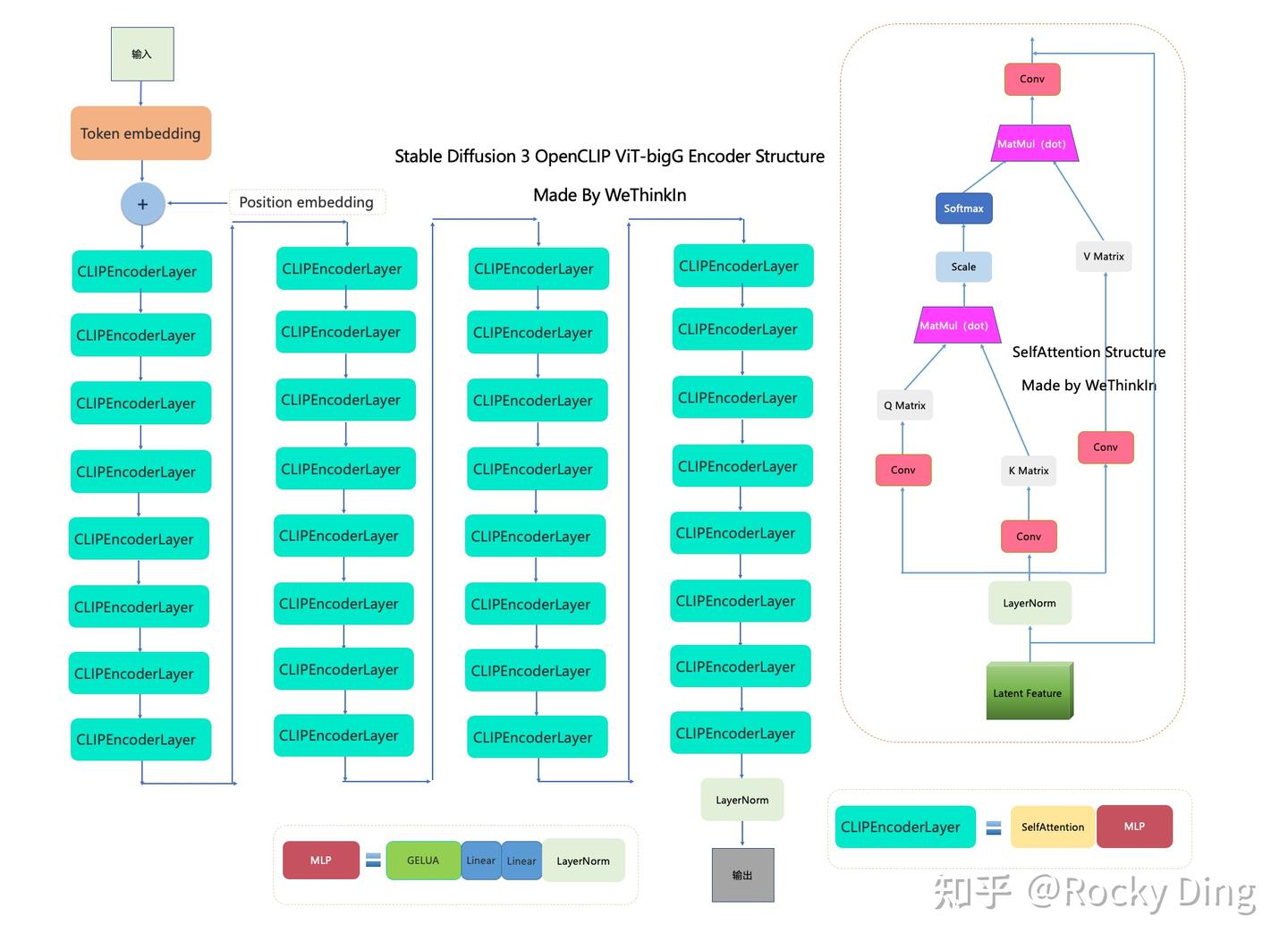
CLIP ViT-L和OpenCLIP ViT-bigG的架构图如下:
【和SD前面系列一样,没变化】
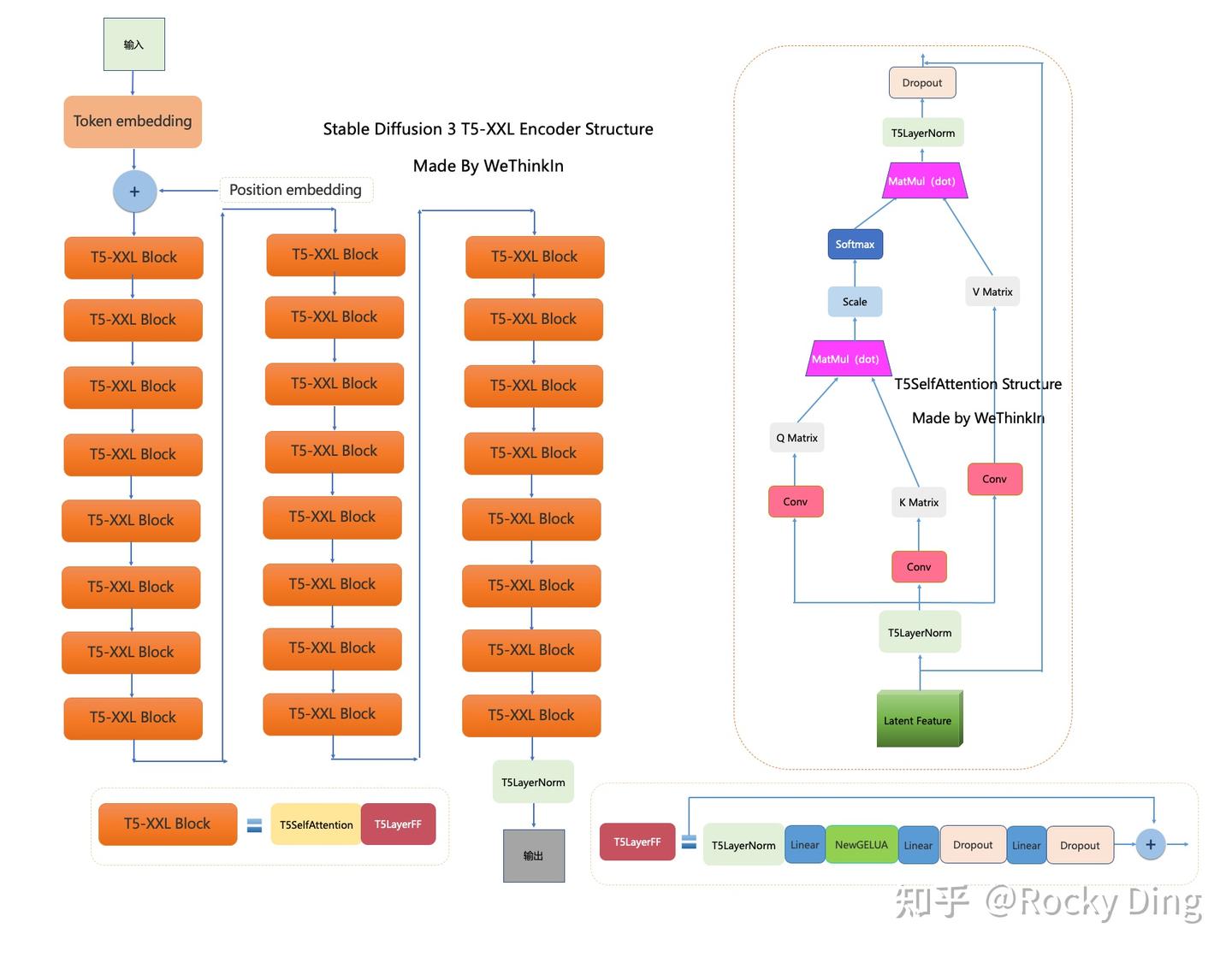
新增T5-XXL Encoder
Stable Diffusion 3 T5-XXL Encoder的完整结构图如下:
总的来说,SD 3一共需要提取输入文本的全局语义和文本细粒度两个层面的信息特征。如下图:

一、提取输入文本的全局语义特征“y”(上图中“1”)
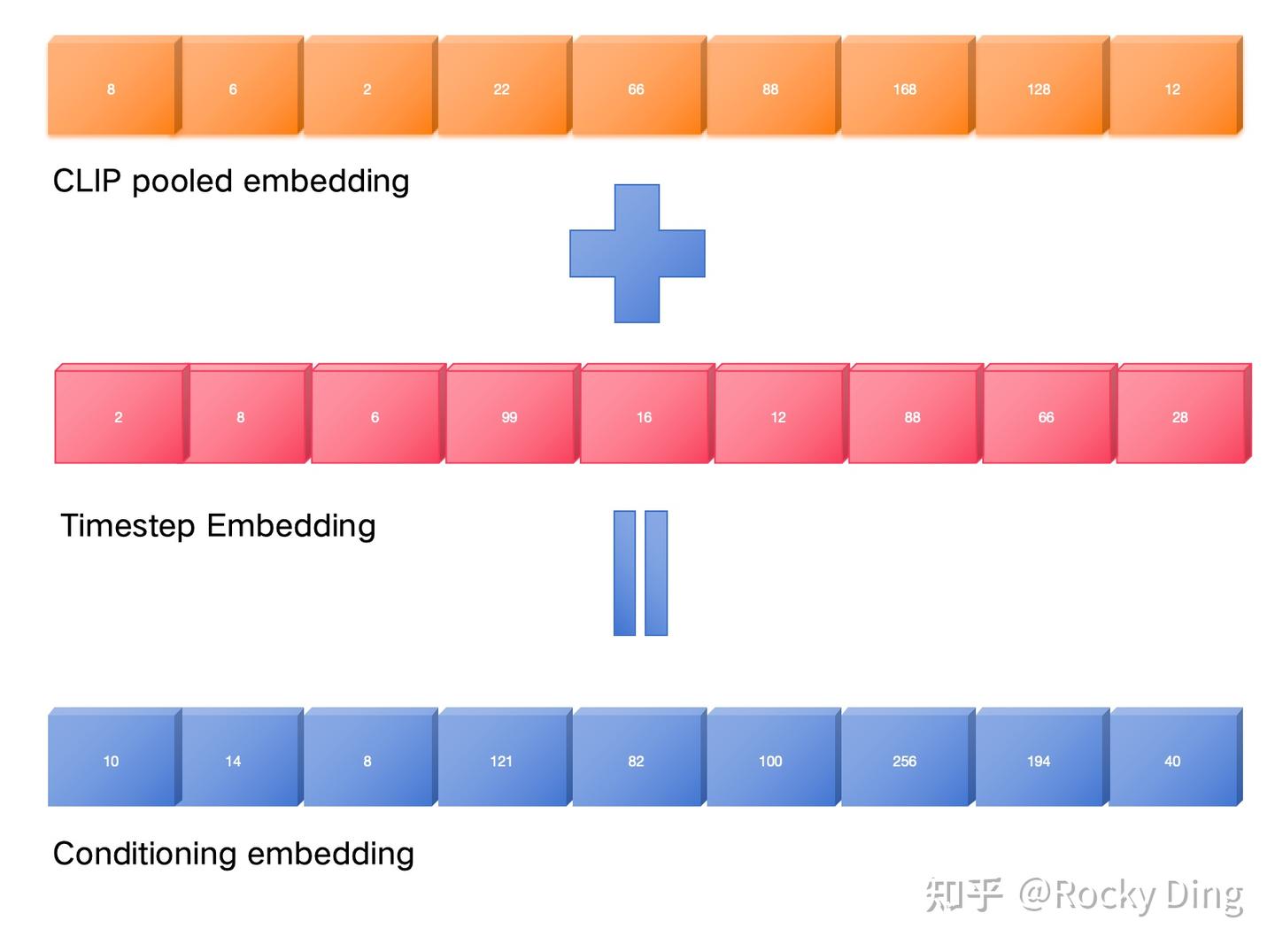
CLIP ViT-L和OpenCLIP ViT-bigG的Pooled Embeddings【全局特征向量】维度大小分别是768和1280,两个embedding拼接在一起得到2048的embedding,然后经过一个MLP网络之后和Timestep Embeddings相加(add操作)。
完成文本的全局语义信息(CLIP pooled embedding)与时间步信息(Timestep embedding)特征提取后,再通过add操作将两个特征进行融合相加【得到MM-DiT的结构图中的“y”】,就获得了要注入每一个Transformer Block的adaLN-Zero层的Conditioning特征。下图是详细清楚的图示,让大家能够直观的了解感受:
二、提取输入文本的细粒度特征“c”(上图中“2”)
- 这里首先分别提取CLIP ViT-L和OpenCLIP ViT-bigG的倒数第二层的特征,拼接在一起可以得到77x2048维度的CLIP Text Embeddings;
