作者 | 山竹
出品 | 锌产业
在刚刚过去几个月里,人工智能在大众应用层面得到了空前涌现。
尤其在微软、谷歌、Facebook、Adobe等科技巨头推波助澜下,AI生成文本、AI生成PPT、AI作画、AI抠图……
相信这段时间不少人会和我一样,会对AI产生一种错觉:凡你所想,皆能实现。
上一次对一个技术产生这样的错觉,还是Facebook为了元宇宙更名Meta时进行的一系列酷炫演示。
对于我等凡人,有魄力的,已经在通过做一个应用软件来亲身创业,大部分都仍只是AI的使用者。
而对于当下的科技巨头,应用是次要的,或者说是要留给自己生态里的开发者去做的事儿,他们真正的战场是:大模型。
刚刚过去的三个月里,国外微软、谷歌就大模型之争一直在贴身肉搏,国内更多是大佬创业在引领风向。
时间迈入4月后,国内科技巨头们终于做好了准备,纷纷将大模型的发布提上日程。
这时,华为大模型,也亟需进入(或者说是重新回到)大众视野。
2023年4月8日,当田奇走到聚光灯下时,大家都明白,华为大模型一次非正式发布要来了。
01
谁是田奇?
2018年6月,华为发布了一则人事变动公告,宣布为华为诺亚方舟实验室从海外引进了一位计算机视觉领域华人科学家担任实验室计算机视觉首席科学家,这位科学家就是田奇。
田奇加入华为的这一年,是国内科技产业亟需新一代顶级科学家引路的一年。

这一年,国内乃至全球推进物联网、云计算、人工智能新一代信息技术已经走过第一个五年,新一代信息技术创新从蛮荒时代开始转向产业应用,国内科技巨头在这一年纷纷将新一代信息技术写进了企业战略。
要支撑这样长期的技术转型,就需要有顶级人才团队持续输血,顶级科学家的人才之争开始变得激烈。
尤其阿里在2017年10月成立达摩院后,为这波科学家人才之争和产学研融合之势踩下了最后一脚油门。
当时国内科技巨头大力招揽的科学家基本可以分为两类:
一类是在产业和学术领域都有造诣的产业科学家,例如微软研究院为中国科技公司培养的诸多人才;
