公司有一套StarRocks的大数据库在大股东的腾讯云环境中,通过腾讯云的对等连接打通,通过dolphinscheduler调度datax离线抽取数据和SQL计算汇总,还有在大股东的特有的Flink集群环境,该环境开发了flink开发程序包部署,实时同步数据。
公司业务帆软报表平台有40张左右的报表连接的Starrocks大数据库。Starrocks大数据库整个库大小超过13TB+
因各种原因,大股东的腾讯云环境不再让使用,打通的对等连接也会断开,需要把Starrocks及相关的服务等迁移回来:
1,Dolphinscheduler分布式调度:调度Datax抽取脚本和SQL计算汇总脚本
2,重新部署StarRocks数据库集群
3,实时同步几十张实时同步的表
4,同步现有StarRocks的历史数据到新的集群中
5,实时Flink聚合的表
因涉及的报表和东西多,再2023年就公司说要迁回来,但情况一说,太复杂了,就一直拖着不迁移。
但到2024年4,5月份,公司大股东说必须要迁移,公司让尽快研究StarRocks迁移事情,这件事又落自己头上,想想头大,这么多事情,测试方案,部署环境,买机器,实时同步,历史数据处理等等,这次没办法只能向前做,从2024年5月份到现在2024年11月份,迁移工作是被动做做停停的,到现在完成差不多,抽空把过程总结写下来:
1,Dolphinscheduler分布式调度
1.1 为省成本,请大股东的运维远程在公司腾讯云现有机器上部署DS调度,部署的版本一致,在个别机器内存做扩容
1.2 以前海豚的调度元数据库导出,部署到公司的MySQL,这样任务和调度就和以前一样。
1.3 海豚调度的Datax脚本,因以前他们用了CFS服务共享磁盘用一套,这边做不了,只能在3台机器上各部署一套路径一致的datax抽取脚本
2,部署StarRocks数据库集群
考虑兼容问题,没有使用最新的StarRocks 3 版本,用的腾讯云EMR集群的Starrocks2.5版本,省去自建和维护的很多事情。
3,实时同步
1,使用Flink集群
以前做的程序是在其特殊Flink API环境开发,拿以前的程序直接部署到Flink集群就无法使用,要么重新开发,我不擅长Flink这块,只能放弃!
2,腾讯云---流计算Oceanus
咨询腾讯云的技术支持,推荐Oceanus,可以实现Flink SQL实现实时同步,发现还有多表同时同步的,觉得终于可以解决这个实时同步问题了,就买了一个月的Oceanus服务,测试了多表,通过Microsoft VS Code搜索目录下的帆软报表,找出实时同步的表,然后按库多表同时同步,但是部署6个任务后,按库多表同时同步,经常报错,不稳定,后来咨询,腾讯云说多表同步不稳定的确不推荐,但我一个表一个job任务,那要多少任务,肯定不行,没办法不能使用!