- 接着再从T5-XXL Encoder中提取最后一层的特征T5 Text Embeddings,维度大小是77x4096(这里也限制token长度为77)。
- 然后对CLIP Text Embeddings使用zero-padding【图中灰色】得到和T5 Text Embeddings相同维度的特征。
- 最后,将padding后的CLIP Text Embeddings和T5 Text Embeddings在token维度上拼接在一起,得到154x4096维度的混合Text Embeddings。
- 这个混合Text Embeddings将通过一个linear层映射到与图像Latent的Patch Embeddings相同的维度大小,并和Patch Embeddings拼接在一起送入MM-DiT中。
CLIP ViT-L和OpenCLIP ViT-bigG都只能默认编码77 tokens长度的文本,这让原本能够编码512 tokens的T5-XXL Encoder在SD 3中也只能处理77 tokens长度的文本,限制了T5-XXL Encoder的能力。
SD系列的“友商”模型DALL-E 3由于只使用了T5-XXL Encoder一个语言模型作为Text Encoder模块,所以可以输入512 tokens的文本,从而发挥T5-XXL Encoder的全部能力。
Dropout
在SD 3的训练过程中,由于三个Text Encoder都是已经预训练好的语言模型,它们的参数被冻结。同时三个Text Encoder的特征单独以46.4%的概率进行drop,然后送入MM-DiT进行训练。按照这样的思路,其实在SD 3推理时也是可以任意组合这三个Text Encoder的。【下文CFG有详细描述】