另一类是在学术领域造诣颇深的科学家,例如国内外顶级高校的教授学者。
虽然田奇也曾在微软亚洲研究院多媒体计算组有过一段工作经历,但严格意义上来说,他应该属于后者。
在加入华为之前,田奇最主要的身份是美国德克萨斯大学圣安东尼奥分校计算机系教授,田奇说“我在高校做了17年老师,华为帮助我完成了从高校向公司的过渡。”
加入华为,离开象牙塔的田奇找到了第一份工作,诺亚方舟实验室成了他人生中第一个实战副本。
田奇虽然是以首席科学家的身份加入的诺亚方舟实验室,但这次华为交给田奇的任务是不只有计算机视觉基础研究的任务,还有将研究落地到平安城市、终端视觉、自动驾驶、GTS大脑等各类应用产业向工作。
之后的两年里,随着计算机视觉在制造、金融、零售等行业不断深入落地,田奇也进行了二次转职。
2020年3月,田奇加入华为云,再次出现在大众视野时,田奇已经有了一个新身份,华为云人工智能领域首席科学家。

就在田奇加入华为云的这一年,大洋彼岸的一家名为OpenAI的非盈利组织发布了GPT3,由于智能化程度有限,GPT3的发布并没有像GPT4加持下的ChatGPT效果这般震撼,因而也没掀起什么风浪。
不过,GPT3为整个产业界验证了一个猜想:预训练大模型这条路,走得通。
彼时,人工智能发展的一个关键瓶颈是,如何形成人工智能基础设施,让人工智能真正迈入批量化、规模化的工业时代。
GPT3的发布,证实了预训练大模型这条路的可行性,这就意味着,人工智能有望短期内再向通用技术迈进一大步,人们无需再重复造轮子,未来可以像使用云计算一样使用人工智能。
华为同样意识到了这一点,开始组建团队造自己的大模型,而华为大模型的牵头人,正是这位在华为已经经过两年锤炼的学术派少帅田奇。
02
盘古,没能开天
2021年是华为架构多变的一年,也是华为云人事任命多变的一年,年初被任命为华为云CEO的余承东,仅仅是在4月的HDC 2021之后,就再次交棒给了张平安。
不过,田奇在华为云的位置一直未变——人工智能领域首席科学家,也是在这一年和余承东搭班HDC 2021时,田奇正式将华为盘古大模型带到了世人面前。