3,Java程序实现实时同步
研发同学,说以前做个单个表的同步,没办法,只能让他通过java程序来实现同步,通过读取binlog程序写到库里,后来把这6个整理的几十个任务表提供,他写java程序同步,可以使用。
4,StarRocks历史数据同步
咨询大股东,他们迁移StarRocks到腾讯云的EMR,历史数据是通过StarRocks外部表来做,但公司说要节省成本折扣更多,把StarRocks买到另外一个腾讯云账号上,再打通到现在公司的腾讯云,这样就有3个腾讯云账号,又没法把新账号腾讯云和大股东腾讯云打通,结果导致2个Starrocks不通,不能通过外部迁移历史数据,没办法,这时就想到用自己做的开源pydatax来同步,但要拼接处src_table_column表,直接通过SQL就可以出来如下:
select TABLE_NAME,GROUP_CONCAT(replace(COLUMN_NAME,'etl_process_time','now() as etl_process_time')) cols from
(select TABLE_NAME,COLUMN_NAME,ORDINAL_POSITION
from information_schema.`columns`
where TABLE_SCHEMA='db'
and TABLE_NAME like 'bo_ods%' order by TABLE_NAME asc,ORDINAL_POSITION asc ) t
GROUP BY TABLE_NAME order by TABLE_NAME asc
以上表是离线的,实时的也是类似。获取到src_table_column信息,通过下列SQL获取写入到datax_config_wm表
SELECT TABLE_NAMe,
CONCAT("INSERT INTO datax_config_wm (type, src_table_name, json_id, des_table_name, relation,dcondition, ",
"src_table_column, des_table_column, server_type, ordernum, status, etl_type, etl_column, etl_num, last_etl_date, note, ",
"create_time) VALUES ('1','",TABLE_NAMe,"','",'9',"','",TABLE_NAMe,"',","'t','","1=1","','",GROUP_CONCAT(COLUMN_NAME),"'",'ss#stt')
FROM (
select * from information_schema.`columns` where TABLE_SCHEMA='report_srdw'
and TABLE_NAME in (
select TABLE_NAME from information_schema.`tables` where TABLE_SCHEMA='report_srdw' and ENGINE='StarRocks'
and TABLE_NAME like 'bo_ods_%')
order by TABLE_NAME asc,ORDINAL_POSITION asc
) t
group by TABLE_NAME;
注:这个'ss#stt'字符,是用来替换成下列字符:
, '*', 0, 22.001, 1, 0, '', 14, CURRENT_DATE(), 'wm', now());
生成完成后,copy和修改pydatax让其读取配置表datax_config_wm,离线是T+1,同步历史数据。
已经部署的海豚调度已经每天在同步数据。历史数据就通过pydatax同步数据,遇到特别大的表,导致抽取查询超时,修改参数成6000秒:
set global query_timeout=6000;
但改完个别表大还是超时,这时对这个表分割多次同步,直接修改datax_config_wm的加上范围就可。
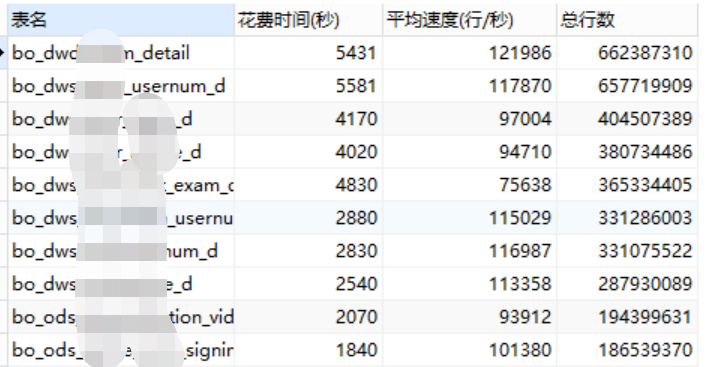
几天时间,实时和离线的322张表历史数据就同步完成,部分大表抽取信息如下,看出Datax的能达到12万行+/秒的速度,6.6亿多条同步要 91分钟。
5,实时Flink聚合的表
帆软报表用到实时聚合表,但是研发同学没有实时聚合功能,查询实时报表,分析虽然做了好多聚合表,但实际只有5张表使用,
想想就使用StarRocks 的物化视图,替换原有聚合表,对报表透明无感知,这5张表的聚合对应修改成聚合后的物化视图。
上线后,有3张物化视图的源实时表老是同步出错,不得不取实时表改成T+1的数据表,和产品经理沟通后,对应的报表的显示的"实时"也加上"昨天"。
以上修改后,正式切换线上帆软报表连接成新的StarRocks 库,观察线上的客户使用情况。
总结:
1,该迁移前后花了好几个月时间,有点长!
2,难到不难,大量的细心的工作需要做!
3,数据同步工具 pydatax 又一次出色完成其高效简单的数据迁移任务。