由于T5 XXL的参数量是最大的,可以只使用CLIP ViT-L + OpenCLIP ViT-bigG的特征,此时需要将T5-XXL的特征设置为zero。
在这种配置下,SD 3论文中发现去掉T5-XXL后,图像生成的整体质量不会下降(有50%的胜率),但是文字渲染能力大幅下滑(仅有38%的胜率),同时文本理解能力有一定的下滑(只有46%的胜率)。
整体上看,T5-XXL Encoder对于SD 3还是非常关键的,因为就算是最大的8B模型,缺少了T5-XXL Encoder后,SD 3引以为傲的文字渲染与文字理解能力都大打折扣,与其他AI绘画主流大模型的效果对比很差。
改进的RF(Rectified Flow,直方流)采样方法
SD 3不再使用DDPM作为扩散模型,而是该用优化的RF(Rectified Flow)做为扩散模型。
【RF(直方流Rectified Flow)是一种革命性的采样方法,彻底改变了传统扩散模型的生成过程。通过直接优化从数据分布到目标分布的映射,RF 提高了生成速度和质量,是 Stable Diffusion 3 生成过程的核心创新之一。】
Rectified Flow技术的核心思想是通过引入流变换方法,前向加噪过程被定义为一个Rectified Flow,以一条直线连接数据分布和噪声分布,简化模型的训练和推理过程,提升生成效率,具有比DDPM更好的理论属性和概念简洁性。具体来说,Rectified Flow采用了分段线性变换(Piecewise Linear Transformations)【不一定是分段线性,也可能是直线】,并结合梯度流修正(Gradient Flow Rectification),使得流的训练过程更加高效。