“今天我们在这里正式宣布我们的盘古大模型正式发布,这是我们最重磅的产品,”在HDC 2021上,余承东如是说。

尽管在这次华为云公布的六项新技术中,余承东将盘古大模型的介绍放到了第五位来介绍,但他还是强调了盘古大模型的重要性。
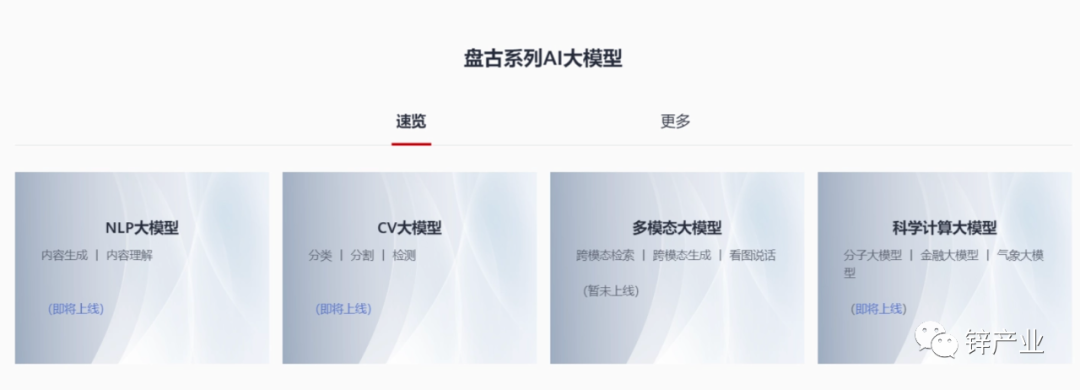
针对盘古大模型的能力,余承东会上主要强调的是NLP大模型和CV大模型的小样本学习和泛化能力,而多模态大模型和科学计算大模型当时还在规划中。
而作为盘古大模型的牵头人,田奇更希望能够实现“AI模型的通用性、泛化能力和高精度”。
据悉,盘古NLP大模型是由华为云、鹏城实验室、循环智能联合开发,鹏城云脑II提供算力支持,预训练阶段学习了40TB文本资料,参数规模达千亿级,田奇在大会上也演示了NLP大模型的对话能力。
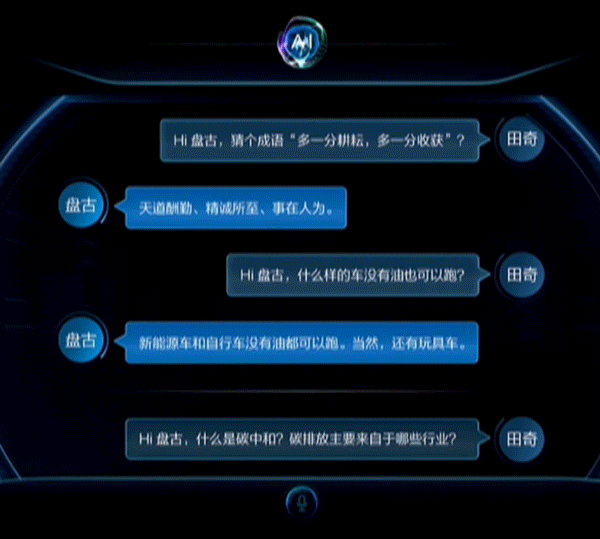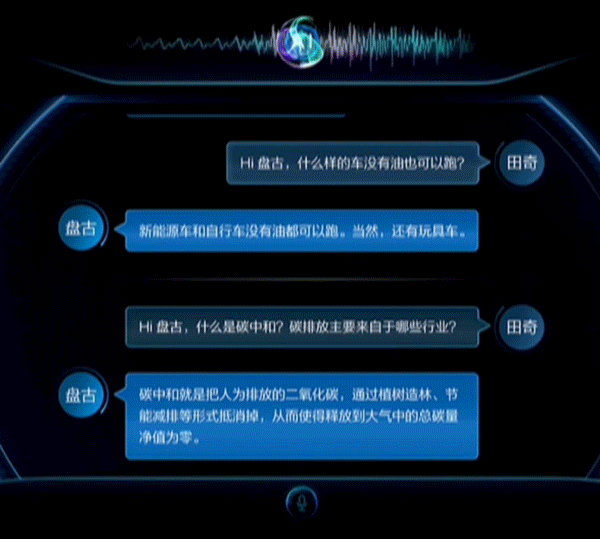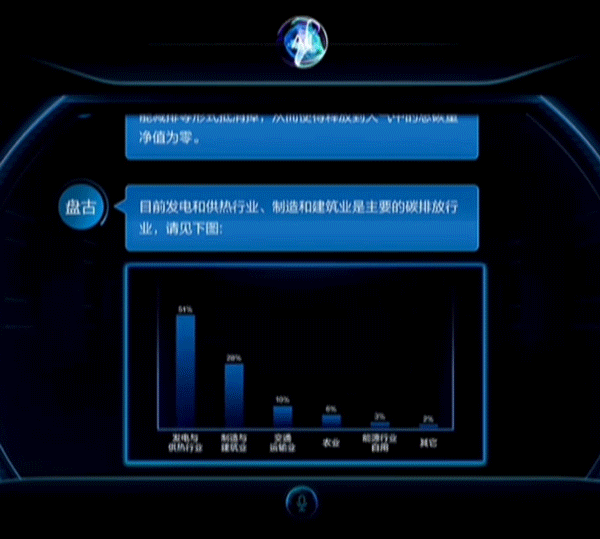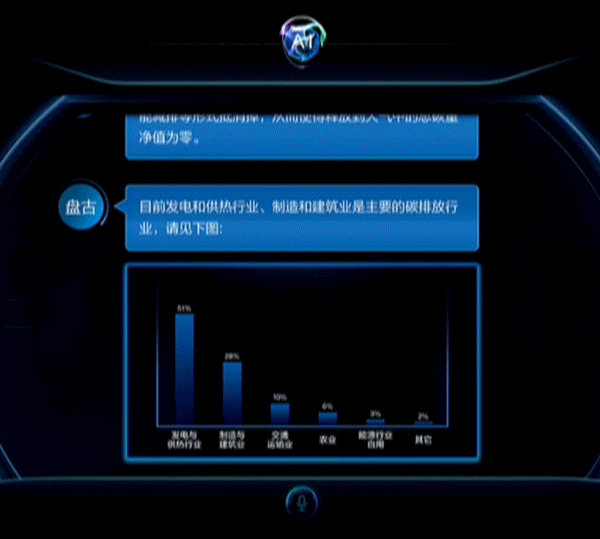
除此之外,华为还拉来国网重庆永川供电公司站台,展示了华为云盘古CV大模型在电力线巡检上的应用能力。
据国网重庆永川供电公司智能运检分公司总助周杰透露,“和小模型相比,应用大模型后,缺陷样本筛选效率提升了30倍,筛选质量提升了5倍,就我们每天采集5万张图片的筛选节省了人工标准时间170人/天。”
按田奇的说法是,当时盘古CV大模型已经能够应用到医疗影像检测、工业缺陷检测和遥感影像分析中。
按照华为官方说法,盘古大模型能力很强,应用性也得到了验证。在会后华为也把盘古大模型主创团队、工程师拉出来进行了一系列介绍和科普。
