点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>CV微信技术交流群
转载自:新智元 | 编辑:Aeneas 昕朋
【导读】2022年有哪些人工智能的突破?今天,李飞飞高徒Jim Fan盘点了年度十大AI亮点。
人工智能的爆炸正在扭曲我们的时间感。
你能相信Stable Diffusion只有4个月大,而ChatGPT的出现还不到一个月吗?
打个形象的比喻,只要眨一下眼,你就会错过一个全新的行业。
2022年的AI领域,大规模的生成模型像雨后春笋一样地冒出,改变了整个AI界的格局。
而且,这些模型正在迅速走出实验室,在现实中被应用。
比如,LLM技术就启发了两个新兴的领域——决策代理(游戏、机器人等等)和 AI4Science。
李飞飞高徒Jim Fan为我们总结了2022年的十大AI高光时刻。让我们把时间倒转,看看2022年都有哪些令人惊叹的AI突破。
一、文字-图像生成
DALLE-2是第一个可以从任意标题生成逼真的高分辨率图像的大规模扩散模型。
它启动了AI的艺术革命,催生了许多新的应用程序、初创公司和思维方式。

但 DALLE-2被保护在OpenAI的围墙后面,并没有开源。
在OpenAI之后,LMU的StabilityAI和runwayml迈出了英勇的一步,基于「潜在扩散」算法训练了他们自己的互联网规模的text2image模型。他们称该模型为「稳定扩散」,并开源了代码和权值(weighs)。

事实证明,Stable Diffusion的开放性,让它给游戏带来了巨变。
现在,许多初创公司和研究实验室都在Stable Diffusion的基础上创建新的应用程序,Stable Diffusion本身也被开源社区不断改进。
最近,Stable Diffusion已经达到了v2.1版本,可以在单个GPU上运行了。

另外,今年还有来自GoogleAI的两个image2text模型。GoogleAI既没有发布模型也没有发布API,但从论文中,我们仍然可以看到不少有趣的见解。
Imagen
https://imagen.research.google

Parti
https://parti.research.google。它是一个没有diffusion的Transformer模型。

二、文字-文字生成
大家都知道,我说的是ChatGPT!
这是历史上唯一一个在5天内就获得了100万用户的应用程序。
ChatGPT也大大启发了我们人类的创造力。
在这个列表中,可以看到所有有用的和有想象力的关于ChatGPT想法:https://github.com/f/awesome-chat
ChatGPT和GPT-3.5都使用了一种叫做RLHF(「从人类反馈中强化学习」)的新技术。
这也就意味着,提示工程或许很快就会消失了。

ChatGPT的流行,已经催生了一波新的创业公司和竞争者,比如Jasper Chat、YouChat、Replit的Ghostwriter chat,以及perplexity_ai。
这些竞争者提供了如此直观的搜索方式,连谷歌的高管们都开始出汗了!