在SD 3的论文中,先介绍的Flow Matching(FM)框架和RF(Rectified Flow),在介绍SD 3基于 RF(Rectified Flow)做的改进的。下面也按照这个顺序,先介绍FM,再介绍RF的改进:
【由于篇幅过长,单独发文展示】
SD3的采样上篇——Flow Matching-CSDN博客
SD3的采样下篇——Rectified Flow-CSDN博客
训练技巧&细节解析
训练数据预处理
在SD 3的技术报告中并没有公布预训练数据集的来源分布,不过技术报告中的很多数据预处理技术:
- NSFW风险内容过滤:使用NSFW检测模型来过滤这些风险数据。
- 筛除美学分数较低的数据:使用美学评分系统预测图像的美学分数,并移除分数较低的数据。
- 数据去重:使用基于聚类的去重方法来移除训练数据集中重复的图像,防止模型对于某些重复图像中的特征过拟合。
在上述的数据预处理完成后,官方筛选出了1B+的数据供SD 3训练优化。SD 3首先在1B数据上进行了预训练,然后再用30M专注于特定视觉内容和风格的高质量美学数据进行微调,最后使用3M偏好数据进行精细化训练。
图像Caption标签精细化
SD 3使用多模态大模型CogVLM来对训练数据集中的图像生成高质量的Caption标签。 这借鉴了DALL-E 3的数据标注方法(已经成为AI绘画领域的主流标注方法)。
那么有读者可能会问,DALL-E 3的数据标注方法具体是什么样的呢?