或许是由于盘古大模型迟迟未能在官网正式上线,再加上并没有像ChatGPT一样面向公众开放,华为盘古大模型和GPT3一样未能在更广泛范围内引起太大关注,甚至在之后两年里逐渐淡出大众视野。
然而,2023年初,就在ChatGPT引爆全网,大模型随之也再次出现在大众视野中时,关于华为盘古大模型的新闻报道也适时涌现,甚至有媒体报道,盘古大模型终于在华为云官网(预)上线。
也是在这时,田奇再次走上舞台,为“盘古”摇旗呐喊。
03
华为再谈大模型
4月8日,再次以学术专家站在人工智能大模型技术高峰论坛的舞台上,田奇分享了华为内部对大模型的三层分级理念:
L0:基础模型,例如GPT3,这类模型无法直接应用到行业场景中,需要与行业数据结合,混合训练得到行业大模型;
L1:行业模型,行业模型可以直接在具体细分场景进行部署,由此也就得到了细分场景模型;
L2:细分场景模型。

他指出,在这样的层级关系中,“如何从行业大模型L1中快速生产高质量的部署模型(细分场景模型)L2并部署到端、边、云侧就成了一个重要课题。”
据悉,华为盘古大模型本质上是L0基础模型,在过往几年里也尝试在不同行业进行了落地应用。
大会上,田奇对这些年华为盘古大模型的具体演进路线,进行了如下梳理:
2019年-2021年之间,华为开始立项做盘古大模型;
2021年4月发布了盘古NLP大模型1.0、盘古视觉大模型,当年也发布了盘古科学计算大模型;
2021年9月,针对小分子药物筛选发布了盘古药物分子大模型;
2022年6月,针对行业应用,华为与能源集团合作发布了盘古矿山大模型;
2022年11月,华为发布了盘古气象大模型、海浪大模型、金融OCR大模型。

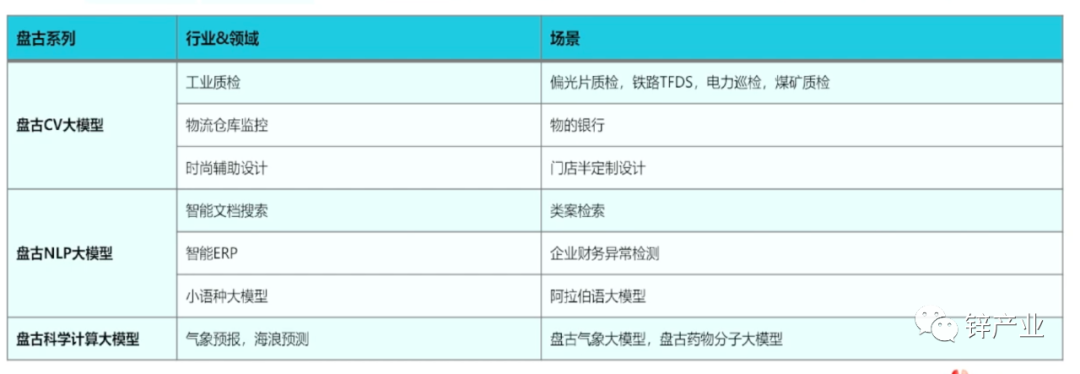
此外,针对行业应用,田奇也列出了华为盘古三类大模型在工业质检、物流仓储监控、时尚辅助设计、智能文档搜索、智能ERP、小语种大模型、气象预报、海浪预测的具体应用场景。