三、文本- 机器人模型
如何给GPT提供胳膊和腿,让它们能打扫你混乱的厨房?
与NLP不同,机器人模型需要与物理世界互动。
在今年,大的预训练Transformer终于开始解决机器人领域最难的问题了!
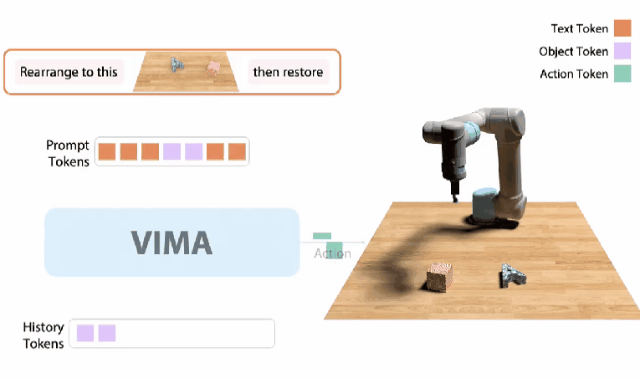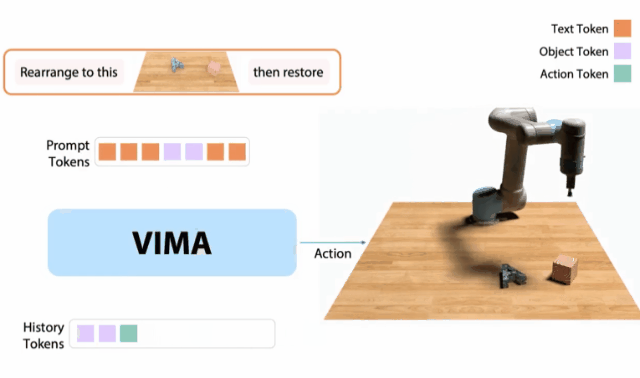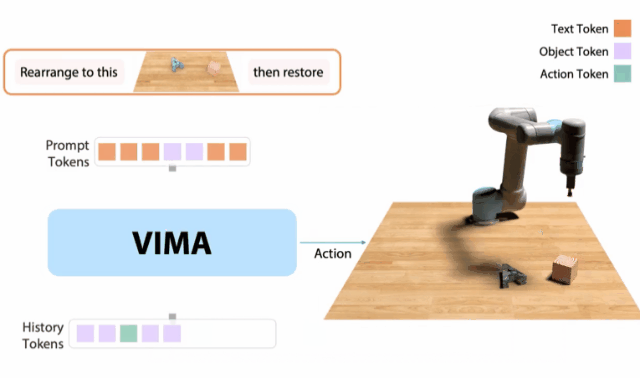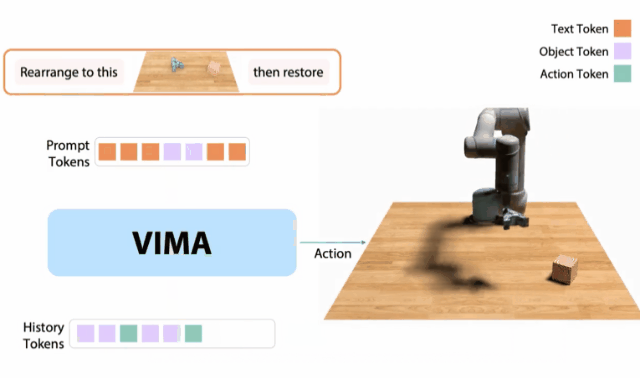
VIMA
10月,我和同事创建了一个 「机器人GPT 」——名为VIMA的tranformer。
它可以接收任何混合的文本、图像和视频作为prompt,并输出机器人手臂的控制。
我们的模型被称为VIMA(「VisuoMotor Attention」),已经完全开源了。
现在,单个智能体已经能够解决视觉目标、视频的一次性模仿、新概念基础、视觉约束等,具有了模型容量和数据的强大扩展性。
RT-1
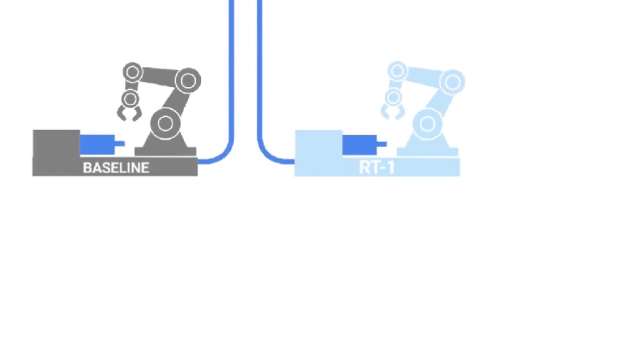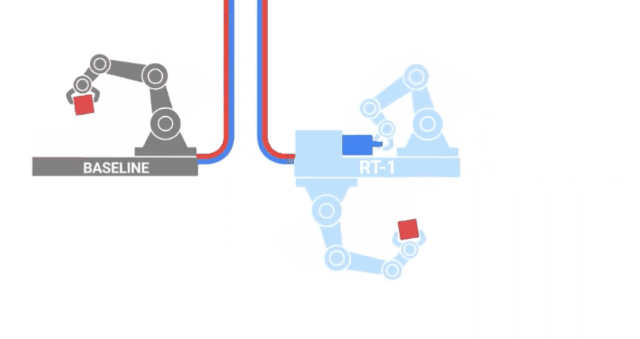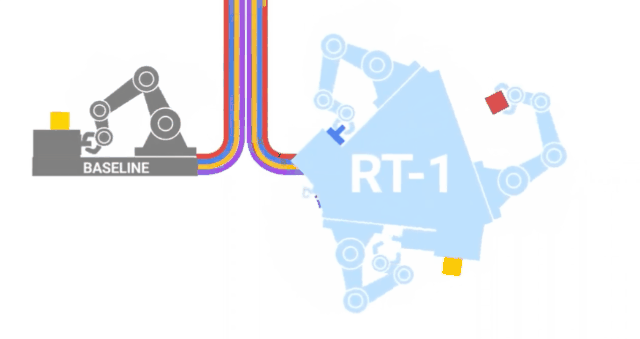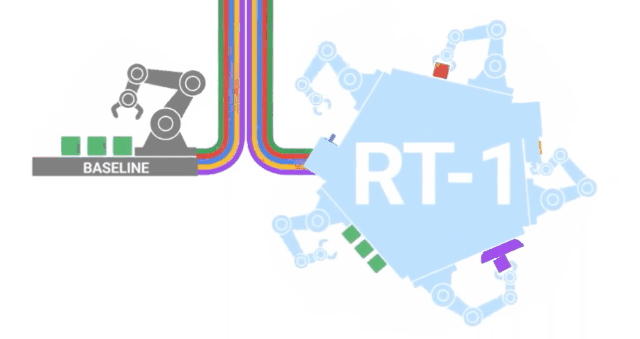
沿着与VIMA类似的路径,来自GoogleAI的研究人员发布了RT-1,这是一种在700项任务和130K的人类演示上训练的机器人transformer。
这些数据是由13个机器人在17个月内收集的,是字面意义上的钢铁部队!
四、文本 - 视频
本质上说,视频就是随着时间的推移捆绑在一起的一系列图像,给我们创造了运动的错觉。
如果我们可以做text2image,那为什么不在里面加上时间轴,来获得额外的乐趣呢?
目前,文本 - 视频领域有3个重大的工作,但没有一个是开源的。
Make-A-Video
首先是Meta AI的Make-A-Video:不需要成对的文本-视频数据,就可以得到文本-视频的生成。
您可以在此处注册试用访问权限:https://makeavevideo.studio