DALL-E 3开源的技术报告题目直接就是《Improving Image Generation with Better Captions》,可见OpenAI对数据质量与标注质量的重视。
目前AI绘画大模型存在一个很大的问题是模型的文本理解能力不强,主要是指AI绘画大模型生成的图像和输入文本Prompt的一致性不高。产生这个问题归根结底还是由训练数据集本身所造成的,更本质说就是图像Caption标注太过粗糙。
这里总共有两个方面的原因。
- 图像数据集自带的常规文本Caption标签一般很简单(比如COCO数据集),它们大部分只描述图像中的主体内容而缺失了背景、主体位置、主体数量、图像中的文字等其它的很多重要信息。
- 当前训练AI绘画大模型的主流图像文本对数据集(LAION数据集等)都是从网页上直接爬取的,其中文本Caption标签其实就是简单的Alt Text信息,并且会包含很多不太相关的文本信息(广告等),加入了太多的无关噪声。
这两个原因导致了AI绘画大模型的预训练数据集中的Caption标签粗糙且不准确,而数据是决定AIGC模型性能上限的关键,自然也导致训练的模型无法充分学习到文本和图像的对应关系,这是就产生了我们刚才说的Prompt Following能力的不足。
所以我们需要优化训练数据集的文本Caption标签,来提升的AI绘画模型的Prompt Following能力,让生成的图像和输入文本Prompt更加一致。
DALL-E 3是通过训练【微调】一个基于CoCa架构的Image Captioner模型来合成完善图像的Caption标签。
论文:CoCa: Contrastive Captioners are Image-Text Foundation Models
CoCa模型相比CLIP模型额外增加了一个Multimodal Text Encoder结构来生成Caption,它训练的损失同时包含CLIP的对比损失和Captioning的交叉熵损失。因此CoCa也可以用于Caption标签的生成,CoCa模型的架构和训练过程如下图所示:
CoCa模型的架构与训练过程 预训练好Image Captioner模型后,为了获得更加精细的Caption标签,DALL-E 3(https://cdn.openai.com/papers/dall-e-3.pdf)中对Image Captioner进行了进一步的微调训练,包括两个不同的数据集构建方案,具体如下所示:
- 第一个方案的微调数据集中只有描述图像主体的短Caption标签。
- 第二个方案的微调数据集中有详细描述图像内容的长Caption标签。
通过这两种方案,我们获得了两个不同的微调模型,分别具备生成短Caption(Short Synthetic Captions,SSC)标签和长Caption(Descriptive Synthetic Captions,DSC)标签的能力。之后主要实验了合成Caption标签的比重对训练的效果。得出两个结论:
- 采用合成的长Caption对AI绘画模型的Prompt Following能力是有比较大提升的。
- 采用95%的合成长Caption+5%的原始Caption作为最终的Caption标签,在此基础上训练得到的AI绘画大模型的图像生成效果是最好的。
上面的内容就是DALL-E 3的完整标签制作流程与训练策略,这也是其图像生成性能大幅提升的关键。
虽然采用95%的合成长Caption进行训练会大大提升AI绘画大模型的生成效果,但是也存在AI绘画大模型过拟合到长Caption上,当我们输入常规的短Caption时,生成图像的效果可能会变差的情况。为了解决这个问题,OpenAI是用了GPT-4对用户输入的Caption进行“upsampling”操作,对输入的文本进行优化扩写。下图展示了用GPT-4对输入Prompt进行优化扩写的过程,这样不论用户输入什么样的Prompt,DALL-E 3都能生成质量较高的图像:
使用GPT-4对用户输入的文本Prompt进行优化扩写 所以,DALL-E 3与GPT-4结合不仅仅是AI产品层面的创新,也是为了保证DALL-E 3的输入Prompt不偏离训练时的分布。
SD 3沿用了DALL-E 3的数据标注技术
- 将Image Captioner模型从CoCa替换成了CogVLM。
- 同时在SD 3的训练过程中,是使用50%的原始Caption和50%的合成长Caption