这次论坛上,在与前后几位院士、学者的观点交锋中,田奇演讲全程并未提到“发布”二字,但如果加上前期媒体的宣传报道,以及当下大家对科技巨头大模型的敏感度,这次田奇携盘古大模型的公开亮相,也足以在这关键时刻,将华为大模型带回到大众视野。
04
科技巨头的关键一役
2023年4月3日,斯坦福大学发布《2023 年人工智能指数报告》,报告中指出,AI模型的研发优势已经从学术界转移到了工业界。
报告中的一个关键数据是,到2022年,工业界产生了32个重要的AI模型,而学术界只有3个。
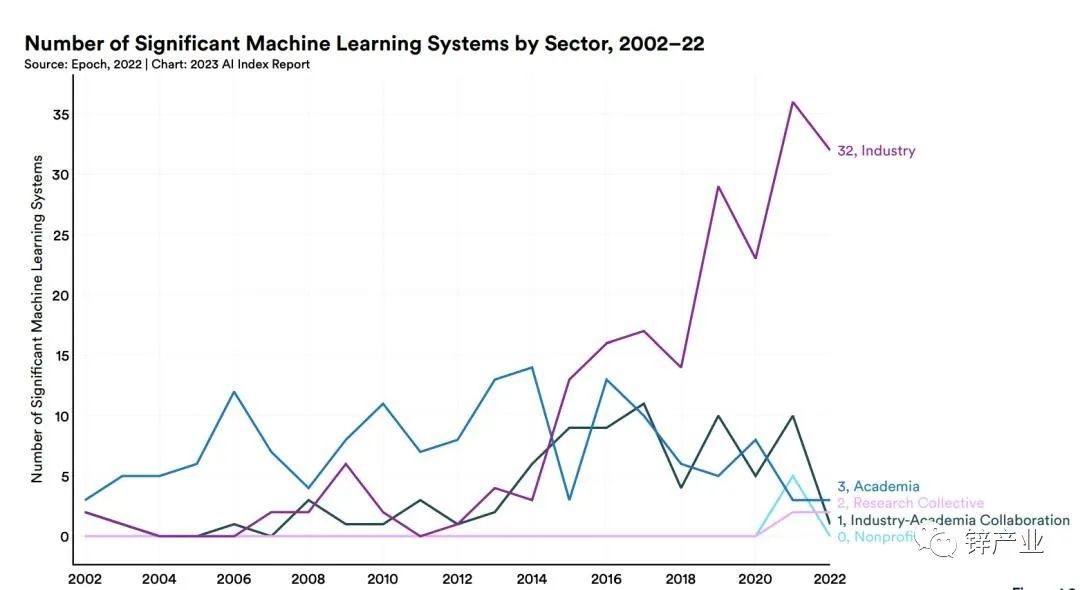
斯坦福的这份报告也分析了出现这一现象出现的原因,其中最重要的一个原因是创建这类AI模型所需要的数据、人才、算力等方面的资源要求越来越大。
2019年,OpenAI的GPT2训练用了15亿个参数,花了5万美元;2022年,谷歌的PaLM训练用了5400亿个参数,训练成本预计已经达到800万美元。
仅仅训练成本,二者相差160倍,而这样的烧钱大战还在加剧。
2023年,当大模型成为主流趋势后,行业中一个主流观点是,这也将是科技巨头之间决定生死存亡的一战。
于是,我们看到,在刚刚过去几个月里,国内李开复、王慧文、王小川等曾经互联网大厂关键战力们纷纷官宣再创业,百度、360不顾翻车风险也秀出了自己的ChatGPT。
而华为盘古大模型的再“发布”,也让华为的大模型重新回到大众视野。
除此以外,我们也看到,阿里通义大模型、科大讯飞1+N认知智能大模型等更多大模型正在跑步入场。
被誉为科技巨头生死战的大模型之战,最终究竟谁会胜出,又将如何成为我们生活中的“水”和“电”,我们拭目以待。
巴比特园区开放合作啦!



中文推特:https://twitter.com/8BTC_OFFICIAL
英文推特:https://twitter.com/btcinchina
Discord社区:https://discord.gg/defidao
电报频道:https://t.me/Mute_8btc
电报社区:https://t.me/news_8btc