论文链接:https://arxiv.org/abs/2209.14792

Imagen Video
Google AI的Imagen Video:它能使用扩散模型生成高清视频,基于Imagen静态图像生成器。
演示:http://imagen.research.google/video/

论文链接:https://arxiv.org/abs/2210.02303

Phenaki
来自谷歌AI的Phenaki: 从开放领域的文本描述中生成可变长度的视频。
演示:https://phenaki.video

论文链接:https://arxiv.org/abs/2210.02399

五、文本-3D建模
从设计创新产品到在电影和游戏中创造奇妙的视觉效果,3D建模正成为文本-X生成模型的下一片蓝海。
令人惊喜的是,2022年出现了许多卓有前途的3D生成模型。在此,Fan列举了3个模型。
DreamFusion
首先登场的,是Google AI研究团队与UC Berkeley联合开发的DreamFusion。

论文链接:https://arxiv.org/pdf/2209.14988.pdf
该模型使用二维文本到图像的扩散模型来执行文本到三维的合成。
基于NeRF算法,DreamFusion可以通过给定文本生成3D模型。

该模型可以从任何角度查看,在任意照明下可以重新点亮,还可以合成到任何三维环境当中。
Magic3D
第二项成果,是英伟达AI团队的两个项目,名为GET3D和Magic3D。

GET3D论文链接:https://nv-tlabs.github.io/GET3D/assets/paper.pdf

Magic3D论文链接:https://arxiv.org/pdf/2211.10440.pdf
GET3D仅使用二维图像进行训练,可生成具有高保真纹理和复杂几何细节的三维图形。

该模型允许用户立即将其形体导入3D渲染器和游戏引擎,以便进行后续编辑。
Magic3D与DreamFusion类似,使用文本到图像模型生成2D图像,然后优化为体积NeRF(神经辐射场)数据,将低分辨率生成的粗略模型优化为高分辨率的精细模型。