【考虑到合成标题可能导致文本到图像模型忘记VLM知识语料库中不存在的某些概念,故他们使用50%的原始标题和50%的合成标题(且做了实验,证明这种一半原始标题 一半合成标题的效果确实明显好于100%都是原始标题的情况)】
这样就能够较好的提升SD 3模型的整体性能,具体结果如下表中所示:

图像特征和文本特征在训练前缓存
SD 3与之前的版本相比,整体的参数量级大幅增加,这无疑也增加了推理和训练成本。
为了减少训练过程中SD 3所需显存和特征处理耗时,SD 3设计了图像特征和文本特征的预计算逻辑:由于VAE、CLIP-L、CLIP-G、T5-XXL都是预训练好且在SD 3微调过程中权重被冻结的结构,所以在训练前可以将整个数据集预计算一次图像的Latent特征和文本的Text Embeddings,并将这些特征缓存下来,这样在整个SD 3的训练过程中就无需再次计算。整体上看,其实预计算逻辑是一个空间换时间的技术。
【分两步:第一步先讲图像特征和文本特征拿到,存起来,第二步,直接使用存起来的特征训练】
使用Classifier-Free Guidance技术
想要了解Classifier-Free Guidance,那首先要从Classifier Guidance讲起。
Classifier Guidance技术是由OpenAI在2021年首次提出,其思想是让扩散模型可以按照指定的类别【提示词】生成图像。我们可以使用贝叶斯定理对条件生成概率进行分解,从下式中可以看出Classifier Guidance的条件生成只需要添加一个额外的Classifier梯度即可:
【
- 无条件分布的梯度(Unconditional Score):
,表示模型对数据分布本身的理解,不考虑任何特定条件
。
- 分类器梯度(Classifier Gradient):
,表示特定条件
的影响(在 生成样本
- 左侧Classifier Guidance: 表示在特定条件
】
我们可以添加一个权重项 λ 来灵活的控制unconditional score和classifier gradient的占比,如下所示:
【原文中的公式2的
位置不对,这里已经更正】
公式各部分含义
1.
- 无条件生成的梯度(unconditional score)。
- 负责生成样本的真实感和自然性,与任何条件
2.
- 分类器梯度(classifier gradient)。
- 提供条件
3.
- 权重项,控制条件生成(分类器信号)与无条件生成之间的平衡:
- 当
- 当
- 当 0 <
使用Classifer Guidance技术需要训练Classifier梯度项,这相当于额外训练一个根据噪声得到类别标签的分类器,这是一个非常困难的任务。此外这个分类器的结果反映到了生成梯度上,无疑会对生成效果产生一定程度的干扰影响。
为了解决这个问题,Google提出了Classifier-Free Guidance技术。Classifier-Free guidance的核心思想是通过一个隐式分类器来代替显式分类器,使得生成过程不再依赖这个显式的分类器,从而解决了Classifier Guidance中出现的上述这些问题。具体来讲,我们对式(1)进行移项,可得:
将式(3)代入到式(2)中,我们有
根据式(4),我们的分类器由conditional score和unconditional score两部分组成。在训练时,我们可以通过一个对标签的Dropout来将标签以一定概率置空,从而实现了两个score在同一个模型中的训练。
同样的,SD 3在训练过程主要对输入文本进行一定程度的dropout来实现Classifier-Free Guidance,实际操作时对三个Text Encoder各以46.4%的比例单独dropout,这也意味着输入文本完全dropout的比例为(46.4%)3≈10%。
【为什么需要独立Dropout?】三个Text Encoder独立进行dropout可以增加模型的泛化性能,这样当我们使用SD 3进行推理时就可以灵活的使用三个Text Encoder或者几种的一两个。
比如说,当我们的计算资源有限时,我们可以不加载占用显存较大的T5-XXL模型,从而只保留两个CLIP Text Encoder模型。官方论文中实验发现这样的操作并不会影响视觉美感(没有T5-XXL的胜率为50%),不过会导致文本一致性的略有下降(胜率为46%),并且还是包含了文本提示词描述高度详细的场景。不过如果想要进行高质量的文字渲染,还是需要加上T5-XXL模型的,因为在不加载T5-XXL时的胜率只有38%。