根据英伟达AI团队,由此产生的Magic3D方法,可以比DreamFusion更快地生成3D目标。
Point-E
继年初推出的DALL-E 2用天才画笔惊艳所有人之后,周二OpenAI发布了最新的图像生成模型「POINT-E」,它可通过文本直接生成3D模型。

论文链接:https://arxiv.org/pdf/2212.08751.pdf
相比竞争对手们(如谷歌的DreamFusion)需要几个GPU工作数个小时,POINT-E只需单个GPU便可在几分钟内生成3D图像。
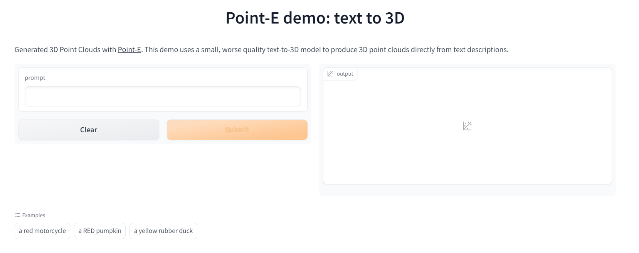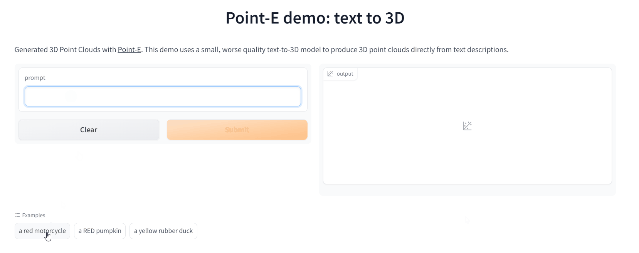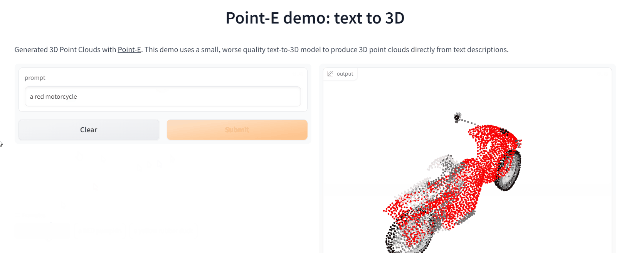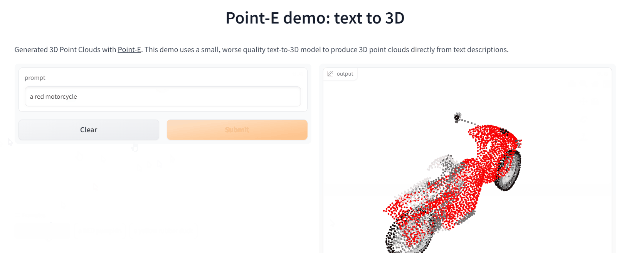
根据测试,Prompt输入后POINT-E基本可以秒出3D图像,此外输出图像还支持自定义编辑、保存等功能。
六、会玩《我的世界》的AI
《我的世界》是一款测试AI通用智能的绝佳游戏。首先,它是一款无限开放的沙盒游戏,极度体现玩家的创造力。
其次,该游戏有1.4亿的玩家群体,是英国总人口的两倍。用户基础如此庞大,供AI学习的游戏数据可谓是源源不绝。
那么,AI能否和人类一样尽情挥洒想象力呢?

Jim Fan和同事合作开发了第一个玩《我的世界》的AI「MineDojo」,它可以在自然语言提示下解决许多任务。

论文链接:https://arxiv.org/pdf/2206.08853.pdf
Fan的最终目标是建立一个「具身的ChatGPT」。目前,MineDojo平台已经完全开源。
与此同时,Jeff Clune的团队宣布了一个名为视频预训练(VPT)的模型,该模型可以直接输出键盘和鼠标的动作。

论文链接:https://arxiv.org/pdf/2206.11795.pdf
VPT拥有更广阔的视野,但不受语言条件的限制。在这点上,MineDojo和VPT恰好相辅相成。

七、AI外交官
Meta AI推出的CICERO是第一个在《外交》游戏中实现人类水平表现的人工智能智能体。

论文链接:https://www.science.org/doi/10.1126/science.ade9097
《外交》是一款七人制经典策略游戏,可以说是棋盘游戏Risk、纸牌游戏扑克和电视节目Survivor的结合。该游戏需要广泛的自然语言协商才能与人类合作和竞争。
然而,CICERO的出现表明,人工智能现在已经有说服他人和虚张声势的能力。
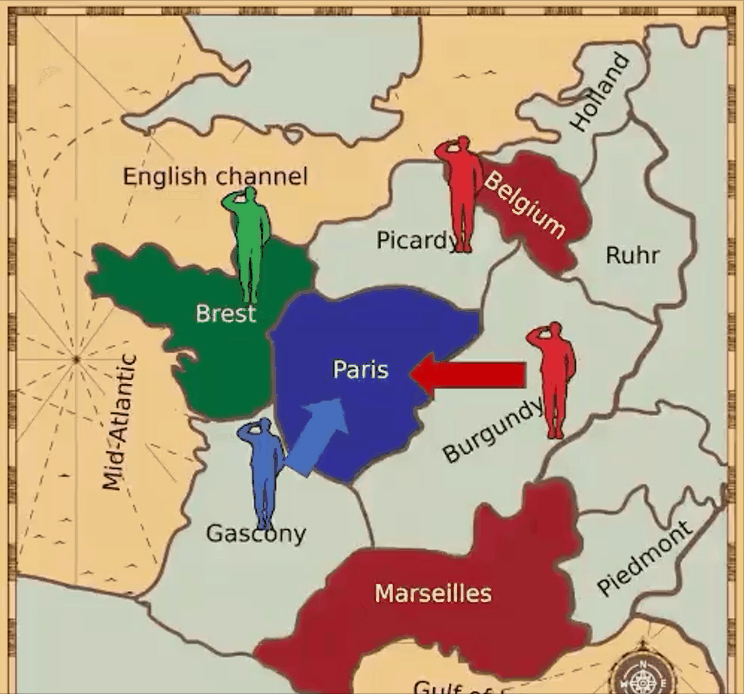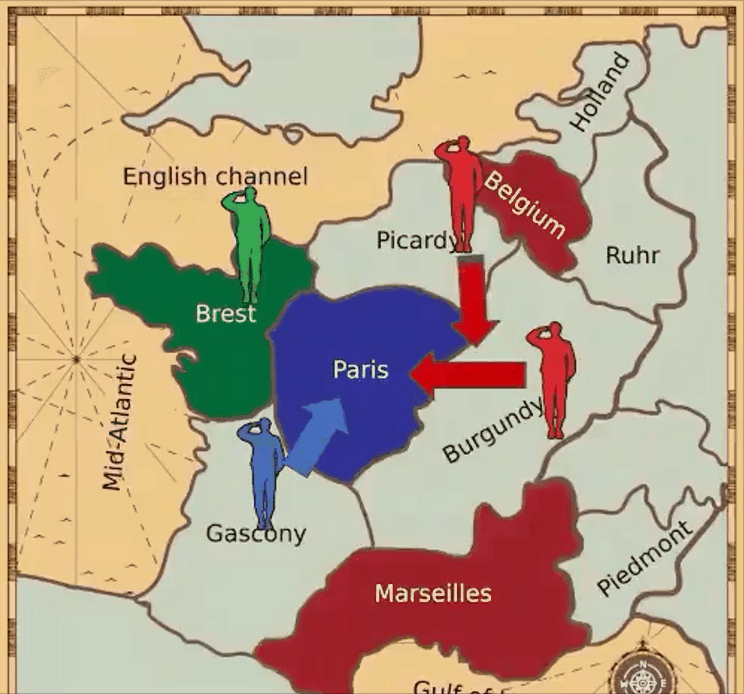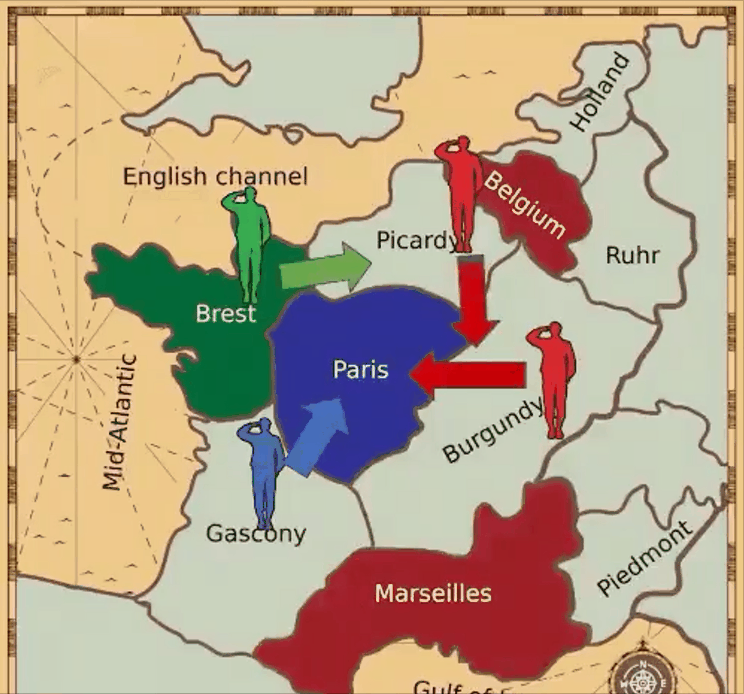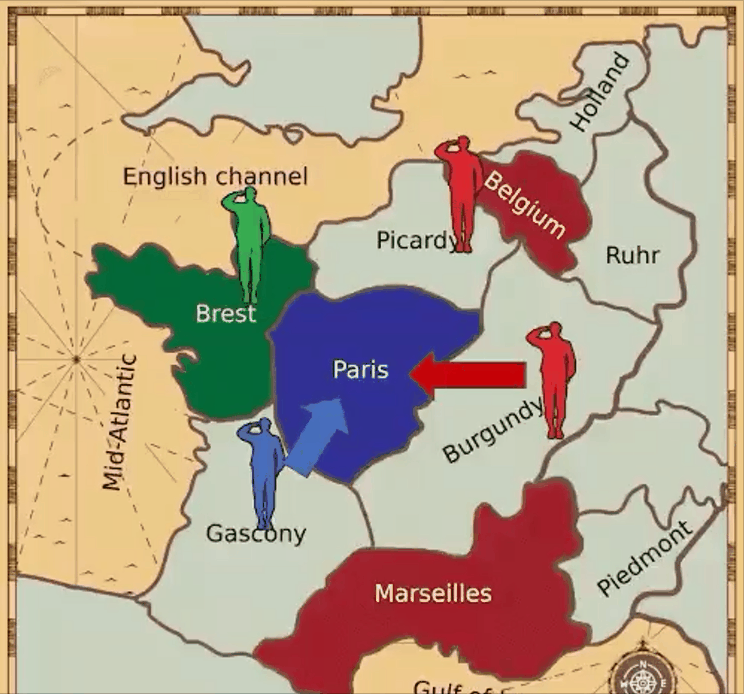
目前,DeepMind也宣布开发自己的外交官AI智能体。那么,如果CICERO使用这个AI模型,又会发生什么呢?
八、音频-文本模型
Whisper是OpenAI发布的一个大型开源语音识别模型,在英语语音识别方面有接近人类水平的鲁棒性和准确性。