使用DPO(Direct Preference Optimization, 人类偏好)技术微调
首先DPO(Direct Preference Optimization)技术一开始在NLP领域被提出,主要是使用偏好数据对大型语言模型(LLMs)进行微调来获得更好的性能。现在在AI绘画领域,DPO技术也可以用来对AI绘画模型进行偏好的微调训练了。
与SDXL使用的RLHF(人类反馈强化学习)相比,DPO技术的优势是无需单独训练一个Reward模型,而是直接基于成对的比较数据进行微调训练。
所以在最后,DPO技术能够有效地根据人类偏好对SD 3模型进行进一步调优,不过SD 3并没有直接微调整个网络参数,而是引入了Rank = 128的LoRA权重在20亿和 80亿参数的SD 3 Base模型上进行了4000次和2000次迭代的微调。
经过DPO技术的微调后,SD 3的图像生成质量有一定的提升,特别是文字渲染方面的能力更强了。
使用QK-Normalization
【Attention层计算的Q 和 K 的矩阵乘缩放仅仅依赖缩放可能不足以解决高分辨率图像训练时的数值不稳定性】
随着SD 3模型的参数量持续增大,官方发现在进行高分辨率图像训练时,Attention层的attention-logit(Q和K的矩阵乘)会变得不稳定,导致训练会跑飞,梯度出现NaN的情况。为了提升SD 3在混合精度训练时的稳定性,在MM-DiT【两个流】的Self-Attention层使用RMSNorm对Q-Embeddings和K-Embeddings进行归一化,也就是论文里说的QK-Normalization。如下图红框:

RMSNorm介绍如下:
RMSNorm(Root Mean Square Normalization)主要是基于Layer Normalization的一种改进方法,它通过计算参数激活值的均方根(RMS)进行归一化,而不是像Layer Normalization那样计算均值和方差。
假设输入向量为 x ,其维度为 d。RMSNorm 的计算步骤如下:
计算均方根值(RMS):
对参数进行归一化:
缩放和平移:
其中,γ 和 β 分别是 缩放参数 和 平移参数,与 Batch Normalization 和 Layer Normalization 类似。这两个参数是可学习的,在 SD3 的训练过程中逐步优化更新。
其他归一化方法请参考:深度学习——优化算法、激活函数、归一化、正则化



使用RMSNorm作为正则化项有如下优势:
- 计算效率高:RMSNorm 仅需计算均方根值,而不需要计算均值和方差,计算量相对较小。
- 适用于小批量或单样本:与Batch Normalization不同,RMSNorm不依赖于批量大小,因此在小批量或单样本情况下表现良好。
- 稳定性:通过均方根值进行归一化,可以在一定程度上避免梯度爆炸和梯度消失问题,提高训练稳定性。
设计多尺度位置编码(插值+扩展)
SD 3先在256x256分辨率的数据上进行预训练,再在1024x1024分辨率的数据上进行多尺寸的微调,所以需要MM-DiT架构对应的位置编码也设计成多尺寸的。
为了能够适应多尺寸的位置编码,SD 3的MM-DiT借鉴了ViT(vision transformer)的2D Frequency Embeddings(两个1D Frequency Embeddings进行concat操作),并在此基础上进行了插值+扩展的策略。
【补充:位置编码,因为Transformer的位置编码主要是针对一维的序列,对于二维的图像数据,将水平位置编码(width, W)和垂直位置编码(height, H)分别计算后拼接,得到二维的位置信息】
2D Frequency Embeddings详细介绍可以参考:深度学习——3种常见的Transformer位置编码中的基于频率的二维位置编码部分。
假设目标分辨率的像素量为 ,SD 3 中也使用了数据分桶(bucketed sampling)训练的策略,数据集中各个尺寸的图像满足
(比如
,
,
等),同时设定图像的宽和高最大分别为
和
。因为 SD 3 的 VAE 会进行 8 倍的下采样,同时设置 Patch Size 为 2 会带来 2 倍的下采样,所以输入到 SD 3 的 MM-DiT 架构中的 patches 尺寸进行了 16 倍下采样,最大值有:
SD 3 的预训练阶段是在 256×256 分辨率下进行位置编码的,我们可以先通过插值的方式将位置编码应用到 S×S 尺度上,此时相当于位置 p 处的网格值为:
进一步地,我们可以将其扩展支持最大的宽和高,以高为例子,这里有:
对于不同的尺寸,我们只需要 CenterCrop 出对应的 2D 网格进行 Embedding 得到位置编码。
插值+扩展的策略是处理多分辨率、多尺寸场景的必要设计,是为了让 位置编码 能够适配不同分辨率和宽高比的图像,从而在高分辨率和多尺寸训练任务中保持模型性能和数值稳定性。一般需要通过以下步骤:
1: 数据分桶(Bucketed Sampling)
目的:
- 解决多分辨率和多宽高比图像在训练中的适配问题。
- 保证模型能处理不同尺寸的图像,同时训练效率更高。
实现:
- 图像分辨率满足
,如
,
,
。
- 设定最大宽高
和
,以支持所有目标分辨率。
- 数据分桶通过将不同尺寸的图像分组,确保每组图像都能有效训练模型。
2: 下采样与 Patch 设计
目的:
- 通过下采样降低输入图像的分辨率,从而减少计算成本,提高训练速度。
- 将不同分辨率的图像归一化为固定尺寸 Patch,使其适配 MM-DiT 架构。
实现:
- 总下采样倍数:通过 VAE 和 Patch Embedding,输入图像会被 16× 下采样。
- VAE 下采样 8× 。
- Patch Size 2× 2 进一步 2× 下采样。
- 结果尺寸:
- 最大输入尺寸变为:
3: 插值策略
目的:
- 让预训练阶段(256×256分辨率)的初始位置编码扩展到更高分辨率(如1024×1024),同时保持平滑性和一致性。
实现:
- 位置编码通过插值扩展到目标分辨率 S×S:网格值 =

- p:网格中的位置。
:从低分辨率到高分辨率的插值缩放因子。
4: 扩展与裁剪策略
目的:
- 扩展位置编码以支持最大宽高的图像,保证任意尺寸的输入都能适配。
- 通过裁剪从扩展网格中提取对应部分,使其适配不同宽高比的输入。
实现:
- 扩展:
- 将位置编码扩展到最大尺寸
,以确保支持所有可能的宽高比。
- 裁剪:
- 通过 CenterCrop 提取目标分辨率的编码: 位置=
- 确保裁剪后的编码能精准匹配输入图像。
TimeStep Schedule中shift参数作用
在AI绘画大模型的训练过程中,如果对高分辨率的图像采用和低分辨率图像一样的noise schedule,会出现对图像的加噪破坏不充分的情况,如下图所示:

DDPM架构的扩撒模型采用对noise schedule进行偏移的方法来进行解决
【SDXL中使用的Offset Noise操作,也是因为加噪破坏不充分。SDXL的解决方案可以参考:SDXL的优化工作-CSDN博客】。
对于SD 3这个基于RF的扩散模型来说,则是设计了TimeStep Schedule的shift策略,详细介绍如下:
【TODO】
SD 3论文中的实验结果表明,当分辨率调整为1024×1024时,shift value 最优值为 3.0。
基于DiT架构AI绘画大模型的Scaling能力
基于Transformer架构与基于U-Net(CNN)架构相比,一个较大的优势是具备很强的Scaling能力,通过增加模型参数量、训练数据量以及计算资源可以稳定的提升AI绘画大模型的生成能力和泛化性能。
SD 3论文中也选择了不同参数规模(设置网络深度为15、18、21、30、38)的MM-DiT架构进行实验。当网络深度为38时,也就是SD 3的8B参数量模型,MM-DiT架构表现出了比较好的Scaling能力,当模型参数量持续增加时,模型性能稳步提升。
同时从实验结果也可以看到,以目前的参数量级来说,还没有出现模型性能饱和的情况,说明如果继续增大模型参数量,模型性能可能继续提升,而这个结论也在后续发布的FLUX.1模型中得到了印证。
同时参数量更大的模型不仅性能更好,而且在生成时可以用较少的采样步数获得相同的性能。
SD 3.5
2024年10月22号,StabilityAI最新发布了Stable Diffusion 3的升级版Stable Diffusion 3.5系列,包括Stable Diffusion 3.5 Large、Stable Diffusion 3.5 Large Turbo以及Stable Diffusion 3.5 Medium(将于10月29日开源)三个模型。

![[VUE]框架网页开发02-如何打包Vue.js框架网页并在服务器中通过Tomcat启动](https://i-blog.csdnimg.cn/direct/dcf2547ffcef46f9a41b02ef768906fb.png)