论文链接:https://arxiv.org/pdf/2212.04356.pdf
Whisper经过了来自网络的680,000小时音频数据的训练。Open AI强调,Whisper的语音识别能力已达到人类水准。
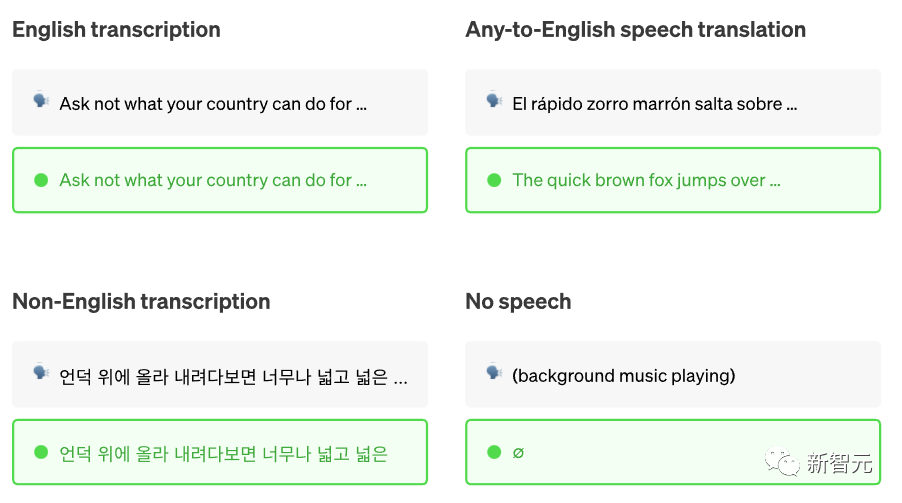
Open AI将Whisper开源,是否是为了解锁更多文本token,用以训练万众瞩目的GPT-4呢?
九、核聚变
DeepMind与瑞士洛桑联邦理工学院(EPFL)联合开发了第一个核聚变相关的深度强化学习系统,可以保持核聚变等离子体在托卡马克内的稳定。

论文链接:https://www.nature.com/articles/s41586-021-04301-9
同样在本月,美国能源部宣布了一项巨大的突破:人类首次实现了核聚变反应的净能量增益!

这是人类首次实现这一里程碑。这一生,我们或许会成为聚变文明!
十、应用于生物学的Transformer
2021年,AlphaFold开启了语言模型预测蛋白质3D结构的序幕。
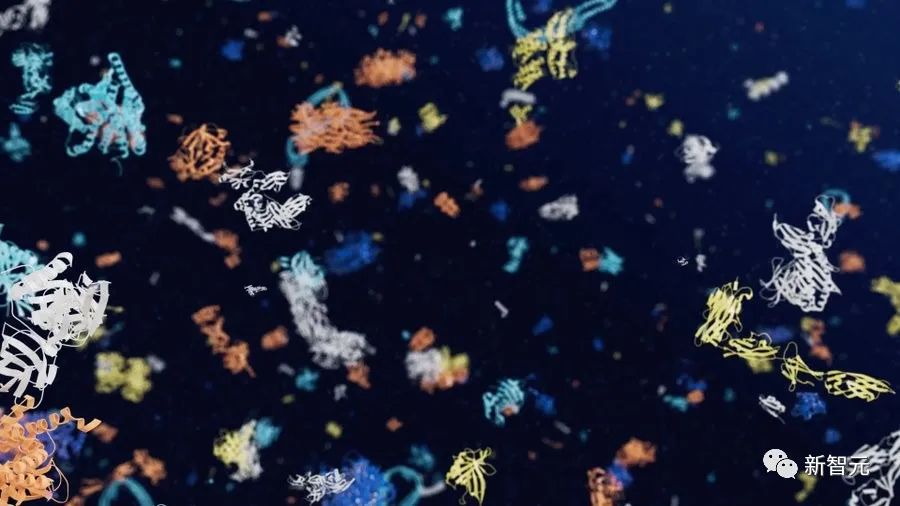
7月,DeepMind宣布了「蛋白质宇宙」——将AlphaFold的蛋白质数据库扩展到2亿个结构!
此外,英伟达AI研究团队还拓展了BioNeMo大型语言模型的框架,以帮助生物技术公司和研究人员生成、预测和理解生物分子数据。

视频讲解:https://www.youtube.com/watch?v=PWcNlRI00jo&t=4399s
以上便是Jim Fan对2022年十大AI亮点的盘点。当然,Fan也表示,还有无数令人兴奋的作品为人工智能的进步做出了贡献。
每篇论文都是AI大厦里的一砖一瓦,所有的努力都应该庆祝。
不过,Fan在最后也强调,随着人工智能系统变得越来越强大,我们必须意识到潜在的危险和风险,并采取措施减轻它们。
无论是通过仔细的培训设计、适当的监督还是全新的保障方法,人工智能的安全与伦理成为越来越的AI专家所讨论的议程。
毫无疑问,2022年是充满奇迹的一年,也是令人惊叹的一年。未来一年又会有什么震惊世界的突破?我们与你一起关注。
参考资料:
https://twitter.com/drjimfan/status/1607746957753057280?s=46&t=OVM_4zdRW2rQwqLohMdPpw
点击进入—>CV微信技术交流群